




推荐视频:
什么是 L1 L2 正规化 正则化 Regularization (深度学习 deep learning)_哔哩哔哩_bilibili
如何解决过拟合问题?L1、L2正则化及Dropout正则化讲解_哔哩哔哩_bilibili
过拟合
什么是过拟合?
过拟合是指模型在训练数据上表现良好(损失小,准确率高),但在新数据上表现很差的现象。
如何判断过拟合?
(1) 训练准确率高,测试阶段准确率明显变低;
(2) 训练损失持续下降,但是验证损失先将后升;
如何解决过拟合?
(1) 数据层面:增加数据量,减少对训练集噪声的记忆;数据增强,例如图像翻转、缩放、加噪等;
(2) 模型层面:减少模型参数,降低模型复杂度;
(3) 训练层面:调整训练策略,减少训练轮次,早停等手段;
(4) 正则化: L1,L2,Dropout等方法
L1,L2正则化
什么是正则化?
正则化(Regularization)是在损失函数中加入对模型参数的约束项,目的是让模型参数不过大、防止模型过度学习训练集的细节,从而提升对新数据的预测能力。
以线性回归为例,普通损失函数:
L1正则化:在损失函数后面加上所有参数绝对值的和,起到“让参数变小,甚至变为0”的作用。
L1正则化会让很多参数变为0,实现自动特征选择(有利于高维稀疏数据);
也就是说部分参数会变为0,相当于直接去除部分特征。
