







目录
文章目录
RISC-V处理器的设计与实现(一)—— 基本指令集_Patarw_Li的博客-CSDN博客
RISC-V处理器的设计与实现(二)—— CPU框架设计_Patarw_Li的博客-CSDN博客
RISC-V处理器的设计与实现(三)—— 上板验证_Patarw_Li的博客-CSDN博客
RISC-V处理器设计(四)—— Verilog 代码设计-CSDN博客
RISC-V处理器设计(五)—— 在 RISC-V 处理器上运行 C 程序-CSDN博客
前面我们选好了要实现的指令集,并且了解了每个指令的功能(传送门:RISC-V处理器的设计与实现(一)—— 基本指令集_Patarw_Li的博客-CSDN博客),接下来我们就可以开始设计cpu了。当然我们不可能一上来就写代码,首先我们要把cpu的结构、工作流程了解清楚,然后再开始代码的编写。
本项目的源码仓库:
一、CPU和计算机的关系
说到计算机,那就不得不提大名鼎鼎的冯诺依曼了:
约翰·冯·诺依曼(John von Neumann,1903年12月28日-1957年2月8日),美籍匈牙利数学家,计算机科学家,物理学家,是20世纪最重要的数学家之一。冯·诺依曼是罗兰大学数学博士,是现代计算机,博弈论,核武器和生化武器等领域内的科学全才之一,被后人称为“现代计算机之父”、“博弈论之父”。
而现在的计算机大多都遵循冯诺依曼结构:
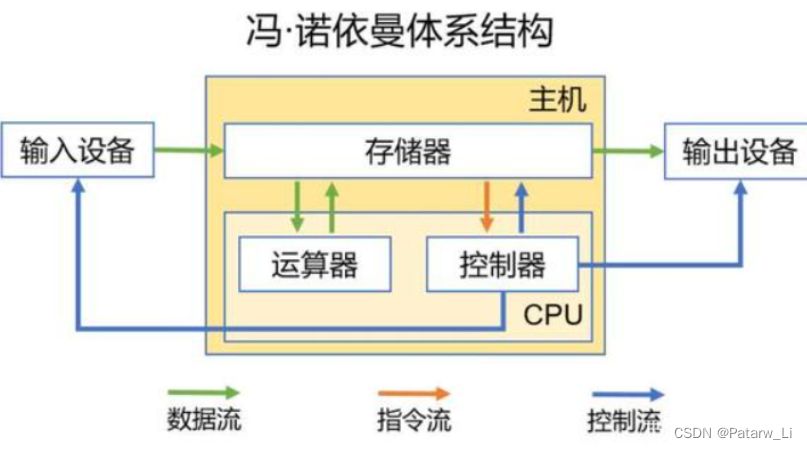
冯诺依曼结构包括如下4个部分:
- CPU,即中央处理器,是一台计算机的运算核心和控制核心。其功能主要是解释计算机指令以及处理计算机软件中的数据。CPU由运算器、控制器、寄存器、高速缓存及实现它们之间联系的数据、控制及状态的总线构成
- 存储器,分为外存和内存, 用于存储数据(使用二进制方式存储)
- 输入设备,用户给计算机发号施令的设备
- 输出设备,计算机个用户汇报结果的设备
其中最核心的部分也就是CPU了,CPU又名中央处理器(Central Processing Unit,简称CPU),它由ALU(算术逻辑单元)和CU(控制单元)两部分组成:
- ALU 算术逻辑单元(Arithmetic logical Unit):是中央处理器(CPU)的执行单元,是所有中央处理器的核心组成部分,由"And Gate"(与门) 和"Or Gate"(或门)构成的算术逻辑单元,主要功能是进行二位元的算术运算,如加减乘(不包括整数除法)。基本上,在所有现代CPU体系结构中,二进制都以补码的形式来表示。
- CU 控制单元(Control Unit):负责程序的流程管理。控制单元是整个 CPU 的指挥控制中心,对协调整个计算机有序工作极为重要。
此外还包括一些寄存器,如PC(程序计数器) 、IR(指令寄存器)和一些通用寄存器等等。
二、CPU的工作流程
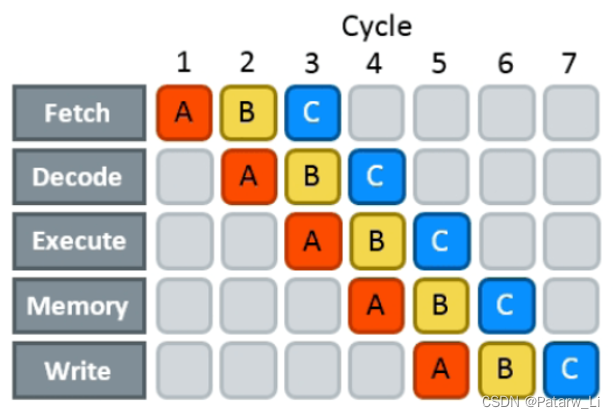
CPU执行分为5个阶段,取指阶段(IF)、译码阶段(ID)、执行阶段(EX)、访存阶段(MEM)、写回阶段(WB):
一、取指令阶段
取指令(Instruction Fetch,IF)阶段是根据PC的值,将一条指令从主存中取到指令寄存器的过程。程序计数器PC中的数值,用来指示当前指令在主存中的位置。当一条指令被取出后,PC中的数值将根据指令字长度而自动递增(如32位指令为PC+4)。
二、指令译码阶段
取出指令后,计算机进入指令译码(Instruction Decode,ID)阶段。在指令译码阶段,指令译码器按照预定的指令格式,对取回的指令进行拆分和解释,识别区分出不同的指令类别以及各种获取操作数的方法。
三、执行指令阶段
在取指令和指令译码阶段之后,接着进入执行指令(Execute,EX)阶段。此阶段的任务是完成指令所规定的各种操作,具体实现指令的功能。为此,CPU的不同部分被连接起来,以执行所需的操作。
四、访存取数阶段
根据指令需要,有可能要访问主存,读取操作数,这样就进入了访存取数(Memory,MEM)阶段。此阶段的任务是:根据指令地址码,得到操作数在主存中的地址,并从主存中读取该操作数用于运算。
五、结果写回阶段
作为最后一个阶段,结果写回(Write Back,WB)阶段把执行指令阶段的运行结果数据“写回”。写回的地方一般是寄存器或者内存,其中写回寄存器的情况最多,方便之后的指令使用。在有些情况下,结果数据也可被写入相对较慢、但较廉价且容量较大的主存。许多指令还会改变程序状态字寄存器中标志位的状态,这些标志位标识着不同的操作结果,可被用来影响程序的动作。
因为每个阶段的执行部件是分时复用的,所以可以用流水线的方式执行指令,下面是一个五级指令流水线:
