










论文地址:[2409.15936] DepMamba: Progressive Fusion Mamba for Multimodal Depression Detection
摘要
抑郁症是一种常见的精神障碍,影响着全球数百万人。尽管当前的多模态方法在抑郁症检测中表现出潜力,但它们依赖于对齐或聚合的多模态融合,存在两个显著局限性:(i) 长时序建模效率低下;(ii) 模态间融合与模态内处理之间的多模态融合效果欠佳。
本文提出了一种用于多模态抑郁症检测的视听渐进融合 Mamba 方法,称为 DepMamba。DepMamba 具有两个核心设计:层次化上下文建模和渐进式多模态融合。一方面,层次化建模引入卷积神经网络和 Mamba 来提取长时序序列中从局部到全局的特征。另一方面,渐进式融合首先提出了一种多模态协作状态空间模型(SSM),用于提取每种模态的模态间和模态内信息,然后利用多模态增强的 SSM 实现模态间的凝聚力。在两个大规模抑郁症数据集上的广泛实验结果表明,我们的 DepMamba 在性能上优于现有的最先进方法。
一、引言
抑郁症是最普遍的精神障碍之一,表现为体重减轻、失眠等多种生理症状,严重时可能导致自杀或药物滥用 [1]。抑郁症检测面临两大挑战:(1) 患者数量持续增长,(2) 人工诊断成本高昂。因此,迫切需要开发一种高效的抑郁症检测系统。近年来,基于多模态的方法通过整合音频、视频和文本模态的信息,在抑郁症检测中显示出良好的效果。这些方法主要关注多模态融合,可分为三类:特征级融合、决策级融合和模型级融合。特征级融合通过拼接多模态特征学习统一的抑郁症检测表示 [2]–[6]。例如,Cai 等人 [3] 引入线性组合技术,从每种模态的脑电信号中构建全局表示。决策级融合通过集成每种模态的决策输出来进行最终分类 [7]–[12]。Zhang 等人 [9] 提出了一种基于多智能体的决策级多模态融合。