






一、图像去雾的基本概况
视觉是人类获取信息的主要方式,随着信息技术的发展,人类生产、生活越来越离不开图像。然而在现实生活中,人们拍摄的图像的质量往往受到多种情况的影响。随着成像设备的精度和功能日趋增强,导致图像质量下降的原因主要取决于拍摄的环境,其中雾和霾就是影响图像质量的主要因素之一。
雾是由悬浮近地面空气中微小水滴或冰晶组成的天气现象,是近地面层空气中水汽凝结(或凝华)的产物。霾是悬浮在大气中的大量微小尘粒、烟粒或盐粒的集合体,使空气浑浊,水平能见度降低到10km以下的一种天气现象。从视觉效果上看,雾和霾降低了图像的对比度,破坏了图像原有的细节从而使纹理模糊不清,以及使场景颜色产生偏移。从成像原理上看,雾和霾削弱了光从场景到观测点的传播,加强了大气光对成像的干扰。
自2009年何明凯提出暗原色先验规律后,图像去雾越来越受到广大研究者的关注。目前,图像去雾有两种主要的方法,分别是图像增强和图像复原。采用图像增强去雾是从视觉角度改善雾的影响,采用图像复原去雾是从成像原理逆推原图像,从而去除雾的影响。
面对日益严峻的天气变化,减轻或去除雾天、雨天、雪天等恶劣气候对图像的影响,才能为机器视觉的发展扫清一大障碍。
二、主流图像去雾算法概述
目前去除图像雾气的算法很多,各种去雾方法所取得的效果不同,接下来将介绍三种较为广泛的去雾算法,他们分别利用了图像增强、图像复原已及深度学习的方法来去除雾气。
1、基于Retinex理论的图像增强去雾
雾天图像具有对比度低、颜色偏移、细节丢失三个主要特征,从灰度直方图的分布来看,绝大多数像素点集中在某个灰度区间。雾天图像所造成的视觉影响主要来源于存在雾的区域对比度低,为解决这一问题,又避免从成像原理层面进行复杂推算,采用图像增强的方式是最为划算的。
Retinex理论在图像增强去雾中受到广泛应用,该理论认为目标物体(object)本身不具有颜色,人眼能观察到物体具有颜色,是光与物体反射的结果,不同的物体具有不同的反射特性,因此能呈现出不同的颜色,同时,可以利用不同比例的红、绿、蓝三基色实现所有颜色的组合。基于这两个客观事实,人眼所感知到的物体表面的颜色主要与物体表面的反射特性有关,相较于从其他地方投射到人眼的光线所起的作用更大,因此只要去除掉这部分入射光,就能最大限度保留反应物体本身特性的反射特性,从而恢复物体的原始色彩,从而达到去除雾气的目的。
不同的Reimex算法区别在于他们对于入射光的处理方式有差异,最终导致他们所得到的物体的反射特性不一样,最终优化得到的去雾图片效果也大相径庭。目前的常用方法有单尺度算法(SSR)、多尺度算法(MSR)、带色彩恢复的多尺度算法(MSRCR)。这三种算法对于图片的去雾效果依次变强,尤其是MSRCR还可以降低去雾之后的色彩失真现象,然而其算法的复杂程度、计算时间也大幅度增加,因此需要根据实际处理的图片选择合适的算法方式来去除雾气。

