







Motivation
现在的诸多task中,普遍需要capacity较大的模型,而随着模型参数的不断增加,计算成本也越来越高。对于一些对latency有较高要求的task,显然是一种挑战。在传统的CNN网络中,一旦训练完成,所有的kernal参数就固定了。对于任意的输入,所有的kernal都对他们同等对待。所以为了提高模型的capacity,大多数方法堆叠卷积层或者增加卷积层的channel数(即增加深度和广度),这种做法虽然一定程度上可以提升模型performance,但显然会造成 computationally expensive。
所以为了压缩模型,在增加模型capacity的同时不会增加太多参数和计算量,动态卷积的概念应运而生。动态卷积的出发点就是,当训练结束后,kernal不再是一个定值,而是一个由input决定的变量。因此kernal相当于一个以input为自变量的function;换句话说就是对于不同的input,都会通过计算得到各自不同的卷积核参数。这种做法相当于变相的增加了模型的capacity,与此同时模型参数和计算量是非常小的。
CondConv
论文名称:CondConv: Conditionally Parameterized Convolutions for Efficient Inference
链接:https://arxiv.org/abs/1904.04971
与其叫条件卷积,私认为动态卷积更加贴切。在CondConv中,通过下述公式得到kernal的参数:
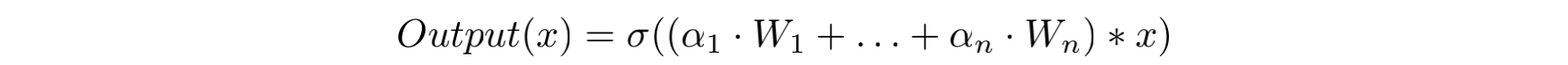
这里
x
x
x表示上一个layer的输出,
n
n
n表示这一层Condconv Layer有
n
n
n个expert(expert就是该层的卷积核W),
σ
\sigma
σ表示激活函数,
α
i
=
r
i
(
x
)
\alpha_{i}=r_{i}(x)
αi=ri(x)表示一个样本依赖的加权参数。
所以一个CondConv层的卷积核参数的由来,就是通过上述的线性组合公式。整个流程可以概括为:依赖于输入
