







Robotics Dataset chap2
question
-
skills & tasks
task -> [skill1,skill2,…]❎
skill <- a task on object_i(不同任务实例)
-
multi-view how to train
-
force sensor
-
human demo
-
……
1. dataset structure
1.1 openX-embodiment
Each data set is represented as a sequence of episodes, where each episode is represented using the RLDS episode format.
episode_length: the number of steps in a given dataset
The action dimensions we consider include seven variables for the gripper movement (x, y, z, roll, pitch, yaw, opening of the gripper). Each variable represents the absolute value, the delta change to the dimension value or the velocity of the dimension.
-
info
- 527skills.
- 160266tasks.
-
metadata
-
机器人形态
- single arm
- mobile manipulator
-
关节(自由度)
- 7,6
- 3,2,1
-
夹爪
- Default gripper that the robot shipped with
- others
-
动作空间
- Task space (ie EEF末端执行器) position control
- Task space (ie EEF) velocity control
- Joint position control
-
控制器频率
- 10Hz, 15Hz…
-
阻塞式控制or非阻塞式控制
- Blocking control: recorded actions are fully executed during data collection or computed from state deltas post-hoc.
- Non-Blocking control: recorded actions are targets for low-level controller, but not necessarily reached before next action is commanded.
-
⭐第三视角 Number of third-person
RGBcamera streams (i.e. non-wrist, non-ego-centric)- 0,1
- 2,3,4
-
Number of third-person
depthcamera streams (i.e. non-wrist, non-ego-centric)- 0
- 1
- 2,4
-
⭐第一视角 Number of ego-centric RGB camera streams (e.g. mounted to robot body)
- 0,1
-
Number of ego-centric depth camera streams (e.g. mounted to robot body)
-
末端执行器上的 Number of wrist RGB camera streams (i.e. mounted to robot end-effector)
wrist camera

-
Number of wrist depth camera streams (i.e. mounted to robot end-effector)
-
内参矩阵K Does the data contain calibration information for all cameras (intrinsic & extrinsic parameters)?
-
位姿、关节角度 Dataset has proprioceptive information? (e.g. EEF pose or robot joint angles)
-
Type of Language Instruction Annotation (if your data contains a mix, choose the option that represents the largest chunk)
- Natural Language (i.e. annotated by humans using natural language)
- Dummy value (i.e. same value for all trajectories)
- Scripted / templated language (i.e. one of a limited number of values)
-
数据是否同质 Is your data homogeneous? (i.e. all trajectories have the same inputs recorded) Note: your data can be homogeneous even if you have e.g. dummy language labels, as long as all trajectories are using dummy language labels.
-
⭐⭐⭐Data collection method (if your data contains a mix of multiple methods, choose the one that contributed the largest chunk of data)
- Human teleoperation – VR Teleop:
23 - Data from scripted policies (including semi-random policies):
13 - Human teleoperation – Spacemouse Teleop:
6 - Human teleoperation – Joystick:
1 - Data from expert learned policies:
14 - Human teleoperation – Puppeteering (i.e. matching joint angles btw leader & follower robot):
3 - Human teleoperation – Kinesthetic Teaching (i.e. human directly moves robot):
2 - Human teleoperation using Shared Control Templates:
1
- Human teleoperation – VR Teleop:
-
Does the data include sub-optimal trajectories?
- Yes, at least some trajectories are sub-optimal: 23
- No, all trajectories are ~optimal (i.e. I would be happy if a policy just imitated the data): 40
-
⭐What types of scenes are in the dataset? (pick all that apply)
scenes types count ⭐Table Top 50 ⭐Kitchen (also toy kitchen) 19 Other Household environments 5 Hallways 4 Outdoors 1 Indoor, on a flat floor 1 anything within 3 entire office buildings 1 Workshop environment 1 robot alone 1 Household objects 1 -
数据集包含多少个场景?
- 50,25,24,20
- 14*2,10*3,5*3
- 4,3*6,2*7
- 1*33
- difficult to estimate, maybe>1000?(RoboVQA)
- 2-3
- 15scenes, they are visually substantially different because the robot was moving in different gaits/velocities.
- 1scene. Simulated tabletop/floor.
