







前言
在实际处理过程中,我们使用YOLO V8进行推理时,通常会针对一张图片进行推理。如果需要对多张图片进行推理,则可以通过一个循环来实现对图片逐张进行推理。
单张图片推理时,需要注意图片的尺寸必须是32的倍数,否则可能导致推理失败。在下面的示例中,我们展示了如何使用PyTorch和Ultralytics库进行单张图片的推理:
import torch
from ultralytics import YOLO
# Load a pretrained YOLOv8n model
model = YOLO('yolov8n-pose.pt')
# Create a random torch tensor of BCHW shape (1, 3, 640, 640) with values in range [0, 1] and type float32
source = torch.rand(1, 3, 640, 640, dtype=torch.float32)
# Run inference on the source
results = model(source) # list of Results objects批量图片推理时,也需要注意图片的尺寸必须是32的倍数。在下面的示例中,我们展示了如何使用PyTorch和Ultralytics库进行多张图片的批量推理:
import torch
from ultralytics import YOLO
# Load a pretrained YOLOv8n model
model = YOLO('yolov8n-pose.pt')
# Create a random torch tensor of BCHW shape (1, 3, 640, 640) with values in range [0, 1] and type float32
source = torch.rand(4, 3, 640, 640, dtype=torch.float32)
# Run inference on the source
results = model(source) # list of Results objects需要注意的是,在批量推理时,虽然一次推理了多张图片,但实际处理方式仍然是通过循环进行的。在下面的文章中,我们将介绍如何使用更高效的方式进行批量推理,以获得更快的推理速度和更好的性能。
下面我们介绍如何将【单张图片推理】检测代码给修改成 【批量图片推理】代码,进行批量推理。
一、批量推理的前处理
原始代码
@staticmethod
def letterbox(im, new_shape=(640, 640), color=(114, 114, 114), scaleup=True, stride=32):
# Resize and pad image while meeting stride-multiple constraints
shape = im.shape[:2] # current shape [height, width]
if isinstance(new_shape, int):
new_shape = (new_shape, new_shape)
# Scale ratio (new / old)
r = min(new_shape[0] / shape[0], new_shape[1] / shape[1])
if not scaleup: # only scale down, do not scale up (for better val mAP)
r = min(r, 1.0)
# Compute padding
ratio = r, r # width, height ratios
new_unpad = int(round(shape[1] * r)), int(round(shape[0] * r))
dw, dh = new_shape[1] - new_unpad[0], new_shape[0] - new_unpad[1] # wh padding
# minimum rectangle
dw, dh = np.mod(dw, stride), np.mod(dh, stride) # wh padding
dw /= 2 # divide padding into 2 sides
dh /= 2
if shape[::-1] != new_unpad: # resize
im = cv2.resize(im, new_unpad, interpolation=cv2.INTER_LINEAR)
top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1))
left, right = int(round(dw - 0.1)), int(round(dw + 0.1))
im = cv2.copyMakeBorder(im, top, bottom, left, right, cv2.BORDER_CONSTANT, value=color) # add border
return im, ratio, (dw, dh)
def precess_image(self, img_src, img_size, half, device):
# Padded resize
img = self.letterbox(img_src, img_size)[0]
# Convert
img = img.transpose((2, 0, 1))[::-1] # HWC to CHW, BGR to RGB
img = np.ascontiguousarray(img)
img = torch.from_numpy(img).to(device)
img = img.half() if half else img.float() # uint8 to fp16/32
img = img / 255 # 0 - 255 to 0.0 - 1.0
if len(img.shape) == 3:
img = img[None] # expand for batch dim
return img处理方式
我们要先知道在原始处理方式中是如何操作的:
它包含以下步骤:
-
self.pre_transform:即 letterbox 添加灰条
-
img.transpose((2, 0, 1))[::-1]:HWC to CHW, BGR to RGB
-
torch.from_numpy:to Tensor
-
img.float() :uint8 to fp32
-
im /= 255:除以 255,归一化
-
img[None]:增加维度
在上述处理过程中我们最主要进行修改的就是 self.pre_transform 里面的操作,其余部分都是可以直接进行批量操作的。
在 letterbox 中最主要的操作就是下面两个函数,使用 opencv 进行实现的。我们要进行批量操作,那么 opencv 库是不能实现的,进行批量操作一般会用 广播机制 或者 tensor操作 来实现。
im = cv2.resize(im, new_unpad, interpolation=cv2.INTER_LINEAR)
im = cv2.copyMakeBorder(im, top, bottom, left, right, cv2.BORDER_CONSTANT, value=color) 由于最终输入到模型里面的是一个tensor,所以在这里我们使用 tensor的操作方式进行实现。
尺寸修改
原始方法:
im = cv2.resize(im, new_unpad, interpolation=cv2.INTER_LINEAR)
现在方法:
resized_tensor = F.interpolate(image_tensor, size=new_unpad, mode='bilinear', align_corners=False)两者的实现效果:
原始方法:(1176, 1956, 3) --》(385, 640, 3)

现在方法:(1176, 1956, 3) --》(385, 640, 3)

添加边框
原始方式:
im = cv2.copyMakeBorder(im, top, bottom, left, right, cv2.BORDER_CONSTANT, value=color)
现在方法:
padded_tensor = F.pad(resized_tensor, (top, bottom, left, right), mode='constant', value=padding_value)两者的实现效果:
原始方法:(385, 640, 3) --》(416, 640, 3)

现在方法:(385, 640, 3) --》(416, 640, 3)

修改后的代码
def tensor_process(self, image_cv):
img_shape = image_cv.shape[1:]
new_shape = [640, 640]
r = min(new_shape[0] / img_shape[0], new_shape[1] / img_shape[1])
# Compute padding
new_unpad = int(round(img_shape[0] * r)), int(round(img_shape[1] * r))
dw, dh = new_shape[1] - new_unpad[0], new_shape[0] - new_unpad[1] # wh padding
dw, dh = np.mod(dw, 32), np.mod(dh, 32) # wh padding
dw /= 2 # divide padding into 2 sides
dh /= 2
top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1))
left, right = int(round(dw - 0.1)), int(round(dw + 0.1))
padding_value = 114
image_tensor = torch.from_numpy(image_cv).permute(0, 3, 1, 2).float()
image_tensor = image_tensor.to(self.device)
resized_tensor = F.interpolate(image_tensor, size=new_unpad, mode='bilinear', align_corners=False)
padded_tensor = F.pad(resized_tensor, (top, bottom, left, right), mode='constant', value=padding_value)
infer_tensor = padded_tensor / 255.0
return infer_tensor二、批量推理的后处理
原始代码
def non_max_suppression(
prediction,
conf_thres=0.25,
iou_thres=0.45,
classes=None,
agnostic=False,
multi_label=False,
labels=(),
max_det=300,
nc=0, # number of classes (optional)
max_time_img=0.05,
max_nms=30000,
max_wh=7680,
rotated=False,
):
"""
Perform non-maximum suppression (NMS) on a set of boxes, with support for masks and multiple labels per box.
Args:
prediction (torch.Tensor): A tensor of shape (batch_size, num_classes + 4 + num_masks, num_boxes)
containing the predicted boxes, classes, and masks. The tensor should be in the format
output by a model, such as YOLO.
conf_thres (float): The confidence threshold below which boxes will be filtered out.
Valid values are between 0.0 and 1.0.
iou_thres (float): The IoU threshold below which boxes will be filtered out during NMS.
Valid values are between 0.0 and 1.0.
classes (List[int]): A list of class indices to consider. If None, all classes will be considered.
agnostic (bool): If True, the model is agnostic to the number of classes, and all
classes will be considered as one.
multi_label (bool): If True, each box may have multiple labels.
labels (List[List[Union[int, float, torch.Tensor]]]): A list of lists, where each inner
list contains the apriori labels for a given image. The list should be in the format
output by a dataloader, with each label being a tuple of (class_index, x1, y1, x2, y2).
max_det (int): The maximum number of boxes to keep after NMS.
nc (int, optional): The number of classes output by the model. Any indices after this will be considered masks.
max_time_img (float): The maximum time (seconds) for processing one image.
max_nms (int): The maximum number of boxes into torchvision.ops.nms().
max_wh (int): The maximum box width and height in pixels
Returns:
(List[torch.Tensor]): A list of length batch_size, where each element is a tensor of
shape (num_boxes, 6 + num_masks) containing the kept boxes, with columns
(x1, y1, x2, y2, confidence, class, mask1, mask2, ...).
"""