2、基于大气散射模型的暗通道先验方法的图像复原去雾
虽然图像增强去雾算法可以有效改善视觉效果,但是其没有考虑到图像降质的真正原因,仅仅从对比度提升方面对图像增强,易造成图像的细节丢失以及色彩偏失。因此采用图像复原方法对雾气建立降质模型并反演,能较好地完成去雾任务,而目前研究较为完善的便是基于大气散射模型的暗通道先验方法。
大气散射模型是描述雾天成因的主要模型,有入射光衰减模型和大气光成像模型两部分,前者描述的是光从照片上的场景到拍摄的观测点的衰减过程,后者则是描述大气粒子散射作用对拍摄的观测点接收光强的影响。入射光衰减模型指大气散射所引起的光线衰减随设备与目标之间的距离的增加呈指数衰减,同时该模型给出了在单散射情况下的场景内任意位置光强估计,可以更加准确地对雾天模型进行处理。大气光成像模型是指大气光(入射光在传播过程中,与大气中的大半径微粒作用后进入观测点的部分光)随着观测目标距离观测点的距离增加而增加的模型。两者相结合,便可以得到距离观测点的实际光强的计算值。
暗通道先验去雾理论是基于大量清晰图像所得到的暗原色所存在的必然规律,从而得到的先验算法,有着较为广泛的可应用性与实践性。该理论的基础理论是在不含天空的清晰图像中,被称为暗原色的像素点具有很低的亮度值,根据这个特性求出的灰度图像被称为暗通道图,而该图的计算依赖因素有二,一是局部窗口的数量,其数量与包含暗通道的概率呈反比,数量过少则去雾效果不明显,图像过黑;数量过多会导致暗通道图块效应过于明显,因此需要适当选择;第二则是对大气光值以及介质传输率的估计,他决定了算法能否成功还原去雾图像。
3、基于深度学习的图像去雾
图像增强与图像复原都是传统的图像修复的方式,而近年随着人工智能的快速发展,深度学习由于其较强的学习能力在各个领域有着广泛的应用,包括在图像处理方面,接下来将介绍一种基于深度学习的图像去雾方法。
一体化除雾网络(AOD-Net),这是一种基于CNN的除雾模型。它是一种端到端可训练的去雾模型,它直接从有雾图像中产生清晰图像,而不是依赖于任何单独的和中间的参数估计步骤。AOD-Net是基于重新变形的大气散射模型设计的,因此保留了与现有工程相同的物理基础。该物理模型可以以“更多端到端”的方式制定,其所有参数都在一个统一的模型中进行估算。
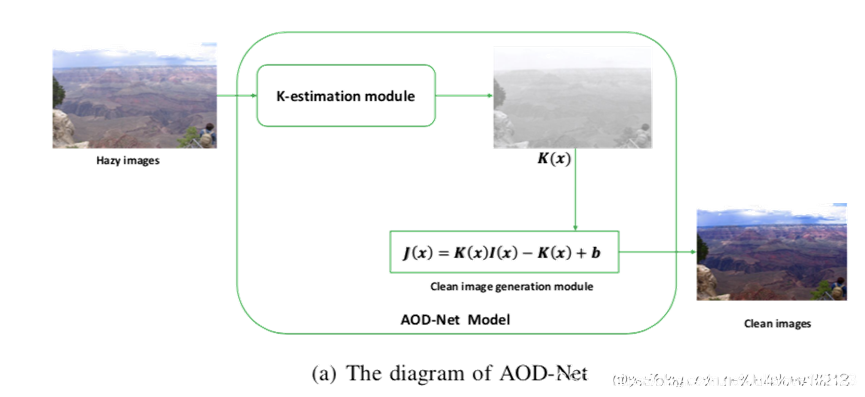
该网络是第一个定量研究去雾质量对后续高级视觉任务的影响,这是比较去雾效果的新客观标准。此外,AOD-Net可以与其他深层模型无缝嵌成一个管道,在有雾图像上执行高级 任务,具有隐式的去雾过程。由于它的一体化设计,这种管道可以从头到尾联合调整,以进一步提高性能,如果用其他深层去雾网络替代AOD-Net是不可行的。
三、基于暗通道—图像增强方法的图像去雾
1、原理和步骤:
由于图像增强算法没有考虑原本含雾图像的噪声,仅仅是增强了图像本身从而达到去除雾气的结果,在一定程度上会加强图像的噪声从而导致图像失真,因此本文采用图像还原算法中的基于大气散射模型的暗通道先验算法对图像进行去雾,在去除了雾气与噪声的情况下使用图像增强算法对图像的质量进行提高,从而达到显著去除雾气,最大幅度提升图像清晰度的目的。
Ⅰ.暗通道基本原理与公式
根据前文所定义的暗通道,可以归纳出对于图像J而言,暗通道的表达式可以写为:

式(2)中,A为大气光值估计值,t(x)为介质透射率估计值,I(x)为待去雾复原图像,J(x)为最终得到图像。为了处理掉实际图像中的过亮像素点以及大量噪声,需要限制t(x)的最小值t0。数学模型变为:




3、主要代码:
(1)暗通道相关代码。(见附录DarkChannel.py)
(2)ACE相关代码。(见附录ACE.py)
(3)主函数。(见附录main.py)
4、实现结果图像(左侧为原图,中间为暗通道处理图,右侧为最终结果):
(1) Bench:

(2) Cones:

(3) Dubai:

(4) Forest:

(5) Herzeliya:

(6) Neighbour:

(7) Pumpkins:

(8) Road:

(9) Tiananmen:

(10) Train:

四、对比分析:
经过暗通道先验理论处理、大气散射模型反演计算、自适应对比度增强,较好地改变了原始的雾天图像。处理前后的图像如下所示:

在图4.1中,原始图像的远景部分雾气较浓,经暗通道先验方法处理后,远处的浓雾基本被除去,但图像左上方(很可能是天空的背景)有较明显的纹理失真,且像素值偏高。近景去雾成效明显,但像素值整体上偏暗。这与暗通道先验处理方法对远近成像深度处的光强估计出现偏差相符合。调整图像整体对比度后,图像整体得到亮度增强,且细节更加完善,但导致了部分区域出现一定的失真。

在图4.2中,原始图像远景部分雾气较浓,经暗通道先验方法处理后,图像整体上消除雾气的干扰,除雾效果显著,但整体的像素值偏低,远景的对比度偏低(视觉上存在模糊感,好似铺上一层较淡的雾)。当图像缺少天空背景时,经过大气散射模型反演后能较准确地计算出各个像素的光强估计。调整图像整体对比度后,图像出现较为明显的颜色失真,这可能是选通分界频率偏小导致的不平衡滤波,从而加剧了图像的增强所引起的。

在图4.3中,原始图像雾气较轻,经暗通道先验方法处理后,图像整体上消除雾气的干扰,但整体的像素值偏低,对比度不足。调整图像整体对比度后,图像对比度明显提高,但远景部分受背景(沙漠)的影响较大,色彩上不协调。

在图4.4中,原始图像中雾气聚集在远景部分,远景细节丢失严重,经暗通道先验方法处理后,图像整体上去雾效果较好,景深处雾气去除干净,但靠近光强较大的背景(天空)部分存在雾气残余,景深处的物体细节不够完善。调整图像整体对比度后,整体的图像细节更加突出,但仍未能去除雾气残余。

在图4.5中,原始图像雾气较淡,随着景深雾气逐渐加重,经暗通道先验方法处理后,图像整体上消除雾气的干扰,由于没有天空背景,图像还原效果符合主观视觉,而调整图像整体对比度后,图像反而因过度增强而偏离主观视觉。这可能是选通分界频率偏小导致的不平衡滤波,从而加剧了图像的增强所引起的。

在图4.6中,原始图像雾气较浓,且图像整体偏暗。经暗通道先验方法处理后,图像整体上消除雾气的干扰,但由于偏暗图像应用暗通道先验方法,图像还原后像素值整体偏低,影响了图像的对比度和纹理细节。调整图像整体对比度后,图像细节的还原效果较好,但过强的对比度偏离了原图像的还原视感。

在图4.7中,原始图像雾气较浓,随着景深雾气逐渐加重,丢失了远景处的细节。经暗通道先验方法处理后,图像整体上消除雾气的干扰,但由于暗通道先验方法对已丢失的远景物体不敏感,远景被估计为天空(背景),并且无法精确还原细节,产生了局部像素块(看起来像是存在模糊或加入了噪声)。调整图像整体对比度后,近景出现一定程度的颜色失真,图像整体受噪声影响明显,偏离了原图像的还原视感。

在图4.8中,原始图像雾气较淡,图像整体亮度适中。经暗通道先验方法处理后,图像整体上消除雾气的干扰,且远景去雾效果显著,唯有近景亮度值估计偏低这一瑕疵。调整图像整体对比度后,近景亮度值有较大的改善,且远景细节更加突出,还原效果显著。

在图4.9中,原始图像雾气较浓,随着景深雾气逐渐加重,丢失了远景处的细节。经暗通道先验方法处理后,图像整体上消除雾气的干扰,但图像右上方(很可能是天空背景)存在一定的纹理失真和颜色偏移。这是暗通道先验方法对已丢失细节不敏感所导致的。调整图像整体对比度后,近景得到增强而远景受到削弱,近景细节增强而远景噪声被放大,偏离了原图像的还原视感。

