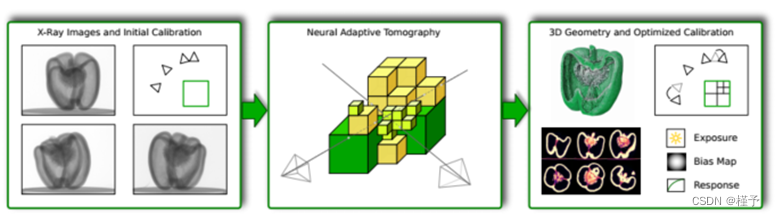
图1所示。神经自适应断层扫描使用混合显式-隐式神经表示层析图像重建。左:输入是一组x射线图像,通常具有病态的几何配置(稀疏的视图或有限的角度覆盖)。中心:NeAT将场景表示为在每个叶节点上具有神经特征的八叉树。本文提出了一种高效的可微分渲染算法。右图:通过神经渲染,NeAT可以重建三维几何结构,即使是病态构型,同时进行几何和辐射自校准。
摘要:在本文中,我们提出了神经自适应断层扫描(NeAT),这是第一个用于多视图逆绘制的自适应分层神经绘制管道。通过将神经特征与自适应显式表示相结合,我们实现了远优于现有神经逆绘制方法的重建时间。自适应显式表示通过促进空白空间剔除和集中复杂区域的样本来提高效率,而神经特征则作为三维重建的神经正则化器。NeAT框架是专门为层析成像设置而设计的,它只包含半透明的体积场景,而不是不透明的物体。在这种情况下,NeAT的质量优于现有的基于优化的断层扫描求解器,同时速度要快得多。
CCS概念:•计算方法→重建;3 d成像;计算摄影;相机标定;分层表征;正则化;无监督学习;计算摄影
附加关键词:x射线计算机断层扫描,隐式神经表征,八叉树
计算机断层扫描(CT)是一种重要的科学成像方式,在广泛的领域,从医学成像到材料科学。虽然大多数CT成像是用x射线进行的,因为它们能够穿透各种材料[Kak和Slaney 2001],但也有一些利用可见光的工作,特别是在视觉计算社区(例如[Atcheson等人2008;Eckert等人2019;Gregson et al . 2012;Hasinoff and Kutulakos 2007;Zang et al . 2020])。
层析重建问题是根据样本的二维投影估计其三维结构的任务。在某些条件下,例如足够多的投影/视图,这些视图的良好角度覆盖范围以及低噪声,此任务是很好的。在这种情况下,基于变换的方法,如滤波后的反向投影[Feldkamp等人1984]提供了快速准确的重建。不幸的是,如果违反上述条件(视图数量少、角度分布差或噪声高),这些方法不再产生令人满意的结果。对于这些类型的困难设置,近年来开发了一系列基于迭代优化的方法(例如[Huang等人2013,2018;Sidky and Pan 2008;Xu et al . 2020;Zang等,2018a]。这些新方法极大地扩展了可行层析重建问题的范围,尽管计算成本显著增加。
与此同时,神经渲染(例如[Garbin et al 2021;Liu et al . 2020b;Reiser等人2021])和一般的可微分渲染(例如[Nimier-David等人2019])最近引起了人们对视觉计算的极大兴趣。特别是神经辐射场(Neural Radiance Fields, NeRF) [Mildenhall et al . 2020]和相关的反向渲染框架,由于它们能够提供具有不透明物体的日常场景的卓越重建,一直是人们关注的焦点。类似的概念也已经应用于层析重建问题[Sun et al . 2021;Zang et al . 2021]。然而,现有的所有神经逆渲染框架都存在计算时间过长的问题。层析成像方法也是如此,尽管只能在二维切片几何上操作,这限制了它们对高分辨率数据集和我们在这项工作中使用的全三维锥束数据的适用性。
在本文中,我们提出了神经自适应断层扫描(NeAT),这是第一个用于多视图逆绘制的自适应分层神经绘制管道。通过将神经特征与自适应显式表示相结合,我们实现了远优于现有神经逆绘制方法的重建时间。自适应显式表示通过促进空白空间剔除和集中复杂区域的样本来提高效率,而神经特征则作为三维重建的神经正则化器。
NeAT专门针对层析重建问题,其中样本广泛分散在整个体积中,而许多现有的系统,如NeRF [Mildenhall等2020]依赖于不透明表面附近的高浓度样本。在这种层析设置中,我们证明了纯显式分层表示的NeAT在质量和计算时间方面优于纯隐式表示以及类似于ACORN的混合显式-隐式表示[Martel等人2021]。此外,与最先进的层析成像重建方法相比,NeAT显示出更高的重建质量,同时与其性能相匹配。
总之,我们工作的主要贡献是:
•基于带有神经特征的显式八叉树表示的自适应分层神经渲染管道。
