









前文内容:从SSM到S4-CSDN博客
参考视频:Mamba 超超超详细解说 |4、Mamba_哔哩哔哩_bilibili
一、SSM的缺点
为什么SSM以及S4在语言建模和生成式的一些重要任务表现不佳?
答:因为缺少关注或忽略特定输入的能力。主要是由于SSM的线性时不变性(LTI:Linear Time Invariance)导致的。
什么是线性时不变性?
答:
1. 线性性(Linearity):
- 线性系统遵循叠加原理:如果输入信号
产生输出
,输入信号
产生输出
,则对于任意常数 a 和 b,输入
的输出为
。
- 这意味着系统的响应与输入成正比,系统的行为是可预测的。
2. 时不变性(Time Invariance):
- 时不变性意味着系统的行为不随时间的变化而变化。如果一个输入信号在某个时刻
产生了某个输出
,那么将该输入信号延迟 Δt 时间后,系统的输出也会相应地延迟 Δt 时间,即
。
- 换句话说,系统的特性在任何时间点都是相同的。
SSM中的线性时不变性
在状态空间模型中,线性时不变性意味着模型的动态行为可以用线性方程来描述,并且这些方程的系数在时间上是恒定的。具体来说,SSM 通常用以下形式表示:
:系统的状态向量。
:输入信号。
:输出信号。
- A,B,C,D:系统的参数(矩阵),这些参数在时间上是固定的