# Checks
assert 0 <= conf_thres <= 1, f"Invalid Confidence threshold {conf_thres}, valid values are between 0.0 and 1.0"
assert 0 <= iou_thres <= 1, f"Invalid IoU {iou_thres}, valid values are between 0.0 and 1.0"
if isinstance(prediction, (list, tuple)): # YOLOv8 model in validation model, output = (inference_out, loss_out)
prediction = prediction[0] # select only inference output
bs = prediction.shape[0] # batch size
nc = nc or (prediction.shape[1] - 4) # number of classes
nm = prediction.shape[1] - nc - 4
mi = 4 + nc # mask start index
xc = prediction[:, 4:mi].amax(1) > conf_thres # candidates
# Settings
# min_wh = 2 # (pixels) minimum box width and height
time_limit = 0.5 + max_time_img * bs # seconds to quit after
multi_label &= nc > 1 # multiple labels per box (adds 0.5ms/img)
prediction = prediction.transpose(-1, -2) # shape(1,84,6300) to shape(1,6300,84)
if not rotated:
prediction[..., :4] = xywh2xyxy(prediction[..., :4]) # xywh to xyxy
t = time.time()
output = [torch.zeros((0, 6 + nm), device=prediction.device)] * bs
for xi, x in enumerate(prediction): # image index, image inference
# Apply constraints
# x[((x[:, 2:4] < min_wh) | (x[:, 2:4] > max_wh)).any(1), 4] = 0 # width-height
x = x[xc[xi]] # confidence
# Cat apriori labels if autolabelling
if labels and len(labels[xi]) and not rotated:
lb = labels[xi]
v = torch.zeros((len(lb), nc + nm + 4), device=x.device)
v[:, :4] = xywh2xyxy(lb[:, 1:5]) # box
v[range(len(lb)), lb[:, 0].long() + 4] = 1.0 # cls
x = torch.cat((x, v), 0)
# If none remain process next image
if not x.shape[0]:
continue
# Detections matrix nx6 (xyxy, conf, cls)
box, cls, mask = x.split((4, nc, nm), 1)
if multi_label:
i, j = torch.where(cls > conf_thres)
x = torch.cat((box[i], x[i, 4 + j, None], j[:, None].float(), mask[i]), 1)
else: # best class only
conf, j = cls.max(1, keepdim=True)
x = torch.cat((box, conf, j.float(), mask), 1)[conf.view(-1) > conf_thres]
# Filter by class
if classes is not None:
x = x[(x[:, 5:6] == torch.tensor(classes, device=x.device)).any(1)]
# Check shape
n = x.shape[0] # number of boxes
if not n: # no boxes
continue
if n > max_nms: # excess boxes
x = x[x[:, 4].argsort(descending=True)[:max_nms]] # sort by confidence and remove excess boxes
# Batched NMS
c = x[:, 5:6] * (0 if agnostic else max_wh) # classes
scores = x[:, 4] # scores
if rotated:
boxes = torch.cat((x[:, :2] + c, x[:, 2:4], x[:, -1:]), dim=-1) # xywhr
i = nms_rotated(boxes, scores, iou_thres)
else:
boxes = x[:, :4] + c # boxes (offset by class)
i = torchvision.ops.nms(boxes, scores, iou_thres) # NMS
i = i[:max_det] # limit detections
# # Experimental
# merge = False # use merge-NMS
# if merge and (1 < n < 3E3): # Merge NMS (boxes merged using weighted mean)
# # Update boxes as boxes(i,4) = weights(i,n) * boxes(n,4)
# from .metrics import box_iou
# iou = box_iou(boxes[i], boxes) > iou_thres # iou matrix
# weights = iou * scores[None] # box weights
# x[i, :4] = torch.mm(weights, x[:, :4]).float() / weights.sum(1, keepdim=True) # merged boxes
# redundant = True # require redundant detections
# if redundant:
# i = i[iou.sum(1) > 1] # require redundancy
output[xi] = x[i]
if (time.time() - t) > time_limit:
LOGGER.warning(f"WARNING ⚠️ NMS time limit {time_limit:.3f}s exceeded")
break # time limit exceeded
return output处理方式
我们要先知道在原始处理方式中是如何操作的。
在这个里面,最主要的操作就是 nms 操作,这里的 nms 操作就是一张图一张图的结果进行处理,不是多张图的结果一起处理,我们最主要的就是要修改这里的代码。
但是在这里,我们要先理解在原始的处理方式是怎样的逻辑。
原始 nms 逻辑
