







 本文探讨了最新大型语言模型在社交媒体机器人检测中的应用,提出了一种混合异质专家框架,展示了LLMs在检测中的优势,同时揭示了利用LLMs进行规避检测的风险。实验结果显示,LLMs能显著提高检测性能,但也可能导致检测系统的鲁棒性降低。
本文探讨了最新大型语言模型在社交媒体机器人检测中的应用,提出了一种混合异质专家框架,展示了LLMs在检测中的优势,同时揭示了利用LLMs进行规避检测的风险。实验结果显示,LLMs能显著提高检测性能,但也可能导致检测系统的鲁棒性降低。
主要观点
社交媒体机器人检测一直是机器学习机器人检测器不断进步与对抗性机器人策略相互竞争的一场持久战。在这项工作中,我们通过调查最新的大型语言模型(LLMs)在社交媒体机器人检测中的机会和风险,将这场竞争推向了新的高度。为了探索机会,我们设计了基于新颖LLM的机器人检测器,提出了一个混合异质专家的框架,来分割和征服多样化的用户信息模态。为了阐明风险,我们探索了利用LLM引导的用户文本和结构化信息操纵来规避检测的可能性。
本文在三个数据集上进行LLM的广泛实验,其在两个数据集上的性能比最先进的基准线提高了高达9.1%,而LLM引导的操纵策略则可以将现有机器人检测器的性能显著降低高达29.6%。
本文的主要关注点在大型语言模型在社交机器人检测中有哪些机会和风险?随着竞争的升级,我们重点关注最先进的大型语言模型如何能够帮助强大的机器人检测系统,并且LLMs可能被恶意利用来设计更具规避性的机器人。
提出的主要解决方法
针对机会(社交媒体机器人检测):本文提出了一个混合异质专家的框架,利用LLMs来划分和征服各种用户信息模态,例如元数据、文本和用户互动网络。对于用户元数据,本文将分类和数值用户特征用自然语言序列化,并采用上下文学习进行机器人检测。对于用户生成的文本,我们从带有注释的训练集中检索相似的帖子作为上下文学习的示例。对于网络信息,受之前关于LLMs图推理能力的研究的启发我们将用户的关注信息以随机或基于相似度的顺序作为提示上下文的一部分,以帮助检测。然后,这些特定模态的LLMs通过上下文学习提示或指令调整来使用,并通过多数投票来集成特定模态的结果。
针对风险(通过LLM来对社交媒体机器人进行改进以避免社交媒体机器人的检测):本文调查了LLM引导的机器人设计可能性,以规避检测,方法是篡改机器人账户的文本和结构信息。对于文本信息,我们探索了利用LLMs重写用户帖子以使其看起来真实的四种机制:1)零样本提示;2)少样本重写,模仿真实用户的帖子;3)LLMs与外部机器人分类器之间的交互式重写;4)合成机器人和人类相关帖子的属性,进行风格转换。对于结构信息,我们利用LLMs建议新用户关注或现有用户取消关注,编辑机器人账户的邻域。然后,LLM引导的文本和结构特征操纵被合并以产生LLM引导的社交媒体机器人。
其中一些数据的定义:
元数据(Metadata):元数据是描述数据的数据。例如,对于用户来说,元数据可以包括用户名、注册日期、地理位置、个人简介等信息。对于帖子来说,元数据可以包括发布时间、地理位置、点赞数、转发数等信息。
文本:是指书面语言中的文字内容。在社交媒体中,文本通常是用户发表的帖子、评论、消息等内容。
