









📢本篇文章是博主强化学习(RL)领域学习时,用于个人学习、研究或者欣赏使用,并基于博主对相关等领域的一些理解而记录的学习摘录和笔记,若有不当和侵权之处,指出后将会立即改正,还望谅解。文章分类在👉强化学习专栏:
【强化学习】- 【单智能体强化学习】(9)---《近端策略优化算法(PPO)详解》
近端策略优化算法(PPO)详解
目录
PPO算法介绍
近端策略优化、PPO(Proximal Policy Optimization)是一种强化学习算法,设计的目的是在复杂任务中既保证性能提升,又让算法更稳定和高效。以下用通俗易懂的方式介绍其核心概念和流程。
1. 背景
PPO 是 OpenAI 在 2017 年提出的一种策略优化算法,专注于简化训练过程,克服传统策略梯度方法(如TRPO)的计算复杂性,同时保证训练效果。
- 问题:在强化学习中,直接优化策略会导致不稳定的训练,模型可能因为过大的参数更新而崩溃。
- 解决方案:PPO通过限制策略更新幅度,使得每一步训练都不会偏离当前策略太多,同时高效利用采样数据。
2. PPO 的核心思想
PPO 的目标是通过以下方式改进策略梯度优化:
- 限制策略更新幅度,防止策略过度偏离。
- 使用优势函数
来评价某个动作的相对好坏。
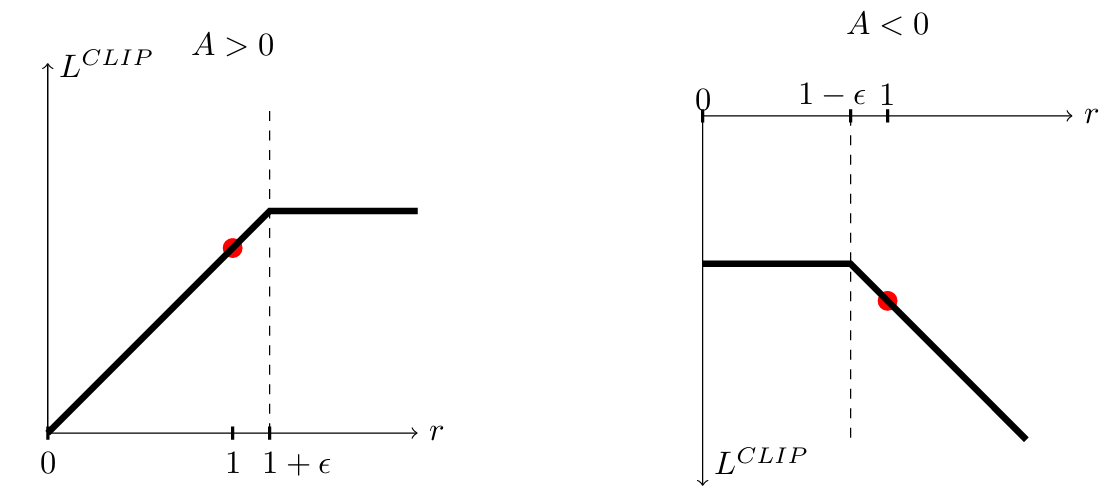
优化目标
PPO 的目标函数如下:
其中:
-
:概率比率
它表示新策略和旧策略在同一状态下选择动作的概率比值。
-
:优势函数 通过以下公式计算:
或者用广义优势估计(GAE)的方法近似。
-
剪辑操作
: 将
内,防止策略变化过大。
3. 为什么 PPO 很强?