三、CPU的架构设计
在了解上面这些内容后我们就可以开始CPU的框架设计了,为了简单,我们只设计三级流水线,写回和访存都放在执行阶段完成,下面是模块框架图:

1、取指阶段
取指阶段负责从rom中取出指令,传给译码阶段。其中pc模块输出需要取出的指令的地址pc_out,将指令地址传给rom后,rom寻址到对应指令再回传给if_id模块。if_id模块的作用是将指令和指令地址延后一拍传给译码模块ID_UNIT,延后一拍的目的是为了让系统以流水线的形式工作。
// 取指单元
module IF_UNIT(
input wire clk ,
input wire rst_n ,
input wire[2:0] hold_flag_i ,
input wire jump_flag ,
input wire[`INST_REG_DATA] jump_addr ,
output wire[`INST_DATA_BUS] ins_o , // 指令
output wire[`INST_ADDR_BUS] ins_addr_o , // 指令地址
output wire[`INST_ADDR_BUS] pc_o , // 传给rom的指令地址
input wire[`INST_DATA_BUS] ins_i // rom根据地址读出来指令
);
wire[`INST_ADDR_BUS] pc;
assign pc_o = pc;
// PC寄存器模块例化
pc u_pc(
.clk (clk) ,
.rst_n (rst_n),
.hold_flag (hold_flag_i),
.jump_flag (jump_flag),
.jump_addr (jump_addr),
.pc_out (pc)
);
// 指令寄存器模块例化
if_id u_if_id(
.clk (clk),
.rst_n (rst_n),
.hold_flag (hold_flag_i),
.ins_i (ins_i),
.ins_addr_i (pc),
.ins_o (ins_o),
.ins_addr_o (ins_addr_o)
);
endmodule2、译码阶段
译码阶段负责对指令进行译码。id模块从指令中读出寄存器写回地址rd,拼接立即数imm,从寄存器单元(RF_UNIT)中取出操作数R1、R2,然后将这些通过id_ex模块延后一拍传给执行模块EX_UNIT。
module ID_UNIT(
input wire clk ,
input wire rst_n ,
input wire hold_flag ,
//从IF模块传来的指令和指令地址
input wire[`INST_DATA_BUS] ins_i ,
input wire[`INST_ADDR_BUS] ins_addr_i ,
// 传给RF模块的地址,用于读取数据
output wire[`INST_REG_ADDR] reg1_rd_addr_o ,
output wire[`INST_REG_ADDR] reg2_rd_addr_o ,
// 根据传给RF模块地址读到的数据
input wire[`INST_REG_DATA] reg1_rd_data_i ,
input wire[`INST_REG_DATA] reg2_rd_data_i ,
output wire[`INST_DATA_BUS] ins_o ,
output wire[`INST_ADDR_BUS] ins_addr_o ,
// 将读到的寄存器数据传给EX模块
output wire[`INST_REG_DATA] reg1_rd_data_o ,
output wire[`INST_REG_DATA] reg2_rd_data_o ,
// 写寄存器地址
output wire[`INST_REG_ADDR] reg_wr_addr_o ,
// 立即数
output wire[`INST_REG_DATA] imm_o
);
wire[`INST_REG_ADDR] reg_wr_addr;
wire[`INST_REG_DATA] imm;
// 指令译码模块例化
id u_id(
.clk (clk),
.rst_n (rst_n),
.ins_i (ins_i),
.ins_addr_i (ins_addr_i),
.reg1_rd_addr_o (reg1_rd_addr_o),
.reg2_rd_addr_o (reg2_rd_addr_o),
.reg_wr_addr_o (reg_wr_addr),
.imm_o (imm)
);
// 将传给EX单元的内容打一拍
id_ex u_id_ex(
