






摘要
稀疏视图锥束CT(CBCT)重建是降低辐射剂量和临床应用的一个重要方向,以往基于体素的重建方法将CT表示为离散体素,由于使用3D解码器,导致存储要求高和空间分辨率有限。我们将CT体积表示为连续强度场,并开发了一种新的DIF网络,以从极稀疏(≤10)CT的强度场可以被认为是3D空间点的连续函数。因此,重建可以被重新表述为从给定的稀疏投影回归任意3D点的强度值。具体地,对于一个点,DIF-Net从不同的2D投影视图中提取其视图特定的特征。这些特征随后由融合模块聚合用于强度估计。值得注意的是,可以并行处理数千个点,以提高训练和测试期间的效率。在实践中,我们收集了一个膝关节CBCT数据集来训练和评估DIF-Net。大量的实验表明,我们的方法可以在1.6秒内从极其稀疏的视图重建出高图像质量和高空间分辨率的CBCT,明显优于最先进的方法。
我们的代码将在xmed-lab/DIF-Net: MICCAI 2023: Learning Deep Intensity Field for Extremely Sparse-View CBCT Reconstruction (github.com)上提供。
1. 介绍

图1.(a-b):常规CT和锥束CT扫描的比较。(c-d):CBCT从稀疏2D投影堆叠重建。
为了保证图像质量,CBCT通常需要数百次投影,这些投影涉及X射线的高辐射剂量,这可能是临床实践中的一个问题。稀疏视图重建是通过减少扫描视图数量来减少辐射剂量的方法之一在本文中,我们研究了一个更具挑战性的问题,极稀疏视图CBCT重建,旨在从少于10个投影视图重建高质量的CT体积。
与传统CT相比(例如,平行束、扇形束),CBCT从2D投影重建3D体积,而不是从1D投影重建2D切片,如图1所示的比较,导致空间维度和计算复杂度的显著增加。因此,尽管稀疏视图常规CT重建[2,23,25,26]已经发展了很多年,这些方法不能简单地扩展到CBCT。根据所需投影视图的数量,CBCT重建可以分为密集视图(≥100)、稀疏视图(20 - 50)、极稀疏视图(≤10)和单/正交视图重建。密集视图重建的典型示例是FDK [6],这是一种滤波反投影(FBP)算法,通过从2D视图反投影来累积强度,但需要数百个视图来避免条纹伪影。(例如,SART [1],VW-ART [16])将重建公式化为迭代最小化过程,这在投影有限时是有用的。然而,这样的方法通常需要很长的计算时间来收敛,并且不能很好地科普极其稀疏的投影;参见表1中SART的结果。随着深度学习技术和计算设备的发展,提出了基于学习的CBCT稀疏视图重建方法。Lahiri等人[12]提出使用FDK重建粗CT并使用2D CNN对每个切片进行降噪。然而,该算法尚未在医学数据集上得到验证,并且性能仍然有限,因为FDK引入了具有稀疏视图的广泛条纹伪影。最近,已经引入了神经绘制技术[5,14,19,21,29],通过将衰减系数场参数化为隐式神经表示场(NeRF)来重建CBCT体积,但是它们需要很长的时间来进行每个患者的优化,并且由于缺乏先验知识而不能很好地执行极其稀疏的视图;参见表2中的NAF结果。对于单/正交视图重建,基于体素的方法[10,22,27]提出了构建2D到3D生成网络,该网络由具有大训练参数的2D编码器和3D解码器组成,导致高存储器要求和有限的空间分辨率。这些方法是网络的特殊设计[10,27]或患者特异性训练数据[22],难以扩展到一般稀疏视图重建。
在本论文中,我们的目标是从极其稀疏(≤10)的2D投影中重建高图像质量和高空间分辨率的CBCT,这是稀疏视图CBCT重建中的一个重要而又具有挑战性和尚未研究的问题。该场可以看作是三维空间点的连续函数g(·),点p在该场中的性质表示其强度值v,即v = g(p),因此,重建问题可以被重新表述为从2D投影I的堆叠回归任意3D点的强度值,即,v = g(I,p)的情况下。
在此基础上,我们提出了一个新的重构框架,即DIF-Net DIF-Net首先从给定的K个二维投影中提取特征图,然后将给定的一个三维点按相应的成像参数投影到每个视点的二维成像板上,最后根据每个视点的二维成像板上的特征图,对每个视点的二维成像板上的点进行三维重建(距离、角度等)并从视图i的特征图中查询其视图特有特征。然后,来自不同视图的K个视图特定特征通过交叉通过引入连续强度场,可以用稀疏采样点集来训练DIF-Net以减少内存需求,与NeRF方法[5,14,19,21,29]相比,DIF-Net的设计具有相似的数据表示方法,可以在任意分辨率下重建CT体积(即隐式神经表示),但是可以引入额外的训练数据来帮助DIF-Net学习先验知识,DIFNet不仅可以在很短的时间内重建高分辨率CT,因为对于新的测试样本仅需要推理(无需重新训练),而且在视图极其有限的情况下,其性能也比基于NeRF的方法好得多。
综上所述,本文的主要贡献包括:
1)首次提出了基于连续强度场的CBCT重建方法;
2)提出了一种新的重建框架DIF-Net,实现了CBCT的高质量重建(PSNR:29.3 dB,SSIM:0.92)和高空间分辨率(≥2563),可在1.6秒内从极稀疏(≤10)的视图中获得;
3.)我们在临床膝关节CBCT数据集上进行了广泛的实验以验证所提出的稀疏视图CBCT重建方法的有效性。
2. 方法
2.1 强度场
我们将CT体积公式化为连续强度场,其中该场中的3D点p ∈ R 3的属性表示其强度值v ∈ R。强度场可以定义为连续函数g:R3 → R,使得v = g(p)。因此,重建问题可以重新表述为从K个投影I = {I1,I2,.. .,IK},即v = g(I,p)。基于上述公式,我们提出一种新的重建框架,即DIF-Net,用于执行有效的稀疏视图CBCT重建,如图2所示。