x
x
x,在卷积操作之前,通过routing函数
r
i
(
x
)
r_{i}(x)
ri(x)计算出每一个expert前面的系数
α
i
\alpha_{i}
αi,再通过线性组合,得到CondConv层最终的kernal,最后与输入
x
x
x做卷积,并进行activation。在这里,routing weight的计算公式如下:
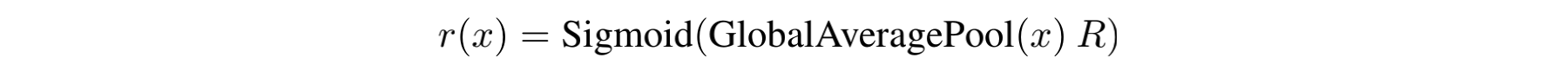
对于输入
x
x
x,首先做GlobalAveragePooling,随后右乘一个矩阵R(该矩阵的目的是将维度映射到n个expert上面,以实现后续的线性组合),最后通过sigmoid将每一个维度上的权值规约到[0,1]区间。因此,根据输入
x
x
x的不同,就会得到不同的routing weight向量,进而CondConv层的kernal也各有差异。
CondConv的流程如下图(a)所示:
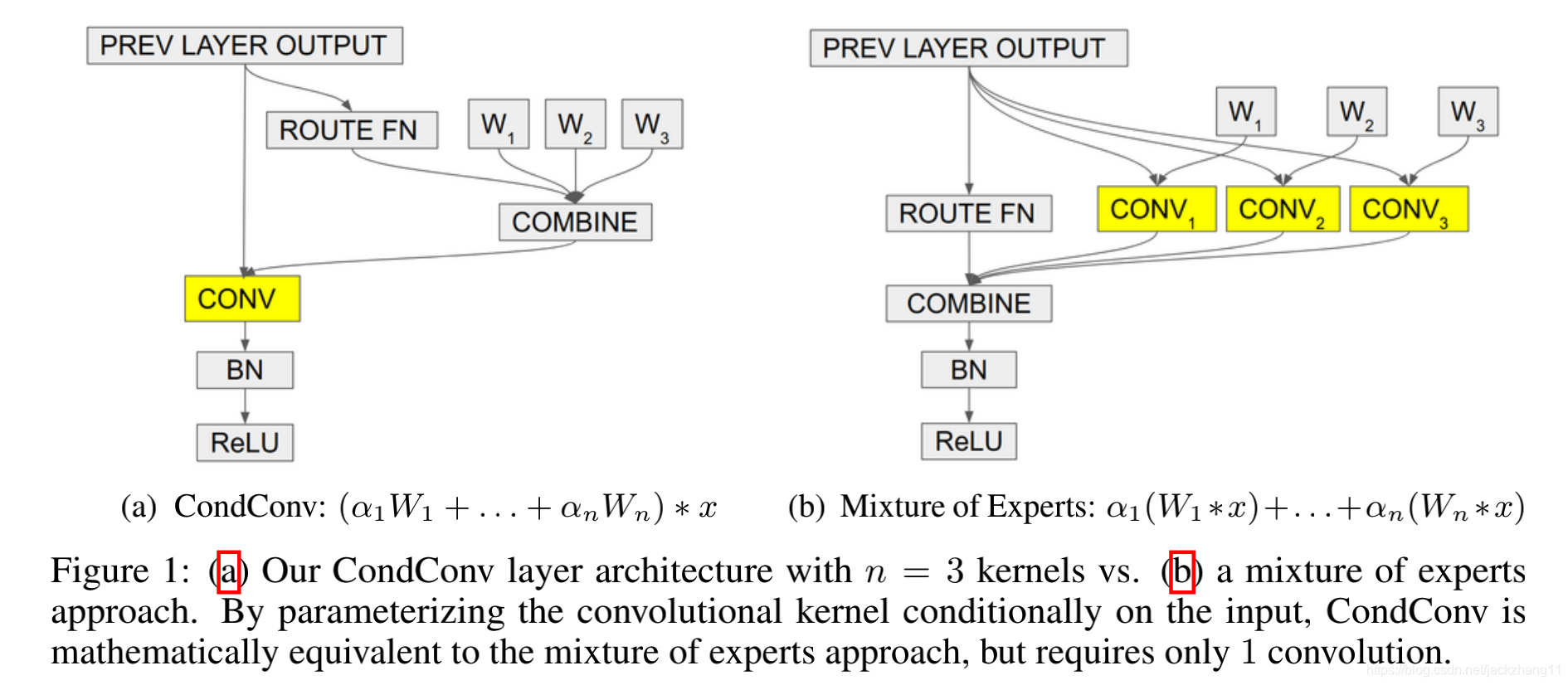
上图(a)中所示的CondConv与图(b)都是将routing weight与expert做线性组合,但还是存在一些区别:CondConv只需要做一次卷积,而图(b)的方式要做n次(expert的数目)卷积。我们知道,直观上expert数目越多,模型的performace越好。因此图(a)的计算量会比图(b)少很多,计算开销大大减少,体现了CondConv这种设计的优越性。
实验部分感兴趣的话可以看论文,我在这里只放一组很有意思的实验结果:
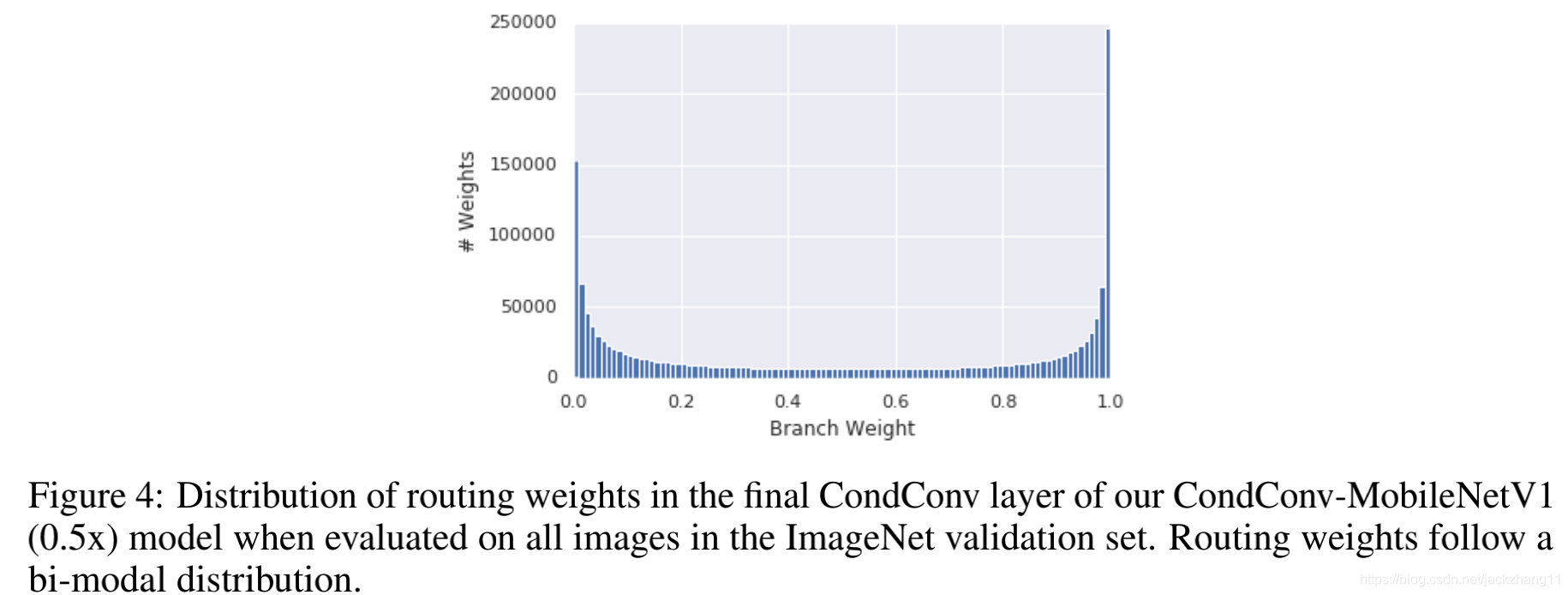
通过上图发现,绝大部分的routing weight都在0或1附近,也就是说expert是sparse activated。这里谈一下我的看法,这些expert很可能编码了不同实例的特征,每一个expert对应了一个characteristic,只有拥有这个特征的input输入进来时,才会对该expert进行激活,随后作为filter,能够更好的进行特征提取。因为最近实例分割的论文有几篇用到动态卷积,思想和这个比较类似。