-
数据集简短介绍
dataset name RoboVQA 一个机器人或人类在三栋办公楼内执行用户提出的任何长期请求 BC-Z 机器人试图在桌面上对各种不同的物体进行拾取、擦拭和放置任务,包括一些具有挑战性的任务,如将杯子堆叠在一起 Saytap Unitree Go1机器人按照自然语言中的人类命令执行(例如,“缓慢向前小跑”) USC Cloth Sim 机器人沿着对角线操作桌面上的一个可变形物体(布料) ETH Agent Affordances 机器人打开和关闭烤箱,从不同的初始位置和门角度开始 KAIST Nonprehensile Objects 机器人在桌面环境中执行各种非抓取式的操作任务。它将各种不同的真实世界和3D打印的物体转换和重新定位到目标6自由度位姿 Berkeley Bridge 机器人与家庭环境进行交互,包括厨房、水槽和桌面。技能包括物体重新排列、扫地、堆叠、折叠以及打开/关闭门和抽屉 RoboNet 机器人与放在面前的容器中的物体进行交互 NYU ROT 机器人手臂在桌面上执行各种操作任务,如打开盒子、堆叠杯子、倒水等 RECON 移动机器人使用预先设计的策略探索室外环境 UIUC D3Field 机器人根据目标图像完成指定的任务,包括整理餐具、鞋子和马克杯 RT-1 Robot Action 机器人从Google微型厨房中拾取、放置和移动17个物体 CMU Stretch 机器人与不同的家庭环境进行交互 Berkeley Fanuc Manipulation 一个Fanuc机器人执行各种操作任务。例如,它打开抽屉、拾取物体、关闭门、关闭计算机,并将物体推到所需位置 SACSoN 移动机器人在行人密集的环境中导航(例如办公室、学校建筑等),并运行可能与行人交互的学习策略 cmu_stretch_dataset 机器人与野外设置进行交互,如垃圾桶、厨房、门、柜子等 Berkeley MVP Data 在桌面和玩具环境(玩具厨房、玩具冰箱)上执行基本的电机控制任务(到达、推动、拾取) Tokyo PR2 Tabletop Manipulation PR2机器人对桌面物体进行操作。它执行面包和葡萄的拾取和放置,并折叠布料 Stanford HYDRA 机器人在相应的环境中执行以下任务:使用keurig机器制作一杯咖啡;使用烤箱制作一片吐司;将盘子分类整理到碗架上 NYU VINN 机器人为各种类型的橱柜打开柜门 UCSD Kitchen 该数据集提供了一套全面的真实世界机器人交互数据,涉及自然语言指令和与厨房物品的复杂操作 Roboturk Sawyer机器人把衣服展平,用碗建立塔并寻找物体 CMU Play Fusion 机器人在3个复杂场景中进行游戏:一个带有多个烹饪对象的烧烤架,如烤面包机、平底锅等。它必须拾取、打开、放置、关闭。它必须摆设餐桌,移动盘子、杯子、餐具。并且必须把碗放在水槽、洗碗机、手杯等地方 CMU Franka Pick-Insert Data 机器人试图拾取放在面前的不同形状的物体。它还试图将特定物体插入圆柱形销中 LSMO Dataset 机器人避开桌子上的障碍物,到达目标物体 Austin VIOLA 机器人执行各种类似家务的任务,如摆桌子或使用咖啡机冲咖啡 UTokyo xArm Bimanual 机器人取下桌子上的毛巾。它们还展开了一条皱巾 UCSD Pick Place 机器人在桌面和厨房场景中执行拾取和放置任务。该数据集包含各种视觉变化 DLR Wheelchair Shared Control 机器人在桌面和架子上抓取一组不同的物体 Austin Sirius 该数据集包括两个任务,kcup和gear。kcup任务需要打开kcup支架,将kcup插入支架,然后关闭支架。齿轮任务需要将蓝色齿轮插入正确的销上,然后插入较小的红色齿轮 test_dataset 一个机器人正在做很酷的事情 Columbia PushT Dataset 机器人将一个T形块推到一个固定的目标姿势,然后移动到一个固定的出口区域 CMU Food Manipulation Data 机器人在桌面环境中与许多不同大小和形状的食物进行交互。它抓取、按下和释放食物片。有指尖视觉数据显示食物片在被抓取和释放时被挤压的情况 NYU Franka Play 机器人与玩具厨房进行交互,执行任意任务。它打开/关闭微波炉门、打开/关闭烤箱门、转动炉子旋钮,并在炉子和水槽之间移动锅子 USC Jaco Play 机器人在桌面玩具厨房环境中执行拾取放置任务。任务的一些示例包括:“拿起橙色水果。”