







 本文通过分析HS300成分股2024年3月24日的数据,探讨了PE因子的离群值处理、市值中性化和标准化策略。作者使用Python的akshare库获取数据,并通过分位数去极值、回归分析和Z-score标准化方法优化数据,以提高因子分析的准确性。
本文通过分析HS300成分股2024年3月24日的数据,探讨了PE因子的离群值处理、市值中性化和标准化策略。作者使用Python的akshare库获取数据,并通过分位数去极值、回归分析和Z-score标准化方法优化数据,以提高因子分析的准确性。
1 概要
本文主要研究对PE因子的离群值处理、中性化和标准化,以HS300成分股2024年3月24日的数据为例,数据来源于akshare数据库,本文代码可在python3环境下复现。
2 数据来源
以HS300成分股2024年3月24日的数据为例,数据来源于akshare数据库,获取方法详见akshare数据字典
2.1 数据展示
import akshare as ak
index_stock_info_df=ak.index_stock_cons_sina("000300")
index_stock_info_df.head()
 获取沪深300成分股代码列表
获取沪深300成分股代码列表
# 获取沪深300指数成分股代码列表
def get_stock_codes(index_code):
index_stock_info_df=ak.index_stock_cons_sina(index_code)
codes=index_stock_info_df['code']
codes=codes.tolist()
return codes
code_list = get_stock_codes("000300")
code_list

获取动态市盈率(TTM)和市值
import pandas as pd
PE_TTM_df = pd.DataFrame(columns = ['code','date','pe_ttm','mv'])
for code in code_list:
stock_zh_valuation_baidu_df1 = ak.stock_zh_valuation_baidu(symbol=code, indicator="市盈率(TTM)", period="近一年").iloc[-1]
stock_zh_valuation_baidu_df2 = ak.stock_zh_valuation_baidu(symbol=code, indicator="总市值", period="近一年").iloc[-1]
new_row = {'code':code,
'date':stock_zh_valuation_baidu_df1['date'],
'pe_ttm':stock_zh_valuation_baidu_df1['value'],
'mv':stock_zh_valuation_baidu_df2['value']}
PE_TTM_df = PE_TTM_df.append(new_row, ignore_index=True)
PE_TTM_df.set_index('code',inplace=True)
PE_TTM_df.head()
2.2 市盈率描述性统计分析
PE_TTM_df['pe_ttm'].describe()
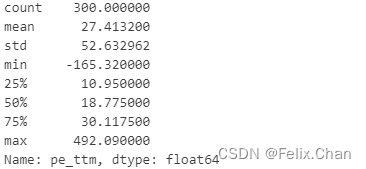
可以看到,市盈率(TTM)标准差高达52.63,最大值为492.09,而75%分位数仅为30.12,说明数据中的离群值对整体数据的分布影响较大,因此离群值处理和标准化显得尤为必要。
3 离群值处理
离群值的处理有两种方法:
- 分位数去极值
- 3σ去极值
这里使用分位数去极值
import numpy as np
from scipy.stats.mstats import winsorize
import matplotlib.pyplot as plt
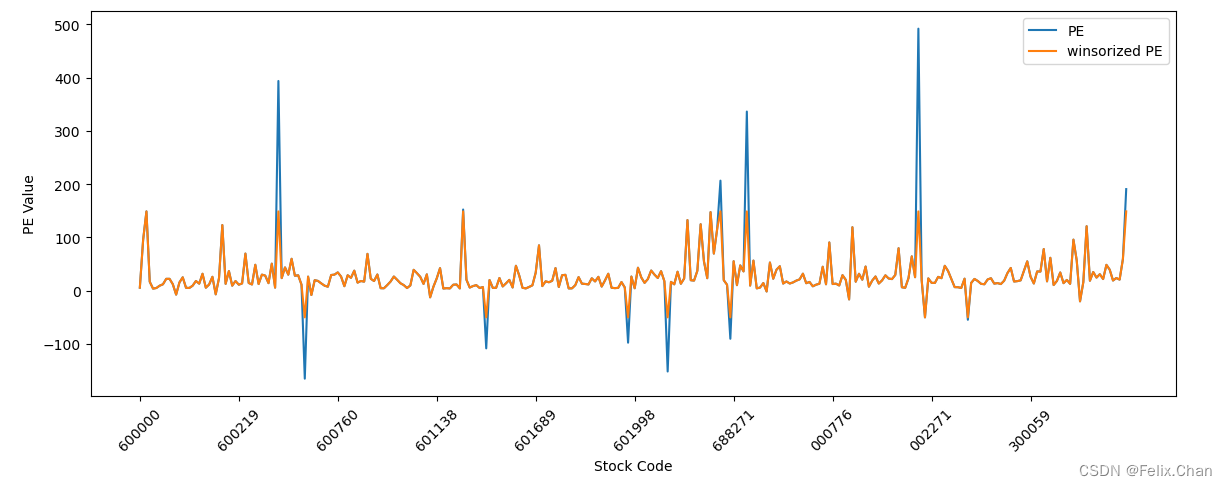
# 去极值winsorize(分位数去极值)
after_winsorize = winsorize(PE_TTM_df['pe_ttm'],limits=[0.02, 0.02])
PE_TTM_df['winsorized PE'] = after_winsorize
# 绘制图表
plt.figure(figsize=(14, 5))
plt.plot(PE_TTM_df.index, PE_TTM_df['pe_ttm'], label='PE')
plt.plot(PE_TTM_df.index, PE_TTM_df['winsorized PE'], label='winsorized PE')
plt.xlabel('Stock Code')
plt.ylabel('PE Value')
plt.xticks(PE_TTM_df.index[::30],rotation=45)
plt.legend()
plt.show()
4 市值中性化
中性化分为市值中性化和行业中性化,这里仅研究市值中性化。
市值中性化是指排除因子数据中市值对因子的影响,使得因子更能够反映公司内在的特征。这可以通过对因子数据进行回归分析,并使用残差项来实现。通常,你会对因子数据与市值进行回归,然后使用回归的残差作为市值中性化后的因子。
import statsmodels.api as sm
# 市值中性化
X = PE_TTM_df['mv']
X = sm.add_constant(X)
y = PE_TTM_df['winsorized PE']
model = sm.OLS(y, X)
result = model.fit()
residual_market_cap = result.resid
PE_TTM_df['MV_Neutralized PE'] = residual_market_cap
# 绘制图表
plt.figure(figsize=(14, 5))
plt.plot(PE_TTM_df.index, PE_TTM_df['winsorized PE'], label='winsorized PE')
plt.plot(PE_TTM_df.index, PE_TTM_df['MV_Neutralized PE'], label='MV_Neutralized PE')
plt.xlabel('Stock Code')
plt.ylabel('PE Value')
plt.xticks(PE_TTM_df.index[::30],rotation=45)
plt.legend()
plt.show()

