






摘要:
锥形束CT(Cone Beam Computed Tomography,CBCT)是目前口腔医学中应用最广泛的一种成像方法,要重建一幅高质量的CBCT图像,需要进行数百次的X线投影(即,衰减场)在传统算法中,表示“稀疏”之义视图CBCT重建已成为降低辐射剂量的主要研究方向,但由于数据量不足或重建的泛化能力差,已进行了多次尝试来解决该问题本文提出了一种新的衰减场编码-解码器框架,首先对来自多视角X射线投影的体特征进行编码,然后将其解码为期望的衰减场,我们遵循了多视角CBCT重建的本质,强调了多视角CBCT重建的几何一致性。该方法具有良好的空间感知特性、空间特征查询特性和自适应特征融合特性,同时利用数据种群的先验知识保证了算法的泛化能力,并通过下游应用进一步验证了所提方法的可行性。
1.介绍
锥形束计算机断层扫描(CBCT)是 CT 扫描的一种变体,是牙科领域应用最广泛的成像技术,因为它能以更短的扫描时间提供空间分辨率更高的三维结构信息。CBCT 的标准成像方案如图 1 所示。在 CBCT 扫描过程中,X 射线源沿着弧形轨道均匀移动,每移动一个角度,就会向感兴趣的器官(如口腔)发射一束锥形光束。患者另一侧的探测器捕捉二维透视投影。CBCT 重建的目的是从这些二维投影中反向恢复出三维衰减场(即 CBCT 图像)。这主要是通过滤波背投影(FBP)算法实现的,然而,这种方法通常需要数百个投影视图,辐射量很大。因此,通过减少投影视图数量进行稀疏视图(如 5 或 10 个视图)CBCT 重建受到了研究领域的广泛关注。
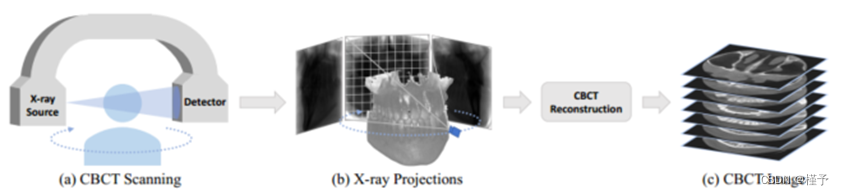 图 1. CBCT 成像:(a) CBCT 扫描会产生一系列 (b) X 射线投影,通过 CBCT 重构,这些投影将被用于绘制 (c) 三维 CBCT 图像。
图 1. CBCT 成像:(a) CBCT 扫描会产生一系列 (b) X 射线投影,通过 CBCT 重构,这些投影将被用于绘制 (c) 三维 CBCT 图像。
2.方法
2.1 几何感知衰减场学习
CNN 特征提取 根据图 1,三维衰减场是用二维 X 射线投影以反渲染方式求解的。一个直观的想法是提取这些投影的特征表示,并利用它们来学习衰减场的映射。具体来说,给定 N 个投影 fIig N i=1,我们利用二维 CNN 编码器 E(在我们的工作中为 ResNet34 [4])来提取二维特征表示,表示为 fFi = E(Ii)g N i=1。
几何感知特征查询 我们框架的关键之处在于通过几何感知来学习衰减场。如图 2 所示,我们的目标是通过查询像素坐标中的二维特征表示,获取世界坐标中的衰减特征场。
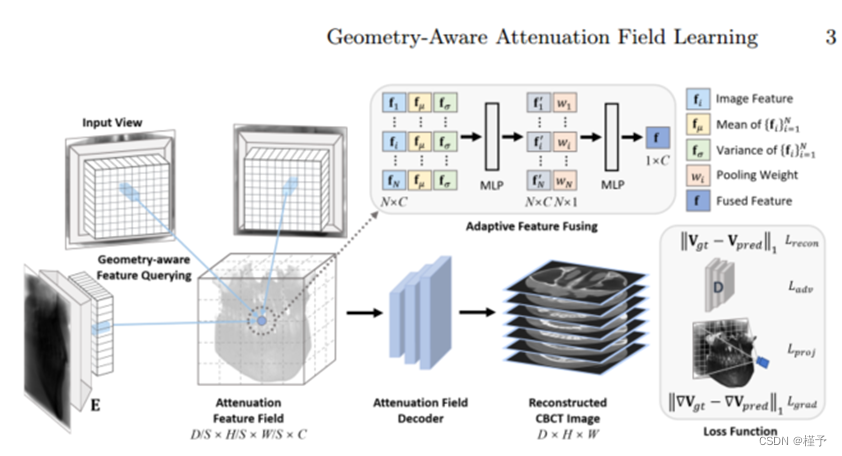

