







在做nlp过程中,需要对单词或者句子用词向量进行表征。因此产生了像embedding、word2vec等词向量方法。
embedding层:embedding的本质是一个矩阵,单词的独热编码与该矩阵相乘,得到词向量模型,作为后续网络层对输入。它更像是一个基于神经网络层的encoding-decoding过程。它是一个网络层,跟随整个模型一起训练。从embedding的作用上理解,它是将原始词向量映射到一个低维空间中,这样在做相关处理过程中,可以去除文本的“一些噪声”,即减少了文本的数据量,从而计算的复杂度,用提高计算效率。下图为embedding层将原词向量映射到一个新的多维空间的表示过程。
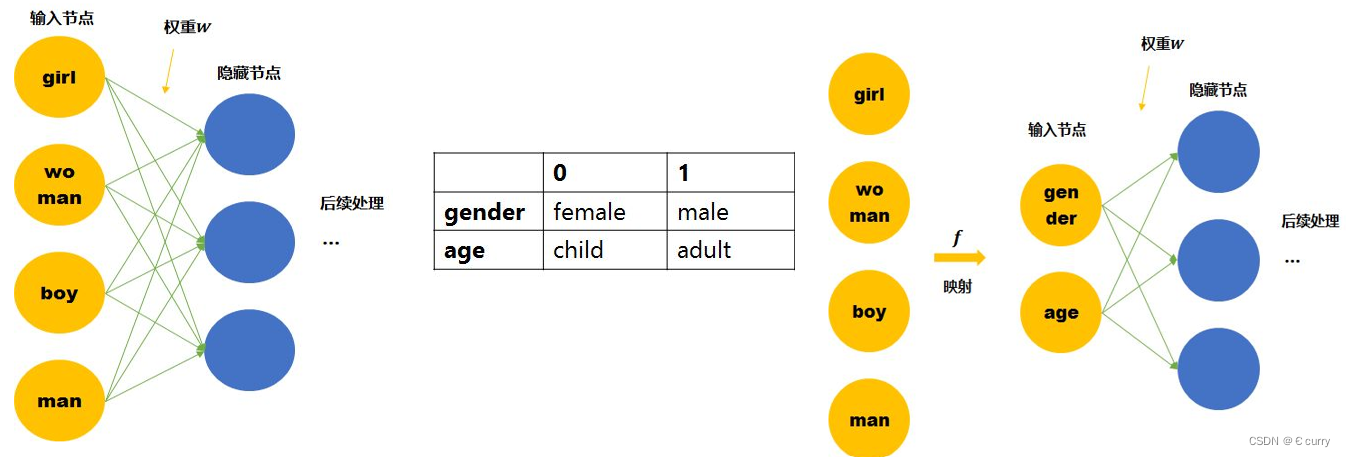 详细请参考:https://www.cnblogs.com/pyclq/p/12405631.html
详细请参考:https://www.cnblogs.com/pyclq/p/12405631.html
Word2Vec:它是google推出的一种算法,其本质是优化过的embedding,进行词向量的训练,而不像embedding那样是一层网络。Word2Vec有CBOW 和 Skip-gram两种方式。CBOW是通过周围单词预测中心单词,而Skip-gram是通过中心词预测周围词。
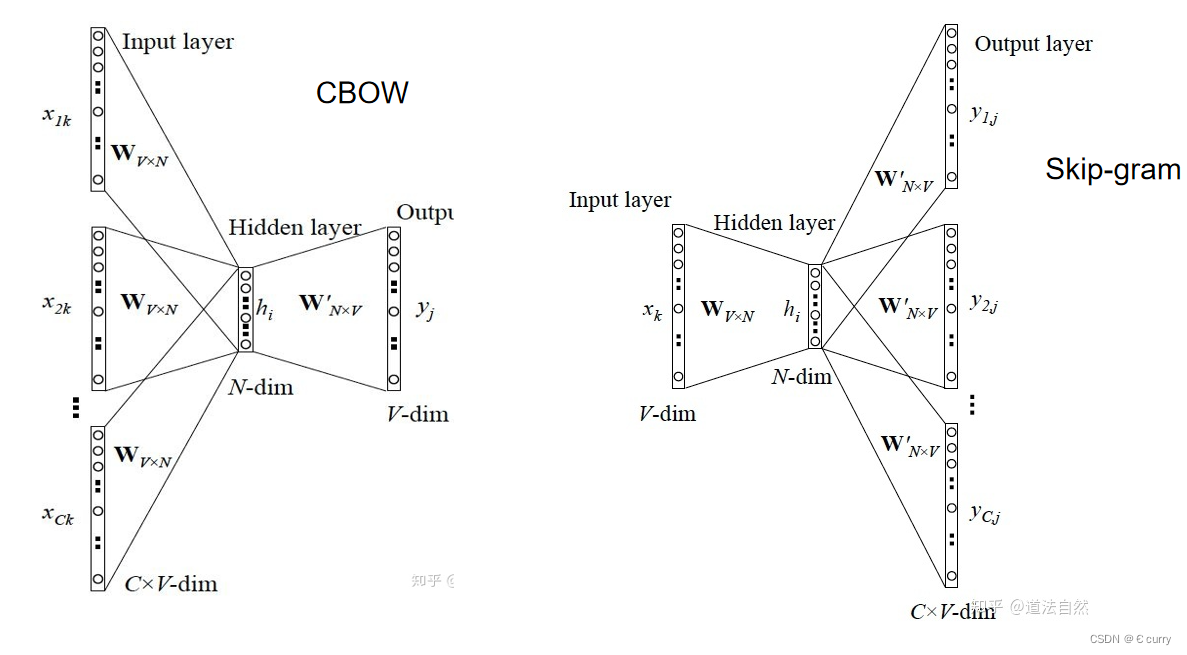 详细请参考:https://blog.csdn.net/vincent_duan/article/details/117967110
详细请参考:https://blog.csdn.net/vincent_duan/article/details/117967110
Word2Ve参数讲解:
-
vector_size (之前称为size): 这个参数决定了词向量的维度,即每个词将被表示为多少维的向量。较大的向量尺寸可以捕捉更多的信息,但也会增加模型的复杂性和训练时间。常见的值范围从50到300。
-
window: 窗口大小决定了模型在学习词向量时考虑的上下文范围。对于CBOW架构,窗口大小是指当前词左右两侧的词的数量。对于Skip-gram架构,它是指当前词预测上下文中词的最大距离。较大的窗口尺寸意味着考虑更远的上下文,可能有助于捕捉更广泛的语义关系。
-
min_count: 这个参数决定了词需要出现的最小频率才能被考虑。这有助于去除稀有词,从而减小模型的噪声并减少计算资源的需求。
-
sg: 选择训练算法:
sg=0表示使用CBOW模型,sg=1表示使用Skip-gram模型。Skip-gram倾向于处理较大的数据集,并且对罕见词汇的处理效果更好,但训练速度较慢。 -
hs (hierarchical softmax): 是否使用层次softmax优化。如果设置为1,则使用层次softmax技术。如果训练数据较小或词汇较少,这可以加速训练并提高效率。
-
negative: 负采样的数量。如果大于0,则会使用负采样。这个参数决定了在优化过程中将多少“负”词(即,非上下文词)纳入计算。使用负采样通常可以加速训练并提高较少频繁词的质量。
-
iter: 训练迭代次数。较多的迭代次数可以提高模型的性能,但也会增加训练时间。
-
alpha: 学习率的初始值。在训练过程中,学习率控制了权重调整的步长大小。较高的学习率可能会导致训练不稳定,而较低的学习率会增加收敛到最佳解的时间。















 1564
1564











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









