







一、本节任务

二、要点
2.1 设备驱动(device driver)
memory-mapped I/O:设备拥有一个地址范围,软件可以使用 ld/st 指令来访存从而读写设备的寄存器。平台设计者决定设备在物理内存空间中的位置。
内核如何识别设备中断?
device -> PLIC -> trap -> usertrap()/kerneltrap() -> devintr()
典型的设备驱动结构:上半部/下半部
上半部:执行进程的系统调用,write() 或 read();启动 I/O,可能会等待。
下半部:中断处理,读或写需要与上半部进程交互的设备;将输入放到上半部进程能读取的位置,告诉上半部输入已经读取完毕。
驱动(driver)是在操作系统中管理特定设备的代码:它可以配置设备硬件;告诉设备执行对应的操作;处理中断;并且与正在等待设备I/O的进程进行交互。设备驱动程序可以和它所管理的设备同时执行。
来自设备的中断也是 trap 的一种,内核陷阱处理程序识别设备引发的中断并调用驱动程序的中断处理程序;在xv6中,此调度发生在 devintr(kernel/trap.c:178)中。
许多驱动程序在两种环境中执行代码:一个是上半部(top half),运行在一个进程的内核线程中;和一个在中断时执行的下半部(bottom half)。上半部分是通过系统调用调用的,如 read 和 write 希望设备执行I/O,然后程序会等待操作(如 read 和 write 操作)执行完成;最终设备执行完 I/O 后会发起一个中断,然后执行中断处理程序,中断处理程序可以唤醒等待 I/O 操作的进程,这部分就是中断下半部。
2.2 UART 驱动
xv6 的 main 函数中调用 consoleinit(kernel/console.c)来初始化串口硬件。
当用户键入一个字符时,UART 硬件会引发一个中断,从而激活 xv6 的陷阱处理程序(trap handler)。陷阱处理程序调用 devintr(kernel/trap.c),它通过 RISC-V scause 的寄存器,判断中断来自外部设备。然后它要求 PLIC 告诉它是哪个设备发生了中断(kernel/trap.c:187)。如果是 UART,devintr 就会调用 uartintr。
uartintr 从 UART 硬件中读取任何等待的输入字符,并将它们交给 consoleintr(kernel/console.c:136);consoleintr 的工作是在 cons.buf 中积累输入字符,直到整行到达。当换行到达时,主机会唤醒一个等待的 consoleread(如果有的话)。一旦被唤醒,consoleread 会将 cons.buf 中的一整行复制到用户空间,并(通过系统调用机制)返回到用户空间。
在设备驱动程序中,一般通过 buffer 和 interrupt 来将设备工作和进程进行解耦。
驱动中的并发问题,驱动程序一般会使用锁来保护临界资源:在两个 cpu 核上执行同样的驱动程序的时候,如果不对访问进行约束,可能会导致冲突和死锁的问题。还有一种情况就是,当多个进程并发运行时,发生输入中断的目标进程并不是当前运行进程,所以此时中断只会把输入复制到 buffer 中,然后唤醒目标进程进行后续处理。
2.3 定时器中断(timer interrupt)
RISC-V CPU 要求定时器中断是在机器模式下,而不是监督模式。RISC-V 的机器模式下没有分页,并且其机器模式使用一套完全与监督模式独立的寄存器(如 mstatus、mcause),所以无法在机器模式下运行 xv6 kernel,所以 xv6 使用的一套独立的机制来处理定时器中断。
在 start(kernel/start.c)中,cpu 运行在机器模式,此时会配置定时器中断(配置 CLINT(core local interrupt)硬件)。
有一些机制可以减少中断的发生频率,如把一系列请求放到一个中断中(如 DMA);另外一种方法是完全禁止中断,并且每隔一段时间就去确认一下设备是否有请求需要处理,这种方法被称为 polling,对于中断频率非常高的设备来说,这种方式十分有效,一些驱动动态地在中断和 polling 之间来回切换。
三、Lab: cow: Copy-on-write fork
问题:uservec、kernelvec、timervec 的作用?分别在什么时候执行?