然后,我们就可以通过双线性插值从 Fi 得到 x 的特征向量:
![]()
其中,fi 2 R C。这样,我们就可以从所有二维特征表示 fFig N i=1 中获得查询点 x 的空间一致特征向量 ffig N i=1。
自适应特征融合 通过特征查询获取查询点 x 的多视角特征向量 ffig N i=1 后,我们的目标是将它们融合为衰减特征向量 f。然而,由于查询点的空间定位各不相同,特定查询点 x 可能会从不同视角获得不同的衰减信息。因此,受文献[12]的启发,我们设计了一种自适应特征融合策略来聚合这些特征向量。具体来说,对于查询点 x 的 ffig N i=1,我们计算一个元素均值向量 fµ 2 R C 和方差向量 fσ 2 R C,以捕捉全局信息。我们将每个 fi 视为第 i 个视图的局部信息,并通过串联将其与 fµ 和 fσ 整合为全局信息。合并后的特征被送入第一个 MLP,以聚合局部和全局信息,产生一个聚合的全局感知特征向量 f 0 i 2 R C 和每个视图的归一化池化权重 wi 2 [0; 1],将其加权求和后送入第二个 MLP,得到最终的融合特征 f 2 R C。注意,池化权重 wi 可视为第 i 个视图的贡献因子。
衰减场解码 在获得每个查询点的衰减特征向量 f 后,我们就可以将所有查询点组合在一起建立衰减特征场。受硬件设备内存大小的限制,我们建立了一个低分辨率的衰减特征体素网格,其下采样大小为 D=S ×H=S ×W=S ×C,这大大加快了计算速度。该衰减特征场可视为目标 CBCT 图像的特征表示。因此,我们将其输入衰减场解码器,以获得所需分辨率为 D × H × W 的目标容积衰减场(即 CBCT 图像)。
2.2模型优化
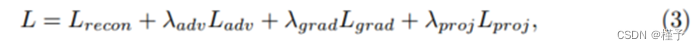 其中,λadv、λgrad 和 λproj 用于控制不同项的重要性。
其中,λadv、λgrad 和 λproj 用于控制不同项的重要性。
3 实验
3.1 实验设置
数据集 在临床实践中,成对的二维 X 射线投影和三维 CBCT 图像非常稀缺。因此,我们利用数字重建放射成像(DRR)技术,从采集的 CBCT 图像中生成多个 X 射线投影,即如图 1 所示的过程,并利用比尔定律模拟扫描过程中的 X 射线衰减,从而解决了这一难题。我们的数据集由 130 幅不同患者的牙科 CBCT 图像组成,分辨率为 256 × 256 × 256。我们将其分为 100 张训练图像、10 张验证图像和 20 张测试图像。如上所述,我们为每张 CBCT 图像生成相应的 X 射线投影。在实验中,我们以 CBCT 图像中心为圆心,每 360=N 度生成 N 个 X 射线投影,每个 X 射线投影的分辨率为 256 × 256。我们在本文中选择 N = 5、10 和 20。
