






 文章介绍了钢板表面缺陷对产品质量的影响,传统检测方法的局限性,以及机器视觉和深度学习(Resnet18)在检测中的应用。通过数据预处理、特征提取和图像分类,利用Resnet网络提高检测精度和效率。文章强调了深度学习在自动化和质量控制中的潜力和优势。
文章介绍了钢板表面缺陷对产品质量的影响,传统检测方法的局限性,以及机器视觉和深度学习(Resnet18)在检测中的应用。通过数据预处理、特征提取和图像分类,利用Resnet网络提高检测精度和效率。文章强调了深度学习在自动化和质量控制中的潜力和优势。
1 问题背景
1.1 问题背景
钢板的表面质量是钢板最为重要的质量因素之一,表面质量的优劣直接影响其最终产品的性能与质量。然而在加工过程中,由于原材料、轧制设备和工艺等原因,导致钢板表面出现结疤、裂纹、锟印、刮伤、针眼、磷皮、麻点等不同类型的缺陷[1]。这些缺陷不仅影响产品的外观,而且降低了产品的抗腐蚀性、耐磨性和疲劳强度等性能。
在钢板轧制过程中,钢板表面缺陷的检测是一种简单的重复性、快速、高度集中的工作,给测试人员带来很大的压力,在目视检测过程中,必须降低钢板的移动速度,降低相应的钢板轧制速度,不可避免地降低生产效率,测试人员不可避免地会受到疲劳、情绪、感觉和技术水平的影响,难以达到精确和定量。此外,对缺陷的记忆存储和分析也比较困难。
如何在生产过程中在线检测钢板的表面缺陷,从而控制和提高钢板产品的表面质量,一直是钢铁加工企业非常关注的问题。
1.2 技术简介
钢板表面缺陷检测技术主要分为两类:传统无损检测技术和基于机器视觉的检测技术。
1.2.1 传统无损检测技术
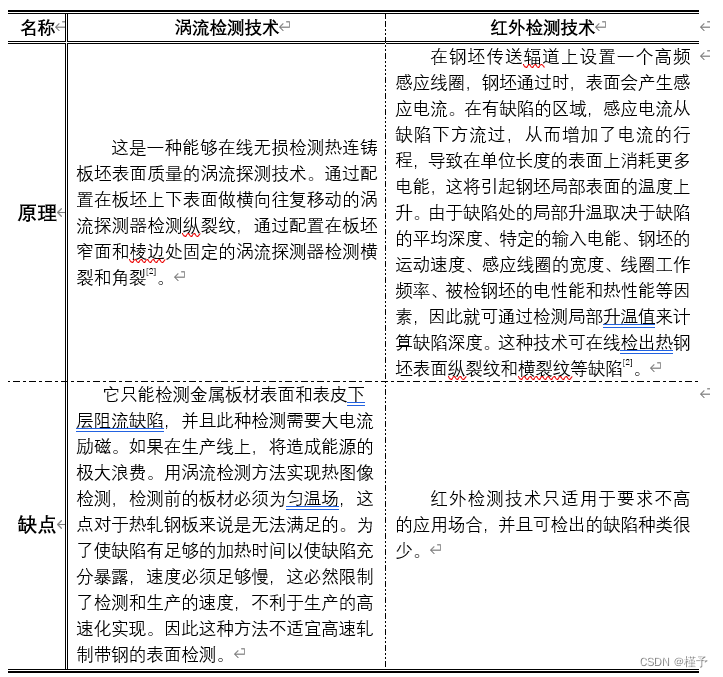
1.2.2 机器视觉检测技术
机器视觉技术的检测机理是表面缺陷的光学特性间存在着明显的差异。

1.3 技术要求
事实上,传统的无损检测方法由于其检测原理的局限性,可检出的缺陷种类和缺陷定量描述参数极为有限,无法综合评估产品的表面质量状况。激光扫描检测技术灵敏度较高,但其光学系统结构复杂,噪声对检测信号影响很大[4]。CCD检测法同其他方法相比具有很大的优势,但是分辨率和灵敏度有待进一步提高。随着科学技术进一步发展,基于机器视觉的钢板表面缺陷检测技术将是未来研究的主要方向。
基于机器视觉的钢板表面缺陷检测技术的难点是通过图片来识别。
近年来,CCD技术快速发展,线阵相机已经应用于表面检测领域,若将线阵相机部署到生产线上,便可将实时采集的图像发送到监视器,工人仅通过监视器就能观察金属表面状况。如今,许多钢材企业还在采用此方法监控钢材表面质量。但其缺点是依然耗费人力,检测结果不稳定,人工劳作强度大。
近年来深度学习飞速发展,并在多个领域中取得了非常好的研究成果,在图像分类与检测任务中,较为常用的是卷积神经网络,它摒弃了传统机器学习中的手工设计特征提取算法的部分,转而采用网络自学习特征的模式,在与样本数据的交互中进行训练,并采用反向传播算法更新网络架构参数,实现自动特征提取。这样一来能够极大提升算法的普适性,省略手工设计特征提取算法的步骤。
在钢板表面缺陷检测任务中,引入了基于深度学习的算法框架来实现精度与效率更高的在线检测。
2 技术理论
由于我找到了钢板表面缺陷图片的数据集,因此我想使用深度学习的方法来完成钢板表面缺陷识别,在多方权衡后,我使用了Resnet18卷积神经网络,效果较好。
2.1 原理
2.1.1 Resnet背景
在深度学习中,随着网络的加深,能获取的信息越多,而且特征也越丰富。但是事实上随着网络的加深,优化效果反而越差,测试数据和训练数据的准确率反而降低了。这是由于网络的加深会造成梯度爆炸和梯度消失的问题。
针对这种现象已有的解决方法是对输入数据和中间层的数据进行归一化操作,这种方法可以保证网络在反向传播中采用随机梯度下降(SGD),从而让网络达到收敛。但是,这个方法仅对几十层的网络有用,当网络再加深时,这种方法就效果不是很好了。而Resnet网络的出现可以让更深的网络也可以得到更好的训练效果。
2.1.2 Resnet原理
在这个框架中,就我的理解,其中主要的创新点在于残差的引入和跳跃连接的思想。
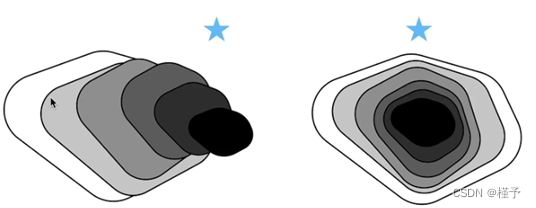
如上图,在不断加深网络的过程中,对于一般的卷积网络,他会像左边的图一样,在训练过程中,它的性能在提升(即覆盖面积更大),但是复杂模型往往可能会学偏,产生模型偏差,导致模型的效果反而更差了。