模型级融合被认为是最有效的,它学习模态间的相互关系 [13]–[15]。例如,Fan 等人 [14] 利用卷积神经网络(CNN)提取高级单模态特征,同时使用 Transformer 模型增强多模态特征。这些方法表明,多模态线索可以显著提高抑郁症检测的性能。然而,现有方法仍面临两个显著局限性:(1) 长时序建模效率低下,例如 CNN 受限于有限的感受野,循环神经网络(RNN)存在梯度消失问题,而 Transformer 等自注意力机制则面临计算效率低下的问题;(2) 多模态融合效果欠佳,现有技术往往专注于学习模态共享或模态特定特征,但无法同时捕捉共享特征并保留模态特定信息。
为了解决这些局限性,我们提出了一种用于高效多模态抑郁症检测的视听渐进融合 Mamba 模型,称为 DepMamba。具体而言,DepMamba 具有两个核心设计:层次化上下文建模和渐进式多模态融合。首先,我们引入 CNN 和 Mamba 模块,从局部到全局提取特征,丰富长时序序列中的上下文表示。其次,我们提出了一种多模态协作状态空间模型(SSM),通过共享状态转移矩阵提取每种模态的模态间和模态内信息。然后,利用多模态增强的 SSM 处理拼接的视听特征,以增强模态间的凝聚力。在两个大规模抑郁症数据集上的广泛实验结果表明,DepMamba 在抑郁症检测的准确性和效率上均优于现有的最先进模型。
本工作的贡献总结如下:
- 我们提出了 DepMamba,一种结合层次化建模和渐进式融合的新颖高效方法,这是 Mamba 在抑郁症检测中的首次尝试。
- 我们开发了一种结合 CNN 和 Mamba 的层次化建模方法,以更好地学习局部和全局上下文表示。
- 我们提出了一种渐进式融合方法,其核心是协作 SSM,在增强模态间融合的同时保留模态内特征,为多模态融合提供了新的视角。
- 广泛的实验结果证明了所提出方法相较于最先进基线的优越性和高效性。
二、提出方法
A. Mamba的初步介绍

B. DepMamba概述