实现细节 在实验中,我们根据经验设置了 λadv = 0:001、λproj = 0:01、λgrad = 1、下采样率 S = 4、通道大小 C = 256 和 DRR 射线批大小 jBj = 1024。我们使用学习率为 1×10-4 的亚当优化器,学习率每 50 个历时衰减 0.5,训练过程在 150 个历时后结束。解码器和鉴别器是 SRGAN [6,10] 的 3D 实现。所有实验均在单个 A100 GPU 上进行。
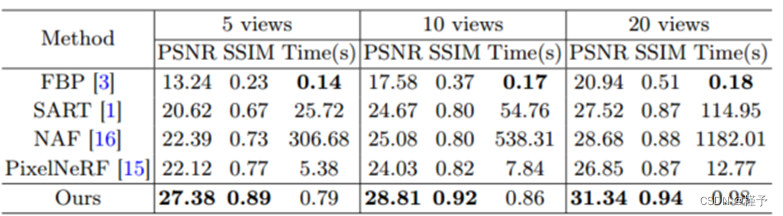
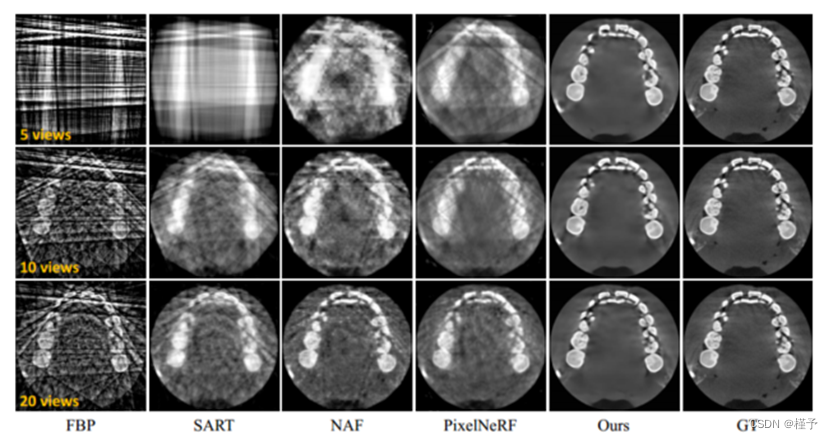
比较方法和评估指标 我们提出的框架与四种典型方法(即 FBP、SART、NAF 和 PixelNeRF)进行了比较。FBP [3] 是业界广泛使用的经典 CBCT 重建算法。SART [1] 是一种传统算法,通过迭代最小化和正则化来解决稀疏视图问题。NAF [16]基于神经渲染[8]和多分辨率哈希编码[9]的适应性,提供了最先进的CBCT重建性能和每场景优化。由于神经渲染旨在解决与我们的工作高度相关的反渲染问题,我们还将我们的方法与 PixelNeRF [15] 进行了比较,PixelNeRF 是计算机视觉领域的一个代表性框架,通过利用 CNN 的泛化能力来解决稀疏视图问题。值得注意的是,我们没有与 [5、11、14] 进行比较,因为它们无法处理灵活的输入姿势和视图数量。我们利用两个常用指标来评估重建性能,即峰值信噪比(PSNR)和结构相似性(SSIM)[13]。我们还报告了重建时间,以衡量不同方法的效率。
3.2 结果
定量和定性结果 表 1 列出了不同方法的定量比较。我们的方法优于所有其他方法,达到了在 PSNR 和 SSIM 方面都有明显优势。值得注意的是,我们的方法只需 5 个输入视图就能达到最高性能(27.38 dB 的 PSNR),而 20 个输入视图的 PSNR 超过 30 dB,大大超过了目前最先进的方法(即 NAF)。此外,我们的重建时间不到一秒,比其他稀疏视图方法(即 SART、NAF 和 PixelNeRF)快得多。SART 和 NAF 分别存在迭代计算耗时和按场景优化的问题,与 PixelNeRF 相比,我们受益于低分辨率特征查询。
表 1. 不同方法的定量比较。
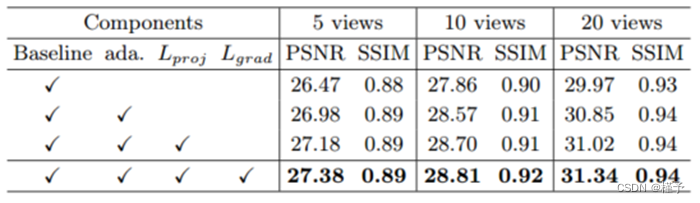