2.2 DIF-Net:深度强度场网络
DIF-Net首先使用共享的2D编码器从投影I中提取特征图{F1,F2,.,FK}<$R C×H×W,其中C是特征通道的数量,H/W是高度/宽度。在实践中,我们选择U-Net [18]作为2D编码器,因为它具有良好的特征提取能力和在医学图像分析中的流行应用[17]。然后,给定一个3D点,DIF-Net收集从不同视图的特征图中查询的视图特定特征,以进行强度回归。
视图特定特征查询。考虑3D空间中的点p ∈ R 3,对于具有扫描角度αi和其他成像参数β的投影视图i,(距离、间距等),我们将p投影到视图i的2D成像面板上,并获得其2D投影坐标p ′ i = φ(p,αi,β)∈ R 2,其中φ(·)是投影函数。投影坐标p ′ i用于从视图i的2D特征图Fi查询视图特定特征fi ∈ R C:
![]()
其中π(·)是双线性插值。与透视投影类似,CBCT投影函数φ(·)可以用公式表示为:

其中R(αi)∈ R 4×4是将点p从世界坐标系变换到视图i的扫描仪坐标系的旋转矩阵,A(β)∈ R 3×4是将点投影到viewi的二维成像面板上的投影矩阵,H:R3 → R2是将p ′ i的齐次坐标映射到其笛卡尔坐标的齐次除法,由于篇幅限制,在补充材料中给出了φ(·)的详细公式。
跨视图特征融合和强度回归。给定K个投影视图,从不同视图查询点p的K个视图特定特征以形成特征列表F(p)= {f1,f2,.,fK}<$RC。然后,引入交叉视图特征融合δ(·)从F(p)中收集特征并生成一维向量<$f = δ(F(p))∈ R C来表示p的语义特征。一般来说,F(p)是一个无序的特征集,这意味着δ(·)应该是一个集合函数,可以用池化层来实现在我们的实验中,训练样本和测试样本的投影角度是相同的,从0 μ m到180 μ m均匀采样因此,F(p)可以看作是一个有序列表(K×C张量),和δ(·)可以由2层MLP实现(K → → 1)进行特征聚合。我们将在消融研究中比较δ(·)的不同实现。最后,对f应用4层MLP(C → 2C → <$C2 <$→ <$C8 <$→ 1)以回归强度值v ∈ R。
2.3网络训练
假设原始CT体积的形状和间距为H × W × D,在训练期间,与将整个3D CT图像视为监督目标的先前基于体素的方法不同,我们随机采样具有坐标范围从(0,0,0)到(0,0,0)的N个点的集合{p1,p2,.,pN }。(shH,swW,sdD)在世界坐标系中(单位:然后,DIF-Net将从给定的投影I估计它们的强度值V = {v1,v2,.,vN }。为了监督,地面实况强度值V = {v1,v2,.,vN }。v <$N }可以从基于点的坐标的地面真实CT图像通过三线性插值获得。我们选择均方误差(MSE)作为目标函数,训练损失可以用公式表示为:

由于背景点(62%,如空气)比前景点(38%,如骨骼、器官)占据更多的空间,均匀采样会带来亮度预测的不平衡,我们设置亮度阈值10−5,通过二值分类来识别前景和背景区域,并从每个区域中采样N2个点进行训练。
2.4容积重建
在推断期间,对覆盖所有CT体素的规则且密集的点集进行采样,即从(0,0,0)到(shH,swW,sdD)均匀地采样H × W × D点。然后网络将2D投影和点作为输入,并生成与以前的基于体素的方法仅限于生成固定分辨率的CT体积不同,我们的方法通过引入连续强度场的表示来实现可缩放的输出分辨率。例如,我们可以均匀地采样3H s × 3W s × 3D s × 3D s来生成粗略的CT图像,但具有更快的重建速度,或采样HsH × HsW × HsD × HsD点,生成更高分辨率的CT图像,其中s > 1为缩放比例。