在这里就只给出关键步骤:
计算第4列到第mi列中的最大值,然后将这个最大值与conf_thres进行比较,得到一个布尔值结果。最终的输出是一个布尔张量,表示每一行是否存在大于conf_thres的最大值。
xc = prediction[:, 4:mi].amax(1) > conf_thres # candidates将原始预测框中的 xywh 转为 xyxy
prediction[..., :4] = xywh2xyxy(prediction[..., :4])从原始结果中选择出为True的结果,得到初步的筛选结果
x = x[xc[xi]] # confidence分离出 标注框,类别,掩码
box, cls, mask = x.split((4, nc, nm), 1)再次根据 cls 进行筛选,并拼接成新的推理结果
conf, j = cls.max(1, keepdim=True)
x = torch.cat((box, conf, j.float(), mask), 1)[conf.view(-1) > conf_thres]计算nms
boxes = x[:, :4] + c # boxes (offset by class)
i = torchvision.ops.nms(boxes, scores, iou_thres) # NMS只选出前 max_det的输出结果,避免有多余的输出
i = i[:max_det] # limit detections现在 nms 逻辑
将 prediction 中所有批次的结果进行统一,处理成一个批次,在将这个批次送入到 batched_nms 中,最后在进行处理,得到标注框,类别,置信度。
筛选出为true的索引(批次数)和行数
true_indices = torch.nonzero(xc)根据索引和行数筛选出 prediction 中真实的结果,注意:这个结果是所有的批次的结果
selected_rows = prediction[true_indices[:, 0], true_indices[:, 1]]将批次数添加在筛选出的结果中,用于区分出那个结果是那个批次的。注意:这个的批次也可以看成是对应的图片
new_prediction = torch.cat((selected_rows, true_indices[:, 0].unsqueeze(1).float()), dim=1)分割出标注框、类别、掩码、索引(批次)
box, cls, mask, idxs = new_prediction.split((4, nc, nm, 1), 1)筛选出最大的类别的置信和类别索引
conf, j = cls.max(1, keepdim=True)根据类别置信度再次进行筛选,选出符合的结果,并进行拼接,得到一个新的结果
x = torch.cat((box, conf, j.float()), 1)[conf.squeeze(-1) > conf_thres]将标注框,置信度,索引,iou值送入到 batched_nms 中,选出最终的预测结果的索引标签。
cls = x[:, 5] # classes
c = x[:, 5:6] * (0 if agnostic else max_wh)
boxes, scores = x[:, :4] + c, x[:, 4] # boxes (offset by class), scores
idxs = idxs.t().squeeze(0)
keep = torchvision.ops.batched_nms(boxes, scores, idxs, iou_thres)batched_nms:以批处理方式执行非最大值抑制。每个索引值对应一个类别,NMS不会应用于不同类别的元素之间。
参数:
boxes (Tensor[N, 4]):标注框,为
(x1, y1, x2, y2)格式,其中0 <= x1 < x2和0 <= y1 < y2。scores (Tensor[N]):每个标注框的得分
idxs (Tensor[N]):每个标注框的类别索引。
iou_threshold(float):剔除 IoU > iou_threshold 的所有重叠方框
返回值:
Tensor:int64,为 NMS 保留的元素索引,按分数递减排序
def batched_nms(boxes: Tensor, scores: Tensor, idxs: Tensor, iou_threshold: float,) -> Tensor:根据 nms 的筛选结果,选择出最终的预测结果
boxes[keep] = self.scale_boxes(inferShape, boxes[keep], orgShape)
temp_masks = masks[keep].view(len(masks[keep]), *self.model.kpt_shape) if len(masks[keep]) else masks[keep][:, 6:]
masks[keep] = self.scale_coords(inferShape, temp_masks, orgShape).view(len(masks[keep]), -1)
boxes = boxes[keep].cpu().numpy()
scores = scores[keep].cpu().numpy()
cls = cls[keep].cpu().numpy()
masks = masks[keep].cpu().numpy()
idxs = idxs[keep].cpu().numpy()修改后的代码
def non_max_suppression(self, prediction, proto, inferShape, orgShape, conf_thres=0.25, iou_thres=0.45,
agnostic=True, multi_label=False, max_wh=7680, nc=0):
prediction = prediction[0] # select only inference output
nc = nc or (prediction.shape[1] - 4) # number of classes
nm = prediction.shape[1] - nc - 4
mi = 4 + nc # mask start index
xc = prediction[:, 4:mi].amax(1) > conf_thres # candidates
# Settings
multi_label &= nc > 1 # multiple labels per box (adds 0.5ms/img)
prediction = prediction.transpose(-1, -2) # shape(1,84,6300) to shape(1,6300,84)
prediction[..., :4] = self.xywh2xyxy(prediction[..., :4]) # xywh to xyxy
true_indices = torch.nonzero(xc)
selected_rows = prediction[true_indices[:, 0], true_indices[:, 1]]
new_prediction = torch.cat((selected_rows, true_indices[:, 0].unsqueeze(1).float()), dim=1)
if new_prediction.shape[0] == 0:
return
box, cls, seg, idxs = new_prediction.split((4, nc, nm, 1), 1)
conf, j = cls.max(1, keepdim=True)
