







论文:Stand-Alone Self-Attention in Vision Models
因为我看这个文章的时候跳过了很多之前self-attention的知识,对公式的理解花了一段时间,所以这里主要写公式的理解,权当笔记。
前言:
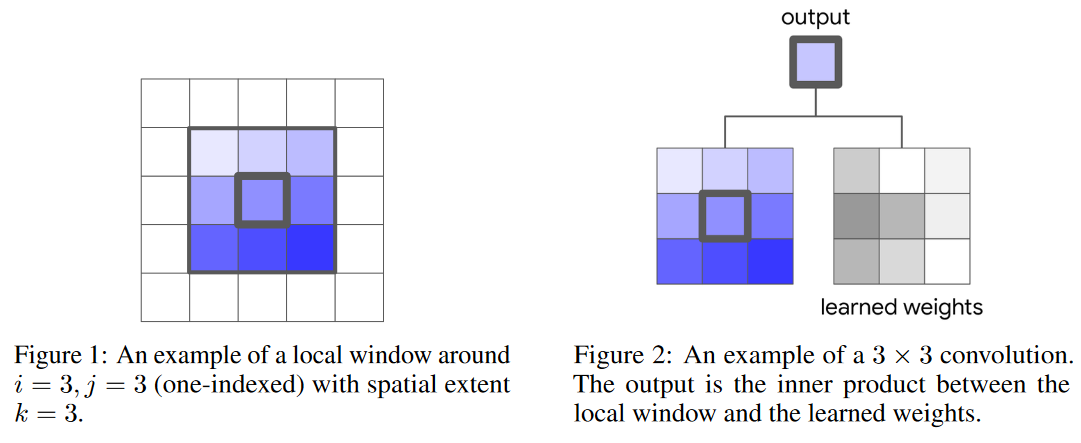 卷积神经网络(CNN)通常学习小范围(kernel sizes)的局部特征,对于输入
x
∈
R
h
×
w
×
d
i
n
x∈\mathbb{R}^{h×w×d_{in}}
x∈Rh×w×din,定义局部像素集
N
k
\mathcal{N}_k
Nk ,为像素
x
i
,
j
x_{i,j}
xi,j周围
k
k
k区域的像素,大小为
k
×
k
×
d
i
n
k×k×d_{in}
k×k×din ,如图1:
卷积神经网络(CNN)通常学习小范围(kernel sizes)的局部特征,对于输入
x
∈
R
h
×
w
×
d
i
n
x∈\mathbb{R}^{h×w×d_{in}}
x∈Rh×w×din,定义局部像素集
N
k
\mathcal{N}_k
Nk ,为像素
x
i
,
j
x_{i,j}
xi,j周围
k
k
k区域的像素,大小为
k
×
k
×
d
i
n
k×k×d_{in}
k×k×din ,如图1:

对于学习到的权重 W ∈ R k × k × d o u × k i n W \in \mathbb{R}^{{k \times k \times d_{o u}} \times k_{in}} W∈Rk×k×dou×kin , 位置 i j ij ij 的输出 y i j ∈ R d o u t y_{ij} \in \mathbb{R}^{d_{out}} yij∈Rdout ,通过公式(1)计算所得, 其中 N k ( i , j ) = { a , b ∣ ∣ a − i ∣ ≤ k / 2 , ∣ b − j ∣ ≤ k / 2 } \mathcal{N}_{k}(i, j)=\{a, b|| a-i|\leq k / 2,| b-j \mid \leq k / 2\} Nk(i,j)={a,b∣∣a−i∣≤k/2,∣b−j∣≤k/2}, CNN 使用权重共享, W W W 用于所有像素位置 i j i j ij 的输出,权重共享使得特征具有平移不变性以及降低卷积的参数量。目前有一些卷积的变种用 以提高预测的表现, 比如深度分离卷积
讲这些的原因主要是为了记住公式中各个符号的意义,从而更好地理解后面的自注意力机制公式计算方法。
Self-Attention
与传统的attention不同,self-attention应用于单个context而不是多个context间,能够直接建模context内长距离的交互信息,论文提出stand-alone self-attention layer用来替代卷积操作,并且构建full attention模型,这个attention layer主要是对之前的工作的一个简化

与卷积类似,对于像素
x
i
j
∈
R
d
i
n
x_{ij} \in \mathbb{R}^{d_{in}}
xij∈Rdin,首先会取
x
i
j
x_{ij}
xij的
k
k
k范围内的局部区域像素
a
b
∈
N
k
(
i
,
j
)
ab \in \mathcal{N}_k(i,j)
ab∈Nk(i,j) (
a
b
ab
ab是像素的位置,和
i
j
ij
ij一样) ,称为memory block。与之前的all-to-all attention不同,这个attention只在局部区域
N
k
(
i
,
j
)
\mathcal{N}_k(i,j)
Nk(i,j)进行attention操作,全局attention只有在特征大小大幅减少后才能使用,不然会带来很大的计算开销

single-headed attention计算如公式2,输出像素
y
i
j
∈
R
d
o
u
t
y_{ij} \in \mathbb{R}^{d_{out}}
yij∈Rdout,首先对输入向量进行三种变化得到3个值,:查询矩阵:
Q
=
W
Q
x
Q=W_{Q}\large x
Q=WQx,关键词矩阵:
K
=
W
K
x
K=W_{K}\large x
K=WKx,值矩阵:
V
=
W
V
x
V=W_{V}\large x
V=WVx
那么就有:查询像素queries
q
i
j
=
W
Q
x
i
j
q_{i j}=W_{Q} x_{i j}
qij=WQxij, 关键词像素keys
k
a
b
=
W
K
x
a
b
k_{a b}=W_{K} x_{a b}
kab=WKxab 以及值像素values