3 实验
在采集的膝关节CBCT数据集上的实验结果表明本文方法在稀疏视CBCT重建中的有效性。与以前的工作相比,我们的DIF网络能够以超快的速度从极稀疏(≤ 10)的投影中重建出高图像质量和高空间分辨率的CT体积。
3.1实验设置
数据集和预处理。我们收集了一个由614个CT扫描组成的膝关节CBCT数据集。其中,464个用于训练,50个用于验证,100个用于测试。我们重新采样,插值和裁剪(或填充)CT扫描,以使各向同性体素间距为(0.8,0.8,0.8)mm,形状为256 × 256 × 256。用分辨率为256 × 256的数字重建X线片(DRR)生成2D投影。
实现。我们使用PyTorch和单个NVIDIA RTX 3090 GPU实现DIF-Net。网络参数使用随机梯度下降(SGD)进行优化,动量为0.98,初始学习率为0.01。学习率每epoch降低0.0011/400 ~ 0.9829倍,我们训练模型400 epoch,批量大小为4。对于每个CT扫描,在一次训练迭代期间,N = 10,000个点被采样作为输入。对于完整模型,我们使用具有C = 128个输出特征通道的U-Net [18]作为2D编码器,并且使用MLP实现跨视图特征融合。
基线方法。我们比较了四种公开可用的方法作为我们的基线,包括传统方法FDK [6]和SART [1],基于NeRF的方法NAF [29]和数据驱动的去噪方法FBPConvNet [11]。由于维数的增加,(2D到3D),去噪方法应配备3D conv/deconvs,以便在扩展到CBCT重建时进行密集预测,这导致极高的计算成本和低分辨率(≤ 643)。为了进行公平的比较,我们使用FDK来获得初始结果,并将2D网络应用于切片去噪。
评价指标。我们遵循以前的工作[27,28,29],使用两个定量指标,即峰值信噪比(PSNR)和结构相似性(SSIM)[24]来评价重建的CT体积。较高的PSNR/SSIM值表示上级重建质量。
3.2结果
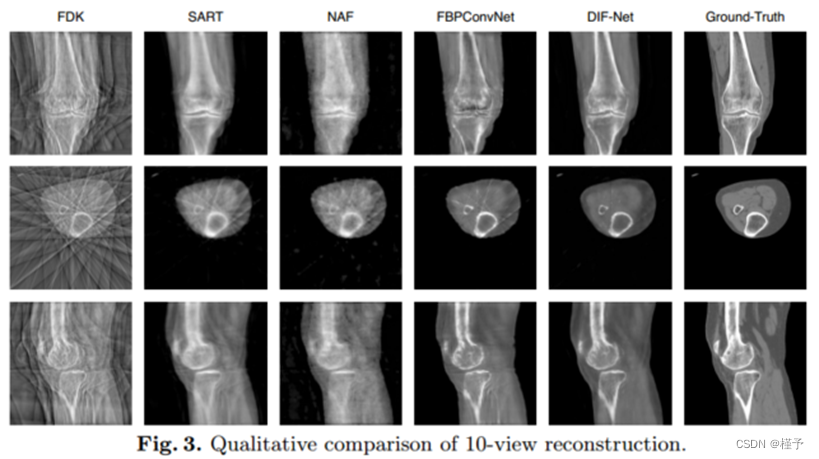
性能。如表1所示,我们在不同输出分辨率的重建设置下比较了DIF-Net与之前的四种方法[1,6,22,29](即,1283、2563)以及来自不同数量的投影视图的投影视图实验表明,我们提出的DIF-Net即使只使用6个投影视图也可以重建具有高图像质量的CBCT,其在PSNR和SSIM值方面明显优于先前的工作。更重要的是,DIF-Net可以直接应用于重建具有不同输出分辨率的CT图像,而不需要模型重新训练或修改。如图3所示的视觉结果,FDK [6]由于缺乏足够的投影视图而产生具有许多条纹伪影的结果; SART [1]和NAF [29]产生具有良好形状轮廓的结果,但缺乏详细的内部信息; FBPConvNet [11]重建了良好的形状和中等的细节,但仍然存在一些条纹伪影;我们提出的DIF-Net可以重建出高质量的CT图像,具有更好的形状轮廓、更清晰的内部信息和更少的伪影。2补充资料中给出了输入视图数量的更直观的比较。
表1.在PSNR(dB)和SSIM测量下,DIF-Net与先前方法的比较。我们评估了不同输出分辨率(Res.)和不同投影视图数(K)的重建。