,“将黑色碗放入水槽中。” Stanford MaskVIT Data 机器人随机推动和拾取放置在容器中的物体,包括填充玩具、塑料杯和玩具等,这些物体定期被洗牌 Freiburg Franka Play “机器人与玩具积木进行交互,它拾取并放置它们,堆叠它们,拆开它们,打开抽屉、滑动门,并通过按按钮打开LED灯。” ASU Tabletop Manipulation 机器人与桌子上的几个物体进行交互。它拾取、向前推动或旋转物体 Berkeley Autolab UR5 数据包括4个机器人操作任务:在容器之间简单地拾取和放置填充动物、扫布、堆叠杯子,以及需要精确抓取和6自由度旋转的瓶子的更困难的拾取和放置 Furniture Bench 机器人在桌子上组装了9个3D打印的家具模型之一,需要抓取、插入和拧紧 Stanford Robocook 在第一个任务中,机器人用不对称夹具/双杆对称夹具/双面对称夹具夹住面团。在第二个任务中,机器人用圆形压模/方形压模/圆形冲头/方形冲头对面团进行压制。在第三个任务中,机器人用大型滚筒/小型滚筒滚动面团 QUT Dexterous Manpulation 机器人在桌面环境中执行一些任务。它整理碗和物体、烹饪和服务食物、摆桌子、扔掉垃圾纸、掷骰子、浇水植物、堆叠玩具积木 QUT Dynamic Grasping 机器人抓取一个连续随机沿XY平面移动的物体 Austin BUDS 机器人试图通过拾取锅、将锅放在盘子上,并使用拾起的工具将它们推在一起来解决一个长期的厨房任务 Tokyo PR2 Fridge Opening PR2机器人打开冰箱 UTokyo xArm PickPlace 机器人拿起一个白色的盘子,然后把它放在红色的盘子上 MPI Muscular Proprioception 机器人没有解决任何任务。它执行了随机多正弦信号和固定目标压力信号的组合 Imperial Wrist Cam 机器人与不同的日常物品进行交互,执行抓取、插入、打开、堆叠等任务 Stanford Kuka Multimodal 机器人学会将形状不同的销插入到容差低(约2毫米)的不同形状的孔中 Austin Mutex Mutex数据集涉及家庭环境中的多种任务,包括像“把面包放在盘子上”这样的拾取和放置任务,以及像“打开热风炉并把装有狗粮的碗放进去”或“从烤箱中取出托盘并放面包上”这样的接触丰富的任务 DLR Sara Pour Dataset 机器人学会将端效应器中的一个杯子中的乒乓球倒入放在桌子上的杯子中 DLR Sara Grid Clamp Dataset 机器人学会将网格夹具放置在桌子上的网格中 Austin Sailor 机器人与玩具厨房中的各种物体进行交互。它拾取和放置食物、平底锅和锅 QT-Opt Kuka机器人从一个箱子中拾取物品 Language Table 机器人在桌面上推动不同几何形状的方块 Berkeley Cable Routing 机器人通过安装在桌子上的多个密合夹片穿过电缆 Maniskill 机器人与放置在地面上的不同物体进行交互。任务包括从杂乱的物体中拾取一个孤立的物体或物体并将其移动到目标位置、将红色立方体堆叠在绿色立方体上、将销插入箱中、组装套件、将充电器插入墙上的插座、打开水龙头 CoryHall 小型移动机器人使用学习策略在办公楼的走廊中导航 CMU Franka Exploration Franka探索厨房环境,提起刀和蔬菜,并打开橱柜 CMU Food Manipulation 机器人与不同的食物进行交互 Berkeley RPT Data 拾取、堆叠、解堆叠和从容器中拾取各种物体,对象的变化 TOTO Benchmark TOTO Benchmark数据集包含两个任务的轨迹:舀取和倾倒。对于舀取任务,目标是将材料从碗里舀到勺子里。对于倾倒任务,目标是将一些材料倾倒到桌子上的目标杯子里 ALOHA 双手机器人执行复杂的、灵巧的任务,如拆包装糖果和穿鞋子
-
1.2 RH20T
- 数据收集方式
- 现有问题
- 3D鼠标或键盘进行控制的不直观性
- 使用VR遥控器时由于运动漂移而导致的不准确性
- 解决
- 配备力矩传感器
- 具有力矩渲染功能的触觉设备
- ->准确高效的数据收集
- 现有问题
https://rh20t.github.io/
We select 48 tasks from RLBench, 29 tasks from MetaWorld, and introduce 70 self-proposed tasks that are frequently encountered and achievable by robots.