消融研究 表 2 列出了定量消融研究的结果,其中基线模型只是利用平均池法汇总不同输入视图的特征向量,在训练过程中只采用重构和对抗损失。表中的每一个 "X "表示在基线模型中添加相应的组件,作为新的备选方案。注意,表中的 "ada. "表示自适应特征融合策略。可以看出,与其他 SOTA 方法相比,我们的基线模型已经表现最佳。例如,在 PSNR 方面,与 PixelNeRF 相比,我们在 5、10 和 20 个视图上分别获得了 4:35 dB、3:83 dB 和 3:12 dB 的显著提升。因为我们强大的基线在特征学习中配备了几何感知视图一致性,在训练中配备了体素智能监督,这些都为我们的方法奠定了基础,也是我们方法成功的关键。此外,随着其他组件的加入,PSNR 和 SSIM 值也逐渐增加,这证明了我们技术设计的有效性。举例来说,自适应特征融合技术就能有效地解决这一问题。与平均汇集相比,投影损失能更灵活、更准确地整合来自不同视图的信息,从而带来相对可观的改进。投影损失和梯度损失分别提高了几何感知视图的一致性和清晰度。
按场景微调 经过跨场景训练后,我们的模型可以从稀疏的 X 射线视图中提供像样的 CBCT 图像重建。我们可以通过只使用相同输入视图的投影损失来进一步微调场景结果。经过大约 4-15 分钟的优化后,5、10 和 20 个视图的重建结果的 PSNR 值平均分别提高了 0.66 dB、0.74 dB 和 0.75 dB。
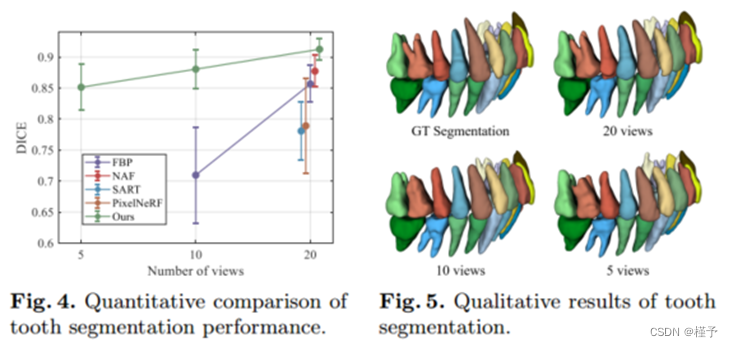
应用 我们将牙齿分割作为下游应用来评估重建 CBCT 图像的质量。我们首先获取测试集中每张 CBCT 图像的专家人工注释,然后使用预先训练好的 SOTA 网络 [2] 对牙齿进行分割。作为参考,我们测试集中来自地面实况 CBCT 图像的牙齿分割(与人工标注相比)的平均 Dice 分数为 0:94。因此,无论哪种方法的 Dice 分数更接近这个值,都能获得更高的重建质量。在图 4 中,我们报告了所有方法的 Dice 分数(平均值和标准偏差),这些方法是在使用不同输入视图数重建的 CBCT 图像上进行测试的。需要注意的是,为了确保比较的清晰性,我们省略了图中一些牙齿分割失败的结果(例如,来自 NAF 的 5 个和 10 个视图的结果)(即 Dice 分数小于 0.6)。可以看出,我们的方法明显优于所有竞争对手,这表明我们的重建方法非常实用,而且图像质量上乘。此外,我们在图 5 中提供了一个直观的例子,在图 5 中,我们对 5 个、10 个和 20 个视图的 Dice 分数分别为 0:88、0:90 和 0:92,而在这种特定情况下,地面实况 CBCT 分割的 Dice 分数为 0:95。虽然我们的 Dice 分数没有地面实况高,但也不相上下,这表明我们的方法在下游应用和实际临床使用中具有巨大的潜力。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