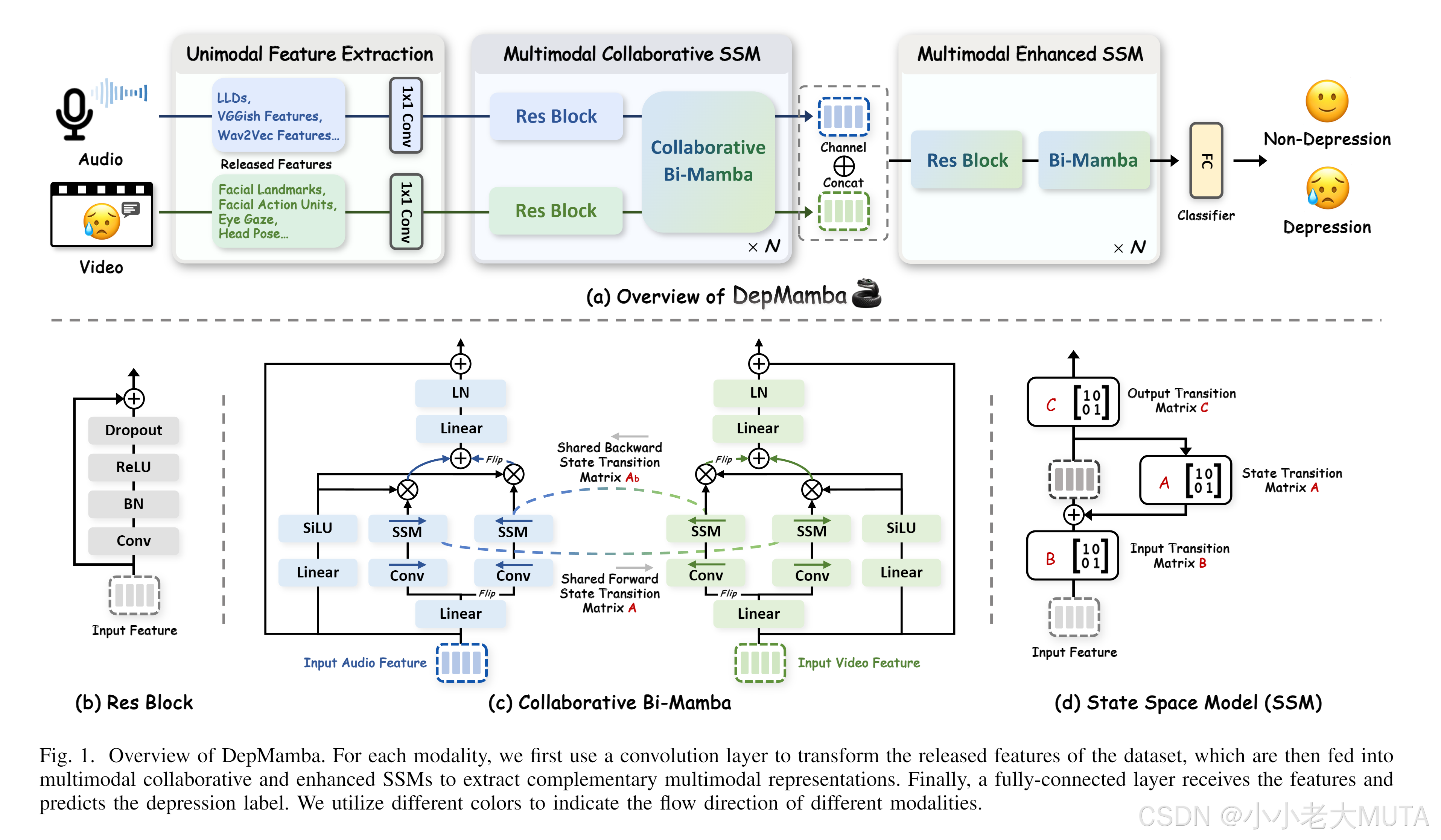
如图 1(a) 所示,提出的 DepMamba 实现了层次化上下文建模和渐进式多模态融合,包含三个关键组件:
- 单模态特征提取:首先利用现有的抑郁症数据集 [13], [25] 中发布的单模态特征,由于隐私问题,这些数据集通常不包含原始信号。然后,这些发布特征通过一维卷积分别转换到相同的维度空间。
- 多模态协作 SSM(CoSSM):旨在建模层次化上下文信息并聚合模态特定和模态共享的表示。每个 CoSSM 层集成了两个残差块(Res Blocks)[26] 和一个协作 Bi-Mamba。
- 多模态增强 SSM(EnSSM):首先拼接音频和视觉特征,并通过每层的 ResBlock 和 Bi-Mamba 建模层次化信息,同时增强多模态凝聚力。最后,使用线性层进行抑郁症检测。以下部分将详细介绍每个组件。
C. 层次化上下文建模
对于图 1 中的 CoSSM 和 EnSSM,我们提出利用 CNN 和 Bi-Mamba 实现从局部到全局的层次化上下文建模,有效捕捉长序列的视听内容。
具体来说,小卷积核的残差块擅长捕捉局部时间信息,而 Bi-Mamba 结合了两个双向 SSM,用于数据依赖的全局上下文建模,通过选择性注意力机制构建上下文的核心记忆。随后,这些局部和全局特征协同作用,丰富了上下文表示。这一过程有效提取了长序列中的内在互补特征,从而提升了整体性能。
D. 渐进式多模态融合
基于第 II-C 节中的模态无关上下文建模,我们进一步引入两阶段渐进式多模态融合。
第一阶段(CoSSM)
为了提取视听模态之间的互补信息,我们提出了协作 Bi-Mamba 以促进模态交互。
具体来说,Bi-Mamba 的前向 SSM 和后向 SSM 包含 6 个关键参数:前向矩阵 和后向矩阵
。状态转移矩阵
对系统影响最大,因为它们控制当前隐藏状态的演化,而
和