•用于x射线成像的可微分物理传感器模型,可在重建过程中进行优化。
•一个有效的开源实现,可以很容易地用于新的数据集。
•对合成数据和真实数据的不同具有挑战性的层析成像重建(稀疏视图、有限角度和噪声投影)进行了广泛的评估。
2相关工作
2.1经典计算机断层扫描
计算机断层扫描是一种成熟的技术,用于成像被扫描物体的内部结构。它在许多领域都有应用,比如医学和生物学[Kiljunen et al . 2015;Piovesan等2021;Rawson et al . 2020;Van Ginneken et al . 2001],材料科学[Brisard et al . 2020;Vásárhelyi等2020]和流体动力学[Atcheson等人2008;Eckert等人2019;Gregson et al . 2012;Hasinoff and Kutulakos 2007;Zang et al . 2020]。
在所有的CT模式中,从不同的方向捕获多个投影图像(sinogram)。然后,应用重建算法从获取的投影集合中检索扫描对象的三维表示。层析成像重建中已经部署了几种算法族。基于Radon变换及其逆的解析方法,如滤波反投影(FBP)及其三维锥束变体FDK (Feldkamp, Davis, and Kress) [Feldkamp et al . 1984],在商用CT设备中使用最多[Pan et al . 2009]。当有大量均匀采样的投影时,这些方法速度快,精度高。然而,在许多情况下,由于各种原因,如x射线剂量的减少[Gao et al . 2014],样品的变形[Zang et al . 2018b, 2019],或从某些方向无法接近[Du et al . 2021a],获得的投影数量较低。对于这种情况,迭代重建方法已被提出来解决不适定层析成像问题的离散公式。这些技术的主要兴趣在于在优化框架中加入正则化术语(如总变化)的可能性[Abujbara等人2021;Huang等2013,2018;Kisner等人2012;Sidky and Pan 2008;Xu et al . 2020;Zang等2018年]。超参数调优和计算量大是这些方法的主要缺点。
2.2基于学习的计算机断层扫描
最近,基于学习的方法已经成为基于优化的重建的替代方案。大多数最初提出的方法将神经网络作为传统重建方法的预处理或后处理步骤,以提高重建质量。预处理网络通过绘制投影来改善逆问题的调节[Anirudh等人2018;Ghani和Karl 2018;Tang等人2019;Yoo et al . 2019];后处理网络对重构体进行校正和去噪[Liu et al . 2020a;Lucas等人2018;Pelt et al . 2018]。第三种策略包括使用具有可微前向模型的网络来学习重建算子[Adler和Öktem 2018;Chen et al . 2018;他等人2020;Kang et al . 2018]。这些方法在类似于用于训练的数据上获得高质量的结果。然而,当应用于看不见的数据时,它们确实存在大量缺乏泛化的问题。
为了克服这一限制,最近的研究引入了深度图像先验(DIP) [Baguer et al 2020;Barutcu et al[2021]结合经典正则化来约束重建问题。另一方面,一些研究提出了基于隐式神经表示的新方法[Sun等人2021;Zang等2021]以基于自监督学习的方式处理断层扫描重建。在这种方法中,使用多层感知器(MLP)网络将扫描对象的密度场表示为输入坐标的函数。然后从捕获的投影中学习这个网络。这种表示提供了在任何所需分辨率下生成合成投影的改进的灵活性。这种方法在重建质量方面优于其他现有技术。然而,尽管它们只在基于并行光束数据的二维切片上操作,但它们需要大量的记忆,并且需要相当长的学习时间,在几个小时的范围内。因此,它们不适合全三维锥形光束重建。在本文中,我们提出了一种自适应神经渲染框架来克服这些限制,并在几分钟内实现全三维锥束数据的高质量重建。