- 简洁性: 比 TRPO(Trust Region Policy Optimization)更简单,无需二次优化。
- 稳定性: 使用剪辑机制防止策略更新过度。
- 高效性: 利用采样数据多次训练,提高样本利用率。
4. PPO 的直观类比
假设你是一个篮球教练,训练球员投篮:
- 如果每次训练完全改变投篮动作,球员可能会表现失常(类似于策略更新过度)。
- 如果每次训练动作变化太小,可能很难进步(类似于更新不足)。
- PPO 的剪辑机制就像一个“适度改进”的规则,告诉球员在合理范围内调整投篮动作,同时评估每次投篮的表现是否优于平均水平。
PPO算法的流程推导及数学公式
PPO(Proximal Policy Optimization)也是一种策略优化算法,它的核心思想是对策略更新进行限制,使训练更加稳定,同时保持效率。以下是其数学公式推导和整体流程:
1. 算法目标
强化学习的核心目标是优化策略 ,最大化累积奖励 R 。策略梯度方法(如REINFORCE)直接优化策略,但更新过大可能导致不稳定。为了解决这个问题,PPO通过引入限制更新幅度的机制,保证策略的稳定性。
目标是优化以下期望:
通过梯度上升法更新策略。
2. PPO的概率比率
PPO在优化过程中引入了概率比率,用于衡量新旧策略的差异:
:新策略对动作
的概率。
:旧策略对动作
这个比率表示策略变化的程度。
3. 优化目标
为了限制策略的更新幅度,PPO引入了剪辑目标函数:
PPO的目标是找到一个折中:在保持改进的同时防止策略变化过大。
4. 值函数优化
PPO不仅优化策略,还同时更新值函数,通过最小化均方误差来更新:
:当前状态的值函数预测。
:累计回报。
这个损失函数使得Critic能够更准确地估计状态值。
5. 策略熵正则化
为了鼓励策略的探索,PPO引入了熵正则化项:
:策略的熵,表示策略分布的不确定性。
- 增加熵可以防止策略过早收敛到局部最优。
6. 总损失函数
PPO结合策略损失、值函数损失和熵正则化项,形成总损失函数:
和
:权重系数,用于平衡策略优化、值函数更新和熵正则化。
7. PPO 算法流程
PPO 可以简化为以下步骤:
-
采样: 使用当前策略
与环境交互,收集状态
、动作
。
-
计算优势函数:
评估某个动作
利用 -
计算概率比率
-
策略更新:
如果更新过大(超出剪辑范围到
),会被惩罚。
保证更新幅度适中,既不太保守,也不太激进。 -
值函数更新: 用以下损失函数优化值函数
:
-
重复以上步骤: 通过多轮迭代,使策略逐步优化,直到收敛。
8.PPO算法的关键
PPO的关键公式和目标可以概括如下:
- 核心目标: 优化策略,使
的改进在限制范围内。
- 限制更新幅度: 通过剪辑函数
,避免策略更新过大导致不稳定。
- 同时优化值函数: 通过
,提高Critic的预测精度。
- 探索与稳定性平衡: 通过
,鼓励策略探索。
这种设计使得PPO在训练过程中高效且稳定,是目前强化学习中的常用算法之一。
[Python] PPO算法的代码实现
以下是使用 PyTorch 实现 PPO(Proximal Policy Optimization)算法的完整代码
项目代码我已经放入GitCode里面,可以通过下面链接跳转:🔥
后续相关单智能体强化学习算法也会不断在【强化学习】项目里更新,如果该项目对你有所帮助,请帮我点一个星星✨✨✨✨✨,鼓励分享,十分感谢!!!
若是下面代码复现困难或者有问题,也欢迎评论区留言。
"""《PPO算法的代码》
时间:2024.12
环境:gym
作者:不去幼儿园
"""
import torch # Import PyTorch, a popular machine learning library
import torch.nn as nn # Import the neural network module
import torch.optim as optim # Import optimization algorithms
from torch.distributions import Categorical # Import Categorical for probabilistic action sampling
import numpy as np # Import NumPy for numerical computations
import gym # Import OpenAI Gym for environment simulation
逐行解释 PPO 代码和公式
以下是对实现的 PyTorch PPO 算法代码 的详细解释,逐行结合公式解析:
1. Actor-Critic 神经网络
# Define Actor-Critic Network
class ActorCritic(nn.Module): # Define the Actor-Critic model
def __init__(self, state_dim, action_dim): # Initialize with state and action dimensions
super(ActorCritic, self).__init__() # Call parent class constructor
self.shared_layer = nn.Sequential( # Shared network layers for feature extraction
nn.Linear(state_dim, 128), # Fully connected layer with 128 neurons
nn.ReLU() # ReLU activation function
)
self.actor = nn.Sequential( # Define the actor (policy) network
nn.Linear(128, action_dim), # Fully connected layer to output action probabilities
nn.Softmax(dim=-1) # Softmax to ensure output is a probability distribution
)
self.critic = nn.Linear(128, 1) # Define the critic (value) network to output state value
def forward(self, state): # Forward pass for the model
shared = self.shared_layer(state) # Pass state through shared layers
action_probs = self.actor(shared) # Get action probabilities from actor network