用户交互网络:描述了用户之间的相互作用和连接关系。在社交媒体中,用户交互网络通常以图形的形式表示,其中节点代表用户,边代表用户之间的关系(如关注、点赞、评论等)。
具体方法
具体方法–机会(社交媒体机器人)
社交媒体机器人检测可以总结为:用户元数据M = {m1, . . . , mk},其中每个mi都是数值或分类特征;用户帖子T = {t1, . . . , tℓ},其中每个ti是一个自然语言序列;用户网络信息N = {N1, N2},其中N1表示用户的粉丝集合,N2表示用户的关注集合。机器人检测器f(M, T , N ) → {人类, 机器人}。
本文提出通过提出混合异质专家框架(mixture-of-heterogeneous-experts )来开发基于LLMs的机器人检测器。具体而言,不同的用户信息模态分别使用LLMs进行分析,而多数投票则用于集成单一模态的预测。每个特定模态的预测器要么使用即插即用的LLM进行上下文学习,要么采用指令调整来使LLM适应于分析特定的用户信息集合。
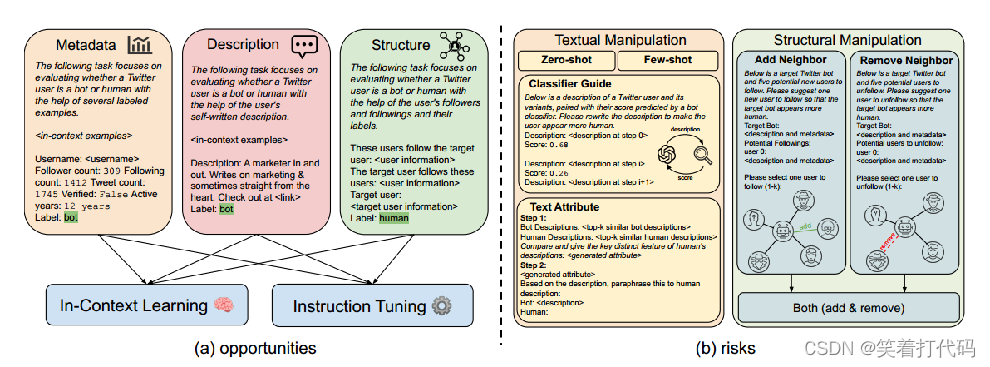
元数据:按顺序连接帐户的元数据M,将其线性化为自然语言序列,随机选择n个上下文示例的平衡集(机器人和人类平衡),并在提示符中提供它们的元数据以及标签,用于上下文学习。
文本:对于文本序列t ∈ T,首先使用检索系统(Robertson等人,2009)从训练集中检索出与之相似度最高的前n个用户帖子。然后,同样使用LLMs进行上下文学习,对T中的所有帖子进行预测,并进行多数投票。还可以采用元数据+文本的方法,在上下文学习中同时提供用户元数据和文本帖子给LLMs进行处理。
网络结构:这些用户关注目标用户:PERM(N1)。目标用户关注这些用户:PERM(N2),其中PERM(·)表示关于如何对关注/被关注集合进行排序和排列的排列函数。我们对PERM采用两种模式:1)随机,其中用户以及他们的信息按随机顺序线性化;2)注意力:受图注意力网络的成功启发以及网络中边的重要性变化,我们根据它们与目标账户的相似度对用户进行排列。形式上,给定目标用户的帖子t,邻近用户的相似度得分可以定义为sim(enc(t),enc(t′)),其中sim(·,·)表示余弦相似度,enc(·)表示基于编码器的LM,t′表示邻近账户的帖子。然后,PERM根据它们的相似度得分从高到低排列用户,并附上提示“从最相关到最不相关:”以鼓励LLMs考虑邻居的相对相似度/重要性。
至此,以及开发了专注于分析不同用户信息模态**(元数据、文本、元数据+文本、结构-随机和结构-注意力)**的五个LLM预测器,这些预测器通过上下文学习或指令调整来使用。
具体方法–风险(回避社交媒体机器人检测)
尽管用户元数据M通常很难通过LLMs进行操纵(例如,关注者数量和账户创建时间),但文本信息T和结构信息N可以很容易地通过LLM生成的帖子改写和LLM建议的用户来进行更改。我们首先探讨了操纵文本信息T的可能性,重点关注使用LLMs重新编写机器人账户的帖子以逃避检测。
