







情感计算入门
- 情感计算介绍
- 情感计算的两大分类
- MER2023方法赏析
- Label Distribution Adaptation for Multimodal Emotion Recognition with Multi-label Learning[^2]
- Learning Aligned Audiovisual Representations for Multimodal Sentiment Analysis[^3]
- Semi-supervised Multimodal Emotion Recognition with Consensus Decision-making and Label Correction[^4]
- IMPROVING MULTI-MODAL EMOTION RECOGNITION USING ENTROPY-BASED FUSION AND PRUNING-BASED NETWORK ARCHITECTURE OPTIMIZATION[^5]
情感计算介绍
情感计算是一种涉及人工智能和计算机科学的跨学科领域,旨在让计算机能够理解、识别和模拟人类的情感和情感状态。该领域结合了自然语言处理、机器学习、心理学和认知科学等多个学科的理论和方法,以开发出能够感知、理解和回应人类情感的智能系统。
情感计算的目标包括但不限于:
- 情感识别:通过分析文本、语音、图像等数据来识别和理解人类的情感状态,如喜怒哀乐等。
- 情感生成:基于情感模型和算法,使计算机能够生成具有情感色彩的文本、音频和图像等内容,以更好地与人类进行交流和互动。
- 情感分析:通过对大规模数据的分析,揭示和理解人类在社交媒体、网络论坛等平台上的情感倾向和情感变化,以便做出相关决策。
- 情感增强:将情感计算技术应用于虚拟现实、增强现实等领域,提升用户体验和交互效果,使系统更加智能化和人性化。
情感计算的发展对于改善人机交互、提升智能系统的人性化水平以及促进情感健康等方面具有重要意义。
情感计算目前研究现状

由图中1 我们可以看到情感计算的发文量是呈现逐年增加的状态(2022年下降的原因为在统计时统计窗口未记录全年的数据)。并且在1文中也提及中国是目前发文量及第一作者量最大的国家。可以说情感计算撑起了中国神经网络工作的一片天。
情感对于计算机的定义
情感对于计算机的定义和计算机系统如何理解、模拟和响应人类的情感和情绪密切相关。通常情感可以被视为人类对于外界刺激的主观体验,包括但不限于喜怒哀乐等情绪状态。在计算机科学领域,情感通常被认为是一种抽象概念,其主要通过文本、语音、图像等数据表现出来。情感对于计算机的定义涉及到计算机系统在理解、模拟和响应人类情感方面的能力,这是情感计算领域的核心内容之一。
情感模型
