






抑郁检测
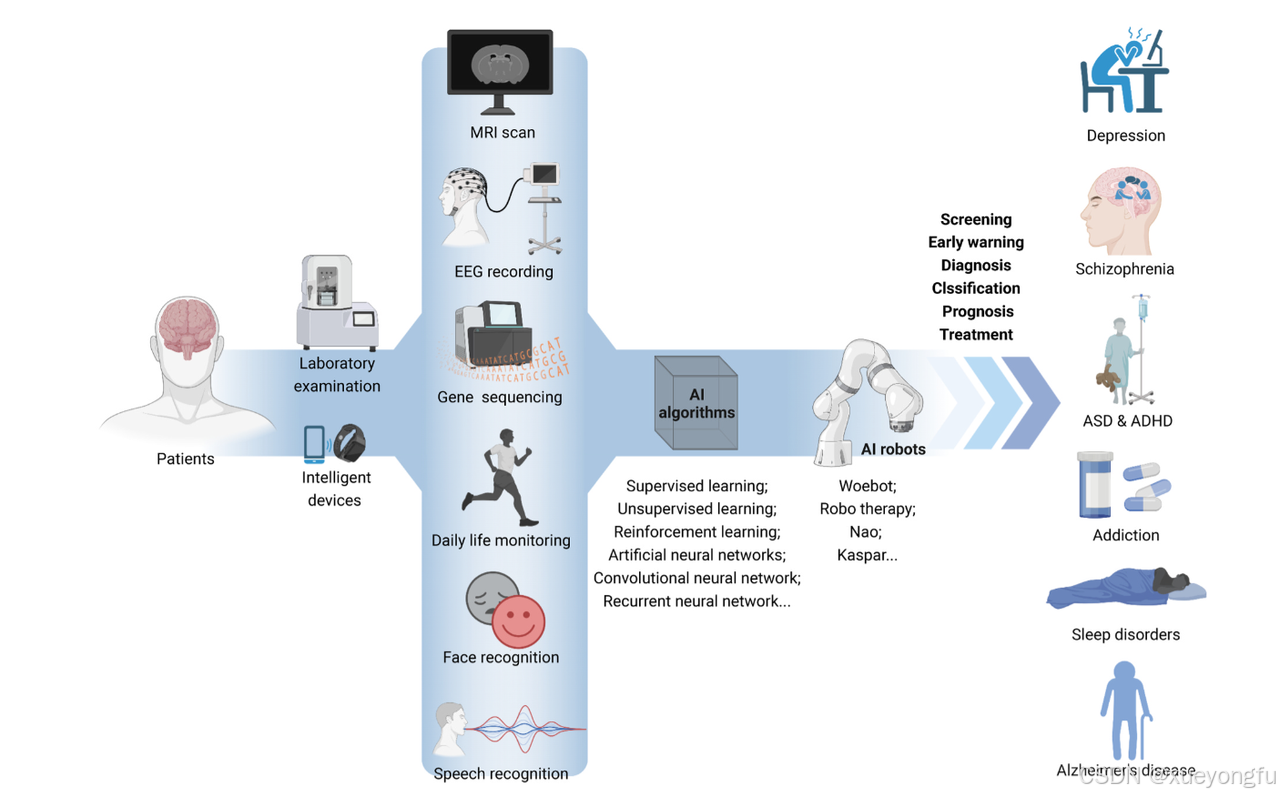
机器学习时代
第一代抑郁诊断方法基于传统机器学习算法。这种方法依赖于强大的先验知识,并需要通过各种特征提取算法来识别与抑郁相关的特征。随后,通过这些特征构建结构较为简单的机器学习模型,使模型能够自动从特征数据中学习并优化性能,从而实现辅助预测抑郁的目标。
语言信息
抑郁症患者的语言特征通常表现为悲观、低自尊以及模糊、重复或不连贯的语句内容。目前,文本内容的分类方法主要分为基于语法规则与统计方法的组合以及机器学习方法。
-
语法规则与统计方法:
-
这类方法通常手动构建领域特定的情感词典,通过比较输入文本中的词汇与情感词典中的词汇或计算向量距离,识别情感词及其极性。
-
在中文抑郁情感词典构建中,方法有:结合词频统计与情感词强度的挖掘方法;基于TF-IDF算法扩展基础情感词典,通过词相似度计算进行拓展;基于权重预处理的PRE-TF-IDF分类算法,通过增加权重预处理和词密度权重提升文本分类的准确性。
-
-
传统机器学习方法:
-
通过手动提取样本数据集中的特征,并基于这些特征选择合适的分类模型。
-
常用分类器包括支持向量机(SVM)、朴素贝叶斯(NB)、极端梯度提升(XGBoost)、K近邻(KNN)等。
-
调查显示,SVM因其能够有效应对高维计算和过拟合问题,在医学数据集中的使用较为广泛。
-
语音信息
通过临床观察和统计,抑郁患者的语音行为通常表现为语速慢、音量低、自发性降低以及发音不清等特征。这些特征可以通过多种语音特性体现,包括基于音高、语调、能量和节奏变化的韵律特性,以及由声带振动引起的基频特性和反映语速的特性。研究表明,抑郁患者的语速下降更快,反应时间更长,且音高和响度与抑郁严重程度呈负相关。
相关的抑郁检测的音频特征集:eGeMAPS和COVAREP
音频特征:韵律、谱系、声门语音特征、声带振动引起的基频特性、音频的MFCC特征
基于音频特征进行分类的算法:基本都是传统机器学习算法如SVM、逻辑回归等
视觉信息
抑郁患者的心理状态与面部表情变化密切相关,其面部特征通常表现为缺乏表情、忧郁神情、悲伤目光以及回避眼神接触。