⭐Zero/One-shot imitation learning
one-shot task descriptors
- images
- language
- robot video
- human video
以上方法可以被分为三类:
- model-agnostic meta-learning 无关模型的元学习
- conditional behavior cloning
- task graph construction
MIME-cmu2018
human-demo=True
行为克隆
给定一个人进行演示的第三人称视频(human-demo)和相应的同一任务的机器人轨迹(robot-demo, 拖动示教),我们希望学习将视觉特征映射到机器人轨迹之间的关系。(input: image、video;output: 关节角度(序列预测))
- 机器人关节角度轨迹和人类演示视频帧固定长度50(顺序地依据每一视频帧预测下一时间步的关节角度)
- 视频特征提取
- 捕获当前物体位置和状态(VGG图像特征提取,输出用作LSTM的隐状态和记忆单元初始值)
- 输出空间向量化(k-means聚类,变量稀疏性方法)
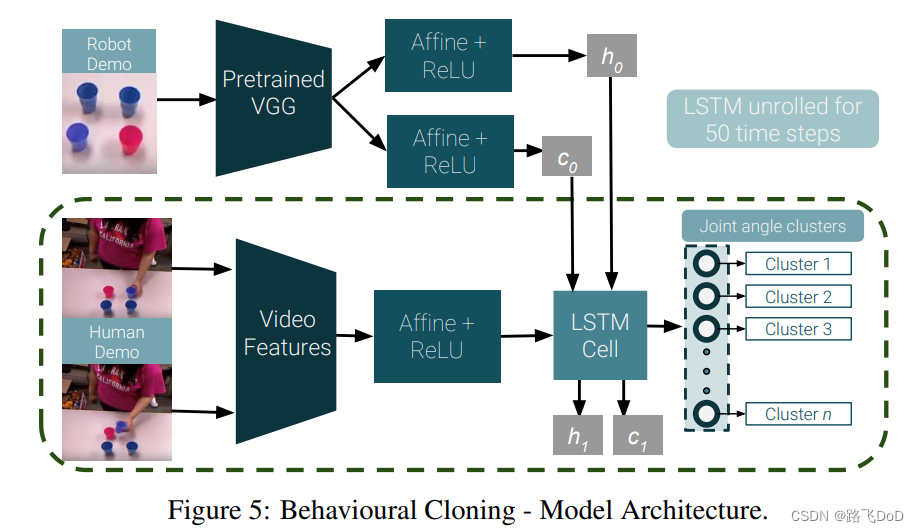
BC-Z
Zero-Shot Task Generalization with Robotic Imitation Learning