而Resnet网络简单来说就是可以使每次新的更复杂的模型都会包含上一个模型,这样就可以保证模型不会更差,简单来说,就像是“套娃”,距离最优解会越来越近。
它的具体实现比较简单,是引入了残差块的概念,实际上这个网络就是残差块的堆叠,就像是搭积木一样。
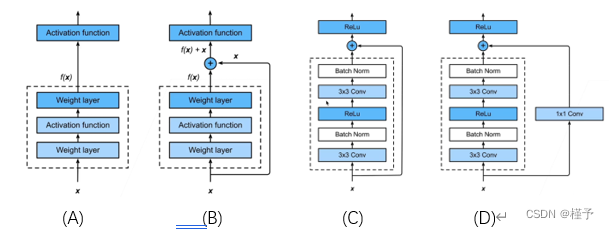
在串联模块的过程中,我们希望大模型可以在继承小模型的基础上再学到一些新的东西。所以在这里采用的方法就是在原有的基础上加上一个快速通道(如上图B所示),得到一种类似f(x)=x+g(x)的结构。
事实上,在实现过程中,往往要在快速通道上添加一个1x1的卷积层(如上图D所示),其目的是为了保证维度的相同,便于模型的可加。
残差块的实现往往是不同的,写法是多种多样的,但其中的核心思想是不变的。
其实Resnet的网络架构类似于VGG和GoogleNet,只是替换了残差块而已。
2.2 应用技术
2.2.1 技术路线
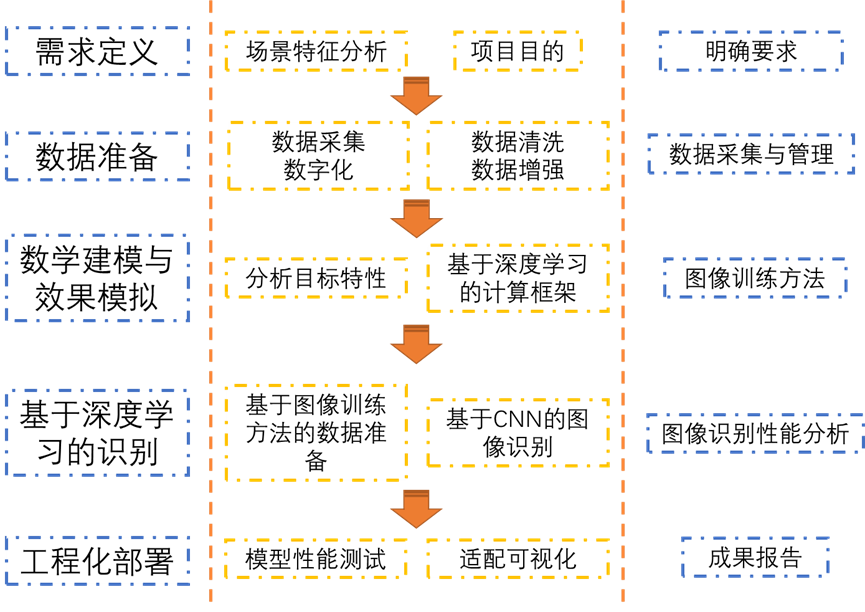
2.2.2 技术介绍
利用机器视觉检测技术的钢板表面缺陷检测系统是在不锈钢研磨线上对钢板上下表面利用机器视觉检测技术进行实时检测,通过图像采集卡在特殊光源的配合下获取钢板表面的图像,自动从图像中准确定位并识别缺陷。机器视觉检测技术与传统的人工目视检测相比,具有快速、可靠和准确的优点,目前已被钢铁企业广泛应用[5]。
钢板表面缺陷检测系统架构主要由工业CCD摄像机、LED照明系统、图像采集及处理计算机系统、数据统计与管理系统等组成。
LED光源以一定方向照射到钢板表面上,CCD像机在钢板上扫描成像,扫描所得的图像信号经过图像采集卡输入计算机,通过图像预处理得到钢板表面缺陷的二值图像,提取二值图像中的几何特征参数,然后再进行图像识别,判断出是否存在缺陷。若有,则保存图像;若没有,则放弃图像。
考虑到钢板生产加工速度快,同时检测对分辨率及速度要求较高,且设备安装空间有限,适用于2D线扫描方案,为减弱钢板振动影响,建议附加检测辊。
考虑到钢板表面三维缺陷同样对其质量产生重要影响,因此深度信息对钢板表面质量的判定同样重要。可以采用3D线激光方案(为了避免镜面反射等问题,可调整线激光入射角度实现激光图像获取),通过线激光、面阵相机及钢板形成完整的轮廓检测系统实现表面检测。考虑到线阵系统对传送振动较为敏感,也可以采用2D面阵相机实现条纹图像采集,利用傅里叶变换轮廓术或相位偏折术等技术实现相位提取,可以更好地解决钢板在传送过程中振动、二维缺陷灰度信息干扰及照明环境不稳定等问题,提高缺陷检出率[6]。
钢板表面缺陷检测系统,利用机器视觉检测技术的基本原理,在钢板的最后一道工序代替人工检测,钢板表面缺陷检测系统不仅可以实时对钢板表面缺陷检测,还能提供数据库管理缺陷以及钢板其他信息,为管理人员提供方便的数据统计及报表打印功能,辅助进行钢板质量管理工作。机器视觉检测技术在不锈钢表面检测与研磨领域得到广泛运用。
2.3 设计方案
2.3.1 编程工具
Visual Studio Code 1.73.1
2.3.2 编程环境
Anaconda、Python3.9
2.3.3 设计方案
(1)数据预处理:
图像灰度处理:改善画质,使图像的显示效果更加清晰;简化矩阵,提高运算速度。
对输入图像进行大小调整:保证所有图片的大小一致,便于神经网络的训练。
数据增强:随机将30%图片水平翻转、垂直翻转、不规则拉伸(拉伸力度0.3),图片随机旋转(0-180度)。扩充数据集,提高模型的泛化能力。
数据归一化:把需要处理的数据限制在一定范围内。为了后面数据处理的方便,并保证程序运行时收敛加快。
(2)特征提取:
利用Resnet卷积神经网络获取特征:使用卷积核来提取图片的特征向量,多层卷积可以提取多层特征,获取其中的隐含特征。
(3)图像分类:
利用CNN卷积+全连接堆叠的神经网络:使用类别编号作为标签,使用CNN卷积+多个全连接层作为分类器的实现。
(4)模型的调优:
使用Adam(自适应矩估计)优化器与CrossEntropyLoss(交叉熵)损失函数来进行模型的调优。
2.3.4 网络结构
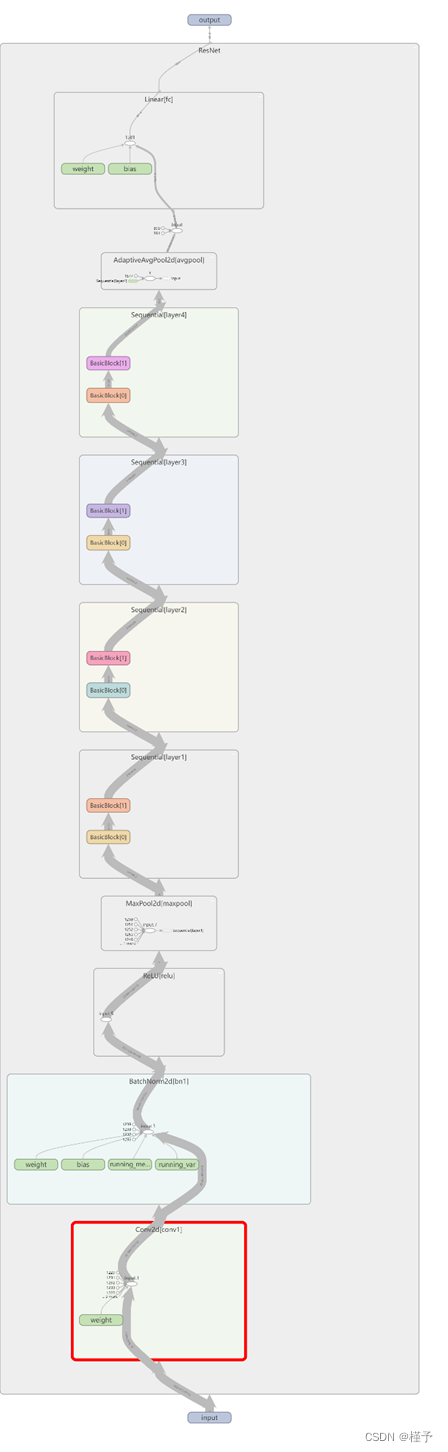