L2正则化:在损失函数后加上所有参数的平方和,起到“让参数变小,但不为0”的作用。
- 其中,λ 是正则化系数,控制正则化项权重,w是参数。
L2会参数收缩,把参数压缩接近0,但一般不会变成0。
正则化后参数普遍较小,但不会直接为0,保留了所有特征。
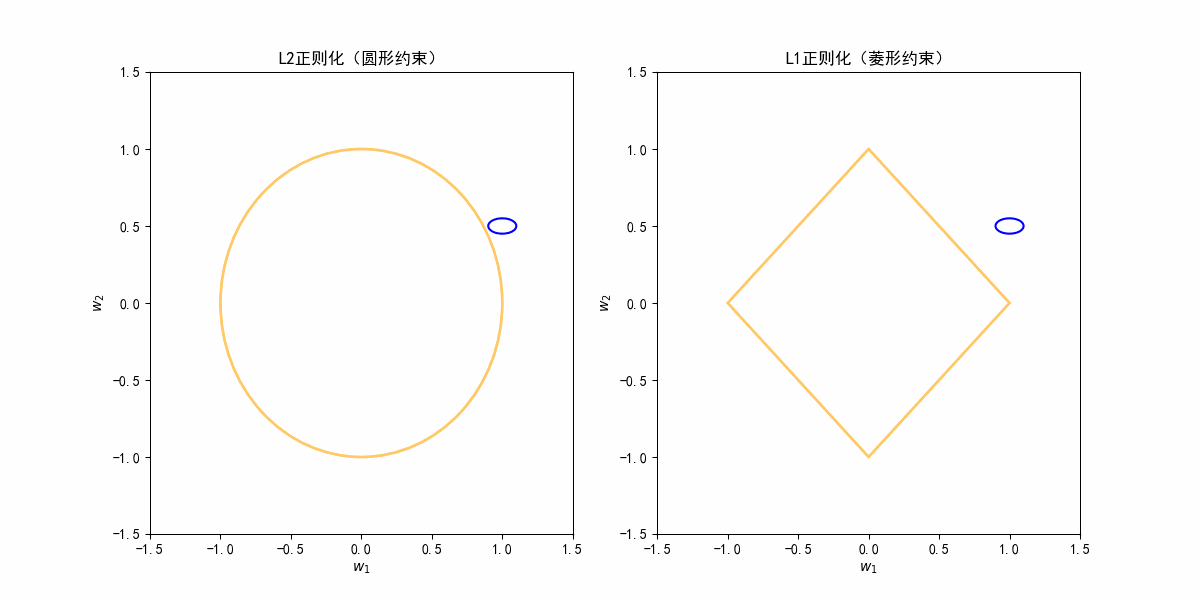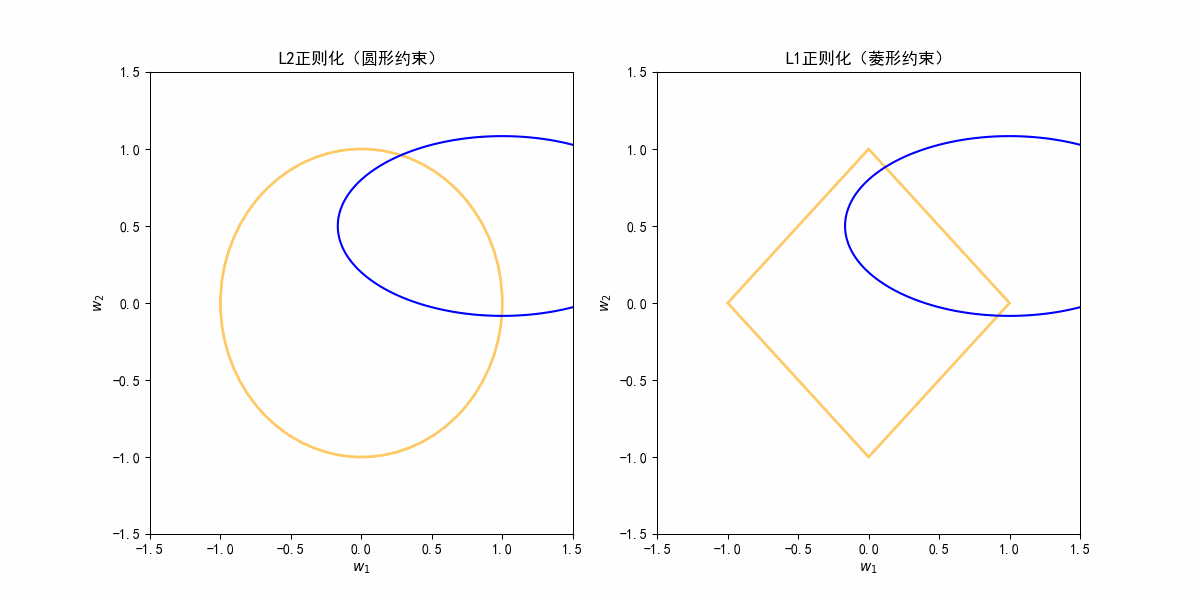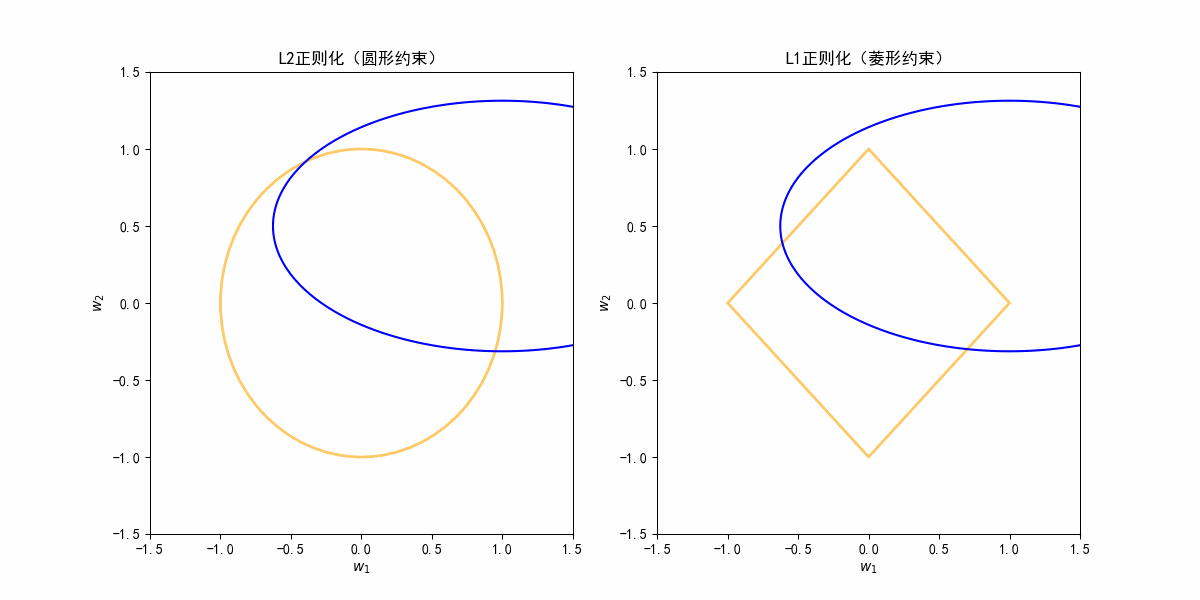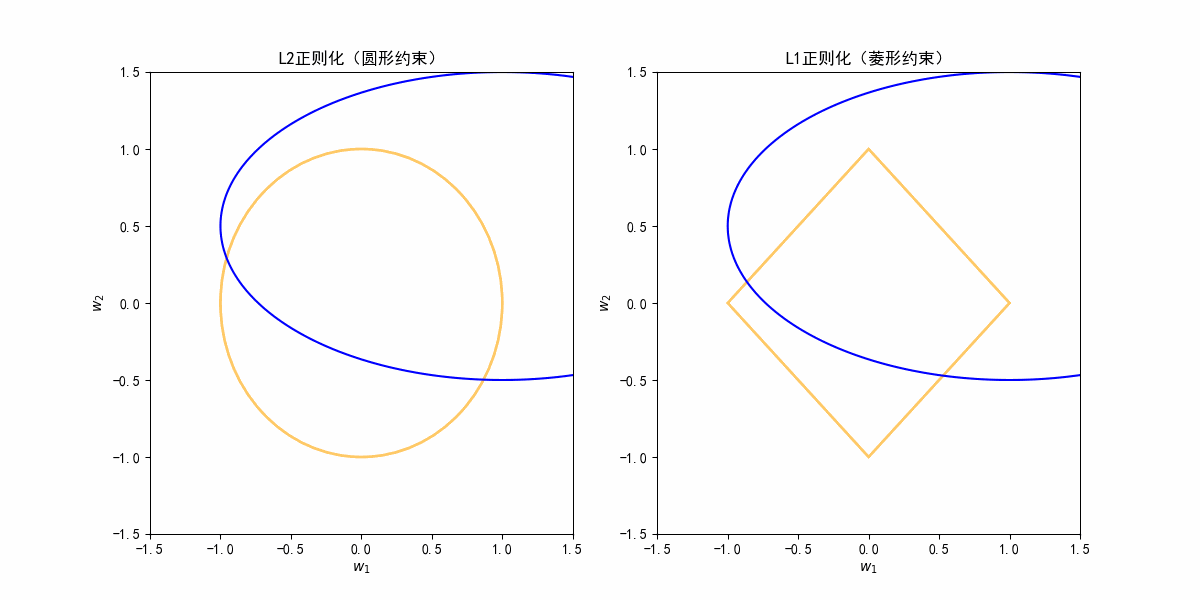
正则化可视化
蓝色等高线为损失函数J(w),正则化的作用是让最终参数点既要尽量靠近损失函数最优点,又不能超出正则化约束区域。
目标是在约束区域内,找到使损失函数最小的点。
从损失函数的极小点出发,画等高线,等高线不断扩大,直到第一次碰到约束边界,这个交点就是正则化下的最优解。
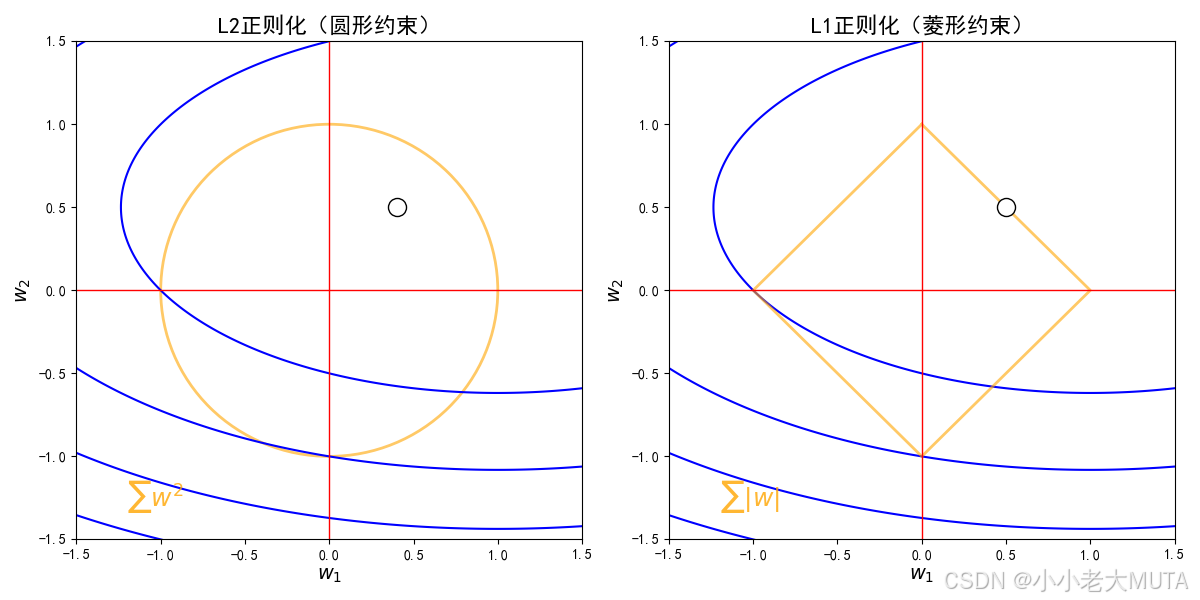
-
横轴为参数 w1,纵轴为参数 w2。
-
蓝色椭圆等高线代表“损失函数”J(θ)的等值线,也就是一组w1,w2损失值一样的点。
-
橙色圆形/菱形分别是L2和L1正则化的“约束边界”:
L2:,边界为圆。
L1:,边界为菱形。
-