我们已经知道 stvec 寄存器保存的是中断服务程序的首地址,在 U 模式下,stvec 指向的是 uservec,在 S 模式下,stvec 指向的是 kernelvec,这样做的原因是需要在 uservec 切换页表,并且从用户栈切换到内核栈。
那么 xv6 是如何设置 stvec 的呢?首先在 uservec 例程中除了执行保存上下文、切换页表等操作之外,还会在 usertrap 中将 stvec 指向 kernelvec,这里的切换的目的是当前已经执行到了 S 模式,所有的中断、陷阱等都必须由 kernelvec 负责处理。
当需要返回 usertrap 时,usertrap 会调用 usertrapret,usertrapret 会重新设置 stvec 的值使其指向 uservec,之后跳转到 userret,恢复上下文和切换页表。
xv6 对于时钟中断的处理方式是这样的:在 M-mode 设置好时钟中断的处理函数 timervec,当发生时钟中断时就由 M-mode 的代码读写 mtime 和 mtimecmp 寄存器,然后激活 sip.SSIP 以软件中断的形式通知内核。内核在收到软件中断之后会递增 ticks 变量,并调用 wakeup 函数唤醒沉睡的进程。 内核本身也会收到时钟中断,此时内核会判断当前运行的是不是进程号为 0 的进程,如果不是就会调用 yield() 函数使当前进程放弃 CPU 并调度下一个进程;如果使进程号为 0 的进程,那就不做处理。
3.1 Implement copy-on-write fork(hard)
xv6 中的 fork() 系统调用会将父进程的所有用户空间拷贝到子进程中,对于用户空间比较大的父进程来说,这个拷贝操作十分耗时,并且对于 fork() + exec() 的子进程来说,会用到的父进程的空间很少,大部分拷贝的空间都丢弃了。所以后面有人提出了写时拷贝(COW, copy-on-write),该方法可以推迟拷贝操作。
COW fork() 仅为子进程创建一个页表,该页表指向父进程的物理页面(也可以理解为直接从父进程那儿拷贝来的页表),并且会将父进程和子进程页表中的页表项设置为只读,当父进程或子进程需要对某个页面执行写操作时,CPU 会引发页故障,在内核的页故障处理函数中会给引发该页故障的进程分配一个物理页面,并且将进程需要放问的页面上的内容拷贝到新页面上,然后把对应页表项与新页面关联起来,并且设置页面为可写,当页故障处理函数返回后,该进程即可对页面的拷贝进行写操作了。
写时拷贝同时也增加了释放页面的复杂性, 因为一个页面可能同时关联多个进程,如果要释放页面的话,还需要确认这几个进程与页面的关联是否释放。
而本实验的目标就是要实现写时拷贝。步骤如下:
修改 kernel/kalloc.c,添加 ref_count 数组用来给每个物理页面保存引用该页面的进程数,当引用数为 0 时表示该页面没有任何页面引用,此时在 kfree 中才能释放页面,否则仅将引用数减一;使用 kalloc 函数时,初始化引用数为 1。
/* kernel/kalloc.c */
#define PA2INDEX(pa) ((uint64)pa/PGSIZE)
int ref_count[PHYSTOP/PGSIZE];
void
freerange(void *pa_start, void *pa_end)
{
char *p;
p = (char*)PGROUNDUP((uint64)pa_start);
for(; p + PGSIZE <= (char*)pa_end; p += PGSIZE){
ref_count[PA2INDEX(p)] = 1;
kfree(p);
}
}
void
kfree(void *pa)
{
struct run *r;
if(((uint64)pa % PGSIZE) != 0 || (char*)pa < end || (uint64)pa >= PHYSTOP)
panic("kfree");
acquire(&kmem.lock);
int remain_count = --ref_count[PA2INDEX(pa)];
release(&kmem.lock);
if(remain_count > 0){
return;
}
// Fill with junk to catch dangling refs.