2.3.5 代码实现
import glob
import torch
from torch.utils import data
from PIL import Image
import numpy as np
from torchvision import transforms
import matplotlib.pyplot as plt
import torch.nn as nn
import torch.optim as optim
from tqdm import tqdm
import sys
#通过创建data.Dataset子类Mydataset来创建输入
class Mydataset(data.Dataset):
# 类初始化
def __init__(self, root):
self.imgs_path = root
# 进行切片
def __getitem__(self, index):
img_path = self.imgs_path[index]
return img_path
# 返回长度
def __len__(self):
return len(self.imgs_path)
#使用glob方法来获取数据图片的所有路径
all_imgs_path = glob.glob(r'dataset\*\*.bmp')#数据文件夹路径
# #循环遍历输出列表中的每个元素,显示出每个图片的路径
# for var in all_imgs_path:
# print(var)
#利用自定义类Mydataset创建对象error_dataset
error_dataset = Mydataset(all_imgs_path)
print(len(error_dataset)) #返回文件夹中图片总个数
error_datalodaer = torch.utils.data.DataLoader(error_dataset, batch_size=5) #每次迭代时返回五个数据
species = ['Cr','In','Pa','PS','RS','Sc']
species_to_id = dict((c, i) for i, c in enumerate(species))
print(species_to_id)
id_to_species = dict((v, k) for k, v in species_to_id.items())
print(id_to_species)
all_labels = []
#对所有图片路径进行迭代
for img in all_imgs_path:
# 区分出每个img,应该属于什么类别
for i, c in enumerate(species):
if c in img:
all_labels.append(i)
print(all_labels) #得到所有标签
# 对数据进行转换处理
transform = transforms.Compose([
transforms.Grayscale(1),
transforms.RandomHorizontalFlip(p=0.3), # 将三成图片水平翻转
transforms.RandomVerticalFlip(p=0.3), # 将三成图片垂直翻转
transforms.RandomPerspective(distortion_scale=0.3, p=0.3), # 将三成图片不规则拉伸,拉伸力度0.3
transforms.RandomRotation(degrees=(0, 180)), # 图片随机旋转,0-180度
transforms.ToTensor(), #第二步转换,作用:第一转换成Tensor,第二将图片取值范围转换成0-1之间,第三会将channel置前
transforms.Normalize(0.5,0.5)
])
transform1 = transforms.Compose([
transforms.Grayscale(1),
transforms.ToTensor(), #第二步转换,作用:第一转换成Tensor,第二将图片取值范围转换成0-1之间,第三会将channel置前
transforms.Normalize(0.5,0.5)
])
class Mydatasetpro(data.Dataset):