对于情感进行分析,需要进行量化的操作。而量化在现实世界中的体现则是离散和连续的表示。离散和连续的数据需要采取不同的模型表示,在情感的量化模型中则分为了两大类:离散情感模型和维度情感模型。然而在区分二者时我们也需要时刻提醒自己:离散和维度情感模型虽然是不同的方法,但是连续之中是可以提取离散的数据,而离散的数据通过一定的规则可以变成连续的数据。这在MER2023比赛中的一篇获奖文章中得以一定体现,下文也会对于这篇文章进行说明。
离散情感模型
离散情感模型是一种用于情感分析的模型,通常基于情感词典或情感词库构建。这种模型将情感表达为离散的类别,如积极、消极、中性等。其工作原理是通过对文本中出现的情感词汇进行计数,并根据这些情感词的权重来判断文本的情感倾向。离散情感模型通常较为简单,易于实现,并且不需要大量的标注数据进行训练。然而,它也存在一些局限性,例如对于文本中的上下文信息和语义复杂性处理能力较弱,容易受到语境影响,无法很好地适应各种不同的情境和语言风格。因此,在实际应用中,离散情感模型常常与其他模型结合使用,以提高情感分析的准确性和可靠性。
维度情感模型
维度情感模型是一种用于情感分析的模型,相较于离散情感模型,它更加细致地描述了情感的多个维度,而不仅仅局限于简单的积极、消极、中性等离散类别。这种模型通常将情感表示为在多个维度上的数值,例如喜悦、悲伤、愤怒、恐惧等维度。相比于离散情感模型,维度情感模型更加细致地描述了情感的不同方面或维度,如喜悦、悲伤、愤怒等。情感在维度情感模型中通常表示为在多个维度上的连续值,而不仅仅是简单的离散类别。这使得模型能够更准确地捕捉情感的变化和程度。此外,维度情感模型常常将情感表示为在一个多维情感空间中的坐标点,其中每个维度代表一个情感维度,通过这些坐标可以准确地描述出不同的情感特征。
情感计算的两大分类
单模态情感计算
单模态情感计算是指利用单一类型的数据(如文本、语音、图像和生理信号)来识别和分析情感状态的技术。它在情感计算领域中具有重要的地位,尽管与多模态情感计算相比略显简单,但它为情感分析提供了坚实的理论和技术基础。
-
文本情感计算主要依赖自然语言处理(NLP)技术,通过分析文本中的词汇、语法、句子结构以及上下文关系来识别出文本中的情感。常用的方法包括词典法和机器学习法。词典法基于情感词典,如SentiWordNet,通过匹配词典中的情感词汇来判断情感。机器学习法则使用有标注的情感数据集训练模型,如朴素贝叶斯和支持向量机(SVM)等。随着深度学习的发展,深度学习法也被广泛应用于文本情感计算中,利用卷积神经网络(CNN)、循环神经网络(RNN)以及注意力机制等进行情感分类,从而大幅提高了情感识别的准确性。
-
语音情感计算通过分析语音信号中的各种特征,如音调、语速、音量和节奏等,来判断说话者的情感状态。特征提取是语音情感计算的关键步骤,通过提取语音信号中的基本特征,如梅尔频率倒谱系数(MFCC)、音高和能量等,可以有效捕捉情感信息。传统的机器学习方法,如高斯混合模型(GMM)和隐马尔可夫模型(HMM),在语音情感识别中取得了一定的成功。近年来,随着深度学习的迅猛发展,深度神经网络(DNN)和长短期记忆网络(LSTM)等方法被引入语音情感计算领域,显著提升了情感识别的效果。
-