由于状态空间模型在时间上具有不变性,任何时间的输入信号都会以相同的方式影响系统的输出。这种特性虽然在许多应用中是有用的,但在需要关注特定输入或时间变化的动态系统(如语言建模和生成任务)中,线性时不变性可能会导致模型的表现不佳。

举例1: 
举例2:

二、Mamba的提出
2.1 贡献一:Selective
目的:模型具备过滤无用信息的能力
背景:S4 模型中使用的状态空间矩阵 BB 和 CC 通常是静态的,即它们是固定和预定义的。然而在许多实际应用场景中,输入序列的特征是动态变化的,静态矩阵很难适应这些变化,导致无法充分利用输入信号中的动态信息。这种固定性会限制模型的灵活性,特别是在需要对输入进行选择性过滤(Selective)的场景中。
Mamba的贡献:提出了动态矩阵的实现方案:矩阵 B 和 C不再是固定的,而是由输入动态生成。
- 矩阵动态化:通过让 B 和 C 矩阵与输入数据相关联,Mamba 允许模型根据输入信号的特点动态调整其参数,从而实现对输入中重要信息的选择性关注。
- 过滤无用信息:通过这种机制,模型可以自动聚焦于输入序列中有意义的部分,过滤掉无关或噪声信息。
由于 B 和 C 矩阵的动态性,无法直接使用 SSM 中的卷积形式。Mamba 提出了parallel scan(并行扫描)作为一种新方案,帮助实现这种动态计算。
2.2 贡献二:Parallel Scan 并行扫描
目的:解决动态矩阵带来的额外计算负担