在大多数层析应用中,由于运算符的简单性,一个明确的、规则的体素网格是选择的表示。在计算机图形学和计算机视觉中,基于坐标的神经网络,也被称为隐式神经表征,最近作为一种替代方案出现。它们由一个神经网络组成,通常是一个MLP,用来学习将空间坐标映射到一些物理属性领域(例如占用、密度、颜色等)的函数。这种表示的主要优点是表示的信号或是为任何给定坐标隐式定义的。换句话说,与离散体素网格相比,这种表示是连续的。在过去的两年中,这些基于坐标的网络已经成功地应用于静态和动态3D场景和形状的建模[Du等人2021b;Martin-Brualla等2021;Park等人2019;Sitzmann et al 2020;Xian et al . 2021],综合新颖观点[Chan et al . 2021;Eslami等人2018;米尔登霍尔等人2020;Niemeyer等2020;Schwarz et al 2020;Sitzmann et al . 2019],合成织构[Chibane and Pons-Moll 2020;Oechsle等人2019;Saito et al . 2019],估计姿态[Su et al . 2021;Wang等2021;Yen-Chen等人2020],以及重新照明和材料编辑[Boss等人2021;Srinivasan等2021;Xiang等2021;Zhang et al . 2021]。除了巨大的学习时间外,当切换到3D体素网格时,基于坐标的网络的渲染速度也很慢。实际上,网络必须对每个单独的体素进行评估,而不是直接查询数据结构。
为了提高基于坐标的神经网络的体绘制速度,已经提出了几种技术。在神经稀疏体素场(Neural Sparse Voxel Fields, NSVF)方法[Liu et al . 2020b]中,场景被组织成一个稀疏体素八叉树,并在学习过程中动态更新。在渲染期间,将跳过空白区域,并强制提前终止光线。在kiloNeRF方法[Reiser等人2021]中,标准NeRF网络被分解为较小mlp的3D网格,以加快渲染过程。AutoInt技术[Lindell等人2021]是基于直接学习沿射线的体积积分的网络,与NeRF网络相比,这使得渲染步骤更快。FastNeRF [Garbin等人2021]使用缓存来实现更快的渲染。标准的NeRF网络被分成两个mlp:一个位置依赖网络生成深辐射图向量,而第二个网络输出给定光线方向的相应权重。Yu等人[2021]提出了一种改进版本的NeRF网络来预测存储在“pleenoctree”结构中的体积密度和球谐权。然后使用渲染损失对这个八叉树结构进行微调以提高其质量。这种方法允许实时渲染,但是,训练步骤仍然很慢。
与神经渲染方法并行,研究人员也在研究如何简单地使用神经网络来表示现有的图像和体积,而不首先解决一个逆问题。在ACORN方法中[Martel等人2021],作者引入了一种隐式-显式混合坐标神经表示。通过多尺度网络架构加速学习过程,并在训练过程中以粗到精的方式进行优化。NeAT在某种程度上受到了所有这些方法的启发,但它是第一个通过直接训练分层神经表示来解决场景重建问题的方法。我们在大幅度改进的训练时间内显示出更高质量的结果。
我们将3D场景表示为一个稀疏的八叉树,其中每个叶节点可以是空的,也可以包含一个统一的神经特征网格。为了查询给定位置的密度,三线性插值神经特征向量通过一个小的解码器网络传递。给定一组x射线输入图像,通过可微体积渲染优化神经特征。在优化过程中,对八叉树结构进行细化,并从树中去除空叶节点。由于所有步骤都是可微的,我们还可以执行自校准来计算精确的相机姿势,光度检测器响应和每个图像捕获能量。我们的呈现管道的概览如图2所示。
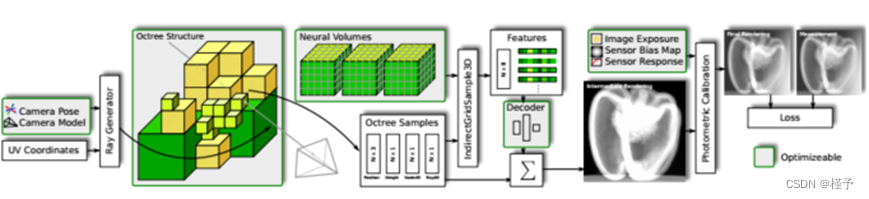
图2所示。层析重建的自适应神经渲染管道概述。为了渲染单个像素,我们生成相应的光线,计算光线与八叉树的相交,对神经体进行采样,解码神经特征,并通过加权和对它们进行积分。然后将估计的像素值通过光度校准模块,从而得到最终的像素强度。绿框中的所有元素都在重建过程中进行了优化。这包括几何和光度校准、八叉树结构、神经特征体积和神经解码器网络。
数字x射线设备的原始图像表示通过物体的特定射线的透射图像。这种情况下的图像形成模型源自Beer-Lambert定律的连续版本[Kak and Slaney 2001]。对于给定的图像像素𝑝,观测到的像素值为:

其中,𝐼0为x射线源的强度(可能存在空间变化),𝑟𝑝为与图像像素𝑝相关的射线,𝑡𝑛和𝑡𝑓为代表重建区域的场景边界框的入口(近)点和出口(远)点的射线参数。在层析成像中,我们试图重建该边界框内的三维分布(衰减截面或密度)。这种重建通常被执行在对数空间中,即:
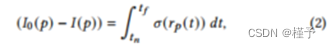
与𝐼= log°𝐼和𝐼0 = log°𝐼0。在这个公式中,每个像素值𝐼(𝑝)被计算为沿相应的观察射线𝑟𝑝的线积分。(2)的离散化将积分转化为有限和。
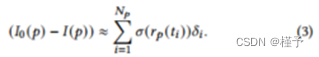
在这里,𝑝表示特定射线的样本数,𝛿表示样本所覆盖的射线段的长度(见下一小节)。
给定八叉树结构和特定的光线𝑟,光线追踪的第一步是生成加权样本列表{(𝑡0,𝛿0),(𝑡1,𝛿1),…}。此过程如图3所示,首先计算射线段{(𝑛0,𝑡𝑛0,𝑡𝑓0),(𝑛1,𝑡𝑛1,𝑡𝑓1),…}对应于该射线与八叉树节点𝑛的交点。每个段由节点ID和段的近、远点对应的标量射线参数𝑡𝑛、𝑡𝑓组成。然后,我们确定沿每个段放置多少个样本:
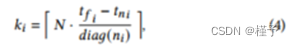
其中,二百元操作是表示每个节点的最大样本数的超参数,而𝑑 ̄𝑎𝑔(𝑛 ̄)是节点𝑛 ̄的对角线大小。
这种方法确保𝑘∈[1,N],并且样本的数量与段的相对长度成正比,但与节点大小无关。平均而言,小节点获得与大节点相同数量的样本,这反过来又在细分区域中产生更高的样本密度,这些区域已被确定为高几何复杂性的区域。
一旦确定了𝑘(),就对区间进行均匀抽样(在测试阶段)或分层随机抽样(在训练阶段)。最后,我们计算样本权值𝛿𝑗为:
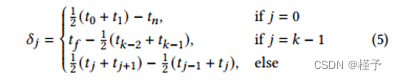
注意,Eq.(5)对应的是中心差分的数值积分,而相关工作,即NeRF [Mildenhall et al 2020],只利用了前向差分。这种方法与分层自适应采样不兼容,因为中间的空节点破坏了跨节点边界的前向集成。
在对光线进行采样后,下一步是在采样位置检索神经特征向量。为此,我们计算全局坐标x𝑔=𝑟(𝑡),并将其转换为包含叶节点的局部空间。然后使用这个局部坐标对正则进行采样神经特征的网格𝑓,并用三线性权值进行插值,得到样本位置的特征向量𝑓(x)。该过程如图4所示。请注意,在两个节点之间的边界处,重复和非流形特征存储在内存中。正则化器被用来解决这个问题(参见第3.5节)。
由于我们的采样策略(参见3.2节),每个射线和每个节点可以有不同数量的样本分配给它们。为此,我们实现了一个间接的三维网格样本核,它可以从局部坐标和节点ID一步计算神经特征向量。实验表明,该自定义层的效率大约是使用标准深度学习操作符的排序和批处理实现的三倍。
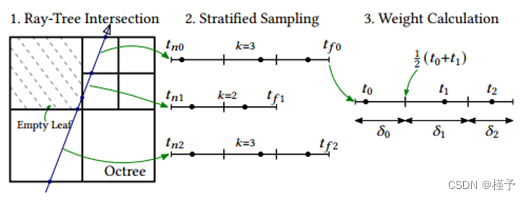
图3所示。稀疏八叉树结构的射线采样。(1)。计算非空叶节点的交点间隔。(2)。样本采用分层随机抽样进行分布。注意,区间(𝑡𝑛0,𝑡𝑓0)和(𝑡𝑛2,𝑡𝑓2)被分配了相同的𝑘= 3个样本数,尽管后者覆盖了更多的空间。(3)。积分权值𝛿由式(5)计算。
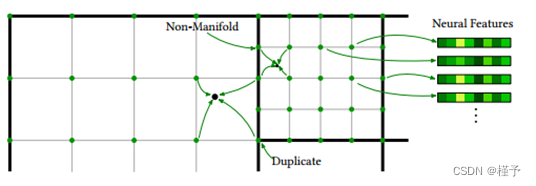
图4所示。八叉树结构的部分,显示每个节点内均匀网格的对齐和采样。在不同节点的边界处,有些特征是重复的,有些特征是非流形的。
一旦获得特征向量,我们使用全局解码器网络将其转换为所需的输出域:
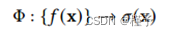
在所有节点之间共享。在层析成像的情况下,输出是一个标量,表示样本点x处的体积密度(x)。解码器本身是一个三层MLP,每个MLP有64个神经元,总共有4801个参数需要学习。我们在MLP内部使用SiLU激活函数[Elfwing等人2018],并在最后一层之后使用单个SoftPlus激活,以获得物理上有意义的正密度值。最后,将密度值乘以每个样本的权重𝛿,并使用散射-相加运算求和,得到式(3)的射线积分。
我们使用估计和测量的射线积分之间的均方误差、总变差(TV)正则化器和边界一致性(BC)正则化器来优化神经特征和解码器参数。
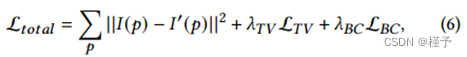
其中𝐼'(𝑝)是射线𝑟𝑝的估计射线积分,𝐼(𝑝)是测量的图像强度,而𝑇s, l, l是控制每个正则化器强度的超参数。
