







前言
vision mamba整个代码结构和detr系列很像,可以先参看detr系列中的数据集设置:
DAB-DETR复现以及训练自己的数据集-CSDN博客
下述内容需要读者具备datset、dataloader等关系的认知。
Vision Mamba源码
数据集的设置


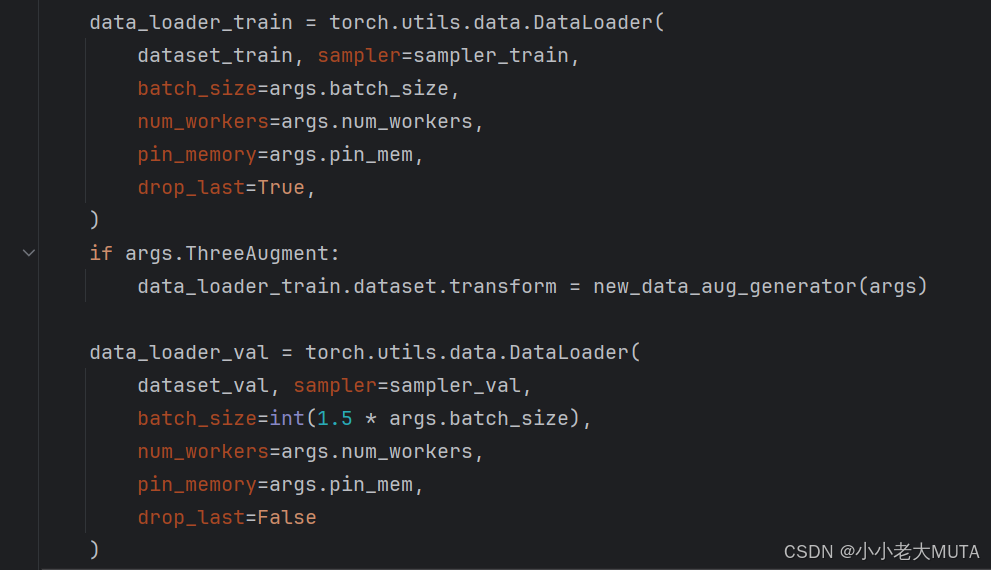
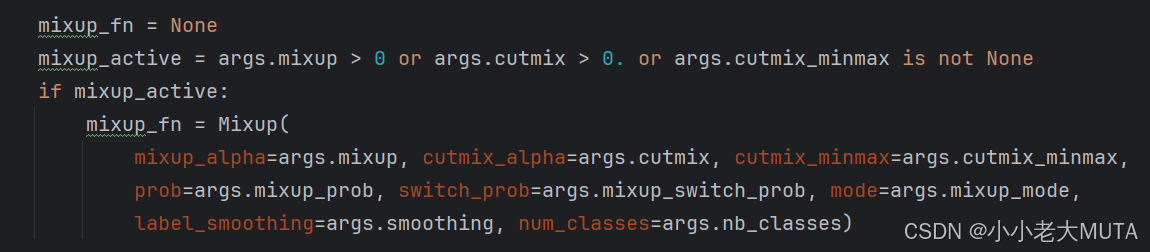
build_dataset
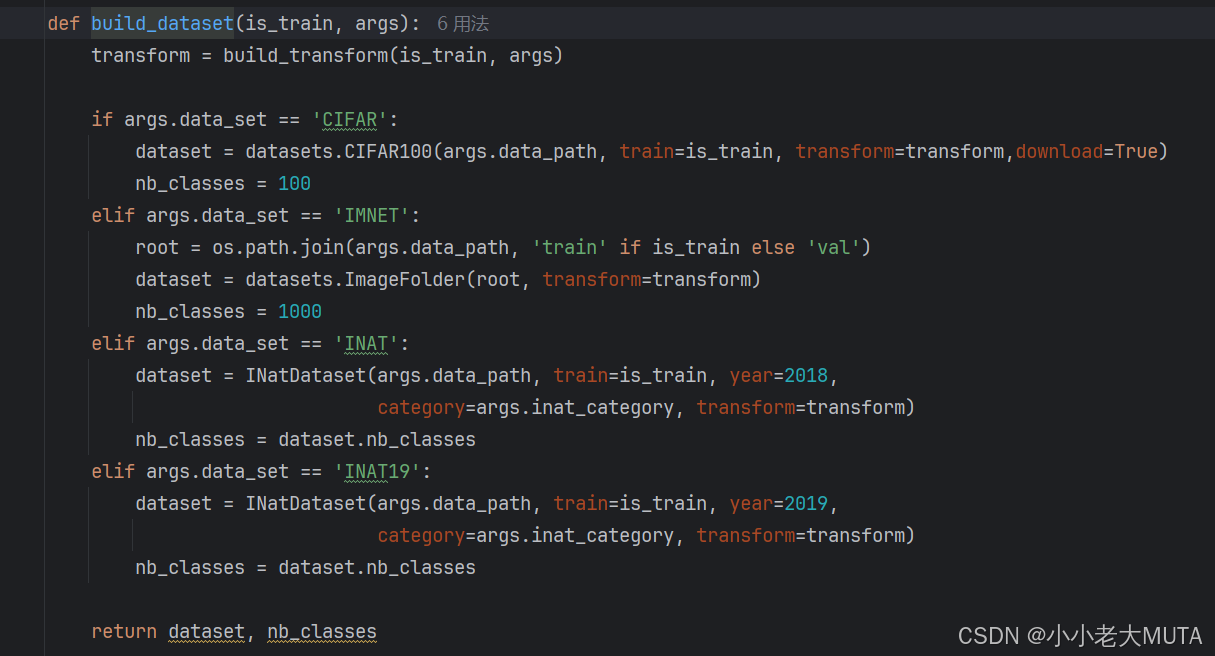
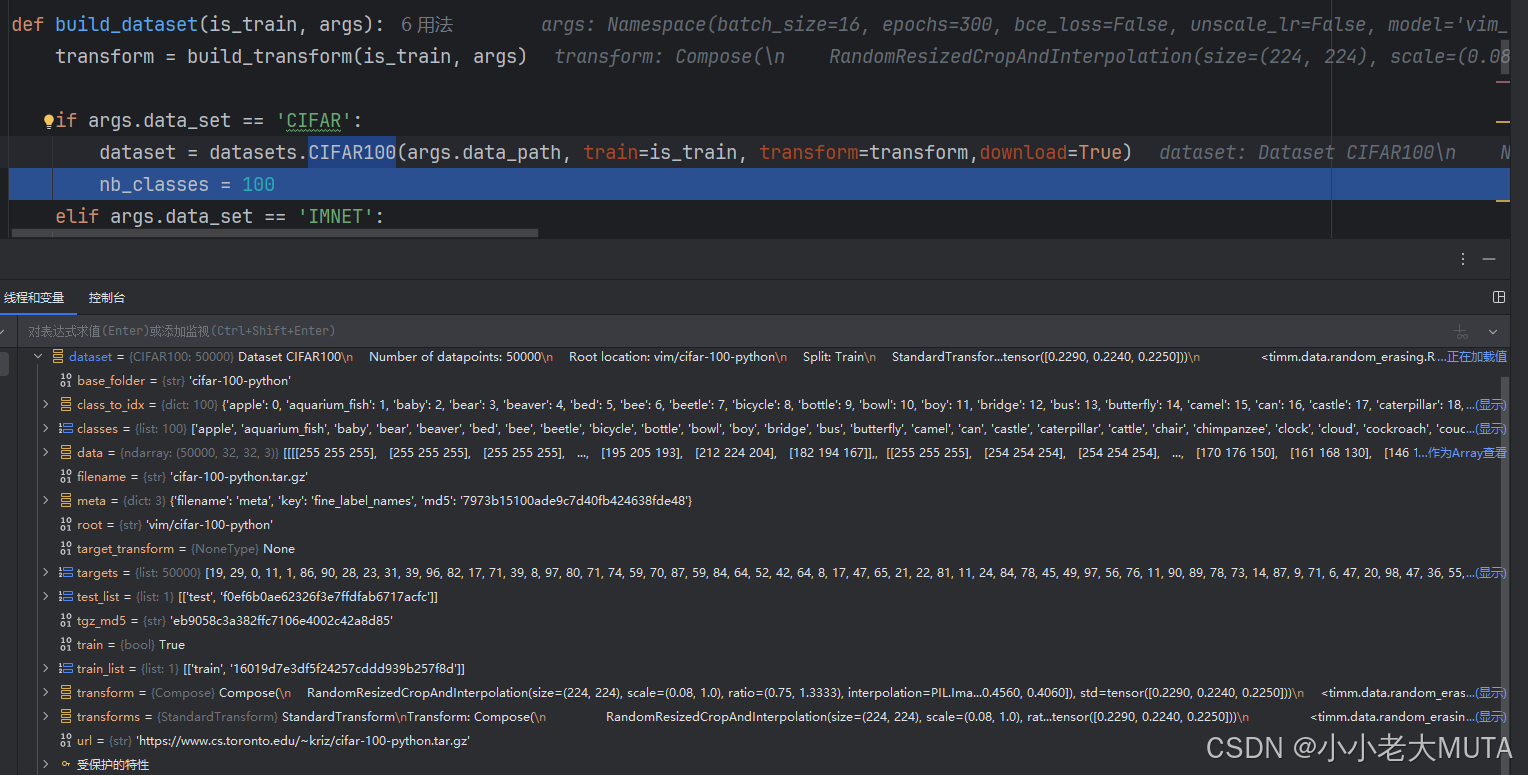
从dataloader中读取的一批次的samples和targets