# 类初始化
def __init__(self, img_paths, labels, transform):
self.imgs = img_paths
self.labels = labels
self.transforms = transform
# 进行切片
def __getitem__(self, index): #根据给出的索引进行切片,并对其进行数据处理转换成Tensor,返回成Tensor
img = self.imgs[index]
label = self.labels[index]
pil_img = Image.open(img) #pip install pillow
data = self.transforms(pil_img)
return data, label
# 返回长度
def __len__(self):
return len(self.imgs)
BATCH_SIZE = 60
error_dataset = Mydatasetpro(all_imgs_path, all_labels, transform)
error__datalodaer = data.DataLoader(
error_dataset,
batch_size=BATCH_SIZE,
shuffle=True
)
imgs_batch, labels_batch = next(iter(error__datalodaer))
print(imgs_batch.shape)
plt.figure(figsize=(12, 8))
for i, (img, label) in enumerate(zip(imgs_batch[:6], labels_batch[:6])):
img = img.permute(1, 2, 0).numpy()
plt.subplot(2, 3, i+1)
plt.title(id_to_species.get(label.item()))
plt.imshow(img)
plt.show()#展示图片
#划分测试集和训练集
index = np.random.permutation(len(all_imgs_path))
all_imgs_path = np.array(all_imgs_path)[index]
all_labels = np.array(all_labels)[index]
#90% as train
s = int(len(all_imgs_path)*0.9)
print(s)
train_imgs = all_imgs_path[:s]
train_labels = all_labels[:s]
test_imgs = all_imgs_path[s:]
test_labels = all_labels[s:]
train_ds = Mydatasetpro(train_imgs, train_labels, transform) #TrainSet TensorData
test_ds = Mydatasetpro(test_imgs, test_labels, transform1) #TestSet TensorData
train_dl = data.DataLoader(train_ds, batch_size=BATCH_SIZE, shuffle=True)#TrainSet Labels
test_dl = data.DataLoader(test_ds, batch_size=BATCH_SIZE, shuffle=True)#TestSet Labels
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, in_channel, out_channel, stride=1, downsample=None, **kwargs):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=out_channel,
kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channel)
self.relu = nn.ReLU()