memset(pa, 1, PGSIZE);
r = (struct run*)pa;
acquire(&kmem.lock);
r->next = kmem.freelist;
kmem.freelist = r;
release(&kmem.lock);
}
void *
kalloc(void)
{
struct run *r;
acquire(&kmem.lock);
r = kmem.freelist;
if(r)
kmem.freelist = r->next;
release(&kmem.lock);
if(r){
memset((char*)r, 5, PGSIZE); // fill with junk
ref_count[PA2INDEX(r)] = 1;
}
return (void*)r;
}
void ref_count_inc(uint64 pa){
if(pa > PHYSTOP)
panic("ref_count_inc");
acquire(&kmem.lock);
++ref_count[PA2INDEX(pa)];
release(&kmem.lock);
}
修改 uvmcopy() 函数(kernel/vm.c),使得其不会给子进程分配新的物理页面,而是仅将父进程的物理页映射到子进程,其中使用 pte 中的 RSW(reserved for software)两位来分别标志页面是否为 COW 页面(第 9 位),以及页面是否为可写的页面(第 8 位)。

/* kernel/vm.c */
int uvmcopy(pagetable_t old, pagetable_t new, uint64 sz)
{
pte_t *pte;
uint64 pa, i;
uint flags;
for(i = 0; i < sz; i += PGSIZE){
if((pte = walk(old, i, 0)) == 0)
panic("uvmcopy: pte should exist");
if((*pte & PTE_V) == 0)
panic("uvmcopy: page not present");
// clear PTE_W and set RSW means it's a writeable page
if((*pte & PTE_W) != 0){
*pte &= (~PTE_W);
*pte |= (1 << 8);
}
// set RSW means it's a COW page
*pte |= (1 << 9);
pa = PTE2PA(*pte);
flags = PTE_FLAGS(*pte);
if(mappages(new, i, PGSIZE, pa, flags) != 0){
goto err;
}
ref_count_inc(pa);
}
return 0;
err:
uvmunmap(new, 0, i / PGSIZE, 1);
return -1;
}
由 riscv 文档可知,引发 page fault 的原因可能有多种,比如因为 load 指令触发的 page fault、因为 store 指令触发的 page fault 又或者是因为 jump 指令触发的 page fault,在引发 page fault 后,cpu 会将出错的地址放到 stval 寄存器中,而发生 page fault 的原因则存放到 scause 寄存器中,scause 的内容如下图所示:

可以看到,12 表示是因为指令执行而引起的 page fault,13 表示是因为 load 而引起的 page fault,15 则是表示因为 store 而引起的中断,而写时拷贝的拷贝操作发生在进程想要写页面的时候,所以在 usertrap 我们只需要判断 scause 是否等于 15 即可。
当 scause == 15 时,即可确定发生了写页面的 page fault,然后判断 RSW 的第二位是否为 1,为 1 则表示此页面为写时拷贝的映射页面,再判断 RSW 的第一位是否为 1,为 1 则代表原来的页面是可写的,此时需要拷贝页面到一个新的物理页面上,然后让进程的页表项指向新的副本页面;若 RSW 的第一位为 0,则代表页面原来是不可写的,此时不拷贝新页面,并且需要 kill 掉该进程,usertrap 代码如下:
/* kernel/trap.c */
void
usertrap(void)
{
int which_dev = 0;
if((r_sstatus() & SSTATUS_SPP) != 0)
panic("usertrap: not from user mode");
// send interrupts and exceptions to kerneltrap(),
// since we're now in the kernel.
w_stvec((uint64)kernelvec);
struct proc *p = myproc();
// save user program counter.
p->trapframe->epc = r_sepc();
if(r_scause() == 8){
// system call
if(killed(p))
exit(-1);
// sepc points to the ecall instruction,
// but we want to return to the next instruction.
p->trapframe->epc += 4;
// an interrupt will change sepc, scause, and sstatus,
// so enable only now that we're done with those registers.
