







(1)You are building a 3-class object classification and localization algorithm. the classes are: pedestrian (c=1), car (c=2), motorcycle (c=3). What would be the label for the following image? Recall
y
=
[
p
c
,
b
x
,
b
y
,
b
h
,
b
w
,
c
1
,
c
2
,
c
3
]
y=[p_c,b_x,b_y,b_h,b_w,c_1,c_2,c_3]
y=[pc,bx,by,bh,bw,c1,c2,c3]

[A]
y
=
[
1
,
0.3
,
0.7
,
0.3
,
0.3
,
0
,
1
,
0
]
y=[1,0.3,0.7,0.3,0.3,0,1,0]
y=[1,0.3,0.7,0.3,0.3,0,1,0]
[B]
y
=
[
1
,
0.7
,
0.5
,
0.3
,
0.3
,
0
,
1
,
0
]
y=[1,0.7,0.5,0.3,0.3,0,1,0]
y=[1,0.7,0.5,0.3,0.3,0,1,0]
[C]
y
=
[
1
,
0.3
,
0.7
,
0.5
,
0.5
,
0
,
1
,
0
]
y=[1,0.3,0.7,0.5,0.5,0,1,0]
y=[1,0.3,0.7,0.5,0.5,0,1,0]
[D]
y
=
[
1
,
0.3
,
0.7
,
0.5
,
0.5
,
1
,
0
,
0
]
y=[1,0.3,0.7,0.5,0.5,1,0,0]
y=[1,0.3,0.7,0.5,0.5,1,0,0]
[E]
y
=
[
0
,
0.2
,
0.4
,
0.5
,
0.5
,
0
,
1
,
0
]
y=[0,0.2,0.4,0.5,0.5,0,1,0]
y=[0,0.2,0.4,0.5,0.5,0,1,0]
答案:A
解析:E选项
p
c
=
0
p_c=0
pc=0表示没有检测到物体,错误。
D选项
c
1
=
1
c_1=1
c1=1表示检测到行人,错误。
图片中汽车在左半边,显然
b
x
<
0.5
b_x<0.5
bx<0.5,故B错
边界框的高度宽度为图片高度宽度0.3比0.5更合适更精确,所以选A不选C。
(2)Continuing from the previous problem, what should y be for the image below? Remember that “?” means “don’t care”, which means that the neural network loss function won’t care what the neural network gives for that component of the output. As before,
y
=
[
p
c
,
b
x
,
b
y
,
b
h
,
b
w
,
c
1
,
c
2
,
c
3
]
y=[p_c,b_x,b_y,b_h,b_w,c_1,c_2,c_3]
y=[pc,bx,by,bh,bw,c1,c2,c3]

[A]
y
=
[
0
,
?
,
?
,
?
,
?
,
?
,
?
,
?
]
y=[0,?,?,?,?,?,?,?]
y=[0,?,?,?,?,?,?,?]
[B]
y
=
[
1
,
?
,
?
,
?
,
?
,
0
,
0
,
0
]
y=[1,?,?,?,?,0,0,0]
y=[1,?,?,?,?,0,0,0]
[C]
y
=
[
0
,
?
,
?
,
?
,
?
,
0
,
0
,
0
]
y=[0,?,?,?,?,0,0,0]
y=[0,?,?,?,?,0,0,0]
[D]
y
=
[
?
,
?
,
?
,
?
,
?
,
?
,
?
,
?
]
y=[?,?,?,?,?,?,?,?]
y=[?,?,?,?,?,?,?,?]
[E]
y
=
[
1
,
?
,
?
,
?
,
?
,
?
,
?
,
?
]
y=[1,?,?,?,?,?,?,?]
y=[1,?,?,?,?,?,?,?]
答案:A
解析:当没有检测到物体时,后续的参数都不关心。
(3)You are working on a factory automation task. You system will see a can of soft-drink coming down a conveyor belt, and you want it to take a picture and decide whether (i) there is a soft-drink can in the image, and if so (ii) its bounding box. Since the soft-drink can is round, the bounding box is always square, and the soft drink can always appears as the same size in the image. There is at most one soft drink can in each image. Here’re some typical images in your training set:

What is the most appropriate set of output units for your neural network?
[A]Logistic unit (for classifying if there is a soft-drink can in the image)
[B]Logistic unit,
b
x
b_x
bx and
b
y
b_y
by
[C]Logistic unit,
b
x
b_x
bx,
b
y
b_y
by,
b
h
b_h
bh (since
b
w
=
b
h
b_w=b_h
bw=bh)
[D]Logistic unit,
b
x
b_x
bx,
b
y
b_y
by,
b
h
b_h
bh,
b
w
b_w
bw
答案:B
解析:
b
x
b_x
bx,
b
y
b_y
by用于确定饮料罐的位置,由于题目the soft drink can always appears as the same size in the image(饮料罐在图像中出现的大小相同),所以不需要
b
h
b_h
bh,
b
w
b_w
bw。
(4)If you build a neural network that inputs a picture of a person’s face and outputs
N
N
N landmarks on the face (assume the input image always contains exactly one face), how many output units will the network have?
[A]
N
N
N
[B]
2
N
2N
2N
[C]
3
N
3N
3N
[D]
N
2
N^2
N2
答案:B
解析:每一组特征点都由(x,y)坐标组成。
(5)When training one of the object detection systems described in lecture, you need a training set that contains many pictures of the object(s) you wish to detect. However, bounding boxes do not need to be provided in the training set, since the algorithm can learn to detect the objects by itself.
[A]True
[B]False
答案:B
解析:边界框需要在训练集中提供,不然无法计算损失函数。
(6)Suppose you are applying a sliding windows classifier (non-convolutional implementation). Increasing the stride would tend to increase accuracy, but decrease computational cost.
[A]True
[B]False
答案:B
解析:增大步长会减小精确度,提升计算速度。
(7)In the YOLO algorithm, at training time, only one cell --the one containing the center/midpoint of an object --is responsible for detecting this object.
[A] True
[B] False
答案:A
解析:YOLO算法的做法是取对象的中心点,然后将这个对象分配给包含对象中心点的格子。
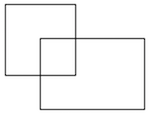
(8)What is the IoU between these two boxes? The upper-left box is 2x2, and the lower-right box is 2x3. The overlapping region is 1x1.
[A] 1/6
[B] 1/9
[C] 1/10
[D] None of the above.
答案:B
解析:
s
i
z
e
o
f
i
n
t
e
r
s
e
c
t
i
o
n
=
1
×
1
=
1
size\ of\ intersection=1\times1=1
size of intersection=1×1=1
s
i
z
e
o
f
u
n
i
o
n
=
2
×
2
+
2
×
3
−
1
×
1
=
9
size\ of\ union=2\times2+2\times3-1\times1=9
size of union=2×2+2×3−1×1=9
I
o
U
=
s
i
z
e
o
f
i
n
t
e
r
s
e
c
t
i
o
n
s
i
z
e
o
f
u
n
i
o
n
=
1
9
IoU=\frac{size\ of\ intersection}{size\ of\ union}=\frac{1}{9}
IoU=size of unionsize of intersection=91
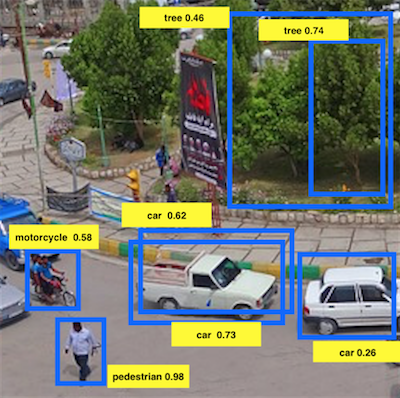
(9)Suppose you run non-max suppression on the predicted boxes above. The parameters you use for non-max suppression are that boxes with probability ≤ 0.4 are discarded, and the IoU threshold for deciding it two boxes overlap is 0.5. How many boxes will remain after non-max suppression?
[A] 3
[B] 4
[C] 5
[D] 6
[E] 7
答案:C
解析:

概率都大于0.4并且显然IoU小于0.5,所以这两个框都会保留。

显然,该框保留。

显然,该框保留。

概率都大于0.4但是两个框的IoU大于0.5,根据non-max suppression 保留概率为0.73的框。

概率小于0.4,丢弃。
所以总共有5个框。
(10)Suppose you are using YOLO on a 19x19 grid, on a detection problem with 20 classes, and with 5 anchor boxes. During training, for each image you will need to construct an output volume y as the target value for the neural network; this corresponds to the last layer of the neural network. (y may include some “?”, or “don’t cares”). What is the dimesion of theis output volume?
[A] 19x19x(20x25)
[B] 19x19x(5x25)
[C] 19x19x(25x20)
[D] 19x19x(5x20)
答案:B
解析:单个anchor box对应的y的输出为
[
p
c
,
b
x
,
b
y
,
b
h
,
b
w
,
c
1
,
c
2
,
⋯
,
c
20
]
[p_c,b_x,b_y,b_h,b_w,c_1,c_2,\cdots,c_{20}]
[pc,bx,by,bh,bw,c1,c2,⋯,c20]维度为25,又因为有5个anchor boxex,所以选B。














 1400
1400











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