在图4.10中,原始图像雾气较浓,物体主要集中在雾气较浓的远景处,且物体的细节基本丢失。经暗通道先验方法处理后,图像整体上基本消除雾气的干扰,但整体像素值偏低,远景物体的细节没有很好的显示。这表明了暗通道先验方法对远景细节既能还原又有丢失的特性。调整图像整体对比度后,图像整体对比度得到很好的改善,远景物体的细节也得到一定程度的还原,但放大了天空(背景)附近的噪声,整体上符合还原视感。
五、总结和展望:
图像去雾理论和算法的研究至今还在发展,真正能实现对大部分图像的精确处理仍是难题。以retinenx理论为指导的图像增强去雾算法和以暗通道先验理论为指导的图像复原去雾算法,在大多数应用场合已经满足要求,且得到实践验证。结合图像复原和图像增强的去雾算法实现了去雾图像的进一步优化,去雾效果更加显著。然而,复合去雾算法在部分应用图像上的处理效果存在波动,处理结果往往受到中间过程的影响。深度学习在图像去雾中的应用给我们提供了新的方案,依靠庞大的雾天图像数据,能有效解决传统方法对雾的特征理解不深刻和对高亮度背景的估计、已丢失细节的估计的偏差的问题。当然,效果显著的网络必然需要提供大量不同分布的图像,这对训练样本的获取提出了较高的要求。
本文结合图像复原与图像增强在去雾领域的理论和方法,提出暗通道先验复原—ACE增强方法,既保证去雾方法(复原)符合客观规律,又促进还原效果(增强)贴合主观视感,找到解决复原结果不精确和主观视感要求严格之间的矛盾的思路。当雾天图像整体雾气适中,远景受雾气影响较严重,但仍有模糊的细节时,采用本方法的处理效果较为显著。当雾天图像远景雾气十分严重,且很可能是天空背景时,采用本方法容易造成过度增强。
想要得到更高精度的去雾效果,还需要结合图像分割进行局部处理,充分发挥暗通道先验方法和自适应对比度增强方法在处理具体区域中的优势。从工程的角度出发,还应该基于机器学习建立分类和评价系统,使不同样式的图像得到不同的处理方案,满足要求的图像不进行多余的处理。这样才能高效地解决天空、景深、暗色、噪声所带来的影响。图像去雾方法与机器学习、深度学习的融合,更有可能提出新的解决方案,无论是用在图像去雾处理本身,还是用在验证和发展图像复原和增强的理论上,是未来的发展方向。
附录
# 1.DarkChannel.py
import cv2
import numpy as np
# 最小值滤波,r是滤波器半径
def zmMinFilterGray(path,r):
zmMinFilterGray=cv2.erode(path, np.ones((2*r+1,2*r+1)))
return zmMinFilterGray
# 引导滤波-制导图像:I(应为灰度/单通道图像)
# 过滤输入图像:p(应为灰度/单通道图像)
# 局部窗口半径:r
# 正则化参数:eps
def guidedfilter(I,p,r,eps):
height, width = I.shape
mean_I = cv2.boxFilter(I,-1,(r,r))
mean_p = cv2.boxFilter(p,-1,(r,r))
mean_Ip = cv2.boxFilter(I*p,-1,(r,r))
cov_Ip = mean_Ip-mean_I*mean_p
mean_II = cv2.boxFilter(I*I,-1,(r,r))
var_I = mean_II-mean_I*mean_I
a = cov_Ip/(var_I+eps)
b = mean_p-a * mean_I
mean_a = cv2.boxFilter(a,-1,(r,r))
mean_b = cv2.boxFilter(b,-1,(r,r))
q = mean_a*I+mean_b
return q
# 计算大气遮罩图像V1和光照值A, V1 = 1-t/A
# 输入rgb图像,值范围[0,1]
def getV1(m, r, eps, w, maxV1):
V1 = np.min(m, 2) # 得到暗通道图像
V1 = guidedfilter(V1,zmMinFilterGray(V1,7), r, eps)
# 使用引导滤波优化
bins = 2000
ht = np.histogram(V1, bins) # 计算大气光照A
d = np.cumsum(ht[0]) / float(V1.size)
for lmax in range(bins - 1, 0, -1):
if d[lmax] <= 0.999:
break
A = np.mean(m, 2)[V1 >= ht[1][lmax]].max()
V1 = np.minimum(V1 * w, maxV1) # 对值范围进行限制
return V1, A
def deHaze(m, r=81, eps=0.001, w=0.95, maxV1=0.80, bGamma=False):
Y = np.zeros(m.shape)
# 得到遮罩图像和大气光照
V1,A = getV1(m, r, eps, w, maxV1)
# 颜色校正
for k in range(3):
Y[:,:,k] = (m[:,:,k]-V1)/(1-V1/A)
Y = np.clip(Y, 0, 1)
# gamma校正,默认不进行该操作
if bGamma:
Y = Y**(np.log(0.5)/np.log(Y.mean()))
return Y
def DarkChannel(img):
path = 'figure\\'
fn = path + img
m = deHaze(cv2.imread(fn)/255.0)*255
cv2.imwrite("DarkChannel/"+img, m)
# 2. ACE.py
#饱和函数
import cv2
import numpy as np