主要影响输入和输出状态。
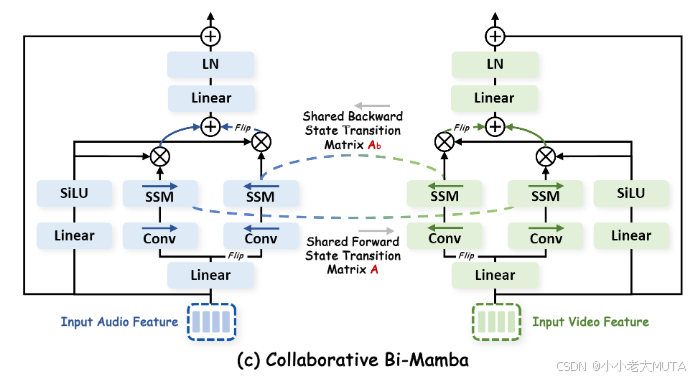
因此,如图 1(c) 所示,我们提出在模态间共享双向状态转移矩阵 和
,学习模态间共享的上下文信息,而
和
保持独立以捕捉模态特定信息。
前向协作 SSM 可以表示为:
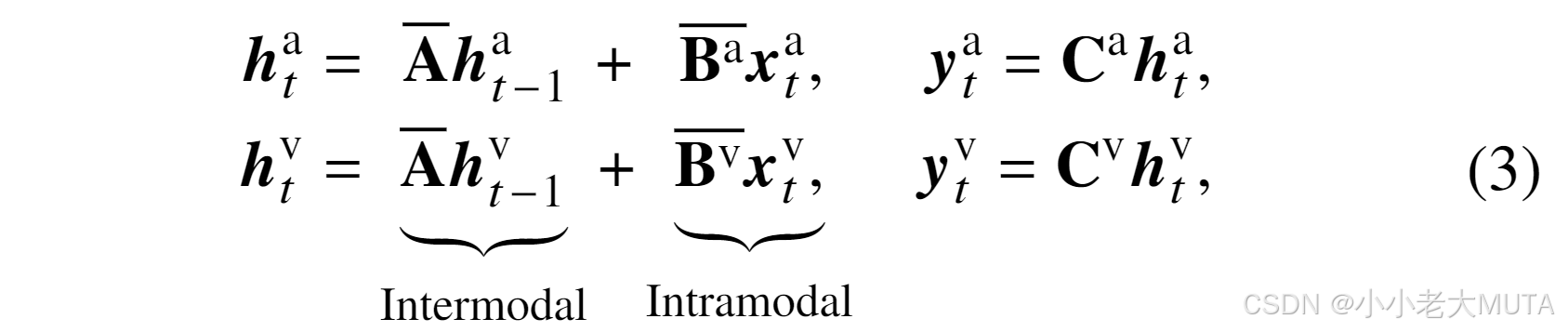
其中 和
分别表示音频和视觉的输入、输出和隐藏特征。
是共享的前向状态转移矩阵,
和
是两种模态的输入和输出矩阵。在不引入额外参数的情况下,基于控制理论的 CoSSM 显式建模了模态间共享和模态内特定信息,用于互补的多模态表示学习。
第二阶段(EnSSM)
我们首先拼接来自 CoSSM 的音频和视觉输出特征,并利用 Res-Block 和 Bi-Mamba 通过层次化上下文建模增强多模态凝聚力。通过采用两阶段流程,我们全面整合了模态内和模态间信息,促进了更有效的多模态融合。最后,我们简单地使用全连接层进行抑郁症分类。
三、实验
A. 实验设置
数据集:为了验证所提出的 DepMamba 与最先进(SOTA)方法的有效性,我们在两个大规模抑郁症数据集上进行了广泛实验:Depression Vlog (D-Vlog) [13] 和 Large-Scale Multimodal Vlog Dataset (LMVD) [25]。D-Vlog 和 LMVD 都是面向真实场景的视听抑郁症检测数据集,数据来源于 YouTube 和 TikTok 等社交媒体平台发布的 vlog 视频。为了保护用户隐私,两个数据集均使用 dlib [33] 工具包提取 68 个面部关键点作为视觉特征。此外,D-Vlog 使用 OpenSMILE [34] 工具包提取 25 个低级别描述符,而 LMVD 则提取 VGGish [35] 特征作为音频特征。D-Vlog 按 7:1:2 的比例划分为训练集、验证集和测试集,LMVD 则按 8:1:1 的比例划分。实验中,每个模型运行三次以避免随机性。