抑郁患者与健康个体之间的眼动模式存在显著差异,包括更大的向下注视角度、较短的注视时长以及较低的微笑强度。此外,双相情感障碍中的精神运动障碍研究表明,抑郁患者在注视任务中的反应时间更长。
视觉特征提取:特定个体的活动外观模型(Person Specific Active Appearance Model)、其他各种特征提取算子
基于提取的视觉特征进行分类:基本都是传统机器学习算法
脑成像信息
部分论文:
-
Multivariate pattern analysis strategies in detection of remitted major depressive disorder using resting state functional connectivity
-
2017
-
利用左后扣带皮质和右后背外侧前额叶皮质的特征,使用支持向量机(SVM)算法区分重度抑郁患者和健康对照组,准确率达76.1%。
-
电生理数据
部分论文:
-
Depression recognition based on the reconstruction of phase space of EEG signals and geometrical features.
-
2021
-
提出一种通过脑波信号的相空间重建和几何特征检测抑郁症的方法。该框架结合粒子群优化选择特征和支持向量机分类器,平均分类准确率达到99.30%,Mathews相关系数(MCC)为0.98。
-
-
A Systematic Evaluation of Machine Learning–Based Biomarkers for Major Depressive Disorder
-
2024
-
本研究系统评估了基于机器学习的重度抑郁症(MDD)生物标志物的有效性。涵盖了多种神经影像学模态,包括结构磁共振成像(MRI)、功能磁共振成像(fMRI)、扩散张量成像(DTI)以及抑郁症的多基因风险评分(PRS)等.尽管整合多种神经影像学模态数据,模型性能并未显著提高。结合所有模态的预测结果,最高平均平衡分类准确率为61.1%.