zero-shot重写:我们直接使用以下提示向LLM提供输入:“请将这个机器人账户的描述重写成听起来像真实用户的样子。”
few-shot重写:我们使用检索系统获取与目标帖子最相似的前n个由真实用户撰写的帖子。然后,我们提示LLM模仿这些示例,并重写目标机器人的帖子。
分类器引导:我们提议让LLMs通过来自外部分类器的反馈来迭代地改进机器人生成的帖子。具体而言,我们首先训练一个基于编码器的LM来将用户帖子分类为机器人或人类,并产生一个置信度分数f(t) → [0, 1]。在每一步中,LLM从先前步骤中重写的帖子以及给出的这些帖子的置信度分数中学习,旨在减少外部分类器中机器人的可能性。
文本属性:我们首先从人类账户中检索出与目标帖子最相似的前n个帖子以及从机器人账户中检索出的前n个帖子,然后提示LLM总结这两组帖子之间的文本属性差异。在另一个提示中,LLM使用总结的差异来重写目标机器人帖子。我们还利用了LLMs的初步图推理能力,并利用它们来编辑结构化信息,具体来说是通过添加和移除关注对象的用户。
对邻居(关注与被关注的列表)的操作:通过LLMs来获得添加,删除操作邻居。
选择性结合:我们利用LLMs来判断在给定的机器人中,哪种信息模态,文本或图形,可能是恶意的,并采用相应的操纵策略。
模型设置
模型设置:使用了三种LLMs,Mistral-7B、LLaMA2-70b和ChatGPT。
实验设置:于上下文学习,我们默认采用16个上下文示例。对于指令调整,我们从训练集中随机抽样1,000个示例以适应LLMs。我们默认将温度τ设置为0.1以进行语言生成。具体提示示例如下(不是很看得懂):
数据集设置:我们使用了两个社交机器人检测的全面基准数据集:TwiBot-20和TwiBot-22,这两个基于图的数据集提供了社交媒体上多样化的用户和机器人互动。
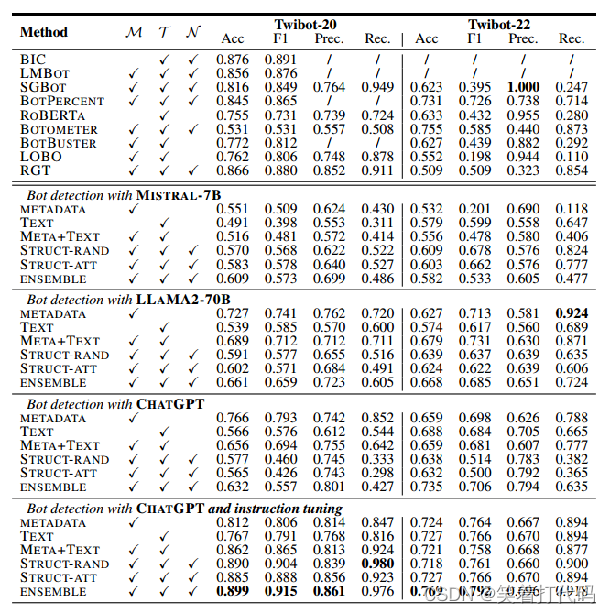
基线设置:在机会方面,我们将我们提出的基于LLMs的机器人检测器与利用用户信息的不同方面的9个基线进行比较:SGBot、LOBO、RoBERTa、RGT、Botometer、BotBuster、BotPercent、BIC和LMBot。

实验结果
实验结果–机会(社交媒体机器人检测)
性能提升:ChatGPT集成模型,在经过指令调整后,在两个数据集上的F1分数都超过了现有最强的基线模型,分别提高了2.6%和9.1%。而且,指令调整后的ChatGPT在准确性上比上下文学习提高了34.7%。
大型模型的优势:更大的LLM在社交机器人检测任务上具有更好的表现。Mistral-7B、LLaMA2-70B和ChatGPT在两个数据集上的平均准确率分别为0.5651、0.6347和0.6478,且这种性能排名与它们在标准自然语言处理基准上的通用效用相符。
模态特定集成:对于经过指令调整的ChatGPT而言,尽管仅使用文本的检测器性能稍逊,但通过多数投票集成不同模态的预测能够提高性能。
数据注释与计算成本的权衡:现有的轻量级监督学习方法虽然运行成本低,但需要大量的数据注释(两个数据集分别有约8千和70万个注释账户)。而基于LLM的方法,尽管计算成本高,但仅需在1千个注释用户上进行指令调整就能实现更优的性能。这表明,随着在高效训练和推理方面的技术创新,基于LLM的方法是一种有前途的社交机器人检测手段,尤其在获取注释数据困难的情况下。