背景:在序列建模中,计算长序列的状态更新往往会引入较高的计算复杂度,尤其是当状态需要动态调整时。为了解决动态矩阵带来的额外计算负担,Mamba 提出了基于parallel scan(并行扫描)的高效计算策略。
Mamba的贡献:
硬件感知算法(Hardware-aware algorithm):
- Parallel scan 是一种能够高效并行化的计算方式,特别适用于 GPU 等现代硬件架构。
- Mamba 设计了一个硬件友好的算法,以实现 parallel scan 的动态性和高效性。这种方法能充分利用硬件的并行计算能力,加速矩阵操作。
进一步优化:kernel fusion 和 recomputation:
- Kernel fusion(核融合):通过在 GPU 上将多个计算核合并为一个核,减少内存访问的开销,从而显著提高计算效率。
- Recomputation(重计算):为了解决内存使用和计算效率之间的平衡问题,Mamba 在适当场景下选择重新计算部分中间结果,而不是保存它们。这种策略能在节省显存的同时保持较高的计算性能。
2.3 总结
Selective(选择性过滤无用信息):
- 通过让矩阵 B 和 C 动态化,Mamba 提升了模型对动态输入的适应能力。
- 提升了模型过滤无关信息、专注于重要输入特征的能力。
Parallel Scan(并行扫描优化):
- 使用硬件感知的并行扫描算法,大幅提升了动态矩阵下的计算效率。