图像情感计算主要通过分析图像中的面部表情和姿态等来识别情感。面部表情分析是图像情感计算的重要手段,通过检测和分析面部特征点,可以识别出面部表情及其对应的情感状态。传统的机器学习方法,如支持向量机(SVM)和随机森林等,在图像情感分类中表现出色。随着计算机视觉技术的进步,卷积神经网络(CNN)被广泛应用于图像情感计算中,通过深度学习模型进行特征提取和情感分类,显著提高了情感识别的准确率。
-
生理信号情感计算通过分析人体的生理信号(如心电图、脑电图、皮肤电反应等)来识别和分析情感状态,利用人体在不同情感状态下的生理反应差异,通过传感器采集生理信号并进行分析,以判断个体的情感状态。常见的生理信号包括心电图(ECG)、脑电图(EEG)、皮肤电反应(GSR)、呼吸频率和血氧饱和度等。心电图(ECG)是最常用的生理信号之一,它通过记录心脏活动的电信号来反映心脏的健康状态和情感状态。在不同情感状态下,心率和心率变异性(HRV)会发生显著变化。例如,在压力状态下,心率通常会增加,而在放松状态下,心率则会下降。通过分析心率和心率变异性,可以有效识别个体的情感状态。脑电图(EEG)记录大脑的电活动,是研究情感与大脑活动关系的重要工具。不同情感状态下,大脑的电活动模式会有所不同。例如,愉悦和放松的情感通常与α波(8-13 Hz)的增加有关,而压力和焦虑的情感则与β波(13-30 Hz)的增加有关。通过分析EEG信号,可以识别出个体的情感状态,并揭示情感与大脑活动之间的关系。生理信号情感计算在实际应用中具有广泛的前景。例如,在心理健康监测领域,通过监测个体的生理信号变化,可以评估其心理健康状态,并及时提供干预措施。在智能穿戴设备中,通过整合心率、EEG和GSR等传感器,可以实现实时情感监测和反馈,帮助用户更好地管理情感和压力。在人机交互领域,通过识别用户的生理信号变化,可以提高系统对用户情感状态的感知能力,从而提供更加个性化和自然的交互体验。
单模态情感计算在实际应用中具有广泛的应用领域。社交媒体分析是一个重要的应用场景,通过分析用户发布的文本、语音或图像,可以了解用户的情感趋势和热点话题,从而帮助企业和研究人员更好地理解社交网络中的情感动态。客户服务领域也广泛应用了单模态情感计算,通过识别客户在交互过程中的情感状态,可以提供更加个性化和及时的服务,提高客户满意度。心理健康监测是另一个重要的应用领域,通过分析用户的语音或文本,可以评估其心理健康状态,及时发现和干预潜在的心理问题。在人机交互中,情感识别技术的应用也越来越广泛,在聊天机器人和虚拟助手等系统中,通过识别用户情感,提高了交互体验,使得人机交互更加自然和人性化。
综上所述,单模态情感计算尽管方法较为单一,但在情感计算领域中发挥着不可替代的作用。它为多模态情感计算奠定了坚实的基础,通过深入研究和应用单一数据类型的情感识别技术,推动了情感计算领域的不断发展和进步。
多模态情感计算