-
生化生理数据
比如红细胞分布宽度、血清葡萄糖和总胆红素
部分论文:
-
Artificial intelligence-based major depressive disorder (MDD) diagnosis using raman spectroscopic features of plasma exosomes
-
血浆外泌体由于能够穿过血脑屏障并提供与大脑相关的信息,被认为是MDD的新型生物标志物。在此研究中,通过深度学习分析和血浆外泌体的表面增强拉曼光谱(SERS)实现了一种新颖且精确的MDD诊断方法。
-
多模态信息融合
抑郁症患者的特征数据在多个模态中表现出差异,这些模态的信息可以相互补充。
部分论文:
-
Research on depression detection algorithm combine acoustic rhythm with sparse face recognition.
-
2019
-
结合语音和面部视觉数据,提出了多模态融合抑郁症诊断算法,引入了频谱减法、正交匹配追踪算法以及基于音频和面部情感比率的级联方法,诊断准确率达 81.14%,比仅使用音频单模态提高了 6.76%。
-
深度学习时代
深度学习技术可以自动提取受访者的多种模态特征数据,并基于大量特征数据训练诊断模型,而传统机器学习时代多依赖人工构建特征。
语言信息
多结合社交网络文本数据与深度学习进行抑郁识别。
部分论文:
-
The Study of Depression Analysis Based on Deep Learning and Social Text.
-
2022
-
采用了多种机器学习和基于Transformer的深度学习模型来分析社交媒体推文数据,以检测其中的抑郁迹象。首先,对推文数据进行预处理,包括文本清洗和特征向量化;然后,训练并比较了逻辑回归、朴素贝叶斯、随机森林等传统机器学习模型,以及RoBERTa、DistilBERT等Transformer模型的性能,以确定最有效的模型用于抑郁症检测.
-
语音信息
部分论文:
-
Speech depression recognition based on attentional residual network
-
2022
-
本文提出了一种基于注意力残差网络的语音抑郁识别模型。该模型结合了残差网络和注意力机制,通过设计基于自我参照效应的心理实验范式构建抑郁语料库,并提取语音的梅尔频率倒谱系数(MFCC)特征,实现了对抑郁的自动识别。实验结果表明,该模型在抑郁二分类和严重程度预测任务中均取得了较好的性能,显示出较高的准确性和鲁棒性。
-
视觉信息
通过将完整面部信息作为输入,防止特征提取过程中的信息丢失,并由模型自动提取特征。此方法需要大量视频数据和复杂的深度学习模型训练。
部分论文:
-
Combining global and local convolutional 3d networks for detecting depression from facial expressions
-
2019
-
该论文提出了一种基于全局与局部三维卷积神经网络(C3D)的深度学习方法,通过分析视频中的面部表情来检测抑郁水平,重点结合全脸与眼部区域的时空特征,并通过3D全局平均池化(3D-GAP)减少模型复杂性和过拟合风险。实验结果表明,该方法在两个公开数据集(AVEC2013和AVEC2014)上表现优于现有技术,为自动化抑郁检测提供了一种高效的解决方案。
-
-
FacialPulse: An Efficient RNN-based Depression Detection via Temporal Facial Landmarks
-
2024
-
背景:许多端到端的深度学习方法利用面部表情特征来自动检测抑郁症。然而,大多数当前的方法忽视了面部表情的时间动态性。尽管最近的3DCNN方法弥补了这一缺陷,但由于选择了基于CNN的骨干网络和冗余的面部特征,它们引入了更多的计算成本。
-
该论文通过考虑面部表情的时间相关性,以高准确率和快速度识别抑郁症。FacialPulse中的面部运动建模模块(FMMM)利用其双向特性和有效处理长期依赖关系的能力,充分捕捉时间特征。由于所提出的FMMM具有并行处理能力和门控机制以减轻梯度消失,该模块还可以显著提高训练速度。
-
多模态信息
部分论文:
-
A multimodal feature fusion-based method for individual depression detection on sina weibo
-
2020
-
总结了与用户文本、社交行为和图像相关的九种统计特征,利用XLNet模型提取文本的深度表示,并与其他模态数据整合,构建了多模态特征融合网络(MFFN)。该方法在WU3D测试数据集上取得了不错效果。
-
-
A Multimodal Fusion Depression Recognition Assisted Decision-Making System Based on EEG and Speech Signals
-
2023
-
涉及脑电图(EEG)和语音信号的多模态融合,旨在全面利用数据来辅助决策过程。从时频域特征、空间特征和语义特征等方面,本研究提取信息并将其融合,构建了一个多模态特征空间。同时,引入并应用于实际场景中的特征级融合策略,成功创建了一个多模态融合的抑郁症识别辅助决策系统。
-
-
IIFDD: Intra and inter-modal fusion for depression detection with multi-modal information from Internet of Medical Things
-
2024
-
提出了IIFDD框架,包括特征提取、单模态模型、模态内融合和模态间融合四个阶段。在特征提取阶段,从原始数据中提取音频、文本和视觉数据的特征,并使用预训练的深度学习模型学习其深度表示。单模态模型用于分别编码每种模态的特征。模态内融合模块通过融合同一模态的低维预设计特征和高维深度表示,更好地学习语义信息。模态间融合模块则利用注意力机制融合不同模态的特征,完成抑郁症分类.