总而言之,CondConv提出了这类动态卷积的思想,challenge了「所有输入要共享卷积核参数」的观点。由于每个layer只需要做一次卷积,CondConv非常高效。同时突出了一个非常重要的研究问题,即如何更好的表示和利用样本的相关性来提升模型的performace。
DynamicConv
论文名称:Dynamic Convolution: Attention over Convolution Kernels
链接:https://arxiv.org/pdf/1912.03458.pdf
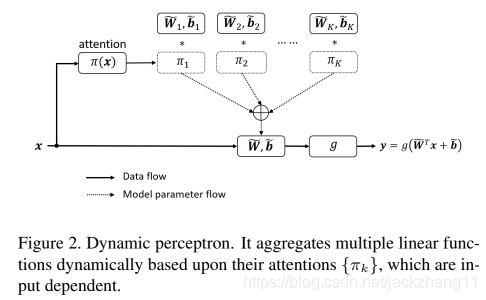
文章从动态感知器出发,类比到动态卷积上面。首先,动态感知器可由下述公式概括:
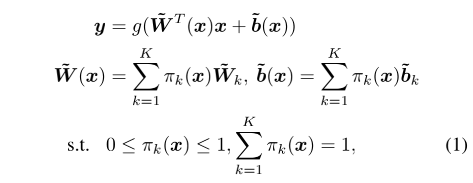
其中
π
k
\pi_{k}
πk表示第k个线性函数
W
~
k
T
x
+
b
~
k
\widetilde{W}_{k}^{T}x+\widetilde{b}_{k}
W
kTx+b
k的attetion权重,这个权重在输入
x
x
x不同的情况下是不同的。因此在给定input的情况下,动态感知器代表了该input的最佳线性函数组合。又因为该模型是非线性的,所以动态感知器拥有更强大的representation能力。
而得到attention weight这一过程计算开销是非常小的,远小于weight与输入之间的矩阵乘法,如下式:
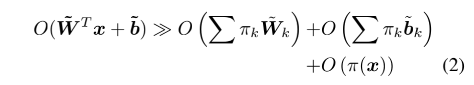
因此,动态感知器在提升模型capacity进而提升模型表示能力的同时,并没有额外增加计算开销。
接下来推广到动态卷积DynamicConv,其实和动态感知器的思想是非常相似的,如下图:
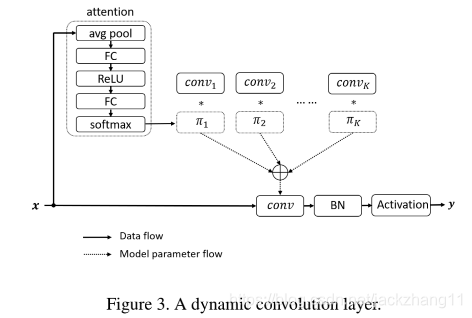
给某个Layer设置
K
K
K个尺度和通道数相同的kernal,通过各自的attention权重
π
k
\pi_{k}
πk进行融合,从而得到该层的卷积核参数。计算
