






1.找到网站
Hugging Face:
魔搭社区(国内):
2.模型选择
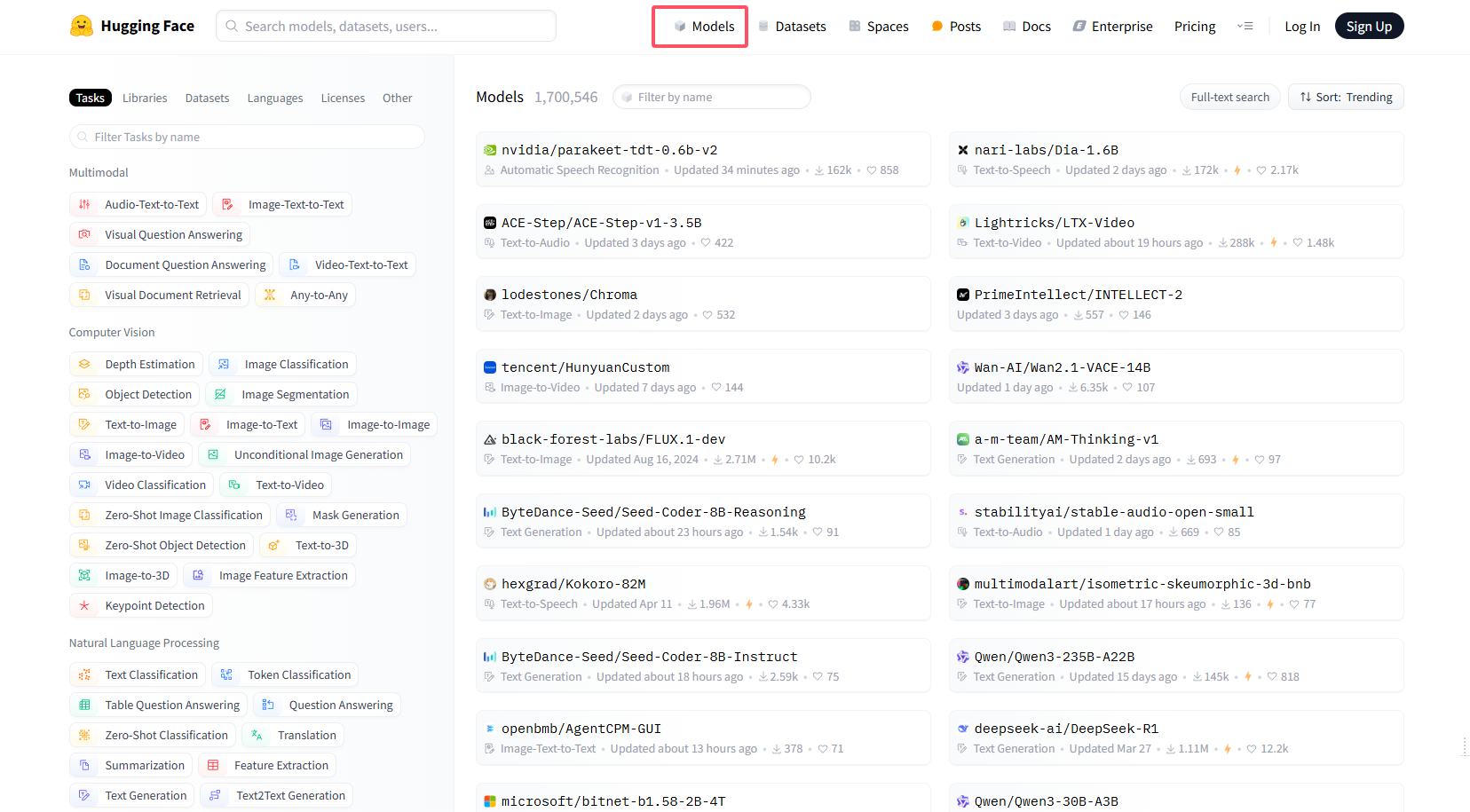
左边选择不同的task,右边出现对应task的模型。也可以按照平台、数据集、语言等进行选择。
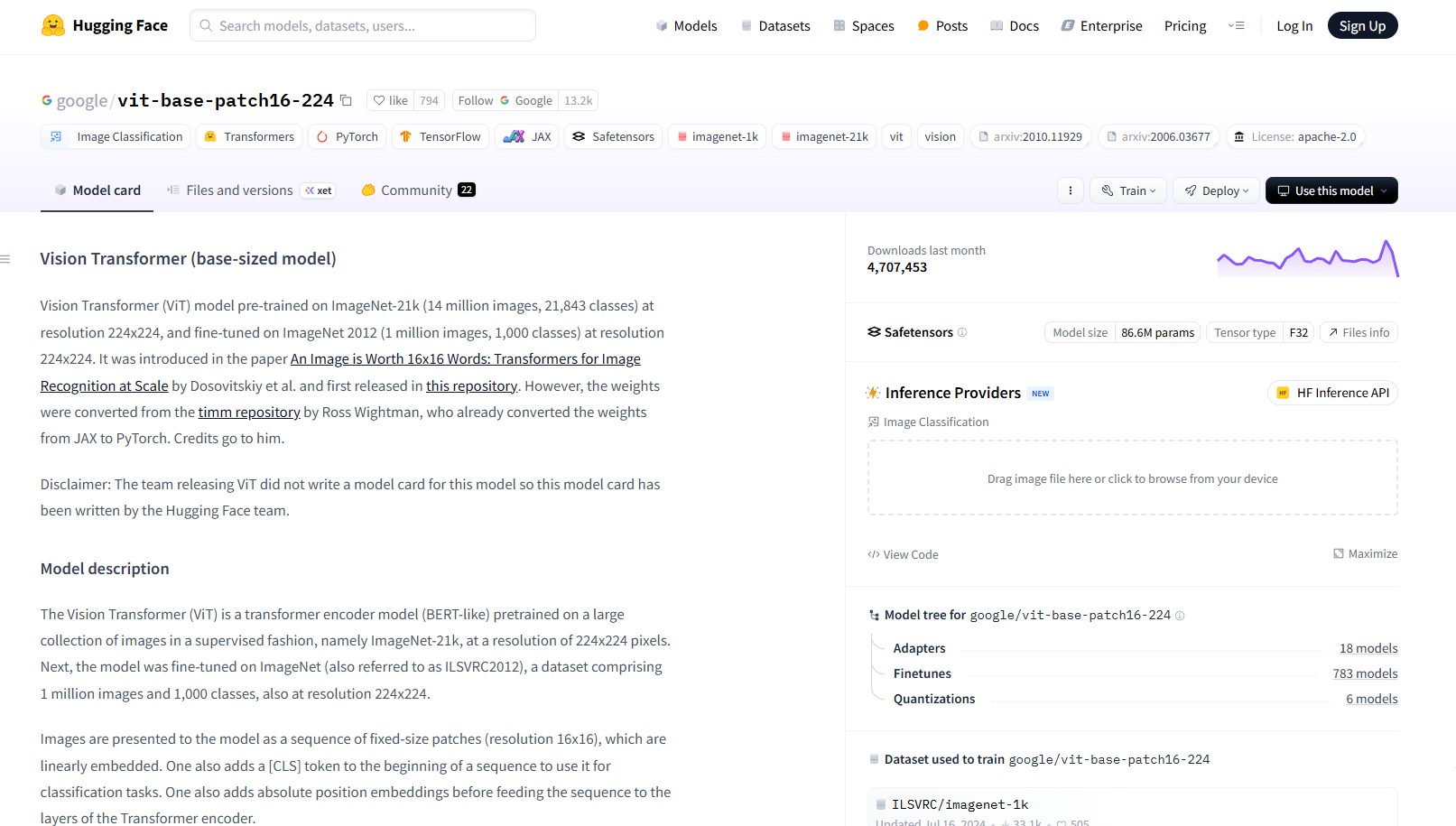
选择一个模型。左侧是对模型的描述,下方通常会给出示例。
3.配置Google colab
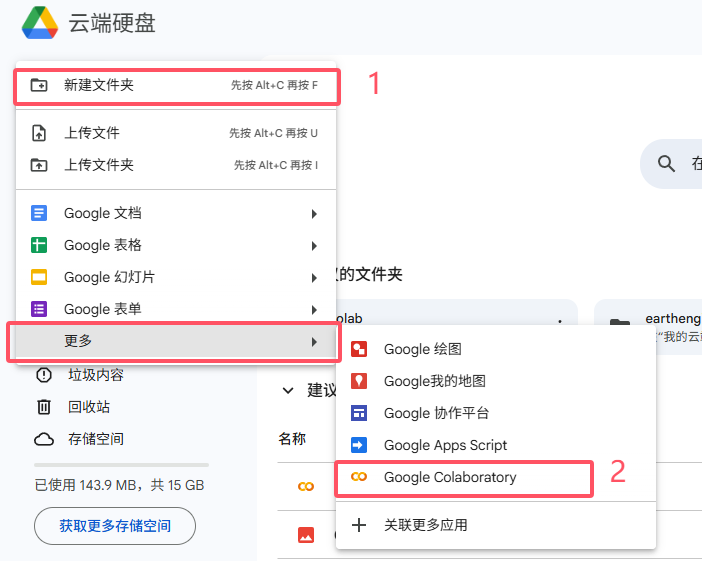
首先新建一个文件夹,叫做colab,用于保存文件。然后点击Google colaboratory,进入。
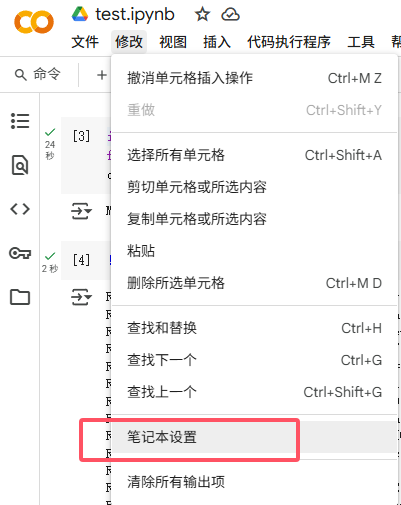
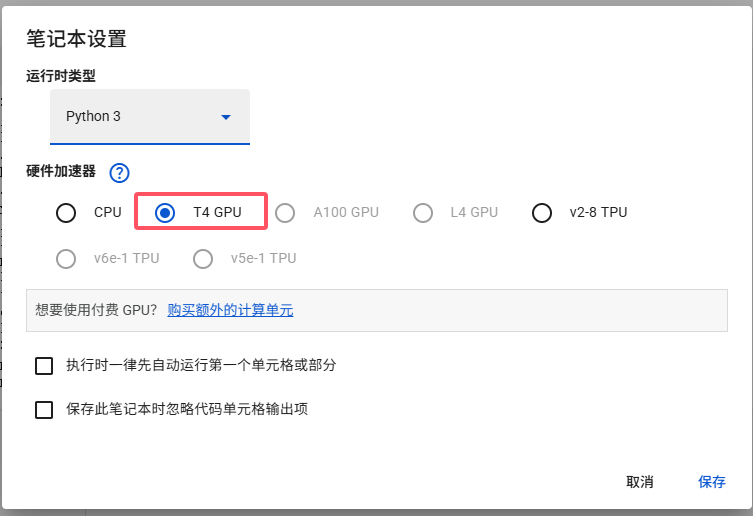
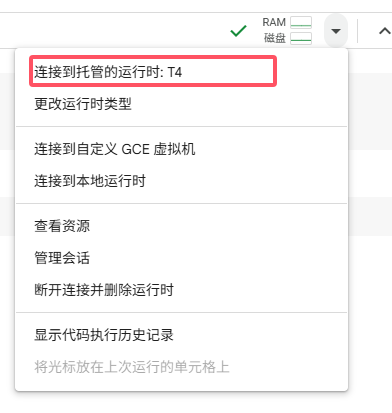