x = torch.cat((box, conf, j.float(), seg), 1)[conf.squeeze(-1) > conf_thres]
if not x.shape[0]: # no boxes
return
# Batched NMS
cls = x[:, 5] # classes
c = x[:, 5:6] * (0 if agnostic else max_wh)
boxes, scores = x[:, :4] + c, x[:, 4] # boxes (offset by class), scores
segs = x[:, 6:]
idxs = idxs.t().squeeze(0)
keep = torchvision.ops.batched_nms(boxes, scores, idxs, iou_thres)
segs = self.process_mask(proto, segs[keep], boxes[keep], inferShape, upsample=True) # HWC
boxes[keep] = self.scale_boxes(inferShape, boxes[keep], orgShape)
segs = segs.view(segs.shape[0], -1).cpu().numpy()
boxes = boxes[keep].cpu().numpy()
scores = scores[keep].cpu().numpy()
cls = cls[keep].cpu().numpy()
idxs = idxs[keep].cpu().numpy()
results = np.hstack((boxes, np.expand_dims(scores, axis=1)))
results = np.hstack((results, np.expand_dims(cls, axis=1)))
results = np.hstack((results, segs))
results = np.hstack((results, np.expand_dims(idxs, axis=1)))
return results三、完整代码
通过上面的解析,我们了解了 YOLO V8-Detection 如何进行批量的推理图片的方法,并对每一步进行了实现。
完整的推理代码如下:
# -*- coding:utf-8 -*-
# @author: 牧锦程
# @微信公众号: AI算法与电子竞赛
# @Email: m21z50c71@163.com
# @VX:fylaicai
import os.path
import random
import cv2
import numpy as np
import torch
import torchvision
from ultralytics.nn.autobackend import AutoBackend
import torch.nn.functional as F
from ultralytics.utils.plotting import colors
class YOLOV8SegmentInfer:
def __init__(self, weights, cuda, conf_thres, iou_thres) -> None:
self.imgsz = 640
self.device = cuda
self.model = AutoBackend(weights, device=torch.device(cuda))
self.model.eval()
self.names = self.model.names
self.half = False
self.conf = conf_thres
self.iou = iou_thres
self.color = {"font": (255, 255, 255)}
self.color.update(
{self.names[i]: (random.randint(0, 255), random.randint(0, 255), random.randint(0, 255))
for i in range(len(self.names))})
def infer(self, img_array, save_path):
img = self.tensor_process(img_array)
preds = self.model(img) # shape [1, 116, 6300]
results = self.non_max_suppression(preds, preds[1][-1][0], img.shape[2:], img_array.shape[1:], self.conf, self.iou, nc=len(self.names))
# 遍历数组,根据最后一列的值进行划分
content_dict = dict()
for row in results:
identifier, content = row[-1], row[:-1]
if identifier in content_dict:
content_dict[int(identifier)] = np.vstack([content_dict[identifier], content])
else:
content_dict[int(identifier)] = np.array(content)
for key, value in content_dict.items():
boxs, scores, ids = value[:, :4], value[:, 4],value[:, 5]
mask = value[:, 6:].reshape(len(value), img[key].shape[1], img[key].shape[2])
self.draw_masks(img_array[key], torch.from_numpy(mask),
colors=[colors(i, True) for i in ids], im_gpu=img[key].squeeze(0))
self.draw_box(img_array[key], boxs, scores, ids)
cv2.imwrite(os.path.join(save_path, f"{key}.jpg"), img_array[key])
def non_max_suppression(self, prediction, proto, inferShape, orgShape, conf_thres=0.25, iou_thres=0.45,
agnostic=True, multi_label=False, max_wh=7680, nc=0):
prediction = prediction[0] # select only inference output
nc = nc or (prediction.shape[1] - 4) # number of classes
nm = prediction.shape[1] - nc - 4
mi = 4 + nc # mask start index
xc = prediction[:, 4:mi].amax(1) > conf_thres # candidates
# Settings
multi_label &= nc > 1 # multiple labels per box (adds 0.5ms/img)
prediction = prediction.transpose(-1, -2) # shape(1,84,6300) to shape(1,6300,84)
prediction[..., :4] = self.xywh2xyxy(prediction[..., :4]) # xywh to xyxy
true_indices = torch.nonzero(xc)