多模态情感计算是指综合利用多种类型的数据(如文本、语音、图像和生理信号)来识别和分析情感状态的技术。相比于单模态情感计算,多模态情感计算能够通过融合多种数据源的信息,提高情感识别的准确性和鲁棒性。这种方法在情感计算领域越来越受到关注。然而如何组合多模态并得到准确的结果则成为了难点。目前在模态融合方面,多模态情感计算可以分为模型无关和模型依赖两种路线。
模型无关
模型无关的方法通常在特征级或决策级进行融合,这些方法不依赖特定的情感计算模型,而是通过简单的操作将来自不同模态的数据或结果进行组合。例如,特征级融合方法会将不同模态的特征向量进行拼接或通过某种变换进行整合,然后输入到一个统一的情感识别模型中进行训练和预测。决策级融合方法则先对各个模态的情感进行单独识别,再通过加权平均、投票等策略综合各模态的识别结果,得到最终的情感判断。模型无关的方法具有灵活性和可扩展性,但可能在处理不同模态间复杂关系时存在不足。下面是对特征级融合和决策级融合以及混合式融合的具体介绍。
- 特征级融合:将来自不同模态的数据特征进行提取和融合,然后输入到一个统一的情感分类模型中。这种方法可以充分利用各个模态的信息,但需要解决不同模态数据的对齐和同步问题。
- 决策级融合:先对每种模态的数据分别进行情感识别,然后将各个模态的情感识别结果进行融合,以得到最终的情感判断。这种方法的优点是可以分别优化每个模态的情感识别模型,但需要设计合理的融合策略来综合各个模态的识别结果。
- 混合式融合:是一种结合特征级融合和决策级融合的方法,这种方法旨在综合两者的优点,提高情感识别的准确性和鲁棒性。混合式融合通过在不同阶段结合特征级融合和决策级融合,达到更佳的情感识别效果。首先对各个模态的数据进行特征提取,然后将部分或全部模态的特征进行融合。这样可以在特征层面上进行初步的信息整合,捕捉不同模态之间的相关性。在初级特征融合之后,分别对每个模态的数据进行单独处理。此时可以应用专门针对每个模态的情感识别模型,进一步提取更高级的特征或直接进行情感分类。将各个模态处理后的高级特征进行再次融合。这一步骤可以进一步综合不同模态的信息,提高情感识别的深度和广度。在最终情感识别阶段,综合各个模态的情感分类结果进行决策级融合。通过加权平均、投票机制等策略,将各个模态的识别结果进行整合,得到最终的情感判断。
模型依赖
模型依赖的方法则通过深度学习等技术,构建专门用于多模态情感计算的端到端模型。这类方法能够更好地捕捉不同模态数据间的复杂交互关系,通常表现出更高的识别精度。常见的模型依赖方法包括:
-
多模态深度神经网络:通过设计多分支或多通道神经网络,各分支分别处理不同模态的数据,然后在网络的某一层进行特征融合,从而实现多模态信息的综合利用。例如,卷积神经网络(CNN)可以处理图像数据,循环神经网络(RNN)处理语音或文本数据,最后将这些特征融合并输入到全连接层进行情感分类。
-
注意力机制:在多模态情感计算中,注意力机制可以动态地分配不同模态的重要性权重,使模型能够更好地捕捉关键情感信息。例如,基于注意力机制的Transformer模型可以同时处理多种模态的数据,通过自注意力机制在不同模态之间进行信息交互和融合,从而提高情感识别的效果。