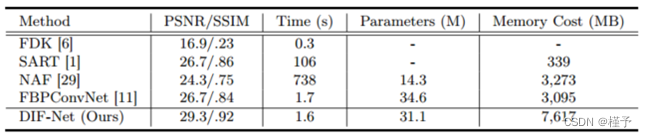
重建效率。如表2所示,FDK [6]需要的重建时间最少,但图像质量最差; SART [1]和NAF [29]需要大量时间进行优化或训练; FBPConvNet [11]可以更快地重建3D体积,但质量仍然有限。我们的DIF-Net可以在1.6秒内重建高质量的CT,比大多数比较方法快得多。此外,DIF-Net受益于强度场表示,具有更少的训练参数,需要更少的计算内存,从而实现高分辨率重建。
表2.不同方法在重建质量(PSNR/SSIM)、重建时间、参数和训练内存开销方面的比较。默认设置:10视图重建,输出分辨率为2563 ;训练批量为1。
†:由于内存限制,使用1283的输出分辨率进行评估。
消融研究。表3和表4显示了交叉视图融合策略的消融分析和训练点的数量N。实验证明1.)MLP执行得最好,但是最大池化也是有效的,并且当视角在训练/测试数据中不一致时将是通用的解决方案,如第2.2节中所讨论的;(2)少点(例如,5,000)可能使训练期间的损失和梯度不稳定,导致性能下降; 10,000个点足以实现最佳性能,并且使用10,000个点进行训练比使用整个CT体积进行训练的基于体素的方法稀疏得多(即,2563或1283)。我们尝试使用不同的编码器,如预训练的ResNet 18 [8],其模型参数比U-Net [18]更多。然而,ResNet 18没有带来任何改善(PSNR/SSIM:29.2/0.92),这意味着U-Net足够强大,可以在此任务中进行特征提取。