state_value = self.critic(shared) # Get state value from critic network
return action_probs, state_value # Return action probabilities and state value
shared_layer: 将状态 s 映射到一个隐层表示,使用 ReLU 激活函数。actor: 输出策略,表示在状态 s 下选择动作 a 的概率分布。使用 Softmax 确保输出是概率。
critic: 输出状态值函数 V(s) ,表示在状态 s 下的预期累计奖励。
其中 是共享层的输出,
和
是权重矩阵。
2. Memory 类
# Memory to store experiences
class Memory: # Class to store agent's experience
def __init__(self): # Initialize memory
self.states = [] # List to store states
self.actions = [] # List to store actions
self.logprobs = [] # List to store log probabilities of actions
self.rewards = [] # List to store rewards
self.is_terminals = [] # List to store terminal state flags
def clear(self): # Clear memory after an update
self.states = [] # Clear stored states
self.actions = [] # Clear stored actions
self.logprobs = [] # Clear stored log probabilities
self.rewards = [] # Clear stored rewards
self.is_terminals = [] # Clear terminal state flags用于存储一个 episode 的经验数据:
states: 状态、actions: 动作、logprobs: 动作的对数概率、rewards: 即时奖励 、is_terminals: 是否为终止状态(布尔值)
作用:为后续策略更新提供样本数据。
3. PPO 初始化
# PPO Agent
class PPO: # Define the PPO agent
def __init__(self, state_dim, action_dim, lr=0.002, gamma=0.99, eps_clip=0.2, K_epochs=4):
self.policy = ActorCritic(state_dim, action_dim).to(device) # Initialize the Actor-Critic model
self.optimizer = optim.Adam(self.policy.parameters(), lr=lr) # Adam optimizer for parameter updates
self.policy_old = ActorCritic(state_dim, action_dim).to(device) # Copy of the policy for stability
self.policy_old.load_state_dict(self.policy.state_dict()) # Synchronize parameters
self.MseLoss = nn.MSELoss() # Mean Squared Error loss for critic updates
self.gamma = gamma # Discount factor for rewards
self.eps_clip = eps_clip # Clipping parameter for PPO
self.K_epochs = K_epochs # Number of epochs for optimizationpolicy: 当前策略网络,用于输出动作概率和状态值。policy_old: 旧策略网络,用于计算概率比率gamma: 折扣因子,用于奖励的时间衰减。eps_clip: 剪辑阈值,用于限制策略更新幅度。
4. 动作选择
def select_action(self, state, memory):
state = torch.FloatTensor(state).to(device) # Convert state to PyTorch tensor
action_probs, _ = self.policy_old(state) # Get action probabilities from old policy
dist = Categorical(action_probs) # Create a categorical distribution
action = dist.sample() # Sample an action from the distribution
memory.states.append(state) # Store state in memory
memory.actions.append(action) # Store action in memory
memory.logprobs.append(dist.log_prob(action)) # Store log probability of the action
return action.item() # Return action as a scalar valueaction_probs: 当前策略下的动作概率dist.sample(): 按照概率分布采样动作log_prob(action): 记录动作的对数概率。
5. 策略更新
def update(self, memory):
# Convert memory to tensors
old_states = torch.stack(memory.states).to(device).detach() # Convert states to tensor
old_actions = torch.stack(memory.actions).to(device).detach() # Convert actions to tensor