- 通过 kernel fusion 和 recomputation 等技术,进一步优化了运行性能,为长序列数据建模提供了高效解决方案。
2.4 S6和Mamba结构
S4+Selective + Scan=======> Selective SSM ,称作S6,作为Mamba block中的一个重要组件
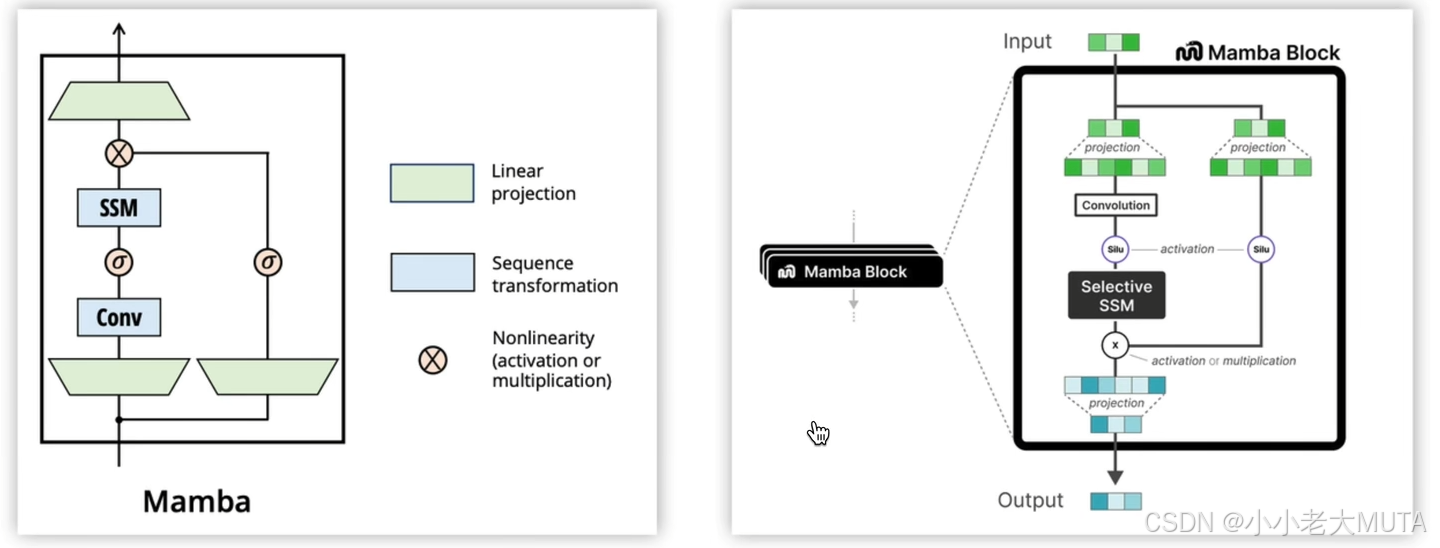
三、Mamba
3.1 Selective


B,C是怎么动态生成的?
答:
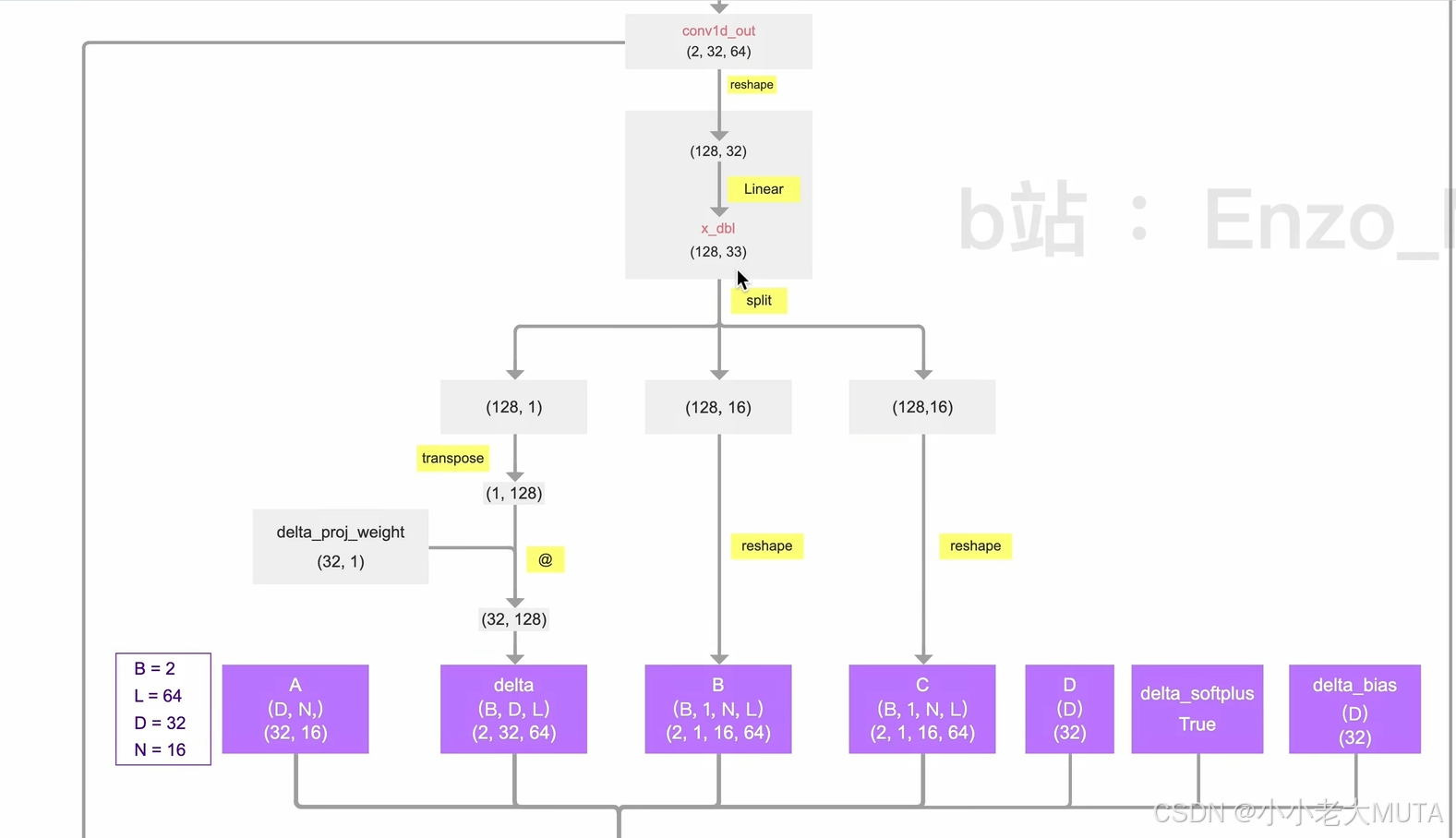
3.2 Selective Scan
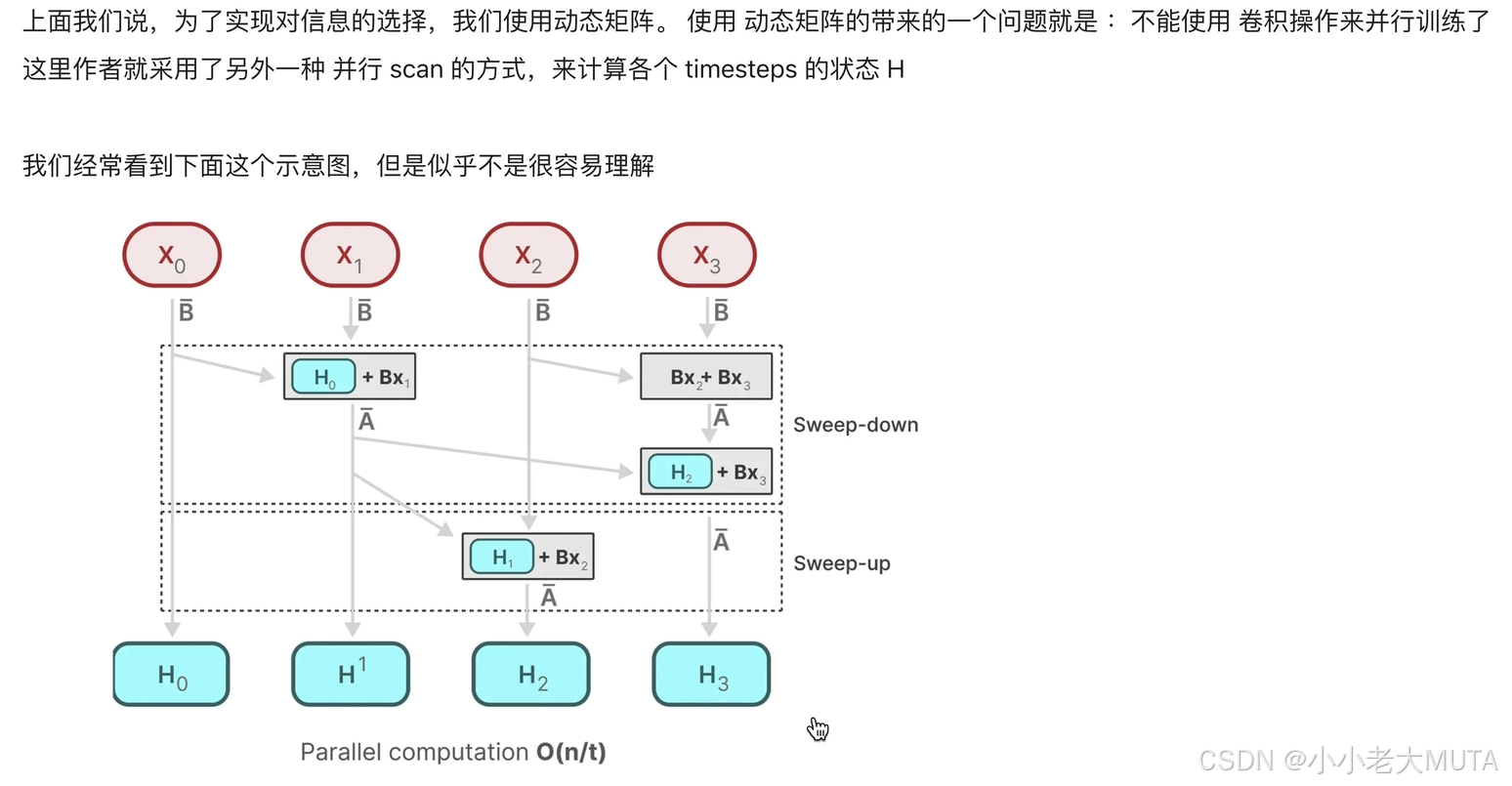
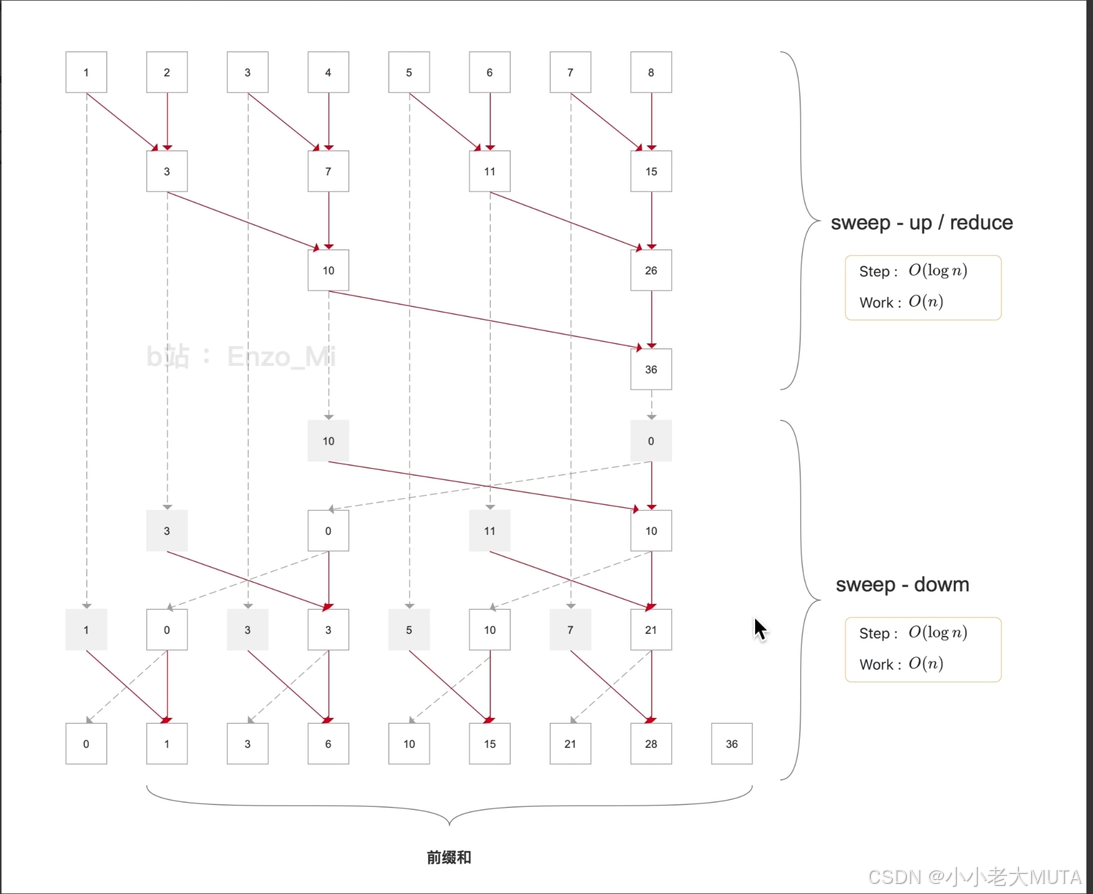
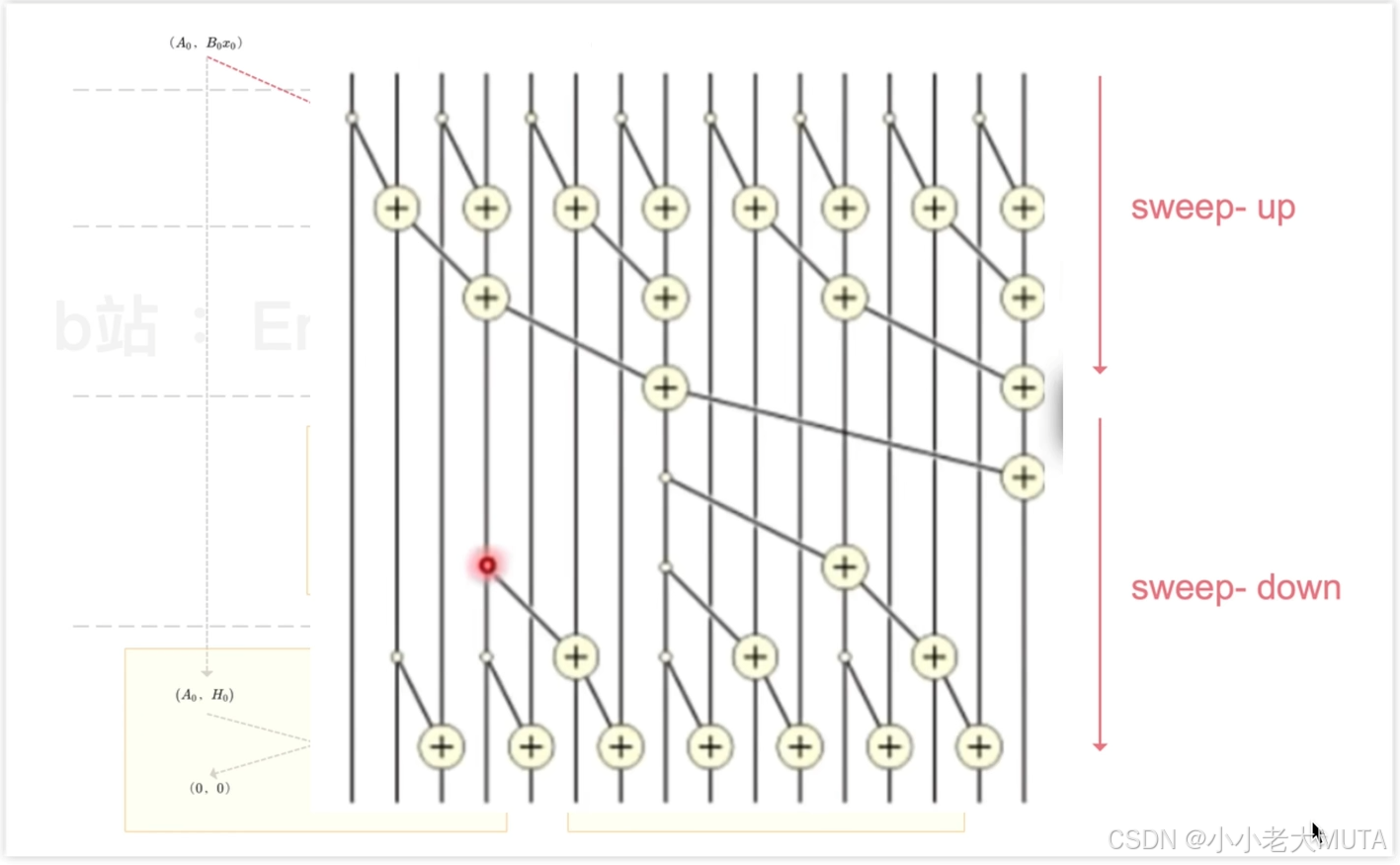
Selective Scan的设计受Blelloch scan算法的启发,特别是在“sweep-up”和“sweep-down”阶段的并行结构上,Selective Scan 利用了这一结构来处理状态空间模型(SSM) 中的并行操作。
3.2.1 Blelloch Scan
Blelloch Scan(布莱洛克扫描)是一种用于计算前缀和(或其他聚合操作)的并行算法。它能有效地利用计算机的并行处理能力,特别适合于多核处理器和图形处理器(GPU)。
什么是前缀和?