selected_rows = prediction[true_indices[:, 0], true_indices[:, 1]]
new_prediction = torch.cat((selected_rows, true_indices[:, 0].unsqueeze(1).float()), dim=1)
if new_prediction.shape[0] == 0:
return
box, cls, seg, idxs = new_prediction.split((4, nc, nm, 1), 1)
conf, j = cls.max(1, keepdim=True)
x = torch.cat((box, conf, j.float(), seg), 1)[conf.squeeze(-1) > conf_thres]
if not x.shape[0]: # no boxes
return
# Batched NMS
cls = x[:, 5] # classes
c = x[:, 5:6] * (0 if agnostic else max_wh)
boxes, scores = x[:, :4] + c, x[:, 4] # boxes (offset by class), scores
segs = x[:, 6:]
idxs = idxs.t().squeeze(0)
keep = torchvision.ops.batched_nms(boxes, scores, idxs, iou_thres)
segs = self.process_mask(proto, segs[keep], boxes[keep], inferShape, upsample=True) # HWC
boxes[keep] = self.scale_boxes(inferShape, boxes[keep], orgShape)
segs = segs.view(segs.shape[0], -1).cpu().numpy()
boxes = boxes[keep].cpu().numpy()
scores = scores[keep].cpu().numpy()
cls = cls[keep].cpu().numpy()
idxs = idxs[keep].cpu().numpy()
results = np.hstack((boxes, np.expand_dims(scores, axis=1)))
results = np.hstack((results, np.expand_dims(cls, axis=1)))
results = np.hstack((results, segs))
results = np.hstack((results, np.expand_dims(idxs, axis=1)))
return results
def clip_coords(self, coords, shape):
if isinstance(coords, torch.Tensor): # faster individually (WARNING: inplace .clamp_() Apple MPS bug)
coords[..., 0] = coords[..., 0].clamp(0, shape[1]) # x
coords[..., 1] = coords[..., 1].clamp(0, shape[0]) # y
else: # np.array (faster grouped)
coords[..., 0] = coords[..., 0].clip(0, shape[1]) # x
coords[..., 1] = coords[..., 1].clip(0, shape[0]) # y
return coords
def process_mask(self, protos, masks_in, bboxes, shape, upsample=False):
c, mh, mw = protos.shape # CHW
ih, iw = shape
masks = (masks_in @ protos.float().view(c, -1)).sigmoid().view(-1, mh, mw) # CHW
width_ratio = mw / iw
height_ratio = mh / ih
downsampled_bboxes = bboxes.clone()
downsampled_bboxes[:, 0] *= width_ratio
downsampled_bboxes[:, 2] *= width_ratio
downsampled_bboxes[:, 3] *= height_ratio
downsampled_bboxes[:, 1] *= height_ratio
masks = self.crop_mask(masks, downsampled_bboxes) # CHW
if upsample:
masks = F.interpolate(masks[None], shape, mode="bilinear", align_corners=False)[0] # CHW
return masks.gt_(0.5)
def crop_mask(self, masks, boxes):
_, h, w = masks.shape
x1, y1, x2, y2 = torch.chunk(boxes[:, :, None], 4, 1) # x1 shape(n,1,1)
r = torch.arange(w, device=masks.device, dtype=x1.dtype)[None, None, :] # rows shape(1,1,w)
c = torch.arange(h, device=masks.device, dtype=x1.dtype)[None, :, None] # cols shape(1,h,1)
return masks * ((r >= x1) * (r < x2) * (c >= y1) * (c < y2))
def xywh2xyxy(self, x):
assert x.shape[-1] == 4, f"input shape last dimension expected 4 but input shape is {x.shape}"
y = torch.empty_like(x) if isinstance(x, torch.Tensor) else np.empty_like(x) # faster than clone/copy
dw = x[..., 2] / 2 # half-width
dh = x[..., 3] / 2 # half-height
y[..., 0] = x[..., 0] - dw # top left x
y[..., 1] = x[..., 1] - dh # top left y
y[..., 2] = x[..., 0] + dw # bottom right x
y[..., 3] = x[..., 1] + dh # bottom right y
return y
def scale_boxes(self, img1_shape, boxes, img0_shape, ratio_pad=None, padding=True, xywh=False):
if ratio_pad is None: # calculate from img0_shape
gain = min(img1_shape[0] / img0_shape[0], img1_shape[1] / img0_shape[1]) # gain = old / new
pad = (
round((img1_shape[1] - img0_shape[1] * gain) / 2 - 0.1),