https://sites.google.com/view/bc-z/home

人类演示视频收集
人类视频是在各种家庭和办公环境中收集的。在每个环境中,设置了一个场景的副本,并由几个网络摄像头从不同的视角同时录制视频。每个视角被视为任务的不同示例,这使我们能够一次收集多个视频。总的来说,我们发现人类视频可以比远程操作的机器人快5倍至7倍,因此收集这些视频所需的时间比收集机器人数据集要少得多。
数据增强:任务的人类演示(左)通过随机扭曲和反射(右)进行增强,然后进行训练以匹配任务的语言特征。来自专家演示的机器人视频嵌入到同一个网络中,同时存在端到端保单损失。

行为克隆
行为克隆中的一种常见方法是使用高斯策略
π
(
a
∣
s
,
z
)
=
N
(
μ
,
σ
)
\pi(a\mid s,z)=\mathcal{N}(\mu,\sigma)
π(a∣s,z)=N(μ,σ) 来最大化专家操作的日志可能性。我们发现使用确定性策略足以实现泛化。该网络
π
(
a
∣
s
,
z
)
\pi(a\mid s,z)
π(a∣s,z) 预测 delta XYZ、delta 轴角和夹持器角度(0 到 1)。Huber loss(
σ
=
1.0
\sigma=1.0
σ=1.0)用于 XYZ 和轴角,log loss用于夹持器角度。
数据层级结构