标准的前缀和(Prefix Sum)是指给定一个数组
,前缀和数组 P 的每个元素表示 A 中所有前置元素之和,即:
例如,给定数组 A=[2,4,6,8],其标准的前缀和数组 P 为:
- P[0]=2
- P[1]=2+4=6
- P[2]=2+4+6=122
- P[3]=2+4+6+8=20
Blelloch Scan可以理解为另类的前缀和计算流程, 是一个分阶段的过程,通常分为两个主要步骤:
- Sweep-up(上扫):通过归约操作计算出前缀和的中间结果。
- Sweep-down(下扫):通过传播中间结果,将最终的前缀和更新回原始数组。
参考链接:Mamba.py: 状态空间模型的并行扫描_mamba并行扫描-CSDN博客
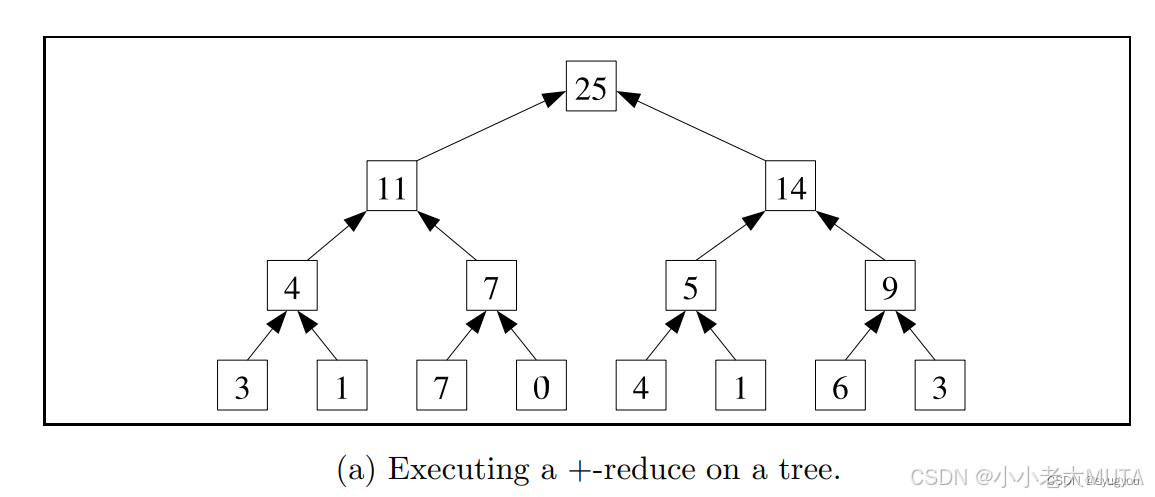
Sweep-up

Sweep-down
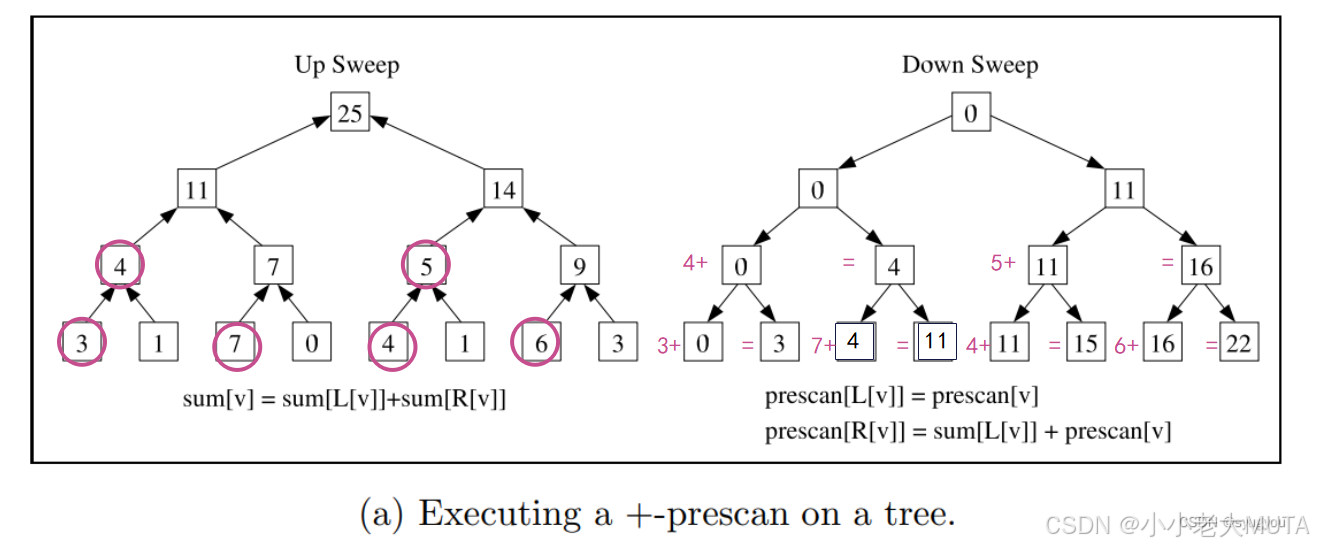
如上图所示,sweep down的过程:
- 左子树继承上一节点结果,即0->0->0->0,4->4,11->11->11,16->16;
- 右子树的结果 = 同级别的左子树结果 + sweep up过程的结果(粉色);

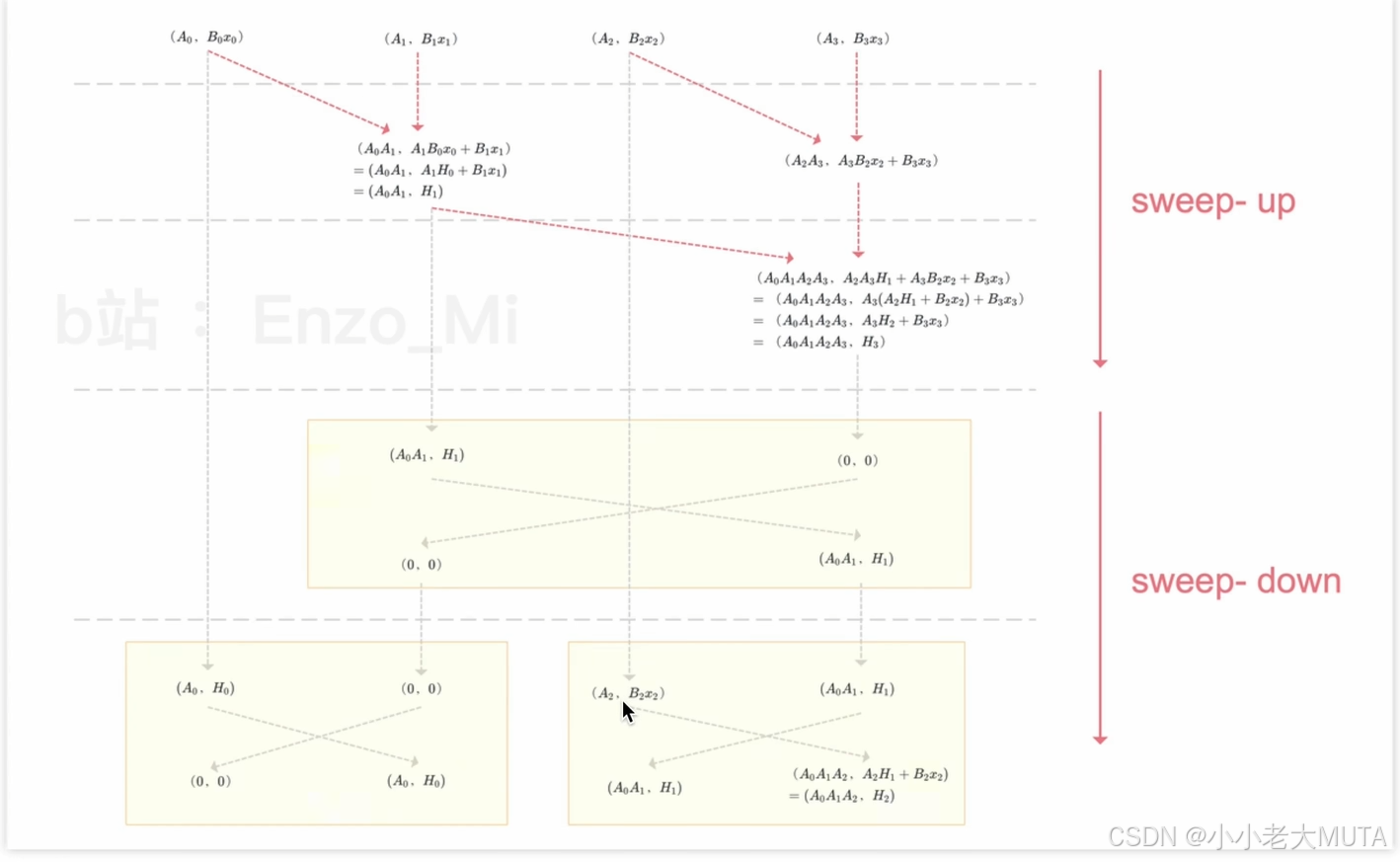
3.2.2 Mamba中的Selective Scan


3.3 Hardware-aware Algorithm
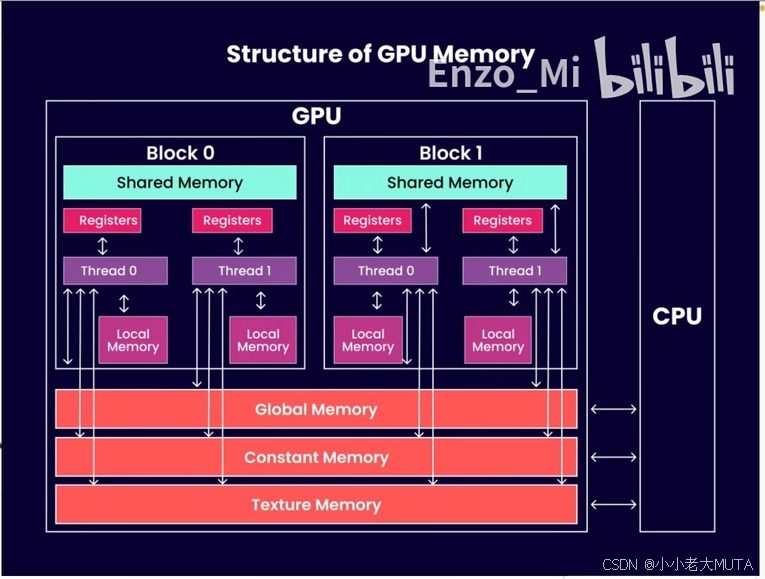
SRAM和HBM