将模型运行的硬件设置改为GPU。可以通过上图的磁盘等信息查看计算资源占用情况。
#输入以下命令查看计算资源
!nvidia-smi
#输入以下命令查看当前路径
!pwd
如果需要用到Google drive上的数据,那么:
import os
from google.colab import drive
drive.mount('/content/drive')
#切换路径
%cd /content/drive/MyDrive/colab #或者其他文件夹4.开始探索
首先下载transformers
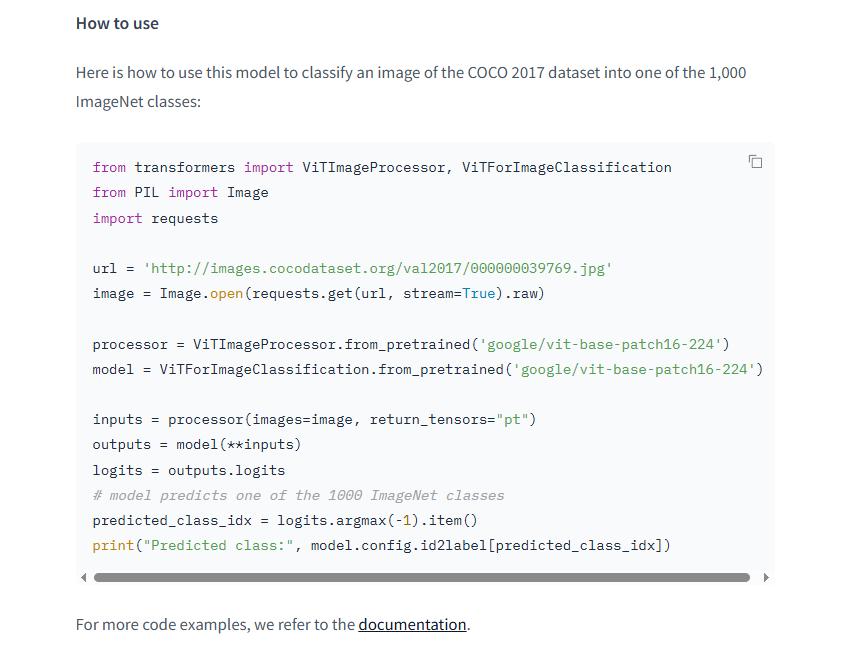
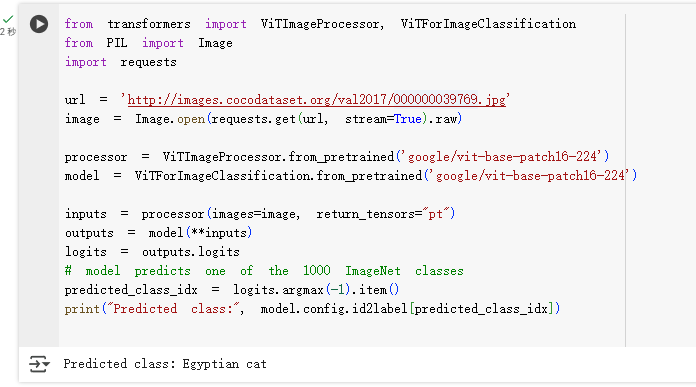
!pip install transformers先用给的例子尝试一下:
from transformers import ViTImageProcessor, ViTForImageClassification
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
processor = ViTImageProcessor.from_pretrained('google/vit-base-patch16-224')
model = ViTForImageClassification.from_pretrained('google/vit-base-patch16-224')
inputs = processor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
输入的图片是:

生成的结果是:
又用了网上下载的图片试了试(上传到Google drive中):
from transformers import ViTImageProcessor, ViTForImageClassification
from PIL import Image
import requests
image = Image.open('/content/drive/MyDrive/0972dbcf6279001b88cc7f0f481ce864.jpg')
image = image.convert('RGB')
processor = ViTImageProcessor.from_pretrained('google/vit-base-patch16-224')
model = ViTForImageClassification.from_pretrained('google/vit-base-patch16-224')
inputs = processor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])

以及:


最初的尝试就到这里了!之后有机会再仔细了解一下!

















 3390
3390

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