v
a
b
=
W
V
x
a
b
v_{ab}=W_{V} x_{a b}
vab=WVxab 都是像素
i
j
i j
ij 和其附近像素的线性变化,
s
o
f
t
m
a
x
a
b
softmax_{a b}
softmaxab 应用于所有
q
i
j
⊤
k
a
b
q_{i j}^{\top} k_{a b}
qij⊤kab ,
W
Q
,
W
K
,
W
V
∈
R
d
o
u
t
×
d
i
n
W_{Q}, W_{K}, W_{V} \in \mathbb{R}^{d_{o u t} \times d_{i n}}
WQ,WK,WV∈Rdout×din 为学习到的变化。与公式1的卷积类似, local self-attention通过结合混合权重(
softmax
a
b
(
⋅
)
\operatorname{softmax}_{a b}(\cdot)
softmaxab(⋅) ) 与值向量进行输出,每个位置
i
j
i j
ij 都重复上述步骤。
Self-Attention公式分析
在这里解释一下公式:
-
先解释一下 W Q , W K , W V W_{Q}, W_{K}, W_{V} WQ,WK,WV的维数为什么是 d o u t × d i n {d_{out}\times d_{in}} dout×din,以 W Q W_{Q} WQ 为例,对于模型的输入 x x x,它的通道数是 d i n d_{in} din,维度是 d i n × w × h × b a t c h d_{in}\times w \times h\times batch din×w×h×batch,我们对输入 x x x进行降维处理,即用矩阵 W Q W_{Q} WQ 和 x x x(需要先对 x x x 实施reshape变成二维矩阵)做矩阵乘法:
( d o u t × d i n ) × ( d i n × ( w ∗ h ∗ b a t c h ) ) (d_{out}\times d_{in})\times (d_{in}\times (w *h* batch)) (dout×din)×(din×(w∗h∗batch)) ,
然后再做reshape,从而得到输出的查询矩阵: Q Q Q 的维度为 d o u t × w × h × b a t c h d_{out}\times w \times h\times batch dout×w×h×batch。
注:实际在代码上都是使用卷积层做降维处理,直接用 1 × 1 1\times 1 1×1的卷积核做处理,就可以得到输出,输出的 d o u t d_{out} dout就是卷积核的channel数,这样就避免了很多reshape操作。 -
因为考虑的是一个像素点 i j ij ij在周围一小块区域的被关注的程度,所以取了一个 N k ( i , j ) = { a , b ∣ ∣ a − i ∣ ≤ k / 2 , ∣ b − j ∣ ≤ k / 2 } \mathcal{N}_{k}(i, j)=\{a, b|| a-i|\leq k / 2,| b-j \mid \leq k / 2\} Nk(i,j)={a,b∣∣a−i∣≤k/2,∣b−j∣≤k/2}
N k ( i , j ) \mathcal{N}_{k}(i, j) Nk(i,j) 就是一个区域,和卷积核一样。
比如现在令 k = 3 , i = 2 , j = 2 k=3,i=2,j=2 k=3,i=2,j=2,所以 N k ( i , j ) = { a , b ∣ ∣ a − 2 ∣ ≤ 1.5 , ∣ b − 2 ∣ ≤ 1.5 } = { ( 1 , 1 ) , ( 1 , 2 ) , ( 1 , 3 ) , ( 2 , 1 ) , ( 2 , 2 ) , ( 2 , 3 ) , ( 3 , 1 ) , ( 3 , 2 ) , ( 3 , 3 ) } \mathcal{N}_{k}(i, j)=\{a, b|| a-2|\leq 1.5, \mid b-2 \mid \leq 1.5\} =\{(1,1),(1,2),(1,3),(2,1),(2,2),(2,3),(3,1),(3,2),(3,3)\} Nk(i,j)={a,b∣∣a−2∣≤1.5,∣b−2∣≤1.5}={(1,1),(1,2),(1,3),(2,1),(2,2),(2,3),(3,1),(3,2),(3,3)} -