.clk (clk),
.rst_n (rst_n),
.hold_flag (hold_flag),
.ins_i (ins_i),
.ins_addr_i (ins_addr_i),
.reg1_rd_data_i (reg1_rd_data_i),
.reg2_rd_data_i (reg2_rd_data_i),
.reg_wr_addr_i (reg_wr_addr),
.imm_i (imm),
.ins_o (ins_o),
.ins_addr_o (ins_addr_o),
.reg1_rd_data_o (reg1_rd_data_o),
.reg2_rd_data_o (reg2_rd_data_o),
.reg_wr_addr_o (reg_wr_addr_o),
.imm_o (imm_o)
);
endmodule3、执行阶段
执行阶段负责指令的执行、访存以及数据的回写。alu模块对传入的两个操作数进行计算,通过 alu_op_code来判断计算类型;cu负责发出各种控制信号,比如寄存器堆写使能信号、ram写使能信号、流水线暂停信号,等等;mul和div模块分别负责乘法和除法运算。
// 执行单元
module EX_UNIT(
input wire clk ,
input wire rst_n ,
input wire[`INST_DATA_BUS] ins_i ,
input wire[`INST_ADDR_BUS] ins_addr_i ,
input wire[6:0] opcode_i ,
input wire[2:0] funct3_i ,
input wire[6:0] funct7_i ,
input wire[`INST_REG_DATA] imm_i ,
input wire[`INST_REG_DATA] reg1_rd_data_i ,
input wire[`INST_REG_DATA] reg2_rd_data_i ,
input wire[`INST_REG_ADDR] reg_wr_addr_i ,
output wire reg_wr_en_o ,
output wire[`INST_REG_ADDR] reg_wr_addr_o ,
output wire[`INST_REG_DATA] reg_wr_data_o ,
input wire rib_hold_flag_i ,
output wire jump_flag_o ,
output wire[`INST_REG_DATA] jump_addr_o ,
output wire[2:0] hold_flag_o ,
// 内存相关引脚(ram)
input wire[`INST_ADDR_BUS] mem_rd_addr_i ,
input wire[`INST_DATA_BUS] mem_rd_data_i ,
output wire mem_wr_rib_req_o ,
output wire mem_wr_en_o ,
output wire[`INST_ADDR_BUS] mem_wr_addr_o ,
output wire[`INST_DATA_BUS] mem_wr_data_o
);
wire[`INST_REG_DATA] alu_data1;
wire[`INST_REG_DATA] alu_data2;
wire[3:0] alu_op_code;
wire[`INST_REG_DATA] alu_res;
wire alu_zero_flag;
wire alu_sign_flag;
wire alu_overflow_flag;
wire[2:0] mul_op_code;
wire[`INST_DB_REG_DATA] mul_res;
wire[2:0] div_op_code;
wire div_req;
wire div_busy;
wire[`INST_REG_ADDR] div_reg_wr_addr;
wire div_res_ready;
wire[`INST_REG_DATA] div_res;
reg [`INST_ADDR_BUS] mem_rd_addr;
// 内存读地址延迟一个时钟周期
always @ (posedge clk or negedge rst_n) begin
if(!rst_n) begin
mem_rd_addr <= `ZERO_WORD;
end
else begin
mem_rd_addr <= mem_rd_addr_i;
end
end
// 控制单元例化
cu u_cu(
.clk (clk),
.rst_n (rst_n),