-
结合手工特征和深度学习
该方法利用手动提取的抑郁特征作为先验知识,并运用深度学习模型从不同模态的特征中捕获深层表示信息。最终,通过多种融合策略整合多源信息,以实现抑郁症的识别。在融合范式方面,包括数据层融合、特征层融合和决策层融合。
-
数据层融合:在数据层融合方法中,来自不同模态的数据被合并为集成特征,使用简单的特征向量,然后将这些特征输入神经网络以进行抑郁症识别。
-
特征层融合:以特定方式将从不同模态提取的特征结合起来,这些特征的融合方法通常包括神经网络、注意力机制、残差网络及其组合
-
决策层融合:为每种模态构建强大的特征提取模型和分类器,然后选择适当的融合策略以获得最终结果。常见的融合策略包括投票、加权和机器学习算法。
相关举例:
-
It’s just a matter of time: detecting depression with time-enriched multimodal transformers
-
2023
-
属于特征融合。通过结合文本、图像和时间信息来识别社交媒体平台上抑郁用户的方法。他们利用EmoBERTa和对比语言-图像预训练(CLIP)对文本和图像进行编码,使用跨模态编码器处理编码后的图像和文本序列,最后结合变换编码器及相对发布时间编码为位置嵌入,以识别抑郁用户。
-
基于大模型LLM的检测系统
部分论文:
-
一种基于大模型的检测系统
该系统通过虚拟医生与受访者的互动,将诊断过程与临床量表评估方法的优势相结合,最终通过大语言模型(LLM)对量表进行评估。
-
构建了对话转录模型、两个基础特征提取模型(MDD音频模型和MDD视频模型)用于描述语音和视觉特征,还开发了基于LLM的聊天系统(针对重度抑郁障碍的聊天模型)用于抑郁症诊断和个人信息总结。
-
通过基于量表的评估过程和诊断标准,实现了抑郁症的自动化诊断。系统外的端到端交互能够提高诊断效率并降低成本。系统内部通过整合多源异构信息和多个大模型的交互,从多个维度分析受访者的情况,同时引入临床诊断标准以提供更准确的诊断支持。
-
诊断结果和细节以文本形式直观呈现,使系统具有高度的可解释性,从而增强医生和受访者对诊断结果的信服度。
-
-
Depression Detection on Social Media with Large Language Models
-
2024
-
介绍了一种名为DORIS的抑郁症检测系统,该系统通过分析社交媒体上的帖子来检测抑郁症。它结合了医学知识和大型语言模型(LLMs),以应对两个主要挑战:需要专业的医学知识和需要高准确性和可解释性。DORIS通过标注高风险文本和分析用户的情绪轨迹来提高检测的准确性,并结合传统分类器以增强可解释性。实验结果表明,DORIS在AUPRC上比现有方法有显著提高,显示出其在自然语言处理应用中的潜力和价值
-
-
Automatic depression severity assessment with deep learning using parameter-efficient tuning
-
2024
-
提出了一种新颖的方法来解决抑郁评估中的数据稀缺问题。该方法结合了预训练的大语言模型和参数高效的调整技术。具体来说,通过在预训练模型中引入少量可调参数(前缀向量),即prefix-tuned,来指导模型预测患者的PHQ-8评分。
-
-