q i j T k a b q_{ij}^Tk_{ab} qijTkab的矩阵乘法操作—— q i j q_{ij} qij就是查询像素矩阵中位置为 i j ij ij的像素向量,它由一个像素点 i j ij ij在所有通道数上的那个值组成,所以对于每个 b a t c h batch batch, q i j q_{ij} qij 的维度就是 d o u t × 1 × 1 d_{out}\times 1 \times 1 dout×1×1,同理 k a b k_{ab} kab 的维度就是 d o u t × k × k d_{out}\times k \times k dout×k×k 。
那么 q i j T k a b q_{ij}^Tk_{ab} qijTkab就是(先reshape把尺寸长×宽变成一个维度):
( ( 1 ∗ 1 ) × d o u t ) × ( d o u t × ( k ∗ k ) ) ((1 * 1)\times d_{out})\times (d_{out}\times (k* k )) ((1∗1)×dout)×(dout×(k∗k)),然后经过 s o f t m a x softmax softmax处理,最终得到的就是 1 × ( k ∗ k ) 1\times (k*k) 1×(k∗k)。 -
与值元素 v a b v_{ab} vab再做矩阵乘法的操作——其实上一步得到的就相当于一个卷积核,这一步就相当于一个卷积操作。只不过根据论文里的实现方式可以进行如下描述:因为 v a b v_{ab} vab的维度是 d o u t × k × k d_{out}\times k \times k dout×k×k (这里也是对于每个 b a t c h batch batch而言的),先reshap成 ( k ∗ k ) × d o u t (k*k)\times d_{out} (k∗k)×dout,然后与 v a b v_{ab} vab 做矩阵乘法,就得到了最终结果: 1 × d o u t 1\times d_{out} 1×dout。
-
这里的每一个矩阵相乘都是在每个 b a t c h batch batch上操作的,实现的话其实不需要手动遍历 b a t c h batch batch,可以使用torch.bmm()函数,输入就是两个三维的矩阵,三个维度的意义分别为1是batch,2和3是矩阵的长和宽。函数功能顾名思义,在b(batch)上进行mm(matrix multiplication)操作。
相对位置编码
在实际中,使用multiple attention heads来学习输入的多个独立表达,将像素特征 x i j x_{i j} xij 分为 N N N 组 x i j n ∈ R d i n / N x_{i j}^{n} \in \mathbb{R}^{d_{i n} / N} xijn∈Rdin/N, 每个head用不同的变化参数 W Q n , W K n , W V n ∈ R d out / N × d in / N W_{Q}^{n}, W_{K}^{n}, W_{V}^{n} \in R^{d_{\text {out }} / N \times d_{\text {in }} / N} WQn,WKn,WVn∈Rdout /N×din /N 进行single-headed attention计算, 最后将结果concatenate成最终的输出 y i j ∈ R d o u t y_{i j} \in \mathbb{R}^{d_{o u t}} yij∈Rdout 。

公式2中没有使用位置信息,而之前的研究指出相对位置编码能为 self-attention 带来明显的精度提升。因此,使用二维相对位置编码(relative attention),相对注意力首先定义
i
j
ij
ij到每个位置的相对距离
a
b
∈
N
k
(
i
,
j
)
ab∈N_k(i,j)
ab∈Nk(i,j)。 相对距离是跨维度分解的,因此每个元素
a
b
∈
N
k
(
i
,
j
)
ab∈N_k(i,j)
ab∈Nk(i,j) 接收两个距离:行偏移
a
−
i
a-i
a−i 和列偏移
b
−
j
b-j
b−j(见图 4)。 行和列偏移分别与嵌入
r
a
−
i
r_{a-i}
ra−i 和
r
b
−
j
r_{b-j}
rb−j 相关联,每个都具有
1
2
d
o
u
t
\frac 12 d_{out}
21dout 维,然后将行偏移
a
−
i
a-i
a−i 和列偏移
b
−
j
b-j
b−j 的编码进行concatenate成
r
a
−
i
,
b
−
j
r_{a-i, b-j}
ra−i,b−j ,最后将公式2变成公式3的spatial-relative attention。
相对位置编码公式分析
那么
r
a
−
i
,
b
−
j
r_{a-i, b-j}