import math
import matplotlib.pyplot as plt
# 线性拉伸处理
# 去掉最大最小0.5%的像素值 线性拉伸至[0,1]
def stretchImage(data, s=0.005, bins=2000):
ht = np.histogram(data, bins);
d = np.cumsum(ht[0]) / float(data.size)
lmin = 0;
lmax = bins - 1
while lmin < bins:
if d[lmin] >= s:
break
lmin += 1
while lmax >= 0:
if d[lmax] <= 1 - s:
break
lmax -= 1
return np.clip((data - ht[1][lmin]) / (ht[1][lmax] - ht[1][lmin]), 0, 1)
# 根据半径计算权重参数矩阵
g_para = {}
def getPara(radius=5):
global g_para
m = g_para.get(radius, None)
if m is not None:
return m
size = radius * 2 + 1
m = np.zeros((size, size))
for h in range(-radius, radius + 1):
for w in range(-radius, radius + 1):
if h == 0 and w == 0:
continue
m[radius+h,radius+w]=1.0/math.sqrt(h**2+w**2)
m /= m.sum()
g_para[radius] = m
return m
# 常规的ACE实现
def zmIce(I, ratio=4, radius=300):
para = getPara(radius)
height, width = I.shape
zh = []
zw = []
n = 0
while n < radius:
zh.append(0)
zw.append(0)
n += 1
for n in range(height):
zh.append(n)
for n in range(width):
zw.append(n)
n = 0
while n < radius:
zh.append(height - 1)
zw.append(width - 1)
n += 1
# print(zh)
# print(zw)
Z = I[np.ix_(zh, zw)]
res = np.zeros(I.shape)
for h in range(radius * 2 + 1):
for w in range(radius * 2 + 1):
if para[h][w] == 0:
continue
res+=(para[h][w]*np.clip((I-Z[h:h+height,w:w+width]) *ratio,-1,1))
return res
# 单通道ACE快速增强实现
def zmIceFast(I, ratio, radius):
# print(I)
height, width = I.shape[:2]
if min(height, width) <= 2:
return np.zeros(I.shape) + 0.5
Rs = cv2.resize(I,(int((width+1)/2),int((height + 1) / 2)))
Rf = zmIceFast(Rs, ratio, radius) # 递归调用
Rf = cv2.resize(Rf, (width, height))
Rs = cv2.resize(Rs, (width, height))
return Rf + zmIce(I, ratio, radius) - zmIce(Rs, ratio, radius)
# rgb三通道分别增强 ratio是对比度增强因子 radius是卷积模板半径
def zmIceColor(I, ratio=4, radius=3):
res = np.zeros(I.shape)
for k in range(3):
res[:,:,k]=stretchImage(zmIceFast(I[:,:,k],ratio, radius))
return res
# 主函数
def ACE(imgname):
img = cv2.imread('DarkChannel/'+imgname)
res = zmIceColor(img / 255.0) * 255
cv2.imwrite('ACE/'+imgname, res)
# 3.main.py
from ACE import *
from DarkChannel import *
from connect import *
picture=["bench_original","cones_original","dubai_original","forest_original","herzeliya_original","neighbour_original","pumpkins_original","road_original","tiananmen_original","train_original"]
for picturename in picture:
DarkChannel(picturename+".jpg")
ACE(picturename+".jpg")
connect(picturename+".jpg")

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