-
对抗训练:通过生成对抗网络(GAN)等技术,利用对抗训练的方式生成多模态情感数据,进一步提升模型的鲁棒性和泛化能力。对抗训练能够在多模态情感计算中有效应对数据不足和噪声干扰的问题。
无论是模型无关的方法还是模型依赖的方法,多模态情感计算的核心目标都是通过综合利用不同模态的数据,提高情感识别的准确性和鲁棒性。随着深度学习和计算能力的不断进步,未来的多模态情感计算将会在模型设计、数据融合和应用场景等方面实现更多的创新和突破,进一步推动情感计算技术的发展和应用。
MER2023方法赏析
Label Distribution Adaptation for Multimodal Emotion Recognition with Multi-label Learning2
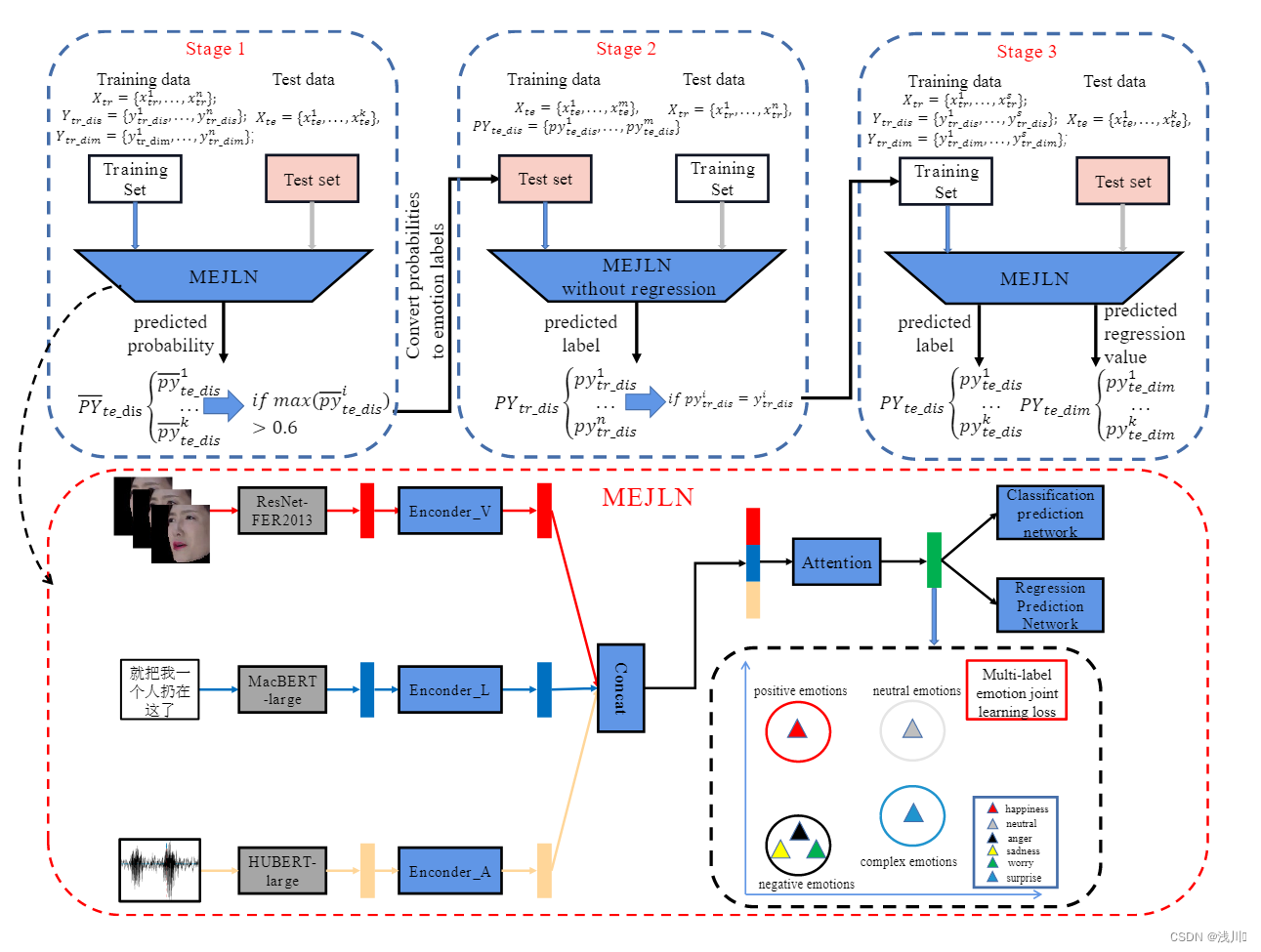
原文中图的解释为:(a)本研究中使用的训练网络是一个多标签联合学习网络(MEJLN)。(b) 在第 1 阶段,MEJLN _stage1 模型使用训练数据集进行训练。随后,从测试数据集中选择高置信度的样本。© 第 2 阶段包括使用第 1 阶段选择的测试数据集样本训练 MEJLN _stage2 模型,目的是选择与测试集特征分布对齐的训练集样本。(d) 在第 3 阶段,从第 2 阶段中选择的训练数据集样本用于训练最终模型,称为 MEJLN _Final。
本文具体实施方法:先使用一个模型训练训练集,随后用模型去预测测试集的离散和维度数据。然后挑选部分测试集数据去训练一个新模型得到离散新标签,挑选出与ground truth相同的训练集作为新训练集。简而言之过程为:
训练集->模型1、模型1->测试集、测试集中准确的一部分->模型2、模型2->训练集得到新离散标签、新离散标签<->ground truth(挑选出一部分正确预测的训练集数据)
随后本文提及的第二个亮点为提出的新的loss function:分为四类:消极、积极、中性、复杂。由于新类别中的离散情绪和价相一致,因此模型中的共享特征分布将被转换为离散情绪和价相一致的空间,使模型更容易捕获离散情绪和维度情绪之间的相关性。这就和之前提及的离散维度和连续维度相对应。
Learning Aligned Audiovisual Representations for Multimodal Sentiment Analysis3
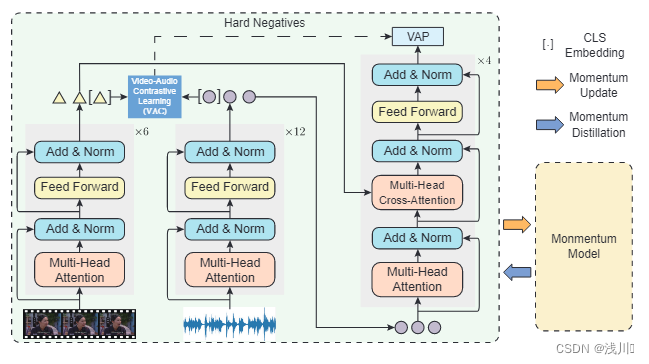
VAT的说明。它包括一个视觉编码器、一个音频编码器和一个多模态编码器(即查询模型)。为了便于融合,模型引入了一个视频-音频对比损失,它对齐视频-音频对的单峰表示。通过利用通过对比相似度获得的批内硬底片,使用视频-音频匹配损失来捕获视频和音频之间的多模态交互。具体来说,VAT 采用 MoCostyle 对比学习框架,其中动量模型具有与查询模型相同的架构,并通过查询模型的基于动量的移动平均值进行更新。此外,为了增强模型对噪声数据的鲁棒性,作者结合了使用动量模型生成的伪目标,该模型在训练期间作为额外的监督形式。