self.conv2 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel,
kernel_size=3, stride=1, padding=1, bias=False)
# 加速收敛,防止梯度消失和梯度爆炸
self.bn2 = nn.BatchNorm2d(out_channel)
self.downsample = downsample
def forward(self, x):
identity = x
#这是为了保证原始输入与卷积后的输出层叠加时维度相同
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out += identity
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self,
block,
blocks_num,
num_classes=1000,
include_top=True,
groups=1,
width_per_group=64):
super(ResNet, self).__init__()
self.include_top = include_top
self.in_channel = 64
self.groups = groups
self.width_per_group = width_per_group
self.conv1 = nn.Conv2d(1, self.in_channel, kernel_size=7, stride=2,
padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(self.in_channel)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, blocks_num[0])
self.layer2 = self._make_layer(block, 128, blocks_num[1], stride=2)
self.layer3 = self._make_layer(block, 256, blocks_num[2], stride=2)
self.layer4 = self._make_layer(block, 512, blocks_num[3], stride=2)
if self.include_top:
self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) # output size = (1, 1)
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
def _make_layer(self, block, channel, block_num, stride=1):
downsample = None
if stride != 1 or self.in_channel != channel * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.in_channel, channel * block.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(channel * block.expansion))
layers = []
layers.append(block(self.in_channel,
channel,
downsample=downsample,
stride=stride,
groups=self.groups,
width_per_group=self.width_per_group))
self.in_channel = channel * block.expansion
for _ in range(1, block_num):
layers.append(block(self.in_channel,
channel,
groups=self.groups,
width_per_group=self.width_per_group))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
if self.include_top:
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
# resnet18网络
def resnet18(num_classes=1000, include_top=True):
return ResNet(BasicBlock, [2,2,2,2], num_classes=num_classes, include_top=include_top)
# resnet34网络
def resnet34(num_classes=1000, include_top=True):
return ResNet(BasicBlock, [3, 4, 6, 3], num_classes=num_classes, include_top=include_top)
# 查看GPU是否可用,如果可以就使用GPU进行训练并打印出训练设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("using {} device.".format(device))
# 导入网络模型
net = resnet34(num_classes=6) # 使用resnet18网络进行训练
net.to(device) # 将网络迁移到GPU进行计算
print(net)
# 定义损失函数,使用CrossEntropyLoss,即交叉熵损失函数
loss_function = nn.CrossEntropyLoss()
# 构造一个优化器
params = [p for p in net.parameters() if p.requires_grad] # 将网络中所有需要更新梯度的参数放入params
optimizer = optim.Adam(params, lr=0.001) # 构建优化器,传入两个参数,前者为要优化的参数,后者为学习率
epochs = 20 # 训练批次
best_acc = 0.0 # 用于存放准确率
save_path = './finidhresNet18kk.pth' # 模型保存路径
train_steps = int(1800*0.9) # 训练步长
#定义两个数组
train_Loss_list = []
test_Loss_list = []
Accuracy_list = []
# 开始训练与测试的迭代
for epoch in range(epochs):
# 训练部分
net.train()
running_loss = 0.0 # 用于记录训练损失函数
train_bar = tqdm(train_dl, file=sys.stdout) # 用这个包来显示训练进度
for step, data in enumerate(train_bar):
images, labels = data
optimizer.zero_grad() # 把梯度置零,也就是把loss关于weight的导数变成0
logits = net(images.to(device)) # 将图片张量送入网络前向传播,images.to(device) 是让其在GPU上计算
loss = loss_function(logits, labels.long().to(device)) # 计算损失
loss.backward() # 反向传播,根据loss计算梯度
optimizer.step() # 更新梯度
# 打印统计
running_loss += loss.item()
train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch + 1, epochs, loss)
train_Loss_list.append(loss.item())
# 测试部分
net.eval()
acc = 0.0 # 累计正确率 / 批次
with torch.no_grad(): # with 下的所有代码都不更新梯度
val_bar = tqdm(test_dl, file=sys.stdout)
for val_data in val_bar:
val_images, val_labels = val_data
outputs = net(val_images.to(device))