.ins_addr_i (ins_addr_i),
.opcode_i (opcode_i),
.funct3_i (funct3_i),
.funct7_i (funct7_i),
.imm_i (imm_i),
.alu_res_i (alu_res),
.alu_zero_flag_i (alu_zero_flag),
.alu_sign_flag_i (alu_sign_flag),
.alu_overflow_flag_i (alu_overflow_flag),
.alu_op_code_o (alu_op_code),
.alu_data1_o (alu_data1),
.alu_data2_o (alu_data2),
.mul_res_i (mul_res),
.mul_op_code_o (mul_op_code),
.div_res_i (div_res),
.div_busy_i (div_busy),
.div_res_ready_i (div_res_ready),
.div_reg_wr_addr_i (div_reg_wr_addr),
.div_req_o (div_req),
.div_op_code_o (div_op_code),
.rib_hold_flag_i (rib_hold_flag_i),
.jump_flag_o (jump_flag_o),
.jump_addr_o (jump_addr_o),
.hold_flag_o (hold_flag_o),
.reg1_rd_data_i (reg1_rd_data_i),
.reg2_rd_data_i (reg2_rd_data_i),
.reg_wr_addr_i (reg_wr_addr_i),
.reg_wr_en_o (reg_wr_en_o),
.reg_wr_addr_o (reg_wr_addr_o),
.reg_wr_data_o (reg_wr_data_o),
.mem_rd_addr_i (mem_rd_addr),
.mem_rd_data_i (mem_rd_data_i),
.mem_wr_rib_req_o (mem_wr_rib_req_o),
.mem_wr_en_o (mem_wr_en_o),
.mem_wr_addr_o (mem_wr_addr_o),
.mem_wr_data_o (mem_wr_data_o)
);
// alu运算单元例化
alu u_alu(
.alu_data1_i (alu_data1),
.alu_data2_i (alu_data2),
.alu_op_code_i (alu_op_code),
.alu_res_o (alu_res),
.alu_zero_flag_o (alu_zero_flag),
.alu_sign_flag_o (alu_sign_flag),
.alu_overflow_flag_o (alu_overflow_flag)
);
// 乘法单元例化
mul u_mul(
.mul_data1_i (reg1_rd_data_i),
.mul_data2_i (reg2_rd_data_i),
.mul_op_code_i (mul_op_code),
.mul_res_o (mul_res)
);
// 除法单元例化
div u_div(
.clk (clk),
.rst_n (rst_n),
.div_data1_i (reg1_rd_data_i),
.div_data2_i (reg2_rd_data_i),
.div_op_code_i (div_op_code),
.div_req_i (div_req),
.div_reg_wr_addr_i (reg_wr_addr_i),
.div_reg_wr_addr_o (div_reg_wr_addr),
.div_busy_o (div_busy),
.div_res_ready_o (div_res_ready),
.div_res_o (div_res)
);
endmodule四、上板测试
本项目的 cpu 目前实现了 RV32I 和 RV32M 扩展,目前可以跑一些基本的c语言代码。
如何编译和测试请参考我的这篇博客:
开发一个RISC-V上的操作系统(一)—— 环境搭建_risc v 开发环境_Patarw_Li的博客-CSDN博客
如果遇到问题也欢迎加群 892873718 交流~















 3023
3023











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