人类可以根据视觉观察准确理解任务的语义,无论是观点、背景、操纵对象还是物体如何。我们旨在提供一个数据集,提供密集的**<人类演示,机器人操作>**对,使模型能够学习这一特性。为了实现这一目标,我们根据任务内部相似性将数据集组织成树形层次结构。图3展示了一个示例树形结构以及不同层次上的标准。具有更近共同祖先的叶节点之间关联更密切。对于每个任务,可以通过将具有不同层次上相同祖先的叶节点进行配对,构建数百万个<人类演示,机器人操作>对。
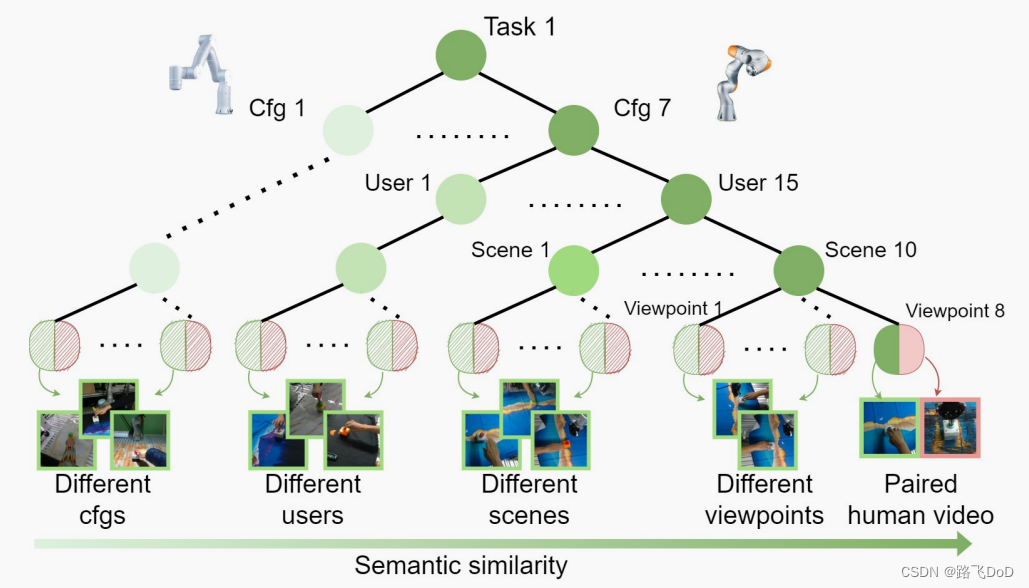
数据收集
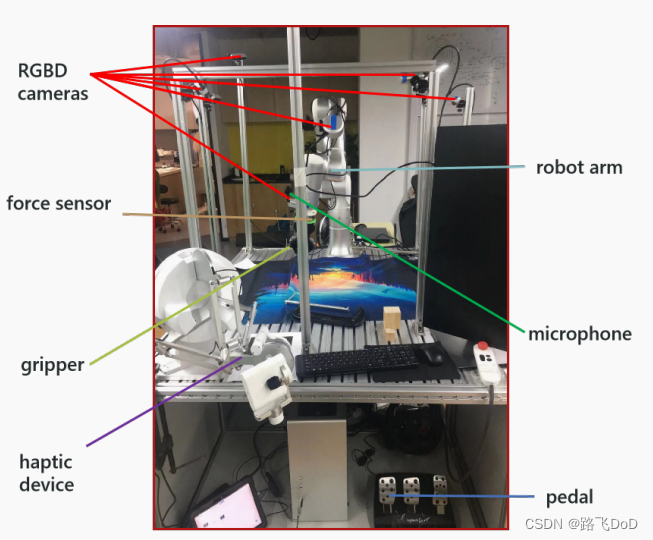
每个平台包含一个带有力矩传感器的机器人手臂,夹持器和1-2个手持摄像头,8-10个全局摄像头,2个麦克风,一个触觉设备,一个踏板和一个数据收集工作站。所有摄像头在进行操作前都经过外部校准。人类演示视频由使用额外的自我中心摄像头的人员在同一平台上收集。数十名志愿者根据我们的任务列表和文本描述进行了机器人操作。我们的远程操作相当直观,平均培训时间不到1小时。志愿者还需要指定任务的结束时间,并在完成每次操作后给出0到9的评分。0表示机器人进入紧急状态(例如,严重碰撞),1表示任务失败,2-9表示他们对操作质量的评价。在我们的数据集中,成功和失败的案例比例约为10:1。
1.3 BEHAVIOR-1K
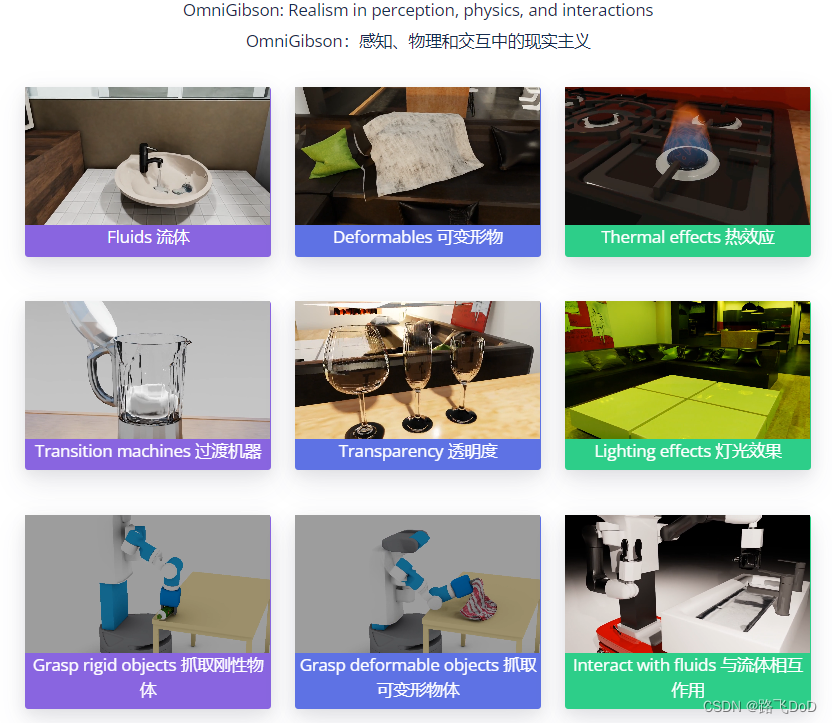
RFUniverse
A Multiphysics Simulation Platform for Embodied AI RFUniverse