# loss = loss_function(outputs, test_labels)
predict_y = torch.max(outputs, dim=1)[1]
acc += torch.eq(predict_y, val_labels.to(device)).sum().item()
val_bar.desc = "valid epoch[{}/{}]".format(epoch + 1, epochs)
val_accurate = acc / (180)
print('[epoch %d] train_loss: %.3f val_accuracy: %.3f' % (epoch + 1, running_loss / train_steps, val_accurate))
test_Loss_list.append(running_loss / train_steps)
Accuracy_list.append(val_accurate)
# 当前训练模型的准确率高于之前时,就将模型保存
if val_accurate > best_acc:
best_acc = val_accurate
torch.save(net.state_dict(), save_path)
x1 = range(0, epochs )
x2 = range(0, epochs )
y1 = Accuracy_list
y2 = test_Loss_list
plt.subplot(2, 1, 1)
plt.plot(x1, y1, 'o-')
plt.title('Test_loss_accuracy vs. epoches')
plt.xlabel('Test accuracy vs. epoches')
plt.ylabel('Test accuracy')
plt.subplot(2, 1, 2)
plt.plot(x2, y2, '.-')
plt.xlabel('Test loss vs. epoches')
plt.ylabel('Test loss')
plt.show()
x = range(0, int(27*epochs))
y = train_Loss_list
plt.plot(x, y, 'o-')
plt.title('Train_loss vs. steps')
plt.xlabel('Train loss vs. steps')
plt.ylabel('Train loss')
plt.show()
print('Finished Training')
3 仿真与分析
3.1 设计方案仿真
3.1.1 数据集展示



3.1.2 标签生产与整理
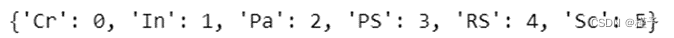
3.1.3 数据预处理效果

3.1.4 训练过程
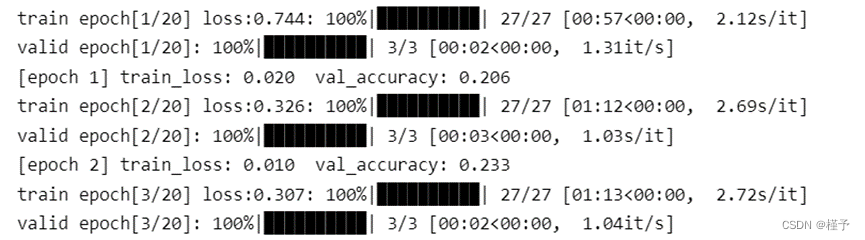
…

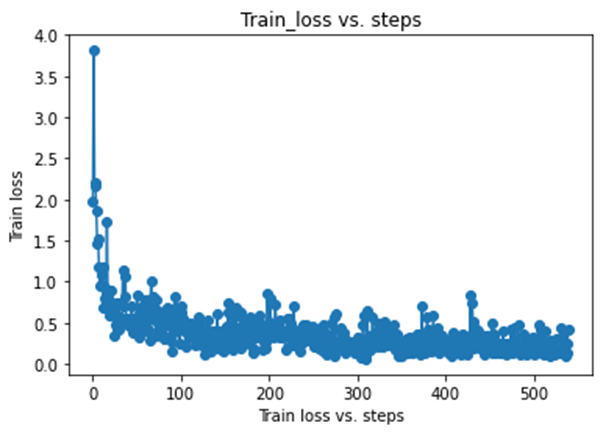
随着训练过程的增长,训练集在模型上的误差越来越小。
3.1.5 模型测试
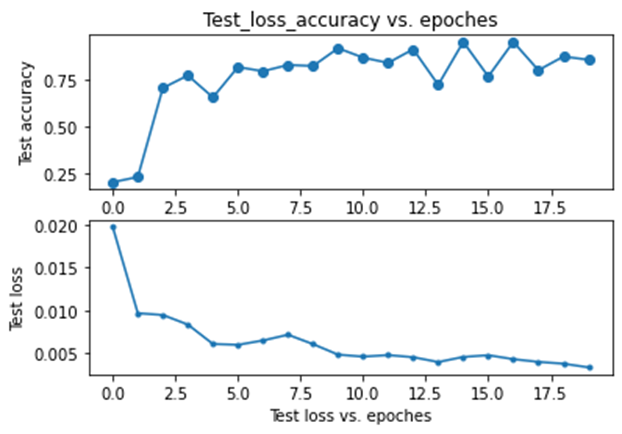
在测试集上的平均误差较低,且准确率基本维持在85%左右,效果较好。
3.2 设计结果分析
观察训练曲线可以发现在训练200批次过程中,验证集loss出现了震荡的情况,但准确率却没有下降,因此是发生了“过拟合”。为此,经过分析,在第150轮次时停止训练得到的模型较为良好。
此时在验证集上,该卷积神经网络可以达到90.83%的准确率。
对于随机划分的测试数据正确率在85%左右,对于这样一个简单的模型效果可以接受。
4 设计优势
钢是冶金企业的主要产品,是汽车、国防、化工、轻工业制造的主要原材料。随着全球能源紧张、铁矿石的涨价,对带钢的成品率、合格率、优质率提出更高的要求。表面质量是带钢的主要质量指标,由于原材料、轧制工艺、系统控制等方面的因素,造成带钢表面出现裂纹、结疤、辊印、空洞、表皮分层、色斑、麻点等缺陷在所难免。这些缺陷对带钢的抗疲劳性、抗腐蚀性、耐磨性、电磁特性都有不同程度的影响,所以在轧制过程中,及时发现这些缺陷、调整控制参数、分类标注不同等级的带钢,对提高带钢产品质量、降低生产能源消耗、最大限度地获取销售利润具有深远的意义。
