








DEFORMABLE 3D CONVOLUTION FOR VIDEO SUPER-RESOLUTION
~前言~
3D卷积可以比2D卷积更关注时空特征。且对于3D Net来说,在所有层使用3×3×3的小卷积核效果更好。
以前的方法多是在空间域上提取特征,在时域上进行动作补偿。因此视频序列中的时空信息无法被共同利用,超分辨视频序列的相干性被削弱。
由于视频帧在时间维度上提供了额外的信息,因此充分利用视频帧的时空依赖性来提高视频SR的性能是非常重要的。
由于三维卷积(C3D)可以同时建模外观与运动,于是C3D应用于视频。但是,C3D的接收域固定,不能有效的模拟大动作。
为了补短板,将可变形卷积与C3D结合,实现可变形3D卷积(D3D)。
D3D仅在空间维度上执行核变形去融合时间先验(时间上越接近参考帧越重要)。
C3D:普通的3D卷积
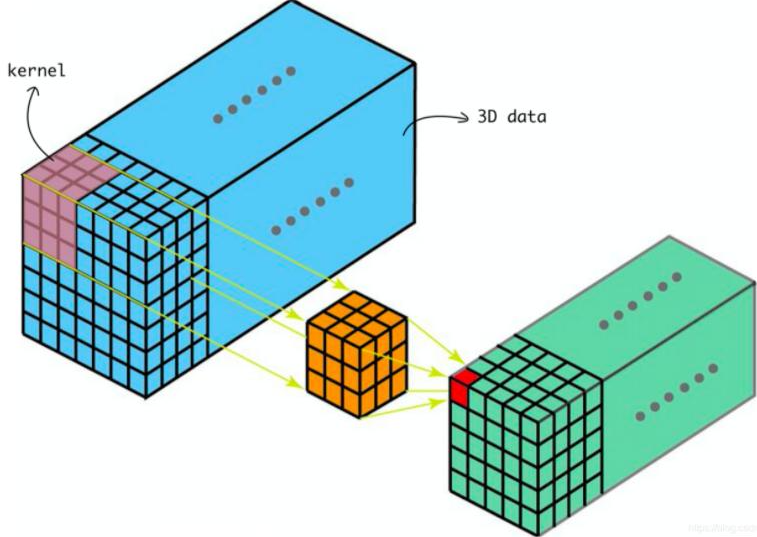
-
对输入的特征图用3D卷积采样
-
通过函数w对采样值计算加权和
具体来说,通过一个3×3×3卷积可以被表示为:
$$y(P_0)=\sum^{N}_{n=1}w(P_n)·x(P_0+P_n)
$$
P_0代表输出特征中的一个位置
P_n代表n_{th}在3×3×3卷积采样网格G中的值。
N=27(3×3×3)是采样网格的尺寸。
Fig.1中所示,在输入特征图中的3×3×3的浅橘色立方体是普通的C3D采样网格,用于生成输出特征中的深橙色立方体。
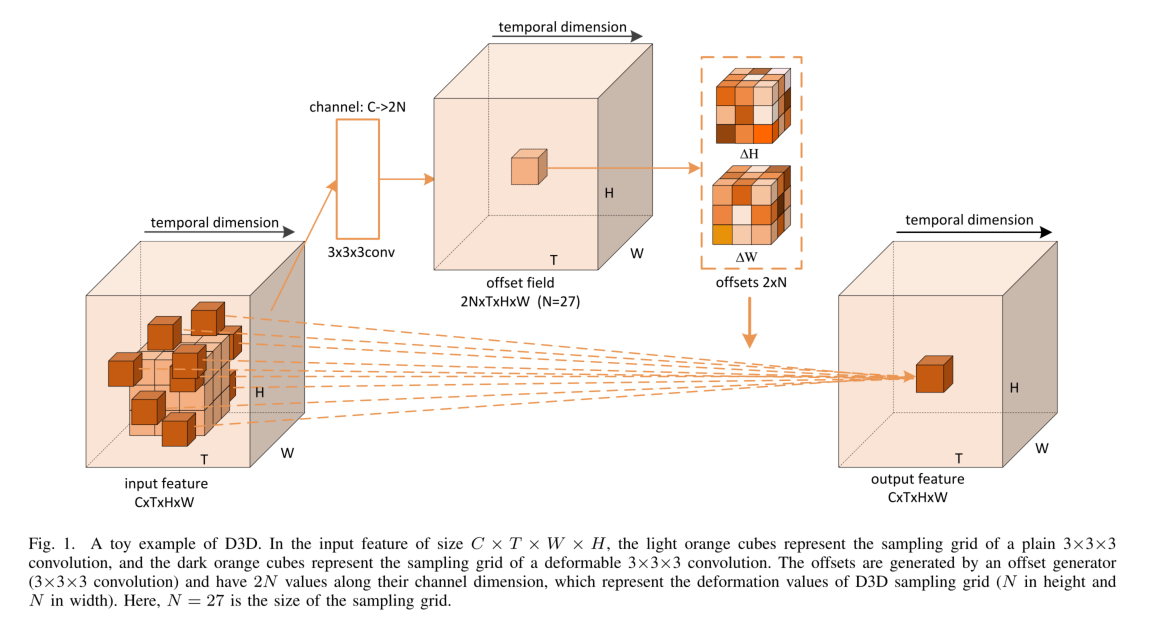
D3D 可变3D卷积
D3D通过可学习的偏置增大空间接收域来提升外观与动作的建模能力。
Fig.1 C×T×W×H的输入特征图一开始被喂进C3D产生2N×T×W×H的偏置。偏移特征的通道数量被设置为2N,是为了2D空间形变(即沿着高度和宽度维度形变)。学习到的偏置用于指导C3D网格的形变去生成D3D网格。最后,D3D网格被用于产生输出特征。
D3D的表达式为:
$$
y(P_0)=\sum^N_{n=1}w(p_n)·x(p_0+p_n+△p_n)
$$
其中的△p_n代表第n_{th}的值在3×3×3卷积采样网格中对应的偏置。
P_0代表输出特征中的一个位置
P_n代表n_{th}在3×3×3卷积采样网格G中的值。
N=27(3×3×3)是采样网格的尺寸。
D3DNET
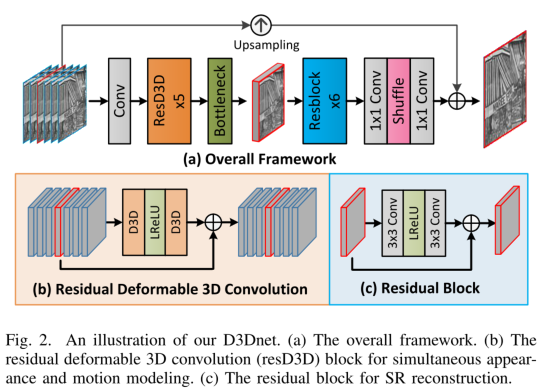
一个带有7帧的视频序列被输入一个C3D层产生特征图。
接着喂进5个resD3D层(Fig.2(b)),以达到动作感知深度时空特征提取。
然后,输入瓶颈层去融合提取的特征。
最后这些融合的特征被6个联级残差模块(Fig.2.(c))处理,一个超像素层用于重建。
总结
-
提出D3Dnet来充分利用时空信息
-
融合可变卷积与C3D卷积为D3D卷积,拥有高效的时空挖掘与自适应运动补偿。
-
计算效率高。
效果


















 875
875

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