- Cewu Lu
多物理场耦合效应,具身智能
除了常见的刚性和多体动力学仿真外,RFUniverse还将三种多物理场耦合效应集成到仿真环境中,即气固相互作用(空气动力学)、流体-固相互作用(流体动力学)和传热(热力学)。

RFUniverse 采用基于 gRPC 的服务器-客户端框架,使 Python 和 VR 接口能够与 Unity 后端进行通信。我们在图 2 中显示了它的结构。此通信框架支持多种语言和操作系统平台。我们采用Python作为接口语言,由于其简单性和生态系统,它被广泛用于学习框架。不同的VR设备可以通过SteamVR连接到RFUniverse。下图中演示了 HTC Vive 头显和 Noitom Hi5 手套的 VR 界面。

多模态数据
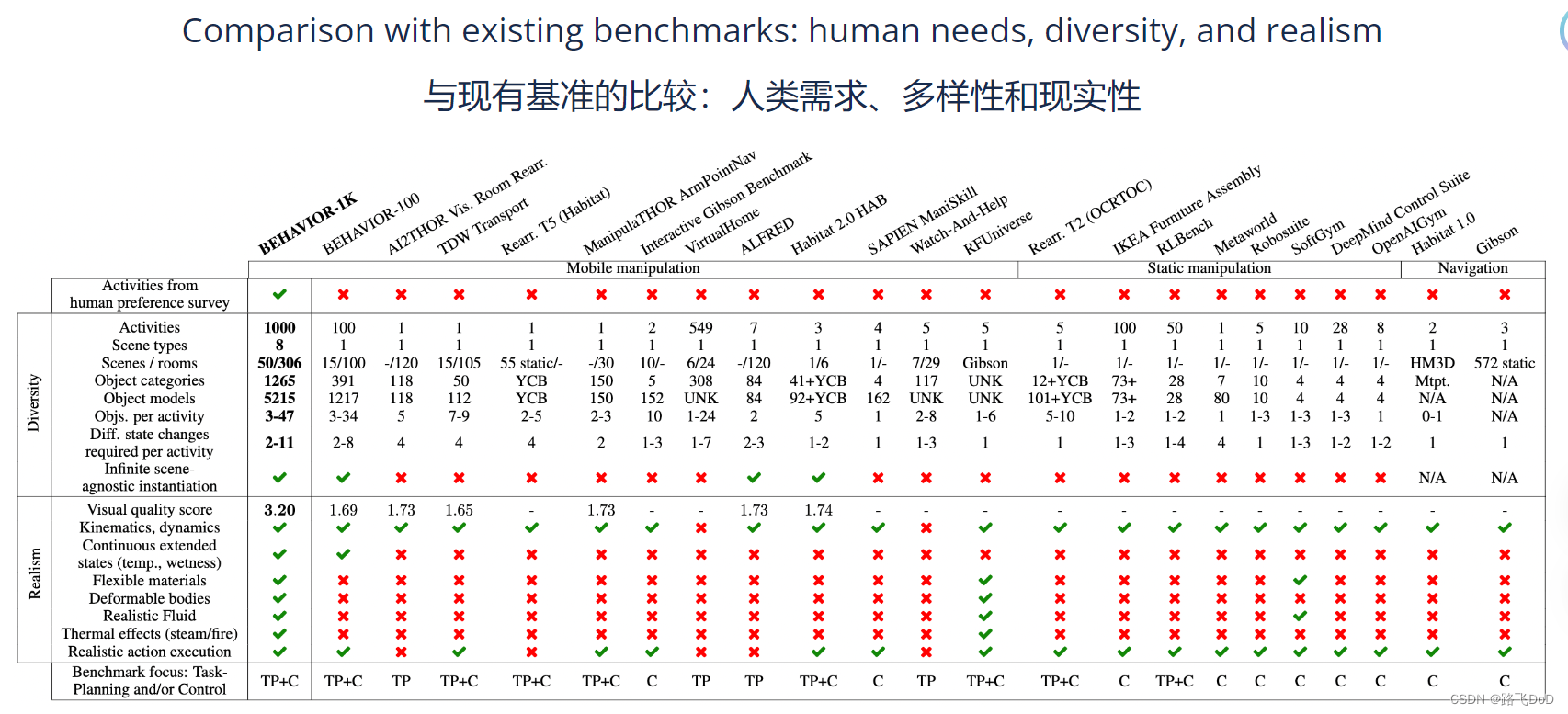
comparison
2. force sensors
3. Multi View
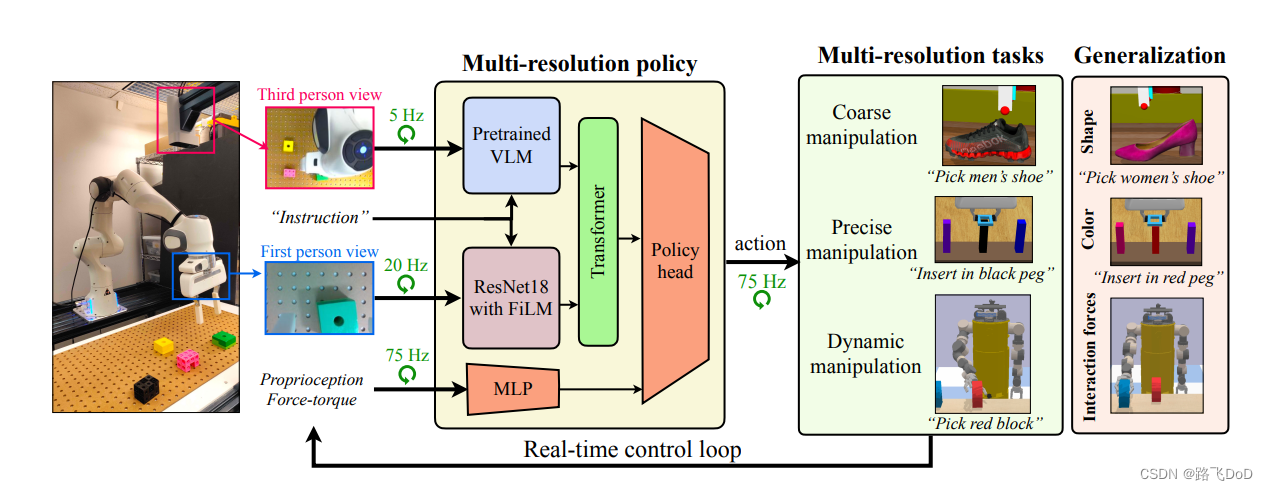
MResT
https://openreview.net/forum?id=WuBv9-IGDUA
https://arxiv.org/abs/2401.14502
Multi-Resolution Sensing for Real-Time Control with Vision-Language Models.