Depression Symptoms Modelling from Social Media Text: A Semi-supervised Learning Approach
-
2022
-
这篇文章介绍了一种半监督学习框架,用于从社交媒体文本中建模抑郁症状。提出了一个半监督学习(SSL)框架,结合了监督学习模型和零样本学习模型,从一个大型的自建的抑郁推文库(DTR)中提取与抑郁症状相关的样本。
-
数据集构建:使用两个数据集(IJCAI-2017和UOttawa)中的自我披露抑郁用户的推文构建抑郁候选推文数据集。通过抑郁推文检测模型(DPD)筛选出抑郁推文,形成抑郁推文库(DTR)。从DTR中选取部分推文进行临床医生标注,形成临床标注数据集。
-
半监督学习框架:初始模型训练:使用临床标注数据集训练初始的抑郁症状检测(DSD)模型。利用初始DSD模型和零样本学习模型从DTR中提取更多与抑郁症状相关的样本。将收获的数据用于重训练DSD模型,以提高模型的鲁棒性和准确性。当无法从DTR中收获更多样本或模型性能不再提升时停止SSL过程。
-
-
LLM Questionnaire Completion for Automatic Psychiatric Assessment
-
2024
-
这篇论文提出了一种基于大型语言模型(LLM)的新方法,用于从非结构化心理访谈中生成结构化问卷答案,从而预测抑郁(PHQ-8)和创伤后应激障碍(PTSD,PCL-C)的量表得分。
-
研究利用E-DAIC数据集,结合GPT-3.5等模型模拟访谈对象回答标准化问卷和自定义问卷,将生成的答案作为特征输入随机森林回归模型进行预测。实验结果显示,该方法在预测准确性方面优于多种基线模型,尤其是结合多领域问卷时表现显著。
-
对话方式检测
部分论文:
-
Early detection of depression using a conversational AI bot: A non-clinical trial
-
2023
-
这篇论文研究了人工智能驱动的对话机器人(DEPRA)在抑郁症早期检测中的可行性和有效性。
-
针对全球范围内因成本、地理位置、社会污名和医疗资源短缺而未能及时获得心理干预的人群,DEPRA通过Facebook Messenger与用户互动,基于标准化的抑郁症评估工具(SIGH-D和IDS-C)设计了27个问题,用于检测抑郁症状的早期迹象。
-
在试验中,50名年龄在18到80岁的澳大利亚居民参与了测试,结果显示约30%-32%的参与者无抑郁症状,20%-22%的参与者存在非常严重的抑郁症状。用户对DEPRA的满意度达到79%,认为其问题设计清晰,使用体验良好。研究表明,DEPRA能够提供经济、隐私保护和便捷的抑郁症筛查方法,尽管不能替代专业心理健康服务,但作为一种辅助工具在减轻心理健康问题负担和降低社会障碍方面表现出显著潜力。
-
基于可穿戴设备检测抑郁症
基本概述
可穿戴设备在抑郁症检测中的应用表现出了良好的前景,尤其是在身体活动、睡眠模式和心率数据的收集和分析方面。然而,目前设备和算法仍需进一步优化,尤其是在设备种类多样化和与其他数据的融合方面。
-
设备类型与使用情况 可穿戴设备在抑郁症检测中广泛应用,常用设备包括Actiwatch系列和Fitbit系列,主要佩戴于手腕。这些设备通过监测身体活动、睡眠模式、心率和其他生理数据,为抑郁症检测提供丰富的数据来源。