在训练过程中,电视损失作为一个额外的空间正则化,与基于优化的方法中使用的电视损失具有相似的作用。为了计算TV损失,我们利用每个节点特征网格𝑓𝑛的规则结构。损失可以直接在特征向量上计算,也可以在解码密度上计算:
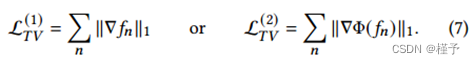
我们对两种变体都进行了实验,发现除了速度更快之外,前一种变体产生的结果略好一些。
边界一致性正则化器确保两个相邻节点之间的平滑过渡。这一点很重要,因为如3.3节所述,重复的和非流形的特征是沿着节点边界存储的。这将导致像块一样的工件,特别是当只使用少量图像时。正则化器将相邻的两个八叉树节点𝑛和*在边界表面Λ𝑛𝑚上的特征误差最小化:
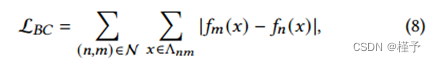
式中,N为所有相邻节点对的集合。
真实数据的CT重建通常需要几个关于相机几何和辐射特性的校准步骤。
放射自校准。从式(2)中可以看出,层摄影重建需要一个代表没有物体存在的照明模式的参考图像𝐼0。在锥束CT中,该图像捕获的效果如由于余弦和1/𝑟2项导致的图像边界的强度下降,以及照明中的任何其他不均匀性。不幸的是,从设置中添加或删除对象也会干扰参考图像的有效性,从而导致重建中的伪影。NeAT框架的可微分特性允许我们改进(或从头开始估计)参考图像𝐼0,以及每个视图的每个视图乘数表示可能不同的曝光时间。如果物体在一个方向上比在另一个方向上厚得多,则适当改变曝光时间。根据数据集的不同,优化这些参数可以显著提高重建质量。
几何自校准。高分辨率层析成像重建也依赖于高精度的相机外部和内部。虽然在锥束CT中,相机姿势通常由高精度转台控制,但诸如精确视场或旋转轴在图像平面上的确切位置等参数很难精确校准,而且实际上,由于热膨胀和其他因素,它们可能会随着时间的推移而漂移。我们建议只使用近似参数估计来获得相机模型的正确范围,然后依靠梯度反向传播来更新相机参数,包括源和检测器的相对位置,以及视图之间的确切旋转角度。
为了在重建过程中自动更新八树结构,我们大致遵循ACORN [Martel et al . 2021]的方法。然而,虽然ACORN可以访问单元格中每个点的地面真实图像/体数据,但在层析重建任务中不可用,因为层析重建任务中唯一可用的误差度量是每个视图中的2D重投影误差。
从这个二维图像空间误差中,我们通过对与给定节点相交的射线的所有重投影误差求和来估计体积误差分布。例如,对于特定节点𝑛,节点错误变为:
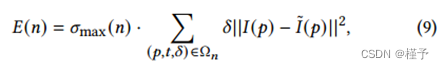
其中Ω𝑛是指𝑛中通过节点𝑛的任何射线的所有样本(𝑡,𝛿)的集合,与生成该射线的像素坐标𝑝配对。𝐼指的是当前预估体积的重新投影。因此,求和项对应于重投影误差的粗层析重建,在八叉树节点上进行积分。这种体积误差度量另外由节点的最大密度来加权,𝜎max(𝑛)= max(𝑡,𝛿)∈Ω𝑛(𝑟(𝑡))。
利用每个节点的误差,我们解决了一个混合整数程序(MIP),它找到了关于重值目标函数的最佳树配置。线性约束确保最多使用𝑇𝑚𝑎个叶节点,并且配置是有效的八叉树。详细信息可以在[Martel等人2021]以及我们的源代码中找到。
4.1数据集和评价指标
下面,我们在不同的CT数据集上进行了几个重建实验。我们将这些数据集分为两类:真实数据和合成数据。真实的数据集是使用尼康工业CT扫描仪捕获的。这些图像是有噪声的,预计会有一些几何和辐射校准误差。由于我们没有真实数据集的真实量,我们使用重投影误差来评估性能。特别是,扫描仪为我们提供了一组真实的x射线图像,我们将其分为训练集和测试集。训练集用于重建卷,测试集用于评估。图5显示了所有真实数据集的3D效果图。
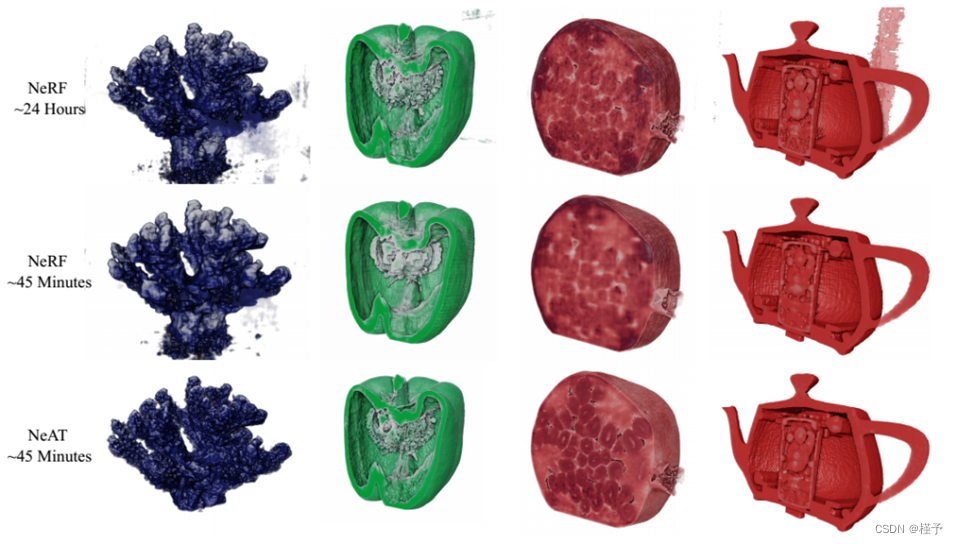
图5所示。真实数据集的三维体效果图,由NeRF和NeAT使用25-50投影重建。从左到右:陶瓷珊瑚,胡椒,石榴,上发条茶壶。二维切片对比如图12所示。
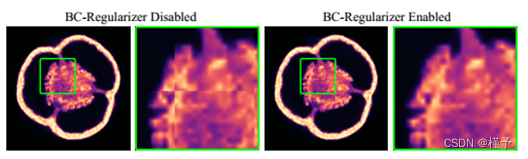
图6所示。有无边界一致性(BC)正则化器的Pepper数据集稀疏视图层析成像。相邻八叉树节点边界处的锐边被成功移除。
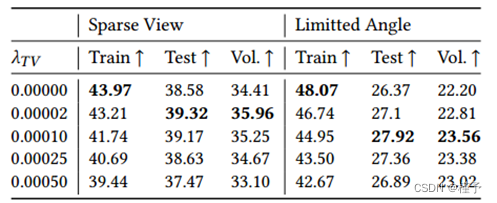