ra−i,b−j是如何得到的呢,我们在此不用复杂的公式来定义它,根据前人的工作,我们知道这个相对位置编码是可以学习到的,所以我们仅仅使用一组随机数初始化就好了,然后让模型自己学习它。注意:这组随机数应该和Q,K,V的值没有任何关系,只和相对位置有关系。
这里涉及到代码了,简单介绍一下思路,首先要可以定义一个nn.Embedding()或者nn.Parameter()来为位置信息随机编码,原理可以看我的那个文章:nn.Embedding()。
我们这里就以nn.Embedding()为例,当令
k
=
3
,
i
=
2
,
j
=
2
k=3,i=2,j=2
k=3,i=2,j=2,所以
N
k
(
i
,
j
)
=
{
a
,
b
∣
∣
a
−
2
∣
≤
1.5
,
∣
b
−
2
∣
≤
1.5
}
=
{
(
1
,
1
)
,
(
1
,
2
)
,
(
1
,
3
)
,
(
2
,
1
)
,
(
2
,
2
)
,
(
2
,
3
)
,
(
3
,
1
)
,
(
3
,
2
)
,
(
3
,
3
)
}
\mathcal{N}_{k}(i, j)=\{a, b|| a-2|\leq 1.5, \mid b-2 \mid \leq 1.5\} =\{(1,1),(1,2),(1,3),(2,1),(2,2),(2,3),(3,1),(3,2),(3,3)\}
Nk(i,j)={a,b∣∣a−2∣≤1.5,∣b−2∣≤1.5}={(1,1),(1,2),(1,3),(2,1),(2,2),(2,3),(3,1),(3,2),(3,3)} 。即每个kernel的大小为3×3,那么我们先实例化nn.Embedding()
- 令embed = nn.Embedding(3, 1 2 d o u t \frac 12 d_{out} 21dout),用来生成3个维度为 1 2 d o u t \frac 12 d_{out} 21dout 的嵌入向量以供编码。
- 然后,根据论文里说的,行偏移和列偏移是分开计算并且编码然后再concatenate得到最终的编码信息的,所以我们现在先看横坐标,用
(
a
,
b
)
(a,b)
(a,b) 的每个横坐标
a
a
a 去减
i
(
=
2
)
i( =2 )
i(=2),得到的结果就是:
[-1, -1, -1, 0, 0, 0, 1, 1, 1] ,因为在用nn.Embedding()编码时,这个位置信息实际上充当的索引值,然后再对每个元素加上 i n t ( k 2 ) int (\frac k2) int(2k),这里就是加1,得到 [0, 0, 0, 1, 1, 1, 2, 2, 2] ,这样这些值都是大于等于0的整数了。 - 接下来就可以刚刚实例化的 embed 来是生成行编码信息了。
同理我们可以得到列编码信息。
然后再进行concatenate,就可以生成最终的相对位置信息。 - 注意把这个位置编码添加上模型的参数model.parameters()中,这样就可以训练了。
计算量分析
同时考虑query和key的内容间的相似性以及相对位置,相对于绝对位置编码,使用相对位置信息从某种角度来说变相地维持了类似卷积的平移不变性。另外, 与使用典型的卷积层相比,注意力层的计算成本随着注意力区域的增加增长很慢,只稍微 d i n d_{i n} din 和 d out d_{\text {out }} dout 有关。例如,如果 d i n = d out d_{i n}=d_{\text {out }} din=dout =128,k=3 的卷积层与 k=19 的注意力层具有差不多相同的计算成本。
这里再解释一下:
我们这里使用MACC作为评估计算成本的指标,MACC的意思是:乘法累加运算,也称为MADD,就是把一次乘法和一次加法合起来看成一次。
这里简单定性分析一下:
卷积层
- 对于卷积层,生成的单通道 feature map 中每个像素位置 i j ij ij都是经过了 K × K × C h a n n e l i n K × K × Channel_{in} K×K×Channelin 次计算
- 而一个feature map的尺寸为
H
o
u
t
×
W
o
u
t
H_{out} × W_{out}
Hout×Wout所以单通道 feature map 的计算就为:
K × K × C h a n n e l i n × H o u t × W o u t K × K × Channel_{in} × H_{out} × W_{out} K×K×Channelin×Hout×Wout。 - 生成的feature map 共有
C
h
a
n
n
e
l
o
u
t
Channel_{out}
Channelout个通道,那么这个卷积层的计算量就为:
K × K × C h a n n e l i n × C h a n n e l o u t × H o u t × W o u t K × K × Channel_{in} ×Channel_{out} × H_{out} × W_{out} K×K×Channelin×Channelout×Hout×Wout
注意力层
- 首先是使用卷积层生成了三个矩阵,这个过程就是卷积层的过程,但是使用是
1
×
1
1 \times 1
1×1的卷积层,所以一共的计算量就是:
3 × 1 × 1 × C h a n n e l i n × C h a n n e l o u t × H o u t × W o u t 3×1 × 1 × Channel_{in} ×Channel_{out} × H_{out} × W_{out} 3×1×1×Channelin×Channelout×Hout×Wout。 - 然后要进行注意力的计算,我们知道每一个
q
i
j
q_{ij}
qij 都会生成一个
y
i
j
y_{ij}
yij,而生成的过程是一个
q
i
j
q_{ij}
qij向量和两块大小为
K
×
K
K×K
K×K的区域矩阵(这个矩阵的每一个元素都是一个维度为
d
o
u
t
的向量
d_{out}的向量
dout的向量)的每一个向量做计算,那么计算量为
2
×
K
×
K
×
d
o
u
t
2×K×K×d_{out}
2×K×K×dout,因为输出的尺寸为
H
o
u
t
×
W
o
u
t
H_{out} × W_{out}
Hout×Wout,所以注意力的计算量共有:
2 × K × K × d o u t × H o u t × W o u t 2×K×K×d_{out}×H_{out} × W_{out} 2×K×K×dout×Hout×Wout - 把两者相加,关于注意力层的计算量就为:
3 × 1 × 1 × C h a n n e l i n × C h a n n e l o u t × H o u t × W o u t + 2 × K × K × c h a n n e l o u t × H o u t × W o u t 3 × 1 × 1 × Channel_{in} ×Channel_{out} × H_{out} × W_{out} +2×K×K×channel_{out}×H_{out} × W_{out} 3×1×1×Channelin×Channelout×Hout×Wout+2×K×K×channelout×Hout×Wout
注: c h a n n e l o u t = d o u t channel_{out} =d_{out} channelout=dout - 那么看看论文给的例子:
k=3的卷积层计算量为:
3 × 3 × 128 × 128 × H o u t × W o u t 3×3×128×128× H_{out} × W_{out} 3×3×128×128×Hout×Wout
k=19的注意力层计算量为:
3 × 128 × 128 × H o u t × W o u t + 2 × 19 × 19 × 128 × H o u t × W o u t 3×128×128× H_{out} × W_{out}+2×19×19×128×H_{out} × W_{out} 3×128×128×Hout×Wout+2×19×19×128×Hout×Wout
两者做一下除法:
3 × 3 × 128 × 128 × H o u t × W o u t 3 × 128 × 128 × H o u t × W o u t + 2 × 19 × 19 × 128 × H o u t × W o u t = 3 × 3 × 128 3 × 128 × + 2 × 19 × 19 ≈ 1.04 \frac {3×3×128×128× H_{out} × W_{out}} {3×128×128× H_{out} × W_{out}+2×19×19×128×H_{out} × W_{out}}=\frac {3×3×128} {3×128×+2×19×19} ≈1.04 3×128×128×Hout×Wout+2×19×19×128×Hout×Wout3×3×128×128×Hout×Wout=3×128×+2×19×193×3×128≈1.04
果然差不多。。。。。
剩下的看论文应该啥问题了,就不写了,如有写错,再更正。















 7144
7144











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









