







原文链接:https://arxiv.org/abs/1912.03458 CVPR 2020
该论文是在CondConv的基础上进行改进的。对CondConv生成权重部分进行改进,用SE(将最后的sigmod替换成softmax)注意力生成不同卷积核的权重。
动态卷积不是每层使用单个卷积核,而是根据输入相关的注意力动态聚合多个并行卷积核。
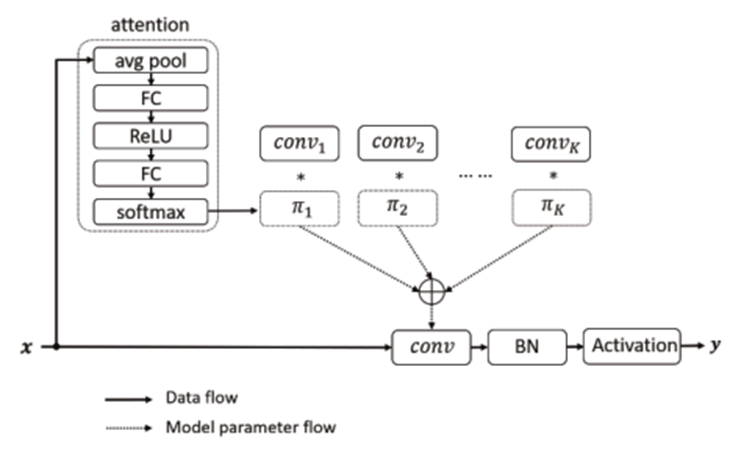
训练策略:
- 注意力取值限制在0与1之间,同时所有注意力的和为1。即0<
<1,
;
- 早期训练时期的注意力要近乎一致。
参考文章: Dynamic Convolution: Attention over Convolution Kernels_JuyongJiang的博客-CSDN博客















 1133
1133











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