-
数据类型与作用 可穿戴设备采集的数据种类丰富,包括:
-
身体活动数据(如步数、卡路里消耗):用于评估运动量与心理健康的关联。
-
睡眠模式(如时长、质量):帮助识别抑郁相关的睡眠异常。
-
心率与变异性:反映情绪波动和压力水平。
-
社交互动与位置数据:通过行为模式评估社会孤立感与情绪状态。
-
-
性能表现 使用AI模型分析上述数据,设备在抑郁症检测中表现出较高的准确率(最高0.89)、灵敏度(最高0.87)和特异性(最高0.93),展示出自动化检测抑郁症的潜力。
-
研究局限与改进方向 尽管性能良好,目前研究存在样本规模小、设备多样性不足的问题。未来应结合其他数据类型(如神经影像学数据),探索更多设备类型,并开发实时检测抑郁症的商业化产品。
相关算法介绍
树模型算法
-
Random Forest: 基于多棵决策树的集成,适合处理复杂、高维数据,常用于分类问题。
-
Decision Tree: 简单的树状模型,易于解释,但在单一树结构下易过拟合。
-
Gradient Boosting: 通过逐步优化误差,增强分类能力,但计算成本较高。
-
Extreme Gradient Boosting (XGBoost): Gradient Boosting的优化版本,性能高且效率好。
-
AdaBoost: 权重自适应调整的集成模型,适用于提升弱分类器的准确性。
-
Gradient-Boosted Decision Trees: 基于梯度提升的决策树模型,适合非线性关系建模。
回归与概率模型
-
Logistic Regression: 用于二分类问题的线性模型,简单易用,但对复杂数据能力有限。
-
Ridge Regression: 增加正则化项以防止过拟合,适合连续型变量预测。
-
Linear Regression: 用于连续变量预测,适用于线性关系建模。
-
Naive Bayes: 基于概率的分类算法,假设特征之间独立,适用于快速分类。
-
Gaussian Process: 基于高斯分布的非参数方法,适用于小数据集和连续变量预测。
神经网络模型
-
Artificial Neural Network (ANN): 模拟生物神经网络,适合处理复杂、非线性数据。
-
Convolutional Neural Network (CNN): 擅长处理图像和时间序列数据,通过提取局部特征实现高效建模。
-
Deep Neural Network (DNN): 深层网络结构,适合复杂数据,但需要大数据支持。
-
Multilayer Perceptron (MLP): 经典全连接神经网络,适用于结构化数据建模。
-
Long Short-Term Memory (LSTM): 专注于时间序列数据,擅长捕捉长期依赖。
支持向量机与相邻算法
-
Support Vector Machine (SVM): 用于分类问题,通过寻找最优分隔平面实现高精度。
-
Support Vector Classifier (SVC): SVM的一种实现,支持多分类任务。
-
K-Nearest Neighbours (KNN): 基于距离的分类算法,易于理解,但计算量大。
正则化和优化模型
-
elasticNet: 将L1和L2正则化结合,处理高维数据中的多重共线性问题。
-