intr_on();
syscall();
} else if(r_scause() == 15){
if(cow(p->pagetable, r_stval()) != 0){
setkilled(p);
}
} else if((which_dev = devintr()) != 0){
// ok
} else {
printf("usertrap(): unexpected scause %p pid=%d\n", r_scause(), p->pid);
printf(" sepc=%p stval=%p\n", r_sepc(), r_stval());
setkilled(p);
}
if(killed(p))
exit(-1);
// give up the CPU if this is a timer interrupt.
if(which_dev == 2)
yield();
usertrapret();
}
cow() 函数的代码如下:
/* kernel/vm.c */
int cow(pagetable_t pagetable, uint64 va){
if(va >= MAXVA)
return -1;
uint64 pa, pa_new;
uint flags;
uint64 va_align = PGROUNDDOWN(va);
pte_t* pte = walk(pagetable, va_align, 0);
if((*pte & (1 << 9)) != 0){
// it's a COW page
if((*pte & (1 << 8)) != 0){
// the page is writeable before
pa = PTE2PA(*pte);
flags = PTE_FLAGS(*pte);
if((pa_new = (uint64)kalloc()) == 0)
return -1;
memmove((void *)pa_new, (const void *)pa, PGSIZE);
kfree((void *)pa); // 减少COW页面的reference count
*pte = PA2PTE(pa_new) | flags | PTE_W;
} else {
// the page is not writeable before
return -1;
}
} else {
printf("not a COW page\n");
}
return 0;
}
最后要注意的一个问题就是 copyout 函数,该函数的作用是将数据从内核空间拷贝到用户空间中,并且该函数是在内核中调用,所以不会触发 usertrap,而是 kerneltrap,所以我们要在 copyout 函数中判断我们的目的用户页面是否为 COW 页面,如果是,则需要额外的拷贝操作(写时拷贝):
int
copyout(pagetable_t pagetable, uint64 dstva, char *src, uint64 len)
{
uint64 n, va0, pa0;
pte_t *pte;
while(len > 0){
va0 = PGROUNDDOWN(dstva);
if(va0 >= MAXVA)
return -1;
pte = walk(pagetable, va0, 0);
if(pte == 0 || (*pte & PTE_V) == 0 || (*pte & PTE_U) == 0)
return -1;
if((*pte & PTE_W) == 0 && (*pte & (1 << 9)) != 0){
// it's a COW page
if(cow(pagetable, va0) != 0)
return -1;
} else if((*pte & PTE_W) == 0){
return -1;
}
pa0 = PTE2PA(*pte);
n = PGSIZE - (dstva - va0);
if(n > len)
n = len;
memmove((void *)(pa0 + (dstva - va0)), src, n);
len -= n;
src += n;
dstva = va0 + PGSIZE;
}
return 0;
}
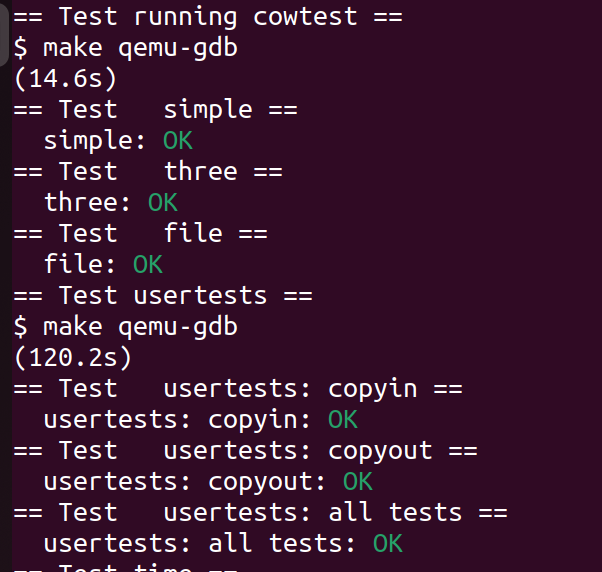
最后测试全部通过:















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