SRAM(Static Random Access Memory)和 HBM(High Bandwidth Memory)是两种不同种类的存储器,用于不同的硬件架构和用途。
SRAM 全称是 Static Random Access Memory,即静态随机访问存储器。是主内存,也成为全局内存(global memory)
- 是一种低延迟、高速的小容量存储器,通常用作 CPU 的缓存(L1/L2/L3 Cache)或嵌入式存储。
- 由于其结构简单且速度快,非常适合在需要临时存储和快速访问的场景中使用。
HBM 全称是 High Bandwidth Memory,即高带宽内存。有共享内存(shared memory)、寄存器(Registers)等。
- 是一种高带宽、低功耗的高容量存储器,广泛应用于 GPU、AI 加速器和高性能计算领域。
- 它通过 3D 堆叠和 TSV 技术,提供了极高的带宽和存储密度,故用来存储较大的数据集,但访问速度比较慢。
DRAM即动态随机存取存储器,是计算机系统中主要的主内存类型,它采用电容器来存储每个比特的数据,因此需要定期刷新以保持数据的有效性。适合于需要大量内存的计算任务。

3.3.1 背景
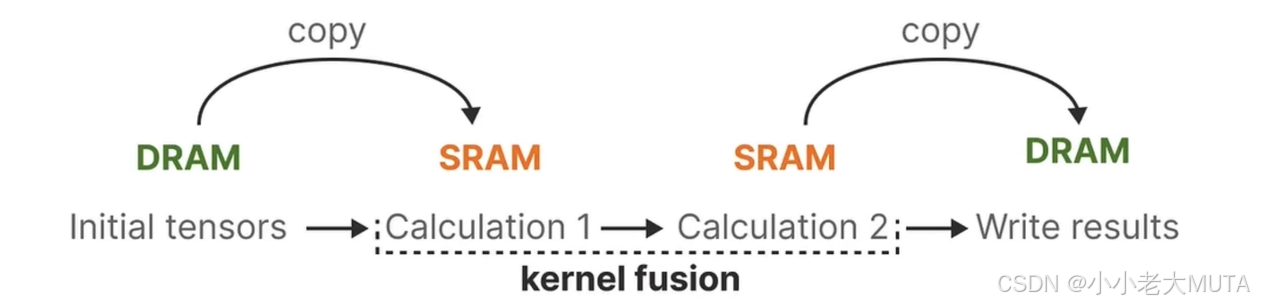
在深度学习框架(如 PyTorch)中,计算任务通常是在 GPU 上通过 CUDA kernel 完成的。每个 CUDA kernel 通常对应一个操作(如矩阵加法、乘法、激活函数等),这个分工的好处是使代码结构清晰、易于维护。但是,过多的 kernel 调用可能会导致性能瓶颈,特别是频繁的数据在 DRAM(全局内存) 和 SRAM(GPU 的共享存储器或寄存器) 之间的读写操作。这种频繁的全局内存访问会显著降低性能。