least Absolute Shrinkage and Selection Operator (LASSO): 使用L1正则化的回归模型,可进行特征选择。
数据类型
基于可穿戴设备进行检测,所基于的数据类型如下:
-
睡眠数据 (Sleep data):与个体的睡眠模式和质量相关的信息。
-
心率数据 (Heart rate data):包括静息心率、心率变异性等信息。
-
心理健康指标 (Mental health measures):关于心理状态、情绪和心理健康评估的数据。
-
智能手机使用数据 (Smartphone usage data):与手机使用频率、时长及行为相关的数据。
-
位置信息数据 (Location data):基于地理位置的活动跟踪。
-
社交互动数据 (Social interaction data):关于人与人之间互动模式和频率的数据。
-
光暴露数据 (Light exposure):关于个体暴露于光照环境的记录。
-
人口统计数据 (Demographic data):例如年龄、性别、职业等背景信息。
-
皮电活动数据 (Electrodermal activity data):与个体生理兴奋状态相关的皮肤电导变化数据。
-
昼夜节律数据 (Circadian rhythms):反映生物钟和日夜活动模式的数据。
-
皮肤温度数据 (Skin temperature data):体温的动态变化数据。
-
天气数据 (Weather data):与气候、天气条件相关的数据。
部分论文介绍
-
Detecting Depression and Predicting its Onset Using Longitudinal Symptoms Captured by Passive Sensing: A Machine Learning Approach With Robust Feature Selection
-
2021
-
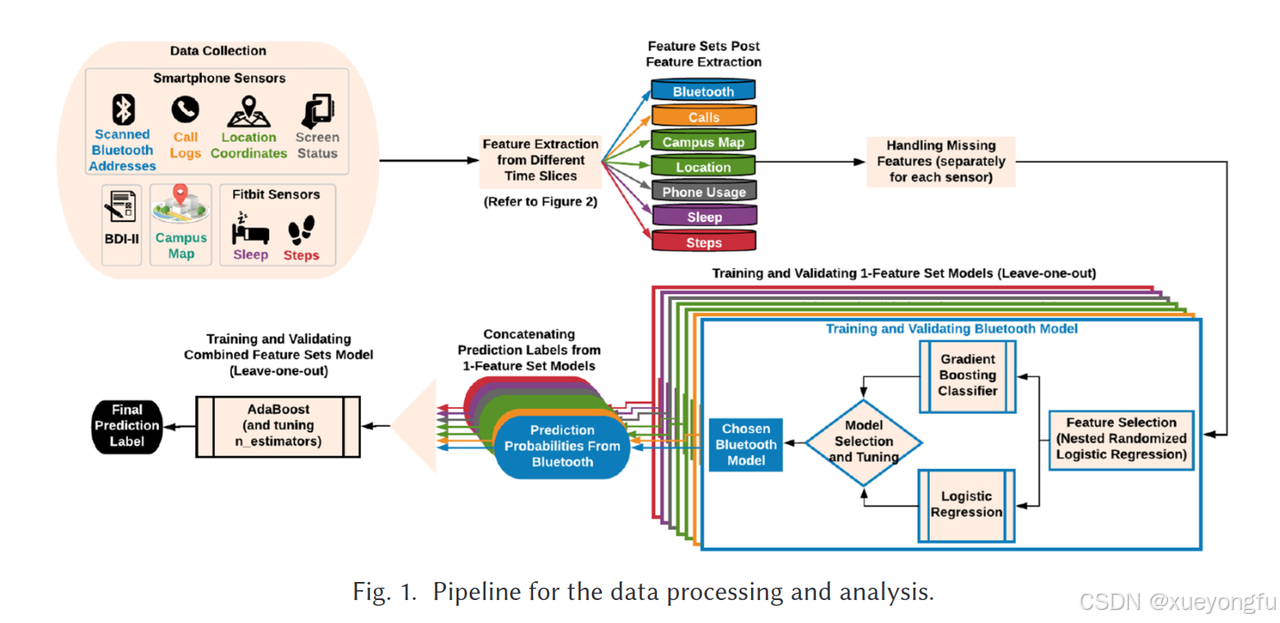
数据处理:采用智能手机和可穿戴设备采集数据,包括蓝牙、通话记录、位置、校园地图、步数、手机使用和睡眠等七个主要特征集。此外,为更好捕捉行为的动态变化,研究还提取了行为变化特征,如斜率、变化点以及变化前后的行为趋势。
-
算法学习:提出了一种嵌套随机逻辑回归方法。该方法先将特征按时间切片分组,在每组内进行特征选择,再对所有组的结果进行全局特征选择,从而确保选出的特征集稳定且具有代表性。研究构建了单传感器特征模型,利用逻辑回归和梯度提升分类器分别对每个特征集进行分类建模。随后,通过集成学习方法,综合所有特征集模型的预测概率,生成最终的预测结果。
-
-
-
Applying machine learning in motor activity time series of depressed bipolar and unipolar patients compared to healthy controls
-
2020
-
这篇论文研究了如何通过机器学习技术分析抑郁症患者(包括双相和单相抑郁症患者)与健康个体的运动活动时间序列,以补充现有的主观诊断方法。
-
研究采用了23名抑郁症患者和32名健康对照的14天腕戴加速度计数据,提取了平均活动水平、活动标准差和零活动比例等统计特征,并使用随机森林、深度神经网络(DNN)和卷积神经网络(CNN)模型进行分类。