实现细节:对于 DepMamba,我们使用 Adam 优化器 [36] 进行训练,学习率为 1e-4,批量大小为 16,硬件为 24GB NVIDIA RTX 3090 GPU。目标函数采用二元交叉熵准则,总训练轮数设置为 120。单模态特征提取的卷积核大小为 1,通道数为 256。我们使用隐藏维度大小为 256,状态维度为 12(D-Vlog)和 16(LMVD),扩展系数为 4 作为每个 BiMamba 块的配置,CoSSM 和 EnSSM 的层数均为 1。
评估指标:根据之前的工作 [13], [25], [32],我们引入了四个广泛使用的指标来评估性能,包括准确率(Accuracy)、精确率(Precision)、召回率(Recall,也称为灵敏度)和 F1 分数。这些指标可以评估模型在平衡和不平衡场景下的整体性能。
B. 对比结果
为了证明 DepMamba 的有效性,我们在两个大规模数据集上比较了几种具有代表性的多模态抑郁症检测方法。
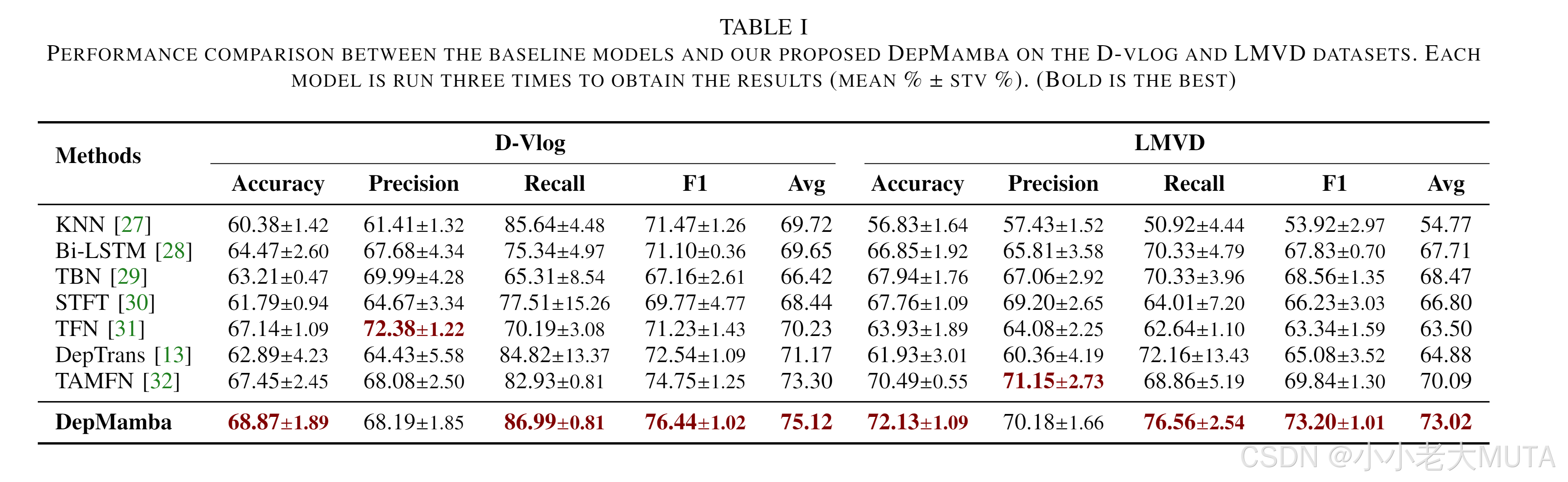
如表 I 所示,我们使用 4 个指标及其平均值来评估这些方法。可以看出,DepMamba 在两个数据集上均表现出优越的性能,平均值分别为 75.12 和 73.02,比第二好的方法分别提高了 1.82% 和 2.93%。在召回率方面,DepMamba 表现最佳,表明其在识别抑郁症患者方面更有效,从而在真实场景中最大限度地降低了假阴性的风险。此外,与 TBN [29]、TFN [31] 和 TAMFN [32] 等多模态融合方法相比,所提出的 CoSSM 和 EnSSM 增强了 DepMamba 捕捉视听数据中抑郁症互补表示的能力,从而提高了抑郁症检测的性能。
C. 消融实验