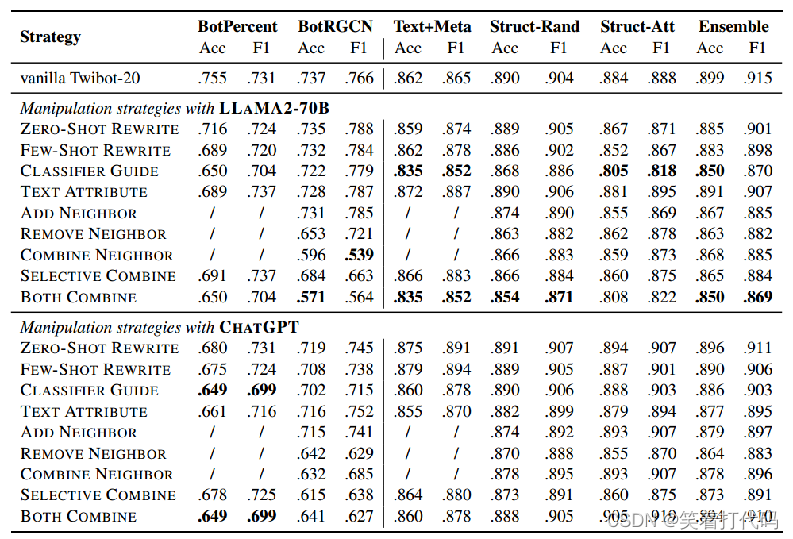
实验结果–风险(回避社交媒体机器人检测)
抵抗操纵的能力:与其他模型(如BotPercent和BotRGCN)相比,基于LLM的检测器对操纵策略的敏感度较低。当面对操纵策略时,LLM集成平均仅有2.3%的准确率下降,而BotPercent和BotRGCN的性能下降更显著(分别为10.9%和7.7%的准确率下降)。
基于ChatGPT的检测器对于由不同LLM(LLaMA2-70B)提出的编辑内容的鲁棒性较差。
分类器引导:'分类器引导’被发现是最有效的,导致平均6.0%的准确率和3.2%的F1分数下降。这可能表明LLM有潜力根据外部分类器的反馈迭代地完善其输出,这对于提升机器人检测技术可能是一个有价值的特性。
社交网络操纵策略:在操纵社交网络结构方面,移除邻居比添加新的邻居更有效。平均准确率分别为移除操作5.0%的下降和添加操作2.5%的下降。
关注一个新账户是一个更复杂和嘈杂的任务,而识别和移除有助于账户看起来像机器人的现有连接则更直接和有效。策略性的关注用户看起来是一个更加值得深究的课题。
实验结果
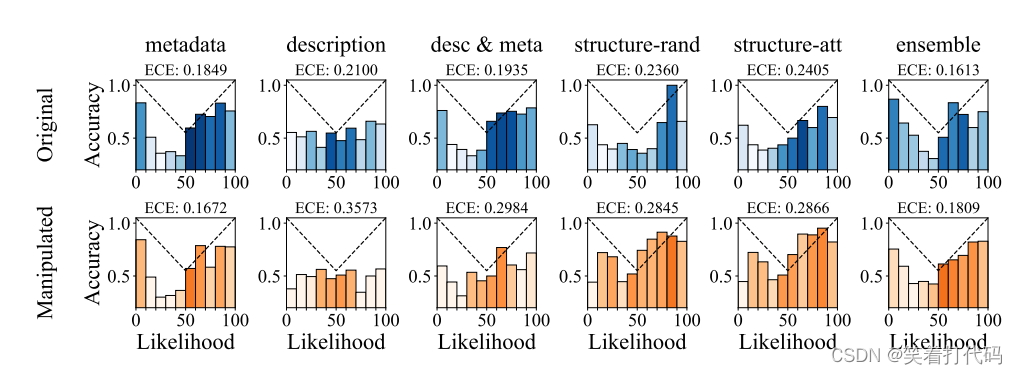
ECE分析
鲁棒的社交机器人检测器应该不仅提供二元预测(即判断为“人类”或“机器人”),还应提供一个校准良好的置信度分数,以便于内容审查。本文评估了基于LLM的机器人检测器的校准情况,使用了Twibot-20数据集以及经过“BOTH COMBINE”策略操纵过的数据集。根据下图,使用经过指令调整的ChatGPT模型预测标记(“人类”或“机器人”)的概率作为机器人的可能性,将其分到10个桶中,并计算估计的校准误差(ECE)。结果表明,基于LLM的机器人检测器校准程度适中,ECE约为0.2,而LLM引导的操纵策略损害了校准并使ECE平均增加了28.4%。因此,LLM在社交机器人检测中的风险不仅在于性能下降,还在于校准度较低,因而预测的可信度较低。
文本重写相似度
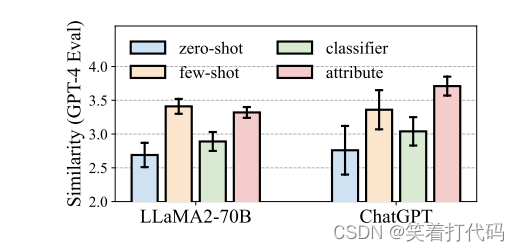
为了规避检测,如果LLM去除机器人生成帖子中所有的恶意内容或意图将是最有效的;然而,这会违背LLM引导下的机器人设计的初衷。本文采用GPT-4来评估LLM改写后的机器人帖子是否仍“保留”了潜在的恶意内容。
具体地,我们向GPT-4提出了这样一个问题:“对于以下两个社交媒体用户的帖子,它们在内容上有多相似?”并请求按照从“1:非常不同”到“4:非常相似”的4点量表来响应。如右图所示,LLM通常能够保留机器人帖子的内容,而文本属性策略是最忠实(faithful)的。
忠实:原有恶意意图不改变,但是通过一些手段可以避免检测。
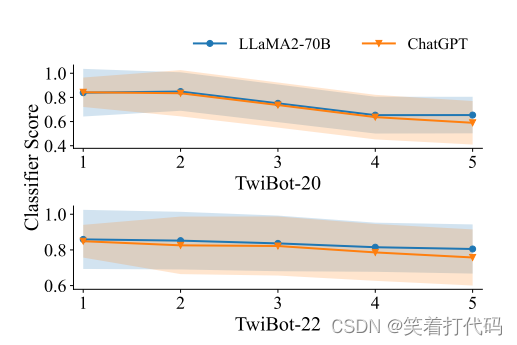
分类器引导收敛
