







 本文探讨了大型语言模型(LLMs)在社交机器人检测中的潜力与风险。通过设计基于LLM的检测器,发现LLMs在利用不同用户信息模式(元数据、文本和用户网络)时具有优势,但也展示了其操纵策略能显著降低现有检测器的性能。实验表明,尽管LLMs增强了检测器,但它们也可能被设计出逃避检测的策略。
本文探讨了大型语言模型(LLMs)在社交机器人检测中的潜力与风险。通过设计基于LLM的检测器,发现LLMs在利用不同用户信息模式(元数据、文本和用户网络)时具有优势,但也展示了其操纵策略能显著降低现有检测器的性能。实验表明,尽管LLMs增强了检测器,但它们也可能被设计出逃避检测的策略。
论文链接:https://arxiv.org/pdf/2402.00371.pdf
1 摘要
动机:
调研最先进的与原模型在社交机器人检测上的机会与危害;
方法:
设计了基于LLM的机器人检测器,通过利用混合异质专家“mixture-of-hetergeneous-experts”架构去划分和征服何种用户模态信息。、
说明LLM对检测的危害:
探索了LLM操作用户文本和结构信息来避免被检测到的概率。
实验:
机会:在1000个注释案例上的指令调整产生专业的LLM应用于检测,其性能便优于最新的方法9.1%。
危害:LLM指导的操纵策略给现有的机器人检测器带来29.6%的性能下降。
2 绪论
目标:
What are the opportunities and risks of large language models in social bot detection?
机会:
mixtureof-heterogeneous-experts 框架: llm划分和征服各种用户信息模式,如元数据、文本和用户交互网络。
用户元数据信息:在自然语言序列中描述分类和数字用户特征,并使用上下文学习进行机器人检测;
用户生成的文本:从带注释的训练集中检索类似的帖子作为上下文学习示例;
网络信息:参考前人关于llm图推理能力的研究,用户的关注信息,以随机或基于相似性的顺序,作为提示上下文的一部分,以帮助检测。
然后通过上下文学习提示或指令调整来使用这些特定于模态的llm,并且通过多数投票来集成特定于模态的结果。
危害:
研究了llm引导的bot设计通过篡改bot帐户的文本和结构信息来逃避检测的可能性。
文本信息:zero-shot prompting; few-shot 改写以模仿真实用户的帖子; llm和外部bot分类器之间的交互重写; 综合机器人和人类相关帖子的属性进行风格转移
结构信息:使用llm建议新用户关注或现有用户取消关注,编辑bot帐户的邻域
文章贡献:
使用3个LLM在2个数据集上进行实验;
虽然上下文学习难以捕捉机器人账户的细微差别,但指令调优成功地产生了强大的机器人检测器,在两个数据集上的性能比基线高出9.1%。
llm引导的对文本和结构信息的操作成功地将现有机器人检测器的性能降低了29.6%,而基于llm的检测器对llm设计的机器人更健壮。
2 方法
2.1 机会:大型语言模型是更好的Bot检测器
针对于用户三个模态信息使用LLM进行检测:
user metadata:
user posts:
user network information: user’s followers’ set 和 the following set.
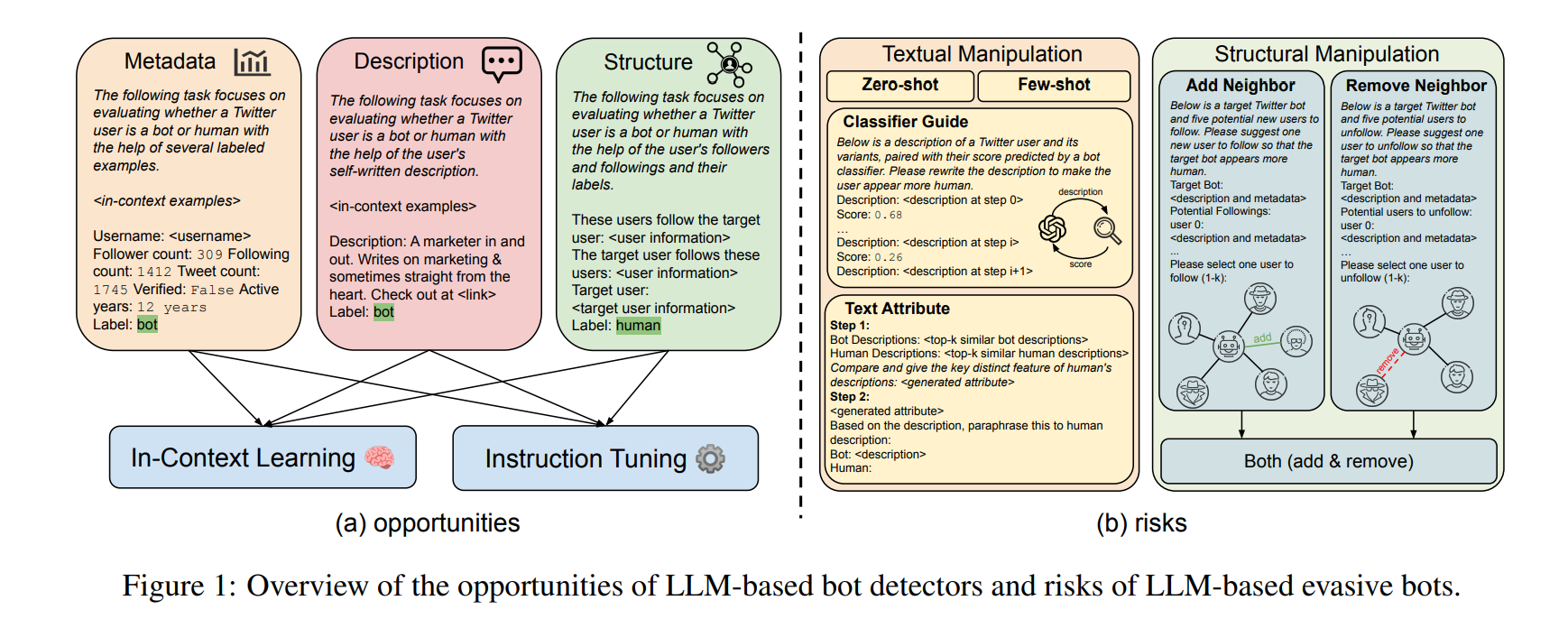
Metadata-Based:
按顺序连接帐户的元数据M,将其线性化为自然语言序列:
之后,随机选择n个上下文示例的平衡集,并在提示符中提供它们的元数据以及标签,用于上下文学习
Text-Based:
对于每个文本序列t∈T,首先使用检索系统检索训练集中top-n个相似的用户帖子;
进行多数投票;
还采用元+文本方法,其中用户元数据和文本帖子都呈现在llm的上下文学习中
Structure-Based:
Prompt: “These users follow the target user: PERM(). The target user follows these users: PERM(