old_logprobs = torch.stack(memory.logprobs).to(device).detach() # Convert log probabilities to tensor
# Monte Carlo rewards
rewards = [] # Initialize rewards list
discounted_reward = 0 # Initialize discounted reward
for reward, is_terminal in zip(reversed(memory.rewards), reversed(memory.is_terminals)):
if is_terminal: # If the state is terminal
discounted_reward = 0 # Reset discounted reward
discounted_reward = reward + (self.gamma * discounted_reward) # Compute discounted reward
rewards.insert(0, discounted_reward) # Insert at the beginning of the list
rewards = torch.tensor(rewards, dtype=torch.float32).to(device) # Convert rewards to tensor
rewards = (rewards - rewards.mean()) / (rewards.std() + 1e-7) # Normalize rewards6. Surrogate Loss
# Update for K epochs
for _ in range(self.K_epochs):
# Get action probabilities and state values
action_probs, state_values = self.policy(old_states) # Get action probabilities and state values
dist = Categorical(action_probs) # Create a categorical distribution
new_logprobs = dist.log_prob(old_actions) # Compute new log probabilities of actions
entropy = dist.entropy() # Compute entropy for exploration
# Calculate ratios
ratios = torch.exp(new_logprobs - old_logprobs.detach()) # Compute probability ratios
# Advantages
advantages = rewards - state_values.detach().squeeze() # Compute advantages
# Surrogate loss
surr1 = ratios * advantages # Surrogate loss 1
surr2 = torch.clamp(ratios, 1 - self.eps_clip, 1 + self.eps_clip) * advantages # Clipped loss
loss_actor = -torch.min(surr1, surr2).mean() # Actor loss
# Critic loss
loss_critic = self.MseLoss(state_values.squeeze(), rewards) # Critic loss
# Total loss
loss = loss_actor + 0.5 * loss_critic - 0.01 * entropy.mean() # Combined loss
# Update policy
self.optimizer.zero_grad() # Zero the gradient buffers
loss.backward() # Backpropagate loss
self.optimizer.step() # Perform a parameter update
# Update old policy
self.policy_old.load_state_dict(self.policy.state_dict()) # Copy new policy parameters to old policy- 比率:
- 策略损失:
- 价值函数损失:
- 熵正则化:
7.主程序
# Hyperparameters
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # Use GPU if available
env = gym.make("CartPole-v1") # Initialize CartPole environment
state_dim = env.observation_space.shape[0] # Dimension of state space
action_dim = env.action_space.n # Number of possible actions
lr = 0.002 # Learning rate
gamma = 0.99 # Discount factor
eps_clip = 0.2 # Clipping parameter
K_epochs = 4 # Number of epochs for policy update
max_episodes = 1000 # Maximum number of episodes
max_timesteps = 300 # Maximum timesteps per episode
# PPO Training
ppo = PPO(state_dim, action_dim, lr, gamma, eps_clip, K_epochs) # Initialize PPO agent
memory = Memory() # Initialize memory
for episode in range(1, max_episodes + 1): # Loop over episodes
state = env.reset() # Reset environment
total_reward = 0 # Initialize total reward
for t in range(max_timesteps): # Loop over timesteps