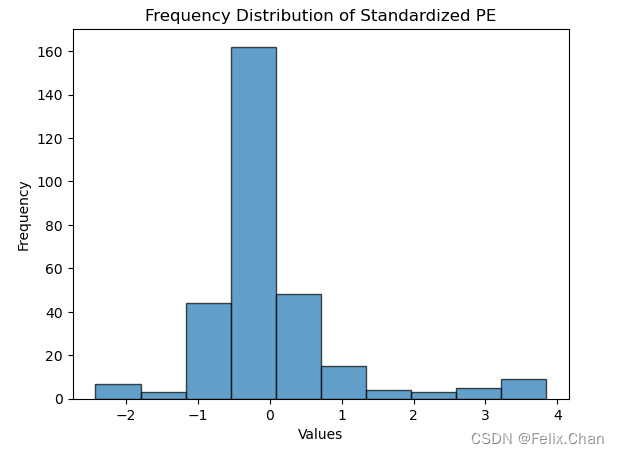
5 标准化
在进行因子分析之前,通常需要对因子数据进行标准化,以消除因子值之间的量纲差异。标准化可以使得不同因子之间的比较更具有可比性。常见的标准化方法包括Z-score标准化、最大最小值标准化等。这里使用Z-score标准化。
from sklearn.preprocessing import StandardScaler
# 标准化
# 创建 StandardScaler 对象
scaler = StandardScaler()
# 对数据进行标准化
standardized_pe = scaler.fit_transform(PE_TTM_df[['MV_Neutralized PE']])
PE_TTM_df['standardized PE'] = standardized_pe
# 绘制图表
plt.hist(standardized_pe, bins=10, edgecolor='black', alpha=0.7)
plt.title('Frequency Distribution of Standardized PE')
plt.xlabel('Values')
plt.ylabel('Frequency')
plt.show()
















 2274
2274











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