-
部分相关数据集
英文数据
-
AVEC 抑郁检测数据集
-
AVEC(Audio/Visual Emotion Challenge)抑郁检测数据集是一个专注于通过多模态数据(如语音、视频和文本)检测抑郁症状的公开研究平台。它旨在为开发和测试基于人工智能的抑郁检测方法提供标准化数据和评估基准,推动心理健康与AI技术的结合。
-
包含语音、视频、文本等模态数据,每个样本标注抑郁评分
-
-
multi-modal open dataset for mental-disorder analysis
-
提供了一个用于精神障碍分析的多模态开放数据集。该数据集包括来自临床抑郁症患者和匹配的正常对照组的脑电图(EEG)数据和语音记录数据,这些患者和对照组均由医院的专业精神病学家精心诊断和选择。
-
脑电图数据集包括使用传统的128电极弹性帽和可穿戴的3电极脑电图采集器收集的数据,后者用于普适计算应用。53名参与者的128电极脑电图信号在静息状态和进行点探测任务时被记录下来;55名参与者的3电极脑电图信号在静息状态时被记录;52名参与者的音频数据在访谈、阅读和图片描述期间被记录下来。
-
-
Paper:A Dataset for Research on Depression in Social Media
-
Social Media Depression Dataset 综述
-
中文数据
-
CMDC1
CMDC1 数据集包含半结构化访谈的数据,收集了音视频记录和问卷回复,并提取了多种视觉、听觉和文本特征。所有受试者都完成了音频录制,但只有部分受试者完成了视频录制,因此数据集可分为两组:一组包含音频和文本特征的完整集,另一组包含音频、文本和视觉特征的子集。由于访谈中预设了12个问题并存储了受试者的回答,因此该数据集的维度为12。完整数据集包含78个样本(26个抑郁样本和52个健康样本),而包含三种模态的子集包含45个样本(19个抑郁样本和26个健康样本)。
-
EATD-Corpus2
EATD-Corpus 数据集由162名同济大学学生志愿者的访谈音频和文本转录数据组成。根据中国人的标准,SDS 指数得分(即原始 SDS 分数乘以1.25)大于或等于53表明受试者存在抑郁症状。因此,该数据集中有30个抑郁样本和132个非抑郁样本。EATD-Corpus 在访谈中预设了3个问题并存储了受试者的回答,因此该数据集的维度为3。
-
SWDD
Sina Weibo Depression Dataset (SWDD) 是从新浪微博平台收集的用于心理健康研究的公开数据集,主要包含用户发布的微博文本及其情感标签(抑郁或非抑郁)。数据通过关键词检索和情感词典筛选,并经过人工或半自动标注,标注内容包括抑郁情绪表达或普通情绪表达。数据集经过匿名化和去重处理,以确保用户隐私和数据质量。
SWDD 广泛应用于心理健康监测、情感分析和自然语言处理任务,支持开发抑郁症自动识别系统和情感分类模型。它为社交媒体数据驱动的心理健康研究提供了宝贵资源,但需要注意数据样本的偏倚和隐私保护问题。

















 1577
1577

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