这张图表显示了两个不同的大型语言模型,LLaMA2-70B和ChatGPT,在Twibot-20和Twibot-22数据集上通过迭代过程后,外部分类器分配的机器人概率评分的变化趋势。x轴代表迭代次数,y轴代表分类器评分,分类器评分越高,意味着分类器更有信心认为帐户是机器人。
从图中可以看出,在经过五次迭代之后,两个数据集上ChatGPT的评分都比LLaMA2-70B的要低,说明ChatGPT在这两个数据集上的表现更好,即它在减少被分类器识别为机器人的概率上更为有效。此外,两个模型的评分都随着迭代次数的增加而有所下降,这表明经过多次迭代后,这些模型生成的文本更不容易被分类器识别为机器人生成的,显示了LLM在迭代过程中对文本进行微调,使其更加类似于人类用户生成的内容的能力。
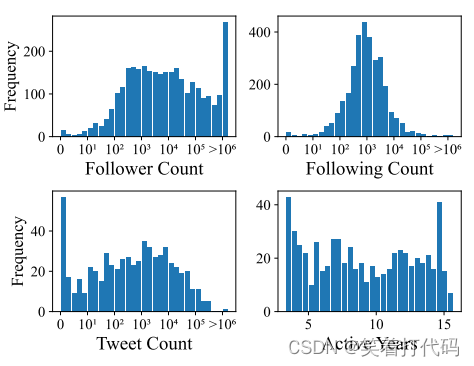
添加/移除邻居统计信息
粉丝数:第一个图展示了被选中账户的粉丝数量分布。大多数账户似乎有介于101到103之间的粉丝数量,而较少的账户拥有超过10^4个粉丝。
关注数:第二个图显示了这些账户的关注数量分布。关注数分布似乎相对均匀,中间的峰值表明有大量账户关注数量在102到103之间。
推文数:第三个图描绘了账户的推文数量分布。这显示了多数账户有一定数量的推文,通常在101到103之间,暗示了这些账户在平台上有一定的活动水平。
活跃年数:最后一个图表展示了账户的活跃年数。许多账户在平台上活跃了5到10年,表明LLM可能更偏向于选择那些有一定历史的账户。
这些分布表明LLM在决定哪些账户从机器人的关注列表中添加或移除时,采取了考虑多个不同账户特征的方法。这不是随机选择,而是基于各种社交指标的综合评估。此外,这些图表还暗示LLM可能在考虑操纵策略时,不仅仅看账户的一两个特性,而是同时考虑了一个账户在社交网络中的多个维度,如其受欢迎程度、活跃性、以及在社交平台上的历史。通过这样的多维度考量,LLM能够制定更复杂的操纵策略,提高机器人账户规避检测的概率。
文本重写相似度
右图显示了基于LLM的机器人检测器在Twibot-20数据集上的表现,随着上下文示例的数量从0增加到16,模型的性能(准确度和F1分数)都稳步提升。这说明更多的上下文示例有助于LLM更准确地识别机器人行为。
然而,LLM通常有上下文长度的限制,这意味着无法无限增加上下文示例的数量。因此,尽管增加上下文示例的数量可以提高性能,但这种提升是有上限的。
图中的几条曲线代表不同的特征组合和训练方法:
metadata-IT 可能代表仅使用元数据进行指令调整(Instruction Tuning)。
text-IT 指仅使用文本进行指令调整。
text+meta-IT 表示同时使用文本和元数据进行指令调整。
metadata-ICL 代表使用元数据进行上下文学习(In-Context Learning)。
text-ICL 表示使用文本进行上下文学习。
text+meta-ICL 则表示同时使用文本和元数据进行上下文学习

















 29
29











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