samples是从dataloader中读取到的打包好的一批次的图像数据,[16,3,224,224],表示一个批次中有16张图片,每张图片rgb三通道,宽高为224*224。
一般在dataset打包数据的时候,都需要对源图像进行处理,包括数据增强、尺寸调整等操作最后转换得到224*224的大小,再对数据进行封装打包到dataloader中去。
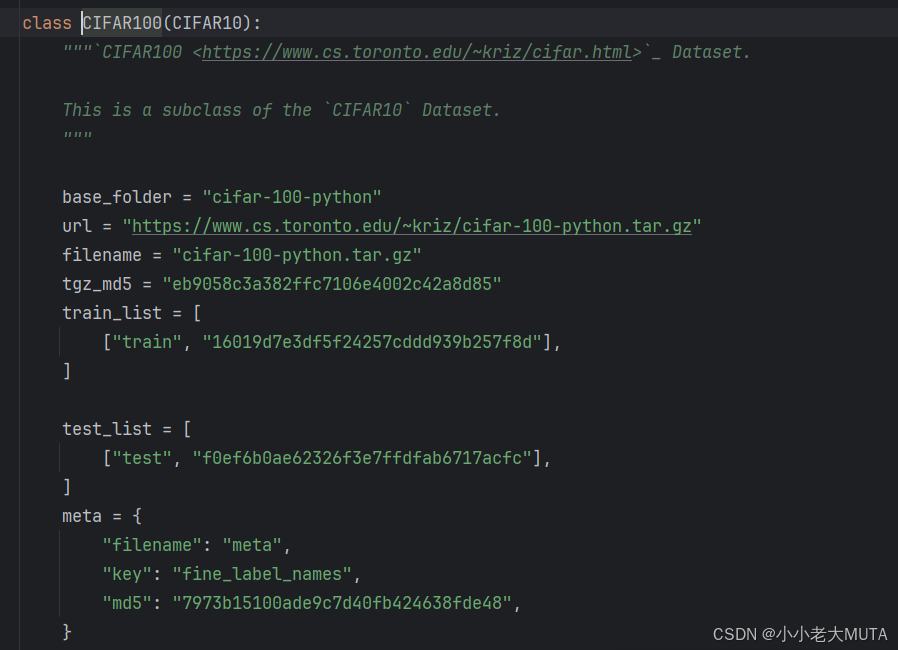
CIFAT100数据集的打包方式
这里使用的CIFAR的数据集:

dataset都被封装好了, 继承的CIFAR10的类。
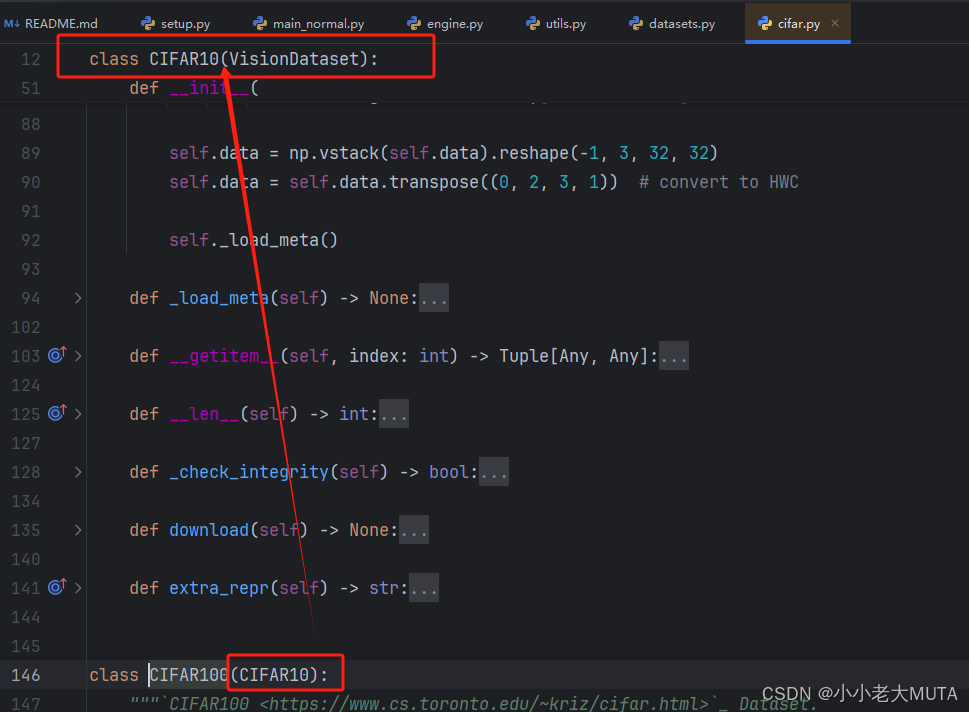
CIFAR10的数据集打包方式如下,继承的VisionDataset类:
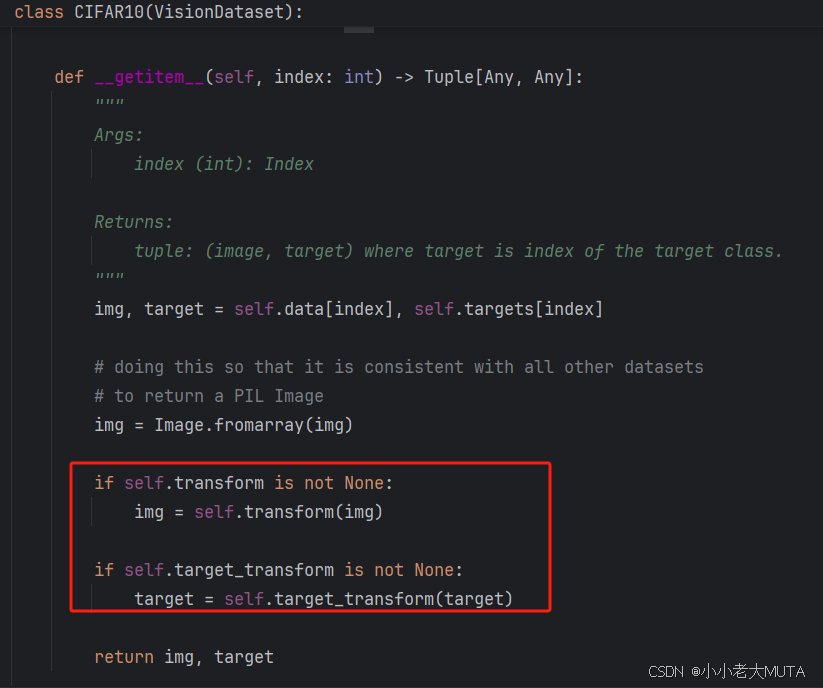
数据打包的dataset执行的是getitem这个函数,在这个函数中图像和标注信息一般需要执行transform即数据增强操作,生成理想的输入:

自己的数据集打包要求
图片尺寸缩放到224*224,等比缩放,其余部分填充。标注框同等缩放。
不使用数据增强操作。
target包含类别信息classification_id、标注框信息bbox。
dataset设计
'''创建适用于目标检测的数据集,bbox为中心点+wh'''
import os
from typing import Any, Callable, List, Optional, Tuple
import torchvision
from PIL import Image
from pycocotools.coco import COCO
from tenacity import retry_all
from torchvision.datasets.vision import VisionDataset
from pathlib import Path
import torch
import numpy as np
from torchvision import transforms
'''单模态目标检测数据集,输出bbox为中心点+wh'''
class cocodataset_center():
def __init__(self,root,input_shape,normalize=None,mode='train'):
"""
初始化多模态 COCO 数据集。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2140
2140

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