表1。训练视图和测试视图的重投影误差(PSNR),以及胡椒数据集上不同TV正则化值的体积PSNR。
合成数据集以在规则体素网格上采样的体积形式给出,我们使用它从不同角度生成合成x射线图像。通过构造,在渲染视图中没有校准误差或图像噪声,但是我们添加了一些合成高斯噪声。为了评估合成数据集的重建质量,我们可以直接将估计体积与地面真实体积进行比较,尽管重投影误差也可以用于评估过拟合。
Regularziation。为了正则化重构,我们实现了TV-和bc -正则化器(参见第3.5节)。b正则化器(Eq. 8)确保相邻之间的平滑过渡八叉树节点。图6演示了这一点,如果BC被禁用,它显示了类似块的工件。我们发现,在所有的数据集上,变量变量= 0.01都能得到很好的结果,因此可以在进一步的实验中使用。电视正则化器(Eq. 7)用于进一步约束欠确定重建问题,即稀疏视图和有限角度断层扫描。表1显示了训练视图和之前未见过的测试视图上的重投影错误。此外,我们直接显示体积误差。训练和测试重投影误差表明,增大𝑇- q - q值可以减小过拟合。这也改善了体积误差。我们发现稀疏视图问题(𝑇= 0.00002)和有限角度问题(𝑇= 0.00010)给出了最好的结果。
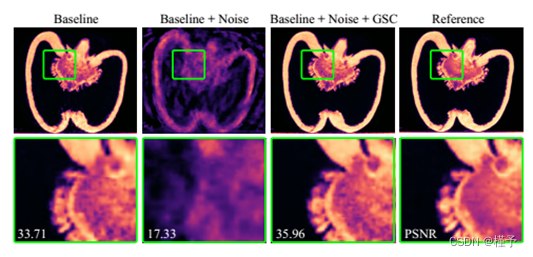
图7所示。几何自标定在实际数据上的消融研究。基线(左列)是使用CT扫描仪提供的初始校准进行重建。在校准中添加噪声会显著降低结果(第二列)。我们的几何自校准(GSC)可以从噪声输入中恢复,甚至稍微优于基线校准(第三列)。
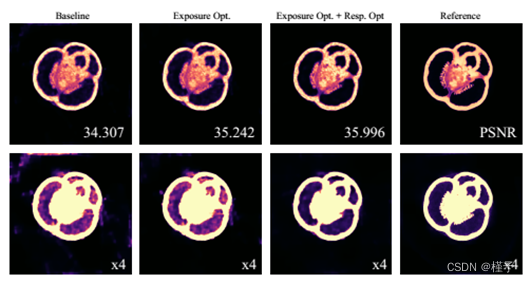
图8所示。胡椒数据集的稀疏视图层析成像,有和没有辐射自校准。底部一行显示相同的音量乘以4,以突出嘈杂的空区域。
几何自校准。如3.6节所述,我们的系统可以在重建过程中优化几何参数,如探测器方向和源位置。在图7中,我们展示了启用和禁用几何自校准的真实数据集上的差异。在左边,基线实验是使用CT扫描仪的几何结构呈现的。然后我们对每个视图的位置和旋转添加高斯噪声。这使重构降低了15 dB。使用我们的几何自校准(GSC),我们的管道从这个糟糕的初始校准中恢复,然后甚至优于基线设置。因此,它具有鲁棒性,并改善了真实CT数据的重建。
放射自校准。为了测试辐射自校准的有效性,我们在真实数据集上运行我们的重建管道并禁用单个步骤。结果如图8所示。第一个实验是禁用辐射自校准的基线。之后,我们启用曝光和传感器偏差估计,这将重建提高了约1 dB。启用响应曲线优化,进一步改善了结果,这可以从底部放大的图像中看到。
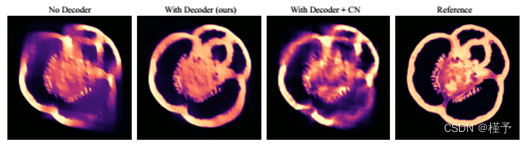
图9所示。无解码器、有解码器、有解码器和acorn式坐标网络(CN)的有限角度重构。
译码器。接下来,我们要分析解码器网络在重建质量和正则化属性方面的有用性。在我们目前的实现中,我们使用一个八元素的特征向量,它被解码器网络转换成一个单一的密度值。对应的是一个没有解码器的管道,但在x,y,z方向上有双分辨率块。音量有完全相同数量的变量,但没有特征解码器。图9显示了对一个有限角度问题进行比较的结果。在左侧,我们有网格分辨率为1 × 333的无解码器变体。在右边,显示了我们的完整管道,它使用8×173的网格分辨率。利用解码器网络,更准确地重建了水果的侧面。没有它,就会出现模糊的伪影,类似于迭代重建方法的伪影。因此,我们可以推断出解码器网络的正则化性质,提高了在困难条件下的重建。
显性与显性-隐性混合表征。我们的重建管道中的神经特征体被显式存储为一个大张量(见图2)。另一种设计是显式-隐式混合模型,如ACORN [Martel等人2021],其中特征体不被显式存储,而是进一步压缩到隐式神经网络中,希望实现额外的压缩和正则化。不幸的是,这种希望在层析重建的背景下无法实现(图9,第三个子图像)。具体来说,我们发现混合显式-隐式表示的PSNR比纯显式分层表示更差,特别是在有限角度断层扫描的情况下。在有限角度层析成像中,重建在与缺失的观测方向正交的方向上已经模糊(缺失的楔形问题)。隐式网络的额外正则化进一步鼓励了这种模糊,而不是修复它。
此外,加入隐式网络显著增加了训练时间。最后,虽然最终的显式-隐式表示比显式表示更紧凑,但训练期间的中间内存消耗实际上更高,因为为了跟踪一个视图的所有光线,需要对所有特征体积进行解码。