4结论
在这项工作中,我们将CT体积表示为一个连续的强度场,并提出了一种新的DIF-Net,用于从极稀疏(≤10)投影视图进行超快速CBCT重建。DIF-Net是一个通用的稀疏视图重建框架,它可以从输入投影中提取3D空间中任意一点的特征,这意味着3D CNN不需要进行特征解码,从而减少了内存需求和计算成本。实验表明,DIF-Net可以进行高效和高质量的CT重建,明显优于以前的最先进的方法。该方法可以在包含不同投影视图和成像参数的大规模数据集上训练,以获得更好的泛化能力,这将是我们未来的工作。
鸣谢本研究获香港创新及科技基金项目PRP/041/22 FX及ITS/030/21,以及佛山科大项目赠款FSUST 21-HKUST 10 E及FSUST 21-HKUST 11 E资助。
学习深度强度场以进行极稀疏视图CBCT重建-补充材料
A. 投影函数φ的公式化
如2.2节所述,3D点被投影到2D成像面板,用于从视图的特征图中查询其视图特定特征。在本节中,我们正式引入投影函数φ。如图4所示,给定世界坐标系中的点,(WCS,下标w),我们首先将其从WCS转换到扫描仪坐标系(SCS,下标s),然后将其从SCS投影到面板坐标系(PCS);最后,获得其在PCS中的二维投影坐标,用于视图特定特征查询。对于简单的公式,我们假设成像面板与SCS的z方向正交,面板中心到PCS原点的偏移为零。
旋转。如图4a所示,给定坐标为pw = [xw,yw,zw] T的点定义在WCS中,我们首先通过旋转矩阵R(α)将pw从WCS变换为SCS,并获得其SCS坐标ps = [xs,ys,zs] T:

其中α是CT扫描仪的旋转角度。
投影。如图4b所示,假设从扫描器源O到成像面板的中心O′的距离为φ 00 ′ = d。投影矩阵A定义为:


图4.(a.)从世界坐标系(3D)到扫描仪坐标系(3D)的旋转。(B.)从扫描仪坐标系(3D)到面板坐标系(2D)的投影。
然后,我们通过投影矩阵A将ps投影到成像面板,并获得投影齐次坐标:
![]()
最后,我们得到PCS中的投影点p ′ = [u,v],其中u = dxs zs和v = dys zs。总之,对于WCS中的点p = [x,y,z] T,投影点p ′ = [u,v] T被公式化为:
![]()
其中β表示成像参数(距离、偏移等),H:R 3 → R 2是将p ′的齐次坐标映射到其笛卡尔坐标的齐次除法。
B.附加实验
重建效率分析。如表5所示,使用较低的输出分辨率(1283),DIF-Net可以实时重建CT。此外,减少投影视图的数量可以加快重建速度。如第2.2节所述,输出分辨率在测试过程中是可伸缩的。因此,我们可以在不同的应用中调整输出分辨率,以在重建时间和图像质量之间进行折衷。
表5.不同输出分辨率(Res.)和不同投影视图数(K)的重建效率比较。

不同投影参数的重建。DIF-Net可以配备最大池进行跨视图融合,并使用不同的投影参数进行训练,以提高真实的场景中的鲁棒性。为了验证上述说法,我们进行了实验,以随机6 - 10视图,随机起始角度,和固定的角度间隔(对于6/7/8/9/10视图为30/26/23/20/18度)。下表6示出了具有不同投影参数的单个训练模型的测试结果。训练模型对于不同数量的输入视图和变化的投影角度是足够鲁棒的,这表明所提出的框架DIF-Net在实际场景中可能是有用的。
C.其他
实现细节。对于训练时间,使用单个3090 GPU分别训练10、15和18小时,用于6视图、8视图和10视图重建。投影配置在我们的代码库中提供。
可视化比较。下面的图5显示了不同数量的输入视图的可视化比较。
















 2744
2744











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