在没有使用硬件感知算法之前,计算流程如下:

1. Initial Tensors(初始张量):
- 数据存储在 DRAM 中。
2. 从 DRAM 到 SRAM 的数据拷贝:
- 在每一次计算开始之前,数据需要从 DRAM 拷贝到 SRAM 或寄存器,以便 GPU 执行计算。
3. Calculation(计算):
- 在 GPU 的计算单元上完成计算。
4. 计算结果写回 DRAM:
- 每次计算操作结束后,结果会从 SRAM 写回 DRAM。
5. 下一步操作:
- 同样的过程重复:DRAM 数据拷贝到 SRAM,完成计算,再写回 DRAM。
由于每个计算操作独立执行,每次都涉及从 DRAM 到 SRAM 的数据传输和结果的回写,导致数据频繁地在全局内存与共享内存之间移动,带来了高延时和低效率的问题。
3.3.2 Kernel Fusion
Kernel Fusion 的出现旨在解决这一问题:通过将多个计算操作合并到一个 CUDA kernel 中,从而减少不必要的内存访问和 kernel 调用,提高性能。
1. 一次性从 DRAM 加载数据到 SRAM:
- 将所需的数据一次性从 DRAM 加载到 SRAM。
2. 在 SRAM 中完成所有计算:
- 在一个 kernel 内完成公式中所有的计算操作(例如,上述公式分别计算 hkhk 和 ykyk)。
3. 计算结果一次性写回 DRAM:
- 计算完成后,将结果一次性写回 DRAM。
这样,原本需要多次的 DRAM-SRAM 数据搬运,现在被优化为一次,极大地提升了效率。
代码层面:
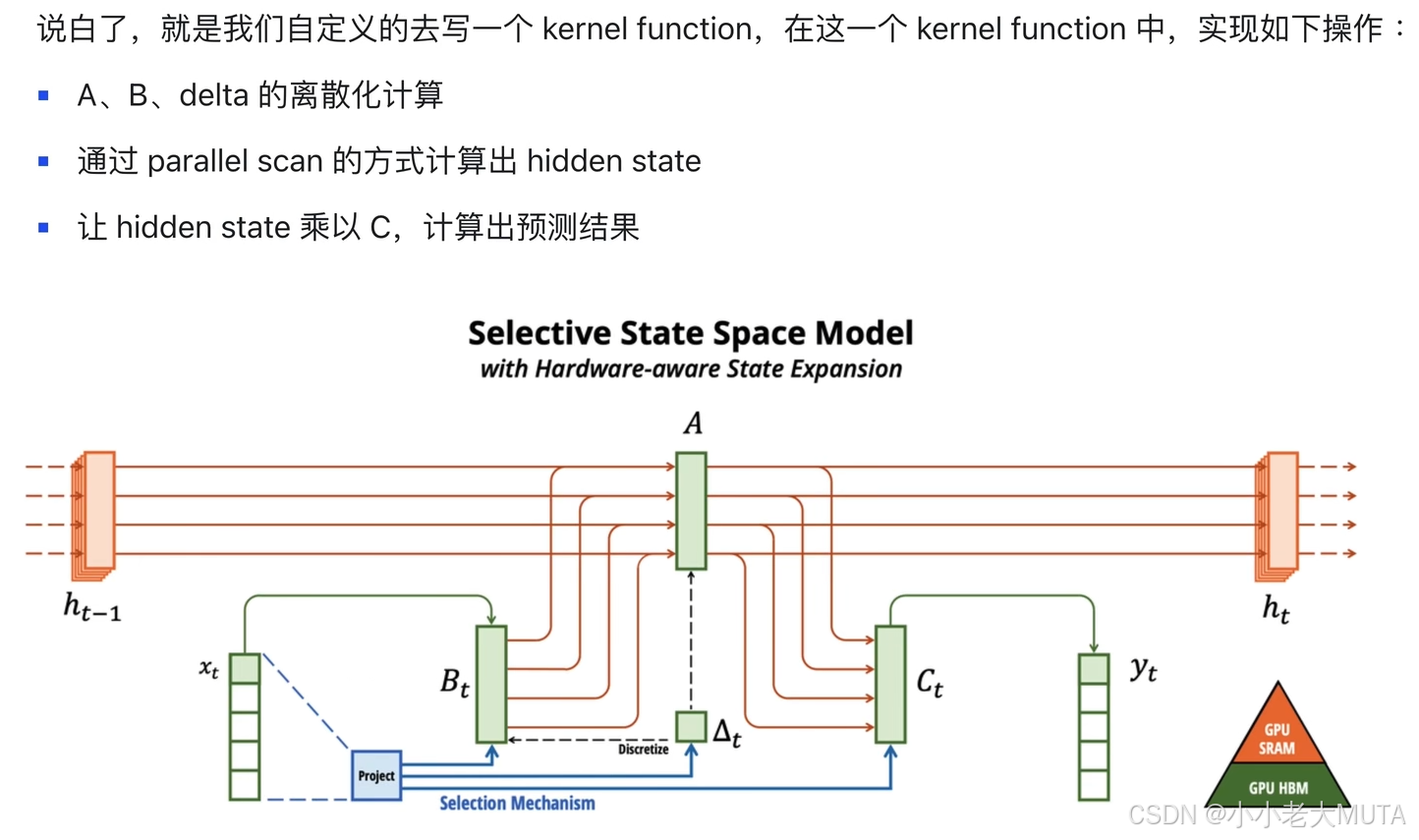
1. 输入数据加载:
- 输入包括上一时刻的隐状态
、输入特征
以及时间步长 Δt。这些数据需要从全局存储(如 GPU 的 HBM)加载到共享存储(如 GPU 的 SRAM)或寄存器中。
2. 矩阵运算(分散化计算):
、
、Δt 等变量的计算是图中核心步骤,可能涉及矩阵乘法、逐元素操作等。
- 例如:
- Δt 是时间步长,通过离散化操作得到。
3. 状态更新(Hidden State 计算):
- 使用并行算法(如 Parallel Scan),通过核心公式计算
:
- 这一部分可能涉及递归运算,因此需要在 GPU 上高效并行化。
4. 输出生成:
- 根据状态
计算最终输出
:
5. 结果写回:
- 计算结果
3.3.3 recomputation
提出背景:
- 在 Kernel Fusion 的情况下,多个操作被合并到一个 kernel 中执行,以减少内存访问和 kernel 启动的开销,从而提升计算效率。
- 但这也带来一个问题:因为多个操作被融合,许多中间结果没有保存到全局内存中,反向传播时这些中间结果无法直接使用。
解决方案:在反向传播阶段,重新执行一次前向传播以重新计算中间结果,而不是在前向传播时将这些中间结果全部存储到全局内存中。
- 在前向传播时只存储必要的少量数据。
- 在反向传播时需要用到中间结果时,通过 recomputation 动态重新计算这些结果。



















 1509
1509

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