round((img1_shape[0] - img0_shape[0] * gain) / 2 - 0.1),
) # wh padding
else:
gain = ratio_pad[0][0]
pad = ratio_pad[1]
if padding:
boxes[..., 0] -= pad[0] # x padding
boxes[..., 1] -= pad[1] # y padding
if not xywh:
boxes[..., 2] -= pad[0] # x padding
boxes[..., 3] -= pad[1] # y padding
boxes[..., :4] /= gain
return self.clip_boxes(boxes, img0_shape)
def clip_boxes(self, boxes, shape):
if isinstance(boxes, torch.Tensor): # faster individually (WARNING: inplace .clamp_() Apple MPS bug)
boxes[..., 0] = boxes[..., 0].clamp(0, shape[1]) # x1
boxes[..., 1] = boxes[..., 1].clamp(0, shape[0]) # y1
boxes[..., 2] = boxes[..., 2].clamp(0, shape[1]) # x2
boxes[..., 3] = boxes[..., 3].clamp(0, shape[0]) # y2
else: # np.array (faster grouped)
boxes[..., [0, 2]] = boxes[..., [0, 2]].clip(0, shape[1]) # x1, x2
boxes[..., [1, 3]] = boxes[..., [1, 3]].clip(0, shape[0]) # y1, y2
return boxes
def draw_box(self, img_src, boxs, scores, ids):
lw = max(round(sum(img_src.shape) / 2 * 0.003), 2) # line width
tf = max(lw - 1, 1) # font thickness
sf = lw / 3 # font scale
for box, score, id in zip(boxs, scores, ids):
color = self.color[self.names[id]]
label = f'{self.names[id]} {score:.4f}'
p1, p2 = (int(box[0]), int(box[1])), (int(box[2]), int(box[3]))
# 绘制矩形框
cv2.rectangle(img_src, p1, p2, color, thickness=lw, lineType=cv2.LINE_AA)
# text width, height
w, h = cv2.getTextSize(label, 0, fontScale=sf, thickness=tf)[0]
# label fits outside box
outside = box[1] - h - 3 >= 0
p2 = p1[0] + w, p1[1] - h - 3 if outside else p1[1] + h + 3
# 绘制矩形框填充
cv2.rectangle(img_src, p1, p2, color, -1, cv2.LINE_AA)
# 绘制标签
cv2.putText(img_src, label, (p1[0], p1[1] - 2 if outside else p1[1] + h + 2),
0, sf, self.color["font"], thickness=2, lineType=cv2.LINE_AA)
def draw_masks(self, img_src, masks, colors, im_gpu, alpha=0.5):
if len(masks) == 0:
img_src[:] = im_gpu.permute(1, 2, 0).contiguous().cpu().numpy() * 255
if im_gpu.device != masks.device:
im_gpu = im_gpu.to(masks.device)
colors = torch.tensor(colors, device=masks.device, dtype=torch.float32) / 255.0 # shape(n,3)
colors = colors[:, None, None] # shape(n,1,1,3)
masks = masks.unsqueeze(3) # shape(n,h,w,1)
masks_color = masks * (colors * alpha) # shape(n,h,w,3)
inv_alpha_masks = (1 - masks * alpha).cumprod(0) # shape(n,h,w,1)
mcs = masks_color.max(dim=0).values # shape(h,w,3)
im_gpu = im_gpu.flip(dims=[0]) # flip channel
im_gpu = im_gpu.permute(1, 2, 0).contiguous() # shape(h,w,3)
im_gpu = im_gpu * inv_alpha_masks[-1] + mcs
im_mask = im_gpu * 255
im_mask_np = im_mask.byte().cpu().numpy()
img_src[:] = self.scale_image(im_mask_np, img_src.shape)
def scale_image(self, masks, im0_shape, ratio_pad=None):
# Rescale coordinates (xyxy) from im1_shape to im0_shape
im1_shape = masks.shape
if im1_shape[:2] == im0_shape[:2]:
return masks
if ratio_pad is None: # calculate from im0_shape
gain = min(im1_shape[0] / im0_shape[0], im1_shape[1] / im0_shape[1]) # gain = old / new
pad = (im1_shape[1] - im0_shape[1] * gain) / 2, (im1_shape[0] - im0_shape[0] * gain) / 2 # wh padding
else:
# gain = ratio_pad[0][0]
pad = ratio_pad[1]
top, left = int(pad[1]), int(pad[0]) # y, x
bottom, right = int(im1_shape[0] - pad[1]), int(im1_shape[1] - pad[0])
if len(masks.shape) < 2:
raise ValueError(f'"len of masks shape" should be 2 or 3, but got {len(masks.shape)}')
masks = masks[top:bottom, left:right]
masks = cv2.resize(masks, (im0_shape[1], im0_shape[0]))