表面缺陷检测的意义主要体现在以下三个方面:
(1)严格把控产品质量
表面缺陷不仅破坏产品的美感和舒适度,还可能对产品的性能造成严重损害。因此,产品的表面缺陷检测必须覆盖在生产的多个环节,既在出厂前的最后环节,也在生产的中间关节。以带钢检测为例,带钢表面质量是评估产品等级的关键指标。对于中间环节来讲,带有孔洞和边裂等表面缺陷的产品由轧机向下游传递,可能造成连退机组断带、钢板降级改判、产品判废等严重生产事故;对于最后环节来说,出厂终检是交付客户前的最后一次把关。如果缺乏有效的缺陷检测系统,会导致产品质量等级的错误分级。由于带钢是电机、发电机和变压器铁芯的主要制作材料,夹杂、斑块、压入氧化平等表面缺陷会严重损害带钢的抗腐蚀性、抗疲劳性和铁损特性,直接影响电机、发电机等产品的性能。若品质不达标的带钢在出厂前未能被甄别出来,可能导致严重的安全事故。
(2)防止潜在的经济损失和法律纠纷
表面缺陷检测能够有效杜绝或减少残次品流入市场。在汽车、3C等领域内,由于该类产品由成千上万的零部件组成,产品又大多属于大批量生产,表面出现微小的划痕、裂纹和凹坑等瑕疵难以避免。但是其中某些关键零部件的破损可能会给最终的用户带来安全风险。以汽车中的悬架弹簧和发动机为例:汽车悬架表面涂层需经过严格的出厂,若悬架的表面涂层不均匀或有剥离脱落,在持续冲击和腐蚀下,容易萌生裂纹,甚至导致悬架弹簧疲劳断裂,危及驾驶人的人身安全;发动机作为汽车的“心脏”,车辆生产制造过程中非常核心的环节,其质量把控非常严格。若发动机缸孔壁出现磨损、缩松等缺陷,会造成漏油、漏气等问题,不但会影响发动机的工作性能,甚至引发安全事故。
如今,因所售产品存在缺陷或安全隐患,每年都有大量生产商将已经送到下游零售商或最终客户的产品召回,导致沉重的经济损失。严格的表面缺陷检测能够防止不合格品流入市场,杜绝潜在的经济损失和法律纠纷,有利于提升企业的形象。
(3)针对性的生产线维护和改造方案
表面缺陷检测的另一重要作用是帮助企业及时发现问题并改进相应生产工艺,预判性地维护生产机器。准确地检测出缺陷的类别是有效指导生产、检修的前提。通过自动化、智能化的表面缺陷检测方法,分析缺陷产生的原因,使得生产线的维护工作更具有针对性,有效降低维护成本和检修成本。同时,表面缺陷检测能够帮助企业更好地掌握产品质量分布状况,寻找质量薄弱环节,降低产品质量波动,形成生产和质量提升的闭环控制。
对于自动化工程而言,自动化的本质是控制,什么时候控制、怎么控制、控制到什么程度,往往需要对控制目标的状态、工作环境等的检测与识别。在传统的自动化中,往往使用人工来观察,对突发情况进行判断和做出反应。深度学习的到来,利用基于深度学习发展出现的CNN、LSTM等框架,我们可以利用其代替人工,应用在自动化工程中。
深度学习在很多地方都可以与自动化工程相结合。
利用深度学习对图像进行分类,可以代替人工对某些分类工作进行高质量的进行,降低生产成本,提高经济效益。
利用深度学习对故障进行检测,可以较早的、准确的发现流水线中的故障,保障生产的顺利进行,减少安全事故的发生。
利用深度学习进行自然语言处理,可以让机器“听懂”我们的话,可以使用语音进行某些操控,使生产更加简单与便捷。
自动化工程是一门多学科交叉的领域,深度学习以很好的相容性可以进入这个领域。二者相互结合,深度学习为自动化工程的更安全、更快速、更高效做出自己的努力;同时,在自动化工程实践中,也会促进深度学习的进步与发展。
5 参考文献
[1]李炜,黄心汉,王敏,等.基于机器视觉的带钢表面缺陷检测系统[J].华中科技大学学报:自然科学版,2003(2):72-74.
[2]阳燚. 高温连铸坯表面缺陷无损检测方法研究[D].浙江工业大学,2012.
[3]王震宇.基于机器视觉钢板表面缺陷检测技术研究[J].计算机与现代化,2013(7):130-134.
[4]赵向阳. 基于神经网络的钢板表面缺陷识别若干问题的研究[D].大连理工大学,2006.
[5]程万胜. 钢板表面缺陷检测技术的研究[D].哈尔滨工业大学,2008.
[6]赵薇. 带钢表面缺陷检测及分割技术研究[J]. 机械设计与制造, 2010 (10): 224-226.

















 383
383

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