action = ppo.select_action(state, memory) # Select action using PPO
state, reward, done, _ = env.step(action) # Take action and observe results
memory.rewards.append(reward) # Store reward in memory
memory.is_terminals.append(done) # Store terminal state flag in memory
total_reward += reward # Accumulate total reward
if done: # If episode is done
break # Exit loop
ppo.update(memory) # Update PPO agent
memory.clear() # Clear memory
print(f"Episode {episode}, Total Reward: {total_reward}") # Print episode statistics
env.close() # Close the environment[Notice] 代码解释
Actor-Critic 网络结构:
ActorCritic 模型通过共享层生成动作概率和状态值。
PPO 的优化目标:
使用裁剪的目标函数限制策略更新幅度,避免过度更新。
state_values 通过 Critic 网络提供状态价值的估计。
内存存储:
Memory 用于存储每一轮的状态、动作、奖励和终止标志。
策略更新:
通过多个 epoch 更新,计算 优势函数 和 裁剪后的策略梯度。
奖励归一化:
使用标准化方法对奖励进行处理,以加快收敛。
训练循环:
PPO 从环境中采样,更新策略,打印每一集的总奖励。
# 环境配置
Python 3.11.5
torch 2.1.0
torchvision 0.16.0
gym 0.26.2由于博文主要为了介绍相关算法的原理和应用的方法,缺乏对于实际效果的关注,算法可能在上述环境中的效果不佳或者无法运行,一是算法不适配上述环境,二是算法未调参和优化,三是没有呈现完整的代码,四是等等。上述代码用于了解和学习算法足够了,但若是想直接将上面代码应用于实际项目中,还需要进行修改。
总结
PPO 的关键是通过限制策略的变化范围(剪辑),让优化更加稳定,同时通过优势函数引导策略改进,充分利用采样数据。这种平衡使得 PPO 成为许多强化学习任务的默认算法。
更多强化学习文章,请前往:【强化学习(RL)】专栏
PPO算法、TRPO算法 和 A3C算法对比
以下是 PPO算法、TRPO算法 和 A3C算法 的区别分析:
| 特性 | PPO (Proximal Policy Optimization) | TRPO (Trust Region Policy Optimization) | A3C (Asynchronous Advantage Actor-Critic) |
|---|---|---|---|
| 核心思想 | 使用裁剪的目标函数,限制策略更新幅度,保持稳定性和效率。 | 限制策略更新的步幅(Trust Region),通过二次约束优化确保稳定性。 | 通过异步多线程运行环境并行采样和训练,降低方差并加快收敛速度。 |
| 优化目标函数 | 引入剪辑机制 | 通过KL散度限制策略更新 | 优化策略梯度 |
| 更新方式 | 同步更新,支持多轮迭代更新样本数据以提高效率。 | 同步更新,通过优化约束的目标函数严格限制更新步长。 | 异步更新,多个线程独立采样和更新全局模型。 |
| 计算复杂度 | 低,计算简单,使用裁剪避免复杂的二次优化问题。 | 高,涉及二次优化问题,计算复杂,资源需求较大。 | 较低,依赖异步线程并行计算,资源利用率高。 |
| 样本利用率 | 高效,可重复利用采样数据进行多轮梯度更新。 | 高效,严格优化目标,提升了样本效率。 | 较低,因为每个线程独立运行,可能导致数据重复和冗余。 |
| 实现难度 | 中等,使用简单的裁剪方法,适合大多数场景。 | 高,涉及复杂的约束优化和实现细节。 | 较低,直接异步实现,简单易用。 |
| 收敛速度 | 快,因裁剪机制限制更新幅度,能快速稳定收敛。 | 慢,因严格的步幅限制,收敛稳定但需要较多训练迭代。 | 快,因多线程并行采样,能够显著减少训练时间。 |
| 稳定性 | 高,裁剪机制限制过大更新,避免不稳定行为。 | 高,严格限制更新步幅,保证策略稳定改进。 | 较低,异步更新可能导致收敛不稳定(如策略冲突)。 |
| 应用场景 | 广泛使用,适合大规模环境或复杂问题。 | 适合需要极高稳定性的场景,如机器人控制等。 | 适合资源受限的场景或需要快速实验的任务,如强化学习基准测试。 |
| 优点 | 简单易实现,收敛快,稳定性高,是主流强化学习算法。 | 理论支持强,更新步幅严格受控,策略非常稳定。 | 异步更新高效,能够充分利用多线程资源,加速训练。 |
| 缺点 | 理论支持弱于TRPO,可能过于保守。 | 实现复杂,计算资源需求高,更新速度慢。 | 异步更新可能导致训练不稳定,样本利用率较低。 |
| 论文来源 | Schulman et al., "Proximal Policy Optimization Algorithms" (2017) | Schulman et al., "Trust Region Policy Optimization" (2015) | Mnih et al., "Asynchronous Methods for Deep Reinforcement Learning" (2016) |
三种算法的对比总结:
- PPO 是 TRPO 的改进版:PPO 使用简单的裁剪机制代替了 TRPO 的二次优化,显著降低了实现复杂度,同时保持了良好的稳定性和效率。
- A3C 的并行化设计:A3C 的核心是通过多线程异步更新提升效率,但其稳定性略低于 PPO 和 TRPO。
- 实用性:PPO 因其简单、稳定、高效的特点,已成为强化学习领域的主流算法;TRPO 更适合需要极高策略稳定性的任务;A3C 在资源受限的场景下表现优异。
博客都是给自己看的笔记,如有误导深表抱歉。文章若有不当和不正确之处,还望理解与指出。由于部分文字、图片等来源于互联网,无法核实真实出处,如涉及相关争议,请联系博主删除。如有错误、疑问和侵权,欢迎评论留言联系作者,或者添加VX:Rainbook_2,联系作者。✨



















 1245
1245

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











