






对于如何写出让CPU跑得更快的代码这一问题,我看到了两种方法,分别是:1、提高数据缓存命中率;2、提高指令缓存命中率。
本文对这两种方法进行了简单的验证,并提供了示例代码。
本文基于2.3 如何写出让 CPU 跑得更快的代码? | 小林coding (xiaolincoding.com)进行分析
在虚拟机上使用的编译环境为:
-
数据缓存命中率验证
-
现象与验证
对于下列代码:
//二维数组 array[N][N] = 0; //形式一: for( i = 0; i<N;i+=1){ for(j = 0; j <N;j+=1){ array[i][j] = 0; } } //形式二: for( i = 0; i<N; i+=1) { for(j = 0; j <N;j+=1) { array[j][i] = 0; } }对于以上二维数组,提供了两种遍历形式,为了测试哪一种遍历形式执行速度更快,将代码补充为完整的C语言程序:
#include <stdio.h> #include <stdlib.h> #include <time.h> #define N 1000 // 数组大小 void initializeArray(int array[N][N], int mode) { int i, j; if (mode == 1) { for (i = 0; i < N; i++) { for (j = 0; j < N; j++) { array[i][j] = 0; } } } else if (mode == 2) { for (i = 0; i < N; i++) { for (j = 0; j < N; j++) { array[j][i] = 0; } } } } double getTimeInSeconds() { return (double)clock() / CLOCKS_PER_SEC; } int main() { int array[N][N]; double startTime, endTime; // 形式一 startTime = getTimeInSeconds(); initializeArray(array, 1); endTime = getTimeInSeconds(); printf("形式一执行时间: %f 秒\n", endTime - startTime); // 形式二 startTime = getTimeInSeconds(); initializeArray(array, 2); endTime = getTimeInSeconds(); printf("形式二执行时间: %f 秒\n", endTime - startTime); return 0; }执行结果如下:
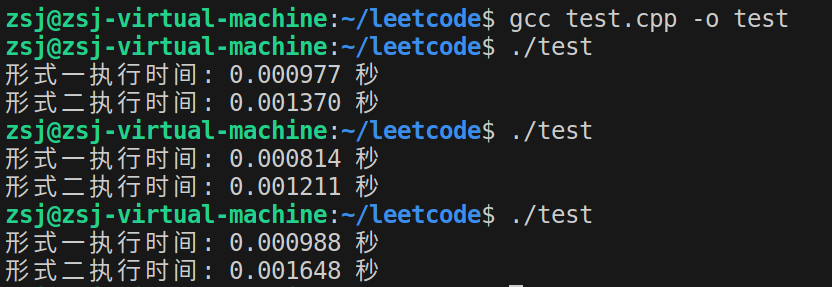
可见形式一(对内存进行连续遍历)确实要快一些。
-
原因说明
二维数组array所占内存连续,
-
对于形式一,按
array[i][j]顺序访问数组元素,与内存中数组元素存放的顺序一致。当CPU访问到array[0][0]时,由于该数据不在Cache中,会顺序把其后的一些元素从内存加载到CPU Cache中,这样当CPU访问后面的几个数组元素时,就能在CPU Cache中中成功找到数据,这意味着缓存命中率很高,缓存命中的数据不需要访问内存,这就大大提高了代码的性能。 -
对于形式二,访问的方式是跳跃的,而不是顺序的,那么如果N的数值很大,那么操作
array[j][i]时,没办法把array[j+1][i]也读入到CPU Cache中,那么就需要从内存读取该数据元素了。这种方式不能利用CPU Cache的特性,从而代码的性能不高。 -
输入指令
cat /sys/devices/system/cpu/cpu0/cache/index0/coherency_line_size可以查看CPU Cache一次性能加载的数据的大小:
-
-
-
指令缓存命中率验证
intarray[N]; for (i = 0; i<N;i++){ array[i] = rand()% 100; } //操作一:数组遍历 for( i = 0; i<N;i++) { if ( array [i] < 50){ array[i] = 0; } } //操作二:排序 sort(array,array + N);为了测试是先遍历再排序执行速度快,还是先排序再遍历速度快,将代码补充为完整的C++语言程序:
#include <iostream> #include <cstdlib> #include <ctime> #include <algorithm> #include <cstring> #define N 100000 // 数组大小 void generateArray(int array[N]) { for (int i = 0; i < N; i++) { array[i] = rand() % 100; } } void arrayTraversal(int array[N]) { for (int i = 0; i < N; i++) { if (array[i] < 50) { array[i] = 0; } } } void sort(int array[N]) { std::sort(array, array + N); } int main() { int array1[N], array2[N]; clock_t start, end; double duration1, duration2; // 生成随机数组 generateArray(array1); std::memcpy(array2, array1, N * sizeof(int)); // 排序 -> 遍历 start = clock(); sort(array1); arrayTraversal(array1); end = clock(); duration2 = (double)(end - start) / CLOCKS_PER_SEC; std::cout << "排序 -> 遍历 执行时间: " << duration2 << " 秒" << std::endl; // 遍历 -> 排序 start = clock(); arrayTraversal(array2); sort(array2); end = clock(); duration1 = (double)(end - start) / CLOCKS_PER_SEC; std::cout << "遍历 -> 排序 执行时间: " << duration1 << " 秒" << std::endl; return 0; }执行结果如下:
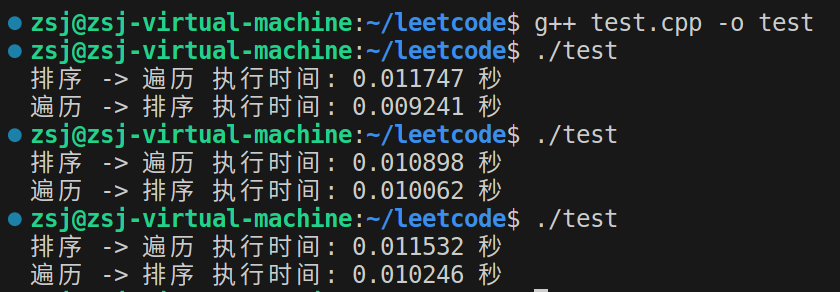
从结果上看感觉先排序再遍历速度好像还慢一点,我们将这两个操作的顺序反过来再验证看:
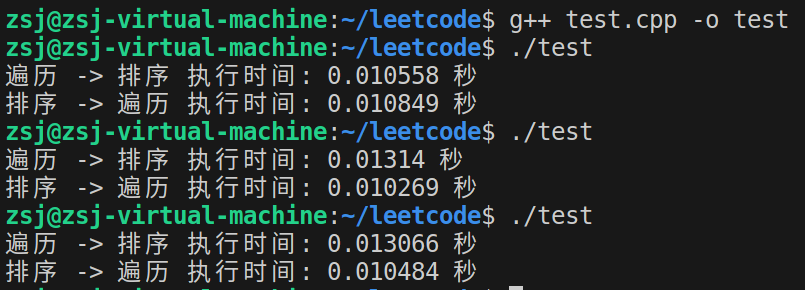
实践发现结果又反了过来,直观上分支预测器在这里的效果并不明显。
-
总结
对于如何让CPU跑得更快这一问题,本文对提高数据缓存命中率与提高指令缓存命中率的方法分别进行了简单的实验验证。
其中前者成功进行了验证,后者在本文中的程序中效果并不明显。
更深层的原因暂未深究,但使用时仍可按原文方法进行。
















 396
396

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