我们进行了消融实验以验证几个设计组件的有效性:(i) 模态选择,探索单模态或多模态的影响;(ii) 层次化建模,分析局部(即 CNN)和全局(即 Mamba)时序建模的效果;(iii) 渐进式建模,评估协作融合和增强融合的影响。表 II 展示了两数据集上 4 个指标的平均结果。
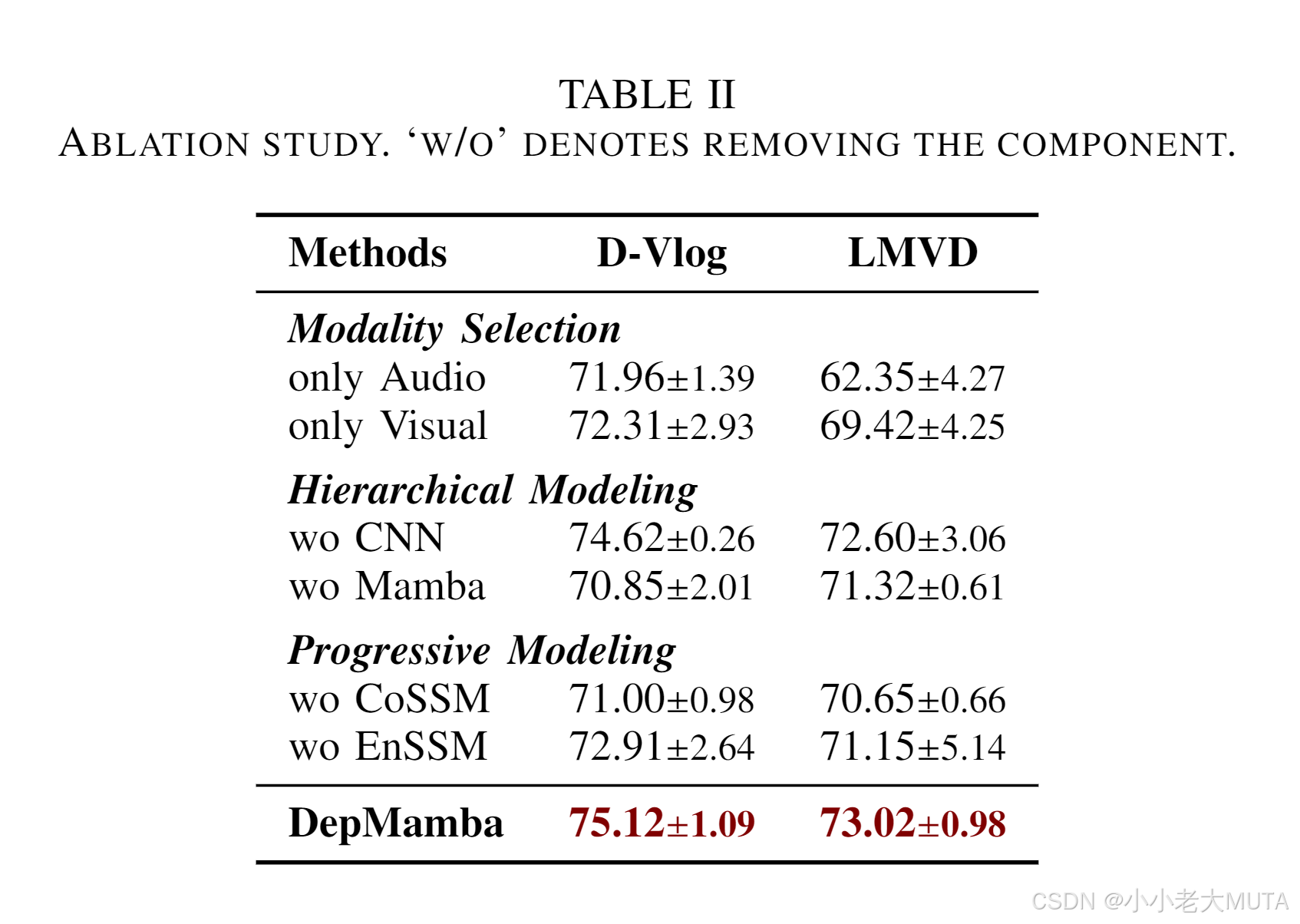
我们有以下观察:
- 多模态数据比单模态数据提供了更全面和有效的信息,两个数据集分别提高了 2.81% 和 3.60%。
- 全局时序建模比局部建模显著提升了抑郁症检测性能,因为患者在说话时常常停顿,导致长时序内容。移除 Mamba 导致性能分别下降 4.27% 和 1.70%,而移除 CNN 仅分别下降 0.50% 和 0.42%。
- 渐进式融合有效促进了视听信息之间的交互,并提取模态内和模态间知识以实现更好的性能。
D. 效率分析
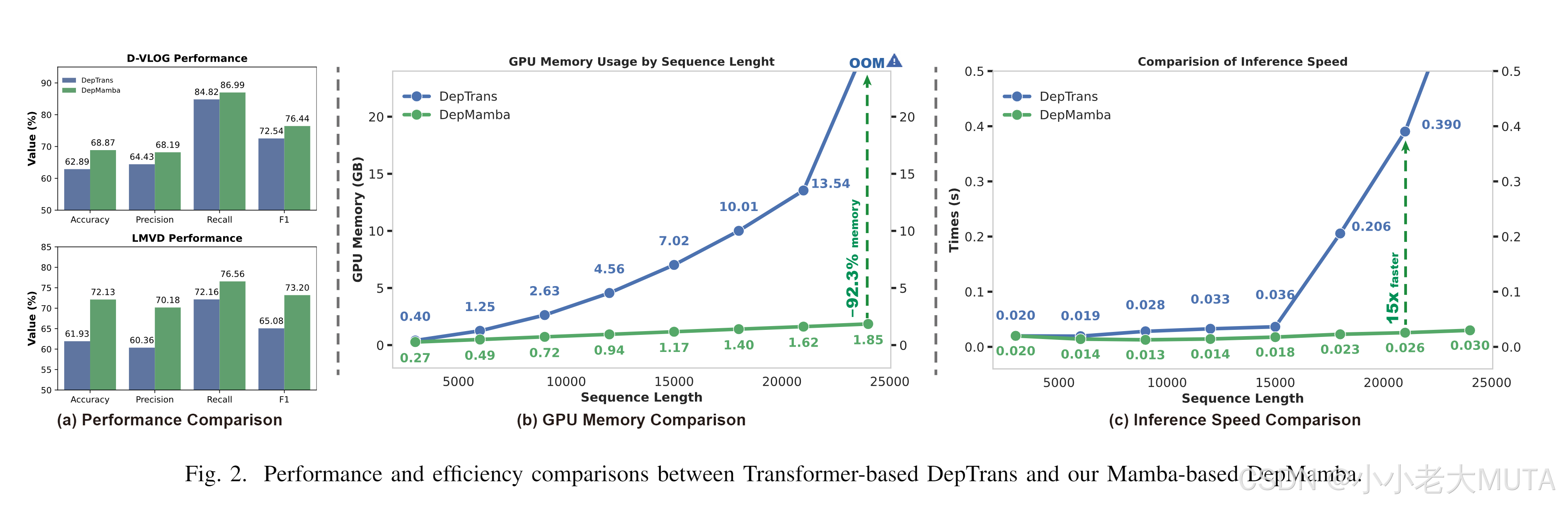
如图 2 所示,我们评估了基于 Mamba 的 DepMamba 与基于 Transformer 的 DepTrans 的效率。结果表明,DepMamba 在两个数据集上均优于 DepTrans,平均分别提高了 3.95% 和 8.14%。在处理长序列建模时,DepMamba 在计算和内存效率上也优于 DepTrans。例如,在 8 种不同序列长度下,DepMamba 在长度为 21000 时比 DepTrans 快 15 倍,在长度为 24000 时节省了 92.3% 的 GPU 内存。而基于 Transformer 的方法的 GPU 内存使用量随长度增加呈指数增长 [37],DepMamba 则呈现线性增长,在实际应用中具有明显优势。



















 1398
1398

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