if len(masks.shape) == 2:
masks = masks[:, :, None]
return masks
def tensor_process(self, image_cv):
img_shape = image_cv.shape[1:]
new_shape = [640, 640]
r = min(new_shape[0] / img_shape[0], new_shape[1] / img_shape[1])
# Compute padding
new_unpad = int(round(img_shape[0] * r)), int(round(img_shape[1] * r))
dw, dh = new_shape[1] - new_unpad[0], new_shape[0] - new_unpad[1] # wh padding
dw, dh = np.mod(dw, 32), np.mod(dh, 32) # wh padding
dw /= 2 # divide padding into 2 sides
dh /= 2
top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1))
left, right = int(round(dw - 0.1)), int(round(dw + 0.1))
padding_value = 114
# Convert
image_cv = image_cv[..., ::-1].transpose((0, 3, 1, 2)) # BGR to RGB, BHWC to BCHW, (n, 3, h, w)
image_cv = np.ascontiguousarray(image_cv) # contiguous
image_tensor = torch.from_numpy(image_cv).float()
image_tensor = image_tensor.to(self.device)
resized_tensor = F.interpolate(image_tensor, size=new_unpad, mode='bilinear', align_corners=False)
padded_tensor = F.pad(resized_tensor, (top, bottom, left, right), mode='constant', value=padding_value)
infer_tensor = padded_tensor / 255.0
return infer_tensor
if __name__ == '__main__':
weights = r'./weights/yolov8n-seg.pt'
cuda = 'cuda:0'
save_path = "./runs"
if not os.path.exists(save_path):
os.mkdir(save_path)
model = YOLOV8SegmentInfer(weights, cuda, 0.45, 0.45)
img_path = r'./img/bus.jpg'
img_src = cv2.imread(img_path)
img_array = np.array([img_src, img_src])
model.infer(img_array, save_path)
四、书籍推荐
推荐一本书籍:《Python深度学习》
书籍介绍
本书是为那些想要从零开始探索深度学习的人或想要拓展对深度学习的理解的人而写的。无论是在职的机器学习工程师、软件开发者还是大学生,都会在本书中找到有价值的内容。本书是对深度学习的实践探索,避免使用数学符号,尽量用代码片段来解释定量概念,帮你建立关于机器学习和深度学习核心思想的直觉。
书中包含 30 多个代码示例,有详细的注释、实用的建议和简单的解释。知道这些你就可以开始用深度学习来解决具体问题了。
全书代码示例都使用 Python 深度学习框架 Keras,并用 TensorFlow 作为后端引擎。Keras是最受欢迎且发展最快的深度学习框架之一,被广泛推荐为上手深度学习的最佳工具。读完本书后,你将会充分理解什么是深度学习、什么时候该用深度学习,以及它的局限性。你将学到解决机器学习问题的标准工作流程,还会知道如何解决常见问题。你将能够使用 Keras来解决从计算机视觉到自然语言处理等许多现实世界的问题,包括图像识别、时间序列预测、情感分析、图像和文字生成等。
谁应该阅读这本书
本书的目标读者是那些具有 Python 编程经验,并且想要开始上手机器学习和深度学习的人。但本书对以下这些读者也都很有价值。
-
如果你是熟悉机器学习的数据科学家,你将通过本书全面掌握深度学习及其实践。深度学习是机器学习中发展最快、最重要的子领域。
-
如果你是想要上手 Keras 框架的深度学习专家,你会发现本书是市面上最棒的 Keras 速成教程。
-
如果你是研究深度学习的研究生,你会发现本书是对你所受教育的实践补充,有助于你培养关于深度神经网络的直觉,还可以让你熟悉重要的最佳实践。
有技术背景的人,即使不经常编程,也会发现本书介绍的深度学习基本概念和高级概念非常有用。
使用 Keras 需要具有一定的 Python 编程水平。另外,熟悉 Numpy 库也会有所帮助,但并不是必需的。你不需要具有机器学习或深度学习方面的经验,本书包含从头学习所需的必要基础知识。你也不需要具有高等数学背景,掌握高中水平的数学知识应该足以看懂本书内容。
学习路线图
本书分为两部分。如果你之前没有关于机器学习的经验,我强烈建议你先读完第一部分,然后再阅读第二部分。我们会从简单示例讲起,然后再依次介绍越来越先进的技术。
第一部分是对深度学习的介绍,给出了一些背景和定义,还解释了上手机器学习和神经网
络需要掌握的所有概念。
-
第 1 章介绍人工智能、机器学习和深度学习的重要背景知识。
-
第 2 章介绍从事深度学习必须了解的基本概念:张量、张量运算、梯度下降和反向传播。这一章还给出了本书第一个可用的神经网络示例。
-
第 3 章包括上手神经网络所需要了解的全部内容:Keras 简介,它是我们的首选深度学习框架;建立自己的工作站的指南;三个基本代码示例以及详细解释。读完这一章,你将能够训练简单的神经网络来处理分类任务和回归任务,你还将充分了解训练过程背后发生的事情。
-
第 4 章介绍标准的机器学习工作流程。你还会了解常见的陷阱及其解决方案。
第二部分将深入介绍深度学习在计算机视觉和自然语言处理中的实际应用。这一部分给出了许多示例,对于在现实世界的实践中遇到的深度学习问题,你可以用这些示例作为解决问题的模板。
-
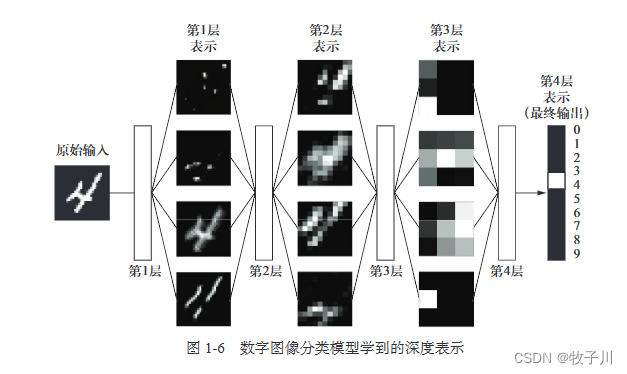
第 5 章介绍了一系列实用的计算机视觉示例,重点放在图像分类。
-
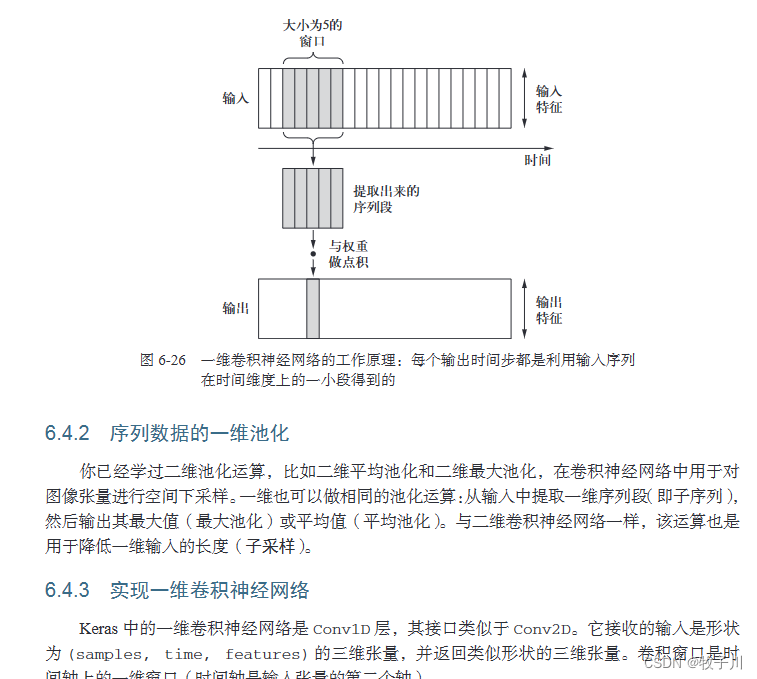
第 6 章介绍了处理序列数据(比如文本和时间序列)的实用技术。
-
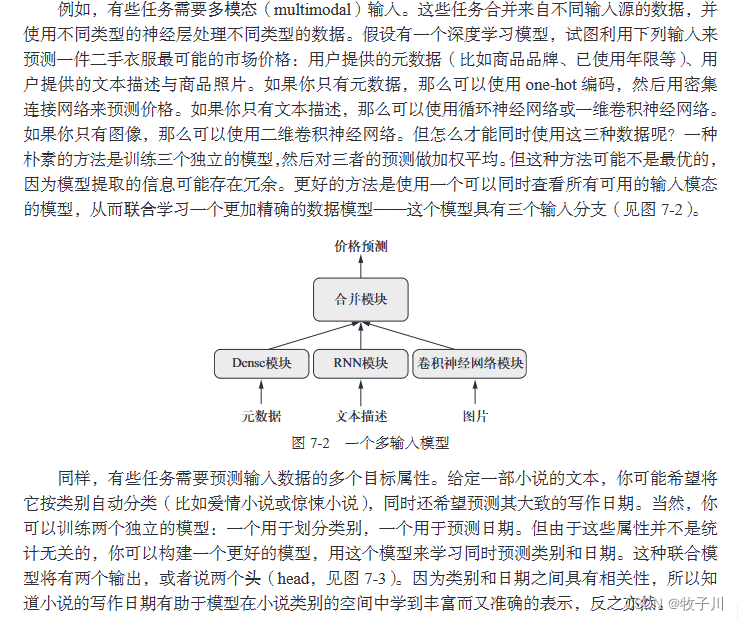
第 7 章介绍了构建最先进深度学习模型的高级技术。
-
第 8 章介绍了生成式模型,即能够创造图像和文本的深度学习模型,它有时会产生令人惊讶的艺术效果。
-
第 9 章将帮你巩固在本书学到的知识,还会探讨深度学习的局限性及其未来的可能性。


关注下方公众号:@AI算法与电子竞赛,回复关键字“PDF”获取下载地址
五、链接作者
欢迎关注我的公众号:@AI算法与电子竞赛
硬性的标准其实限制不了无限能的我们,所以啊!少年们加油吧!
















 3354
3354

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