白色圆点为最优点(损失函数最小且满足正则化约束)。
-
L1的边界拐角容易与坐标轴重合,导致稀疏解(某些参数为0)。
从图像理解L2是收缩,L1产生稀疏:
根据上面动图,其实蓝色等高线可能存在各种方向,这个是不定的。
在各种情况下的等高线扩大,因为L1是菱形,其实和蓝色等高线首次相交的地方更可能是边界的角点(在坐标轴上);
L2是个圆,等高线碰到圆边界通常是某个斜的方向,w1和w2都不为0,只是都被约束得更小了。
Dropout正则化
dropout是一种在神经网络训练过程中的“随机失活”技术。
核心思想:在每一次训练前向传播时,随机“丢弃”一部分神经元(即让它们输出0、不参与本次计算),而不是每次都用全部神经元。
通过随机失活的方式,使得模型不会过多依赖某个“强特征”或“偶然相关的信息”--->让模型更加稳健、泛化能力更强,减少过拟合
一般不用于输入层、卷积层、小模型、小数据。
L1,L2,Dropout区别与关联
| 正则方法 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
| L1 | 常用于做特征选择(比如logistic/Lasso回归),高维数据优选 | 变量选择,稀疏,易解释 | 有时优化不稳定,稀疏后性能未必最好 |
| L2 | 普遍适用,异常点噪声影响大 | 简单有效,收敛快,理论基础好 | 不会直接产生稀疏性 |
| Dropout | 深度神经网络,尤其全连接层 | 强大抑制过拟合,提升泛化 | 训练慢,不适合小数据(容易欠拟合)、RNN等 |
- Dropout适合深度/宽大网络的“泛化能力提升”,和L1/L2合用可效果更佳。
- L1/L2可以用于CNN参数,Dropout一般用于MLP/全连接层。
import torch.nn as nn
model = nn.Sequential(
nn.Linear(1000, 256),
nn.ReLU(),
nn.Dropout(p=0.5), # Dropout
nn.Linear(256, 10)
)
# L2正则在优化器设置
optimizer = torch.optim.Adam(model.parameters(), weight_decay=1e-5) # L2正则
# L1正则
l1_lambda = 1e-4
l1_loss = sum(p.abs().sum() for p in model.parameters()) * l1_lambda
loss = criterion(outputs, targets) + l1_loss



















 2089
2089

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