结构细化。在3.7节中,我们描述了结构八叉树优化,该优化在重建过程中每隔几个epoch执行一次。该优化包括合并、分裂和从树中剔除叶节点。从这些转换中,我们预计重建时间会更短,因为空空间跳跃,更准确的重建,由于分配更多的资源,困难的部分场景。以最大叶节点数为1024的辣椒数据集为例,结构优化过程如图11所示。八叉树由分辨率为43 = 64的统一网格初始化。一旦训练收敛于该分辨率,则使用Eq.(9)计算每个节点的误差,并应用结构精化。从左上到右上,所有叶节点都被分割,因为完全分割不超过移动的叶节点8 3 = 512 < 1024。但是,在下一个结构细化步骤中,再次拆分所有节点是不可能的。163 = 4096 > 1024。因此,优化会自动合并低错误节点进行分割更多的高误差叶。注意,在本例中,为了演示自适应节点分配,禁用了空空间剔除。图11左下角的图形显示了重建过程中的损耗曲线。陡峭的台阶表示结构优化点。
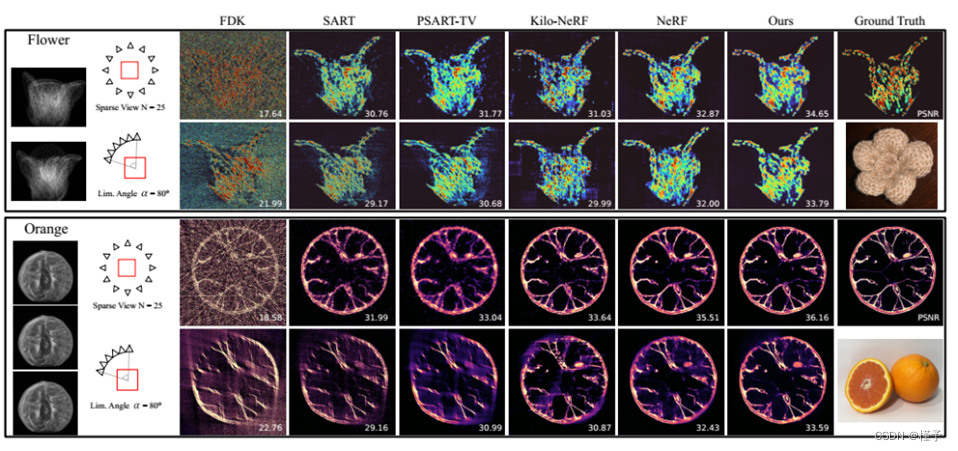
图10所示。合成CT数据集的稀疏视图和有限角度重建。在最左边的列中,显示了一些原始输入图像以及重构配置。在最右边的一栏中,我们显示了地面真相,并说明了扫描对象的图像。这个比较表明,我们的方法(我们的)在定性和定量上都优于其他基线方法。
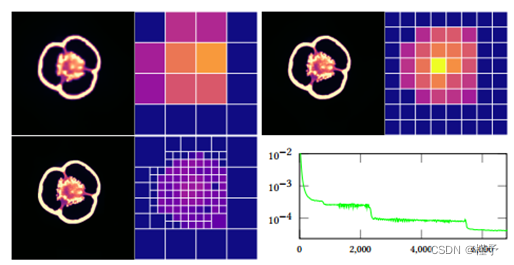
图11所示。辣椒数据集的自适应重建。右边的每一片八叉树结构可视化。颜色表示公式(9)中定义的pernode误差。该误差用于将固定数量的叶节点最优地分布到场景中。右下角显示了重建过程中的训练损失。一旦检测到收敛,树结构就会被优化,这里是在步骤2200和5400。
4.3与现有方法的比较
我们已经在各种数据集上评估了我们的CT重建方法,并将其与其他最先进的方法进行了比较。其他方法包括锥束滤波反投影(FDK) [Feldkamp等人1984],同步代数重建(SART)[Kak和Slaney 2001],带TV正则化器的近端SART (PSARTTV) [Zang等人2018a],神经辐射场(NeRF) [Mildenhall等人2020]),以及使用单独局部隐式函数的NeRF变体(Kilo-NeRF) [Reiser等人2021]。前三种是传统的CT重建方法,它们的变体通常在商用CT系统中发现。后两者是现代渲染方法,最初是为新颖的视图合成和多视图重建而设计的。我们已经调整了它们来处理x射线输入数据,通过改变合成算子到我们的图像形成模型。此外,我们通过禁用学生-教师蒸馏来修改Kilo-NeRF,以验证是否有可能直接培训本地mlp。
代数重建技术运行直到收敛,根据使用的投影数量,SART等简单方法需要5-30分钟,但PSART-TV等更高级的方法需要大约40-50分钟。对于基于优化的方法,我们进行参数搜索并给出最佳质量的结果。NeRF和Kilo-Nerf是经过训练的我们的方法在A100 GPU上运行了40个epoch,对应于大约45分钟。在比较时间时,重要的是要记住巨大不同的代码库,以及所有方法都有影响时间的大量参数和超参数这一事实。因此,所提供的时间只能被解释为计算性能的粗略指标。也请参阅第5节中的讨论。
在第一个实验中,我们测量了合成数据的重建质量。体是先验已知的,投影图像是通过体绘制生成的。在每个投影上,我们加上高斯噪声的标准差为:φ = 0.02·𝐼𝑚𝑎没有模拟其他校准误差。每种方法的重建结果如图10所示。前两行描述了花数据集上的稀疏视图和有限角度断层扫描。在下面的行中对Orange数据集执行相同的操作。所有方法(除了FDK)在数据集和配置上都取得了不错的结果。然而,在Flower数据集上,我们的方法显然是最受欢迎的,PSNR比第二好的方法提高了近2dB。在Orange数据集上,NeRF和Neat都显示出高质量的重建。在定量上,我们的方法由于其清晰度而具有边缘,但在有限角度重建(最后一行)中,NeRF能够更好地完成橙子的皮肤。
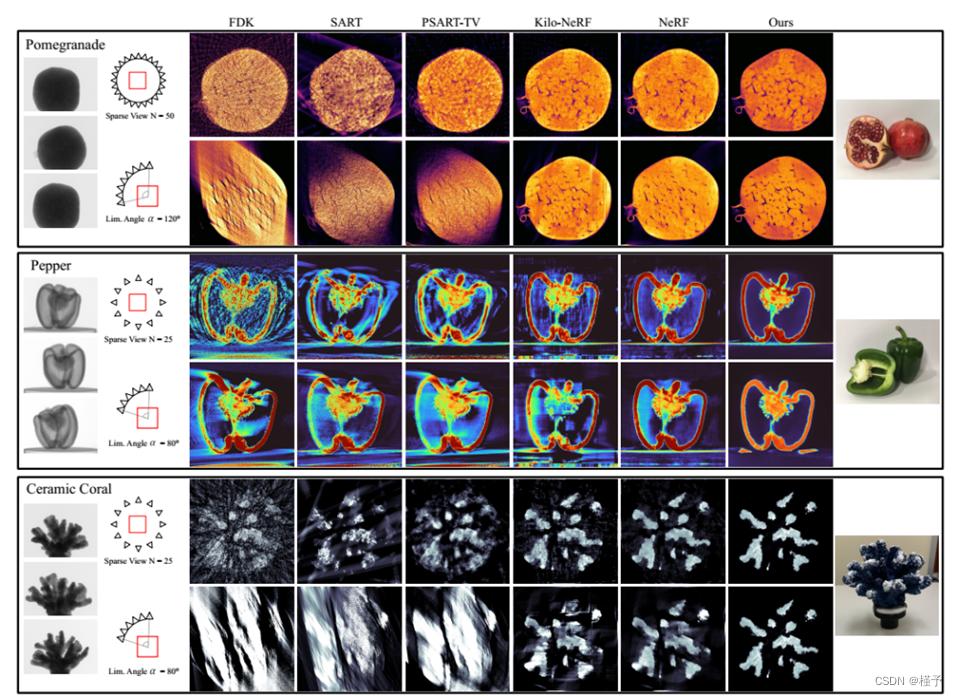

图12所示。真实CT数据集的稀疏视图和有限角度重建。在最左边的列中,显示了一些原始输入图像以及重构配置。在最右边的一列中,我们展示了扫描对象的图解图像。这个比较表明,我们的方法对所有数据和两种配置都获得了高质量的结果。