Semi-supervised Multimodal Emotion Recognition with Consensus Decision-making and Label Correction4
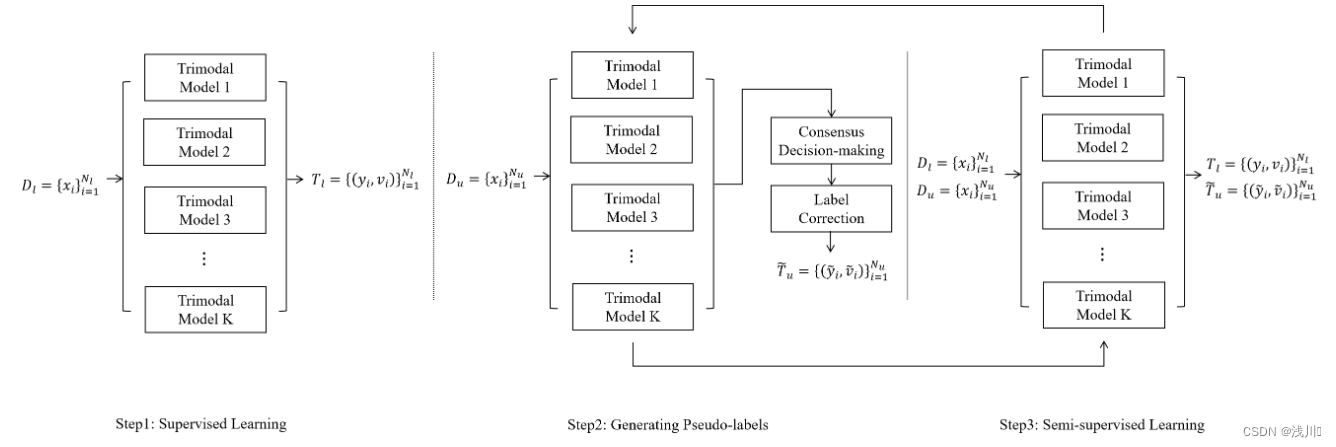
原文中图的解释为:
- Supervised Learning:首先使用具有三模态输入的传统监督学习来训练具有强大性能的初始模型。这一步有助于为后续阶段建立基础。
- Generating Pseudo-labels:利用共识决策和标签校正方法为未标记的数据生成可靠的伪标签。共识决策结合了来自多个初始模型的预测来获得高置信度伪标签。此外,训练一系列二元分类模型来纠正伪标签中的错误,确保其准确性和可靠性。
- Semi-supervised Learning:继续使用标记数据和生成的伪标记数据以有监督的方式训练模型。需要注意的是,伪标签的生成和半监督学习可以迭代执行,从而进一步细化和提高模型的准确性和鲁棒性。
本文通过结合共识决策和标签校正方法,通过半监督学习框架提出了一种新的方法。首先,在三模态输入数据上使用监督学习来建立稳健的初始模型。其次,利用共识决策和标签校正方法为未标记的数据生成可靠的伪标签。随后,使用标记和未标记的数据以有监督的方式训练模型。此外,可以迭代生成伪标签和半监督学习的过程,以进一步细化模型。
共识决策
共识决策简而言之即是用多个模型模型对未标签数据进行预测,只挑选所有模型一致的数据,而不一致的则被舍去不采用。
标签校正
标签效验的作用是为了消除噪声(应该主要是未标记中的噪声)。标签纠正的过程简而言之为多个二分类:和共识决策一样需要用到多个模型。假定模型一识别愤怒,模型二识别快乐等。首先将数据L用模型一识别,获得愤怒标签的数据和剩下的数据L1;随后将L1用模型二识别为快乐标签的数据和剩下的数据L2;以此类推直到全部识别完毕。
IMPROVING MULTI-MODAL EMOTION RECOGNITION USING ENTROPY-BASED FUSION AND PRUNING-BASED NETWORK ARCHITECTURE OPTIMIZATION5
前置知识-彩票假说
彩票假说为在神经网络中存在一个子网络在发挥着主要作用,通过一个mask限制参数的发挥(冻结参数)可以简化网络的迭代。加快网络的训练。
方法框架
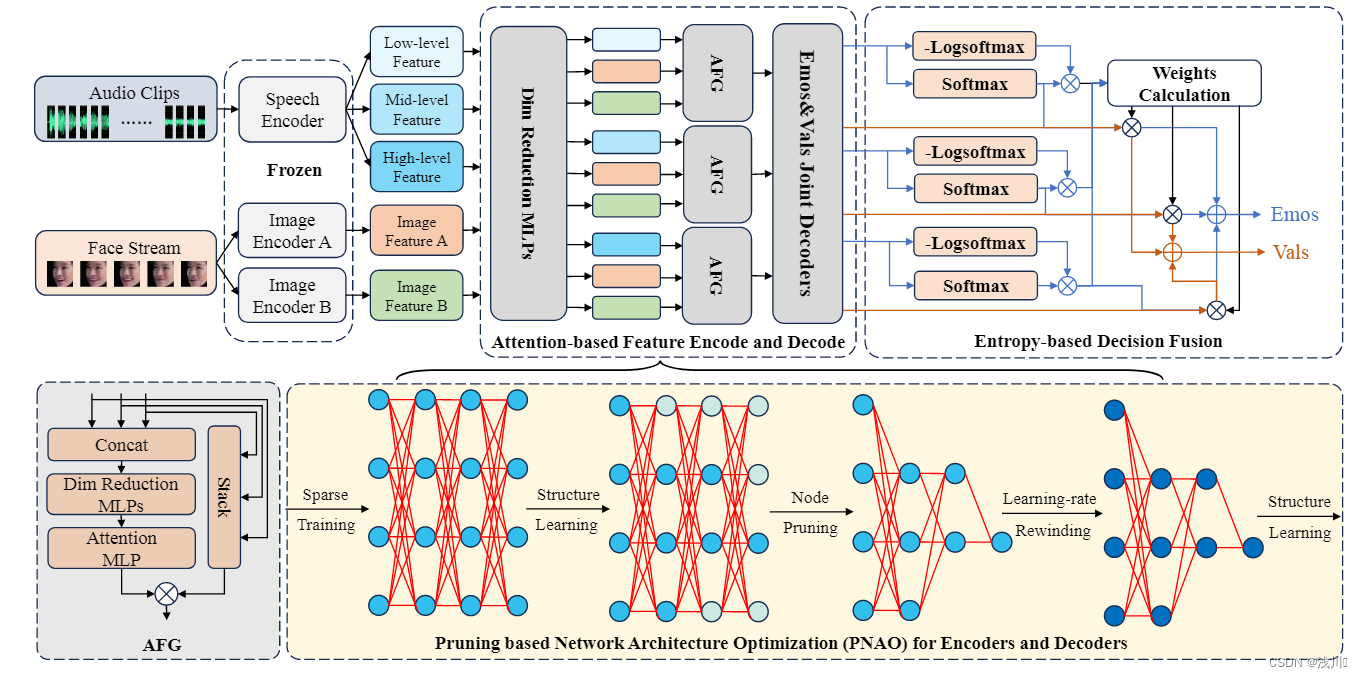