cmu
- task: peg-insertion(插钉子)
- 1、use a statically-mounted third-person camera (low spatial resolution or global information) to reach close to the hole(全局到达)
- 2、use a wrist-mounted first-person camera for finer alignment(局部对齐)
- 3、use proprioception and force-feedback for insertion (high spatial resolution or local information)(多模态感知信息)
- 多分辨率(空间和时间分辨率)传感器融合方法
- 操作任务
- 粗略的准静态(只需要第三人称图像)
- 精确的反应
- 操作任务
- 使用大型预训练VLM
- 问题1:推理速度慢,不利于实时闭环控制
- 不同频率、不同容量网络
- 第三视角用,低频率推理
- 第一视角更换小型训练模型,较高频率推理
- 问题2:特定域内操作任务(尤其是精确任务)需要微调,但是会降低鲁棒性、泛化
- 冻结预训练VLM
- 问题1:推理速度慢,不利于实时闭环控制
- 数据增强
- 第三人称
- 图像级增强(随机裁剪)
- 第一人称
- 图像级和像素级增强(颜色抖动、灰度)【影响图像语义】
- 第三人称
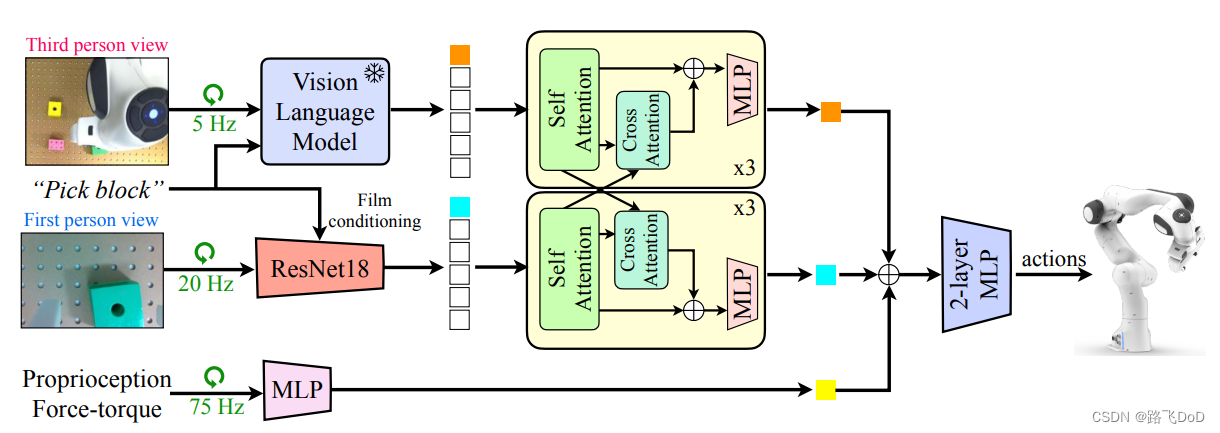
look closer
Look Closer: Bridging Egocentric and Third-Person Views with Transformers for Robotic Manipulation
https://jangirrishabh.github.io/lookcloser/
https://arxiv.org/pdf/2201.07779.pdf
fusing information from multiple cameras using transformers



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