在综合实验之后,我们在商用CT扫描仪捕获的四个真实数据集上对相同的系统进行了评估。这些数据集是石榴,胡椒,陶瓷珊瑚,和发条茶壶。它们涵盖了很多有趣的方面,比如石榴的低对比度内部结构和上发条茶壶的复杂机制。每个对象的样例原始图像如图12所示。接下来,当前的重构配置是可视化的。在所有四个数据集和两种配置上,NeAT提供了视觉上最好的重建。音量几乎是无噪音的,边缘是锋利的和精细的细节,如辣椒种子被保留。有限角度重构中存在少量伪影,但其他方法的伪影和噪声更为严重。
5讨论与结论
在前一节中,我们比较了NeAT与其他CT重建方法。我们已经证明,我们的方法在合成和真实数据集上都比基线方法取得了显着改善的结果。我们认为,理由是多方面的。首先,我们使用解码器网络形式的神经正则化器,它能够将重建引导到物理上合理的解决方案。其次,我们的几何和光度自校准消除了实际数据的微小误差。最后,自适应八叉树优化确保了对场景复杂部分的内存和计算资源的智能分配。
在计算时间方面,NeAT与基于高级优化的方法(如PSART-TV)在计算时间上相当,尽管计算时间的精确比较当然取决于两种方法的超参数以及代码优化的程度。
NeAT的大部分计算工作都花在评估解码器网络上,而光线跟踪本身比PSART-TV实现要快得多。这主要是由于两个因素:我们的自适应、基于八树的方法可以有效地将样本分配到感兴趣的卷区域,以及我们在基于优化的方法的参考实现中有效地使用gpu(已经高度优化)多核CPU代码。
因此,一个谨慎的GPU实现分层版本(例如PSART-TV)可能会实现与NeAT类似的性能提升。然而,这样做将比使用NeAT困难得多:迭代求解器基于体积投影算子a和相应的反向投影算子a𝑇。由于矩阵太大而无法存储,A和A𝑇在程序上作为单独的操作符实现,其中A是聚集操作符,而A𝑇是分散操作符。即使在统一网格上使用CPU代码,要使两个运算符在保持彼此精确的转置关系的同时表现良好也不是一件容易的事情,这是大多数求解器收敛和正确性的一个条件。具有分层数据结构的GPU实现将使这一任务进一步复杂化。
这就是NeAT的可微渲染方法的亮点所在:我们只需要以可微的方式实现前向运算符A,然后依靠反向传播进行优化,而不必实现两个运算符。通过使用适当的环境(如PyTorch后端),可以大大减少在GPU上有效实现此功能的工作量。
5.2限制和未来的工作
尽管有这些优点,在我们的实验中,我们也发现了一些限制,需要在未来的工作。在科学应用中采用神经网络的一个普遍问题是,传统方法的工件通常很容易被人类发现,因为它们以强烈的模糊或长条纹的形式出现。在神经自适应断层扫描的情况下,伪影在物理上看起来是可信的,因此很难与正确的重建区分开来。例如,在茶壶数据集(图12底部)中,所有有限角度重构都在右下角显示拓扑变化。对于基于优化的方法,很明显这些区域是不可信的,而深度学习方法显示出合理的低频几何补全,但与现实不符。
作为进一步的限制,我们还注意到,我们的方法目前仅适用于层析图像形成模型,该模型可以以顺序无关的方式进行评估(2)。不透明物体的重建需要类似于NeRF的合成图像形成模型[Mildenhall等人2020],该模型要求所有体积样本前后有序。使用我们的分层八叉树空间细分,这将需要额外的簿记工作。此外,我们认为采样策略可能必须适应这种类型的场景,以便将样本集中在物体表面附近。
总之,我们提出了NeAT,这是第一个直接从图像中训练自适应、分层神经表示的神经渲染架构。与其他最近的神经渲染方法相比,这种方法产生了更好的图像质量和训练时间。与传统的基于优化的层析成像求解器相比,NeAT在匹配计算性能的同时显示出更好的质量。
虽然NeAT目前针对层析重建进行了优化,但我们相信类似的概念可以用于重建具有不透明表面的复杂场景。然而,我们把这些留给未来的工作。
本研究得到了阿卜杜拉国王科技大学的支持,作为VCC竞争基金和CRG项目的一部分。作者要感谢Gilles Lubineau教授、Ran Tao博士、Hassan Mahmoud博士和Guangming Zang博士帮助扫描这些物体。

























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