)”
PERM()表示关于如何排序和安排follower/following集合的排列函数。
1)随机,用户及其信息按随机顺序线性化;
2) 根据用户与目标帐户的相似性来安排用户;sim(enc(t), enc(t ′ )), t'表示相邻账号的帖子; 添加Prompt: “from most related to least related:”
五个分析用户信息的LLM预测器:
(metadata, text, metadata+text, structure-random, and structure-attention)
In-Context Learning:
直接使用现成的LLM,无需任何调优或调整,具有n个上下文示例和标签以及目标用户的信息
Instruction Tuning:
微调llm:{instruction, input, output}
2.2 风险:大型语言模型具有规避性机器人设计师
textual information:
Zero-Shot Rewriting: prompt the LLM with “Please rewrite the description of this bot account to sound like a genuine user.”
Few-Shot Rewriting: 首先采用检索系统,检索由真正用户撰写的与目标帖子最相似的n个帖子;之后提示LLM模仿这些示例并重写目标bot帖子。
Classifier Guidance: 首先训练一个基于编码器的LM,将用户帖子分类为机器人或人类,并产生一个置信度分数。之后,在每一步中,LLM利用从前面步骤中获取的重写的帖子以及这些帖子的置信度分数中学习,旨在降低外部分类器眼中的机器人可能性。
Text Attributes: 首先从人类账户中检索top-n相似的帖子,从机器人账户中检索top-n个帖子,然后提示LLM总结两组帖子的文本属性差异。在一个单独的prompt中,LLM在总结的差异的帮助下重写目标bot帖子。
preliminary graph reasoning:
Add Neighbor: 随机选择n个目标机器人目前没有关注的用户。prompt the LLM to “Please suggest one new user to follow so that the target bot appears more human.”
Remove Neighbor:prompt the LLM to “Please suggest one user to unfollow so that the target bot appears more human.”
Combine Neighbor:合并添加邻居和删除邻居的结果。
Selective Combine:使用llm来判断在给定的机器人中哪些信息模式(文本或图形)可能是恶意的,并采用相应的操作策略。首先向LLM提供有关现有机器人探测器如何在前置通道中工作的基本原理。然后给出所有M, T,和N对于给定的bot,提示LLM评估文本、结构或用户信息是否看起来是恶意的;然后有选择地激活分类器引导和组合邻居来编辑bot账号
Both Combine:简单地合并分类器指导的编辑,并结合给定bot帐户的文本和结构特征的邻居
3 Experiment Settings
Models and Settings:
3个LLM:: Mistral-7B, LLaMA2-70b, ChatGPT
in-context learning:默认使用16个上下文示例;
instruction tuning:随机选择1000个样本
Datasets:
TwiBot20;TwiBot-22
Baselines:
9 baselines:SGBot;LOBO;RoBERTa;RGT;Botometer;BotBuster;BotPercent;BIC;LMBot
4 Results
4.1 Opportunities
基于llm的探测器实现了最先进的性能:

带有指令调优的ChatGPT在准确率上比上下文学习高出34.7%;
更大的LMs更擅长社交机器人检测:Mistral-7B, LLaMA2- 70B, and ChatGPT achieve 0.5651, 0.6347, and 0.6478 accuracy on the two datasets.
特定模式llm的组合产生了有希望的结果:
虽然纯文本检测器在性能上落后,llm在利用帐户的结构信息方面更好,但通过多数投票的特定模式预测的集合提高了性能;
4.2 Risks
对Twibot-20进行文本和结构上的操纵:

基于llm的检测器对操纵策略不太敏感:BotPercent和BotRGCN由于操纵策略,准确率平均下降了10.9%和7.7%, LLM-ensemble只下降了2.3%。
在文本操作中,分类器引导是最成功的
移除邻居比添加邻居更好
5 Analysis
Model Calibration(模型校准):
强大的社交机器人检测器不仅应该提供二元预测,还应该提供校准良好的置信度评分,以促进内容审核:
使用来自指令调优的ChatGPT模型的预测令牌(“人类”或“机器人”)的概率作为机器人的可能性,将其分成10个桶,并计算估计的校准误差

ECE表示估计校准误差,越低越好
基于llm的机器人检测器的校准误差在0.2左右,而llm引导的操作策略损害校准平均下降28.4%.
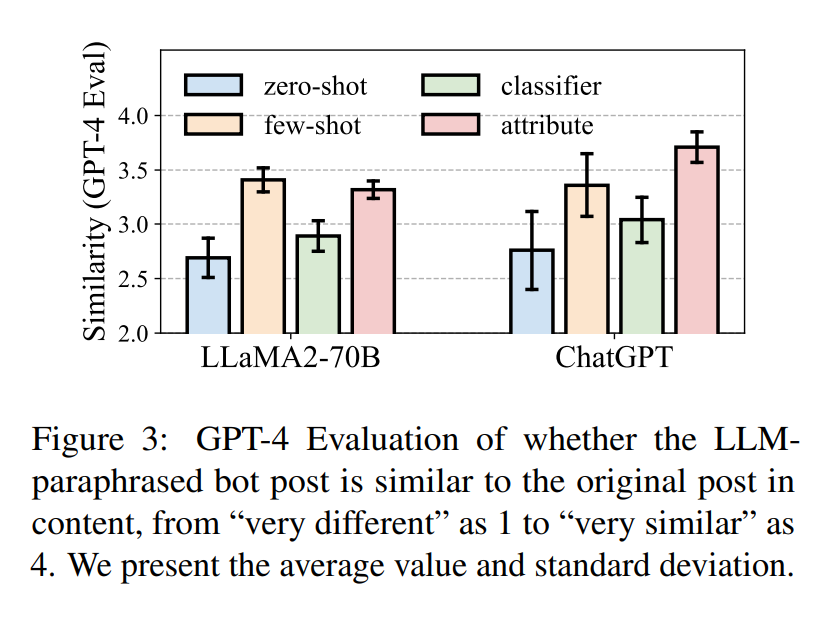
Text Rewrite Similarity:
为了逃避检测,如果LLM删除机器人生成的帖子中的所有恶意内容/意图,将是最有效的:使用GPT-4来评估llm释义的bot帖子是否仍然“保留”潜在的恶意内容
“For the following two posts of social media users, how similar are they in content?” 征求GPT-4的意见:“1: very different” to “4: very similar”















 582
582











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