在作者提出的架构中,首先其从原始特征空间中预训练模型提取声音和视觉表示。具体来说,从HUBERT-large的不同层中提取低级、中级和高级声学表示。对于视觉部分,使用预训练的 MANet 和 ResNet 来获得互补的视觉表示。然后,如图 所示,在 AFG 中分别将三个不同的声学表示与视觉表示相结合,以获得不同级别的声学视觉统一表示。之后,在联合解码器中使用不同的融合表示来预测情绪和效价的多标签。考虑到不同层次的融合表示包含各种声学信息。利用不同层次的融合特征的不同情感分类器可以在判断上产生不同的置信水平。一些分类器可以提供高置信度预测,而其他分类器可能提供较低的置信度判断,因为无法根据它们利用的声学信息有效地区分相似的情绪。为了获得更准确的判断,作者提出了一种基于不同情感分类器预测的置信度驱动方法来获得联合预测,如图所示,根据情感标签后验概率预测的信息熵来计算不同预测的置信水平得分。PNAO则是作者提出的剪枝算法,用于简化模型。
Lian H, Lu C, Li S, et al. Label Distribution Adaptation for Multimodal Emotion Recognition with Multi-label Learning[C]//Proceedings of the 1st International Workshop on Multimodal and Responsible Affective Computing. 2023: 51-58. ↩︎
Ding C, Zong D, Li B, et al. Learning Aligned Audiovisual Representations for Multimodal Sentiment Analysis[C]//Proceedings of the 1st International Workshop on Multimodal and Responsible Affective Computing. 2023: 21-28. ↩︎
Tian J, Hu D, Shi X, et al. Semi-supervised multimodal emotion recognition with consensus decision-making and label correction[C]//Proceedings of the 1st International Workshop on Multimodal and Responsible Affective Computing. 2023: 67-73. ↩︎
Wang H, Du J, Dai Y, et al. Improving Multi-Modal Emotion Recognition Using Entropy-Based Fusion and Pruning-Based Network Architecture Optimization[C]//ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2024: 11766-11770. ↩︎

















 2627
2627

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