π
k
(
x
)
\pi_{k}(x)
πk(x)的过程如图中虚线方框所示,首先做GlobalAvgPooling,得到全局Spatial特征,再通过两个FC层映射到
K
K
K的维度,最后做softmax归一化。这样得到的
K
K
K个attention权重就可以分配给该层的
K
K
K个kernal。这里与SENet不同的是,SENet是在channel层面的attention,而DynamicConv是以整个kernal为一个被attention的对象。
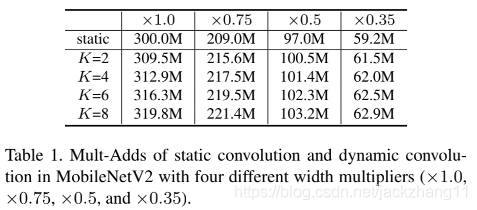
再关注一下计算复杂度:假设feature map的大小为
H
∗
W
H*W
H∗W,kernal的size为
D
k
∗
D
k
D_{k}*D_{k}
Dk∗Dk,
C
i
n
C_{in}
Cin和
C
o
u
t
C_{out}
Cout表示输入通道数和输出通道数。所以在计算attention权重时额外增加的计算量为
H
W
C
i
n
+
C
i
n
2
/
4
+
C
i
n
K
/
4
HWC_{in}+C_{in}^{2}/4+C_{in}K/4
HWCin+Cin2/4+CinK/4(除以4是因为第一层FC将维度从
C
i
n
C_{in}
Cin缩小到四分之一),在kernal融合时额外增加的计算量为
K
C
i
n
C
o
u
t
D
k
2
+
K
C
o
u
t
KC_{in}C_{out}D_{k}^{2}+KC_{out}
KCinCoutDk2+KCout。这两部分额外开销都远小于静态卷积计算的
H
W
C
i
n
C
o
u
t
D
k
2
HWC_{in}C_{out}D_{k}^{2}
HWCinCoutDk2,因此只要当
K
<
<
H
W
K<<HW
K<<HW,这部分额外开销是非常efficient的,根据上表可以直观看出。
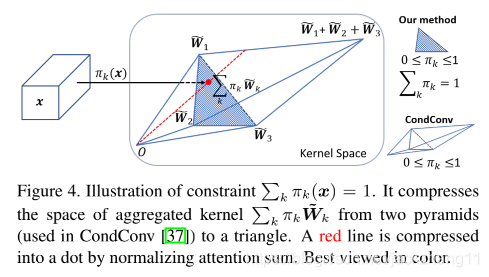
训练过程中要关注两个问题:(1)通过softmax把所有的attention weight限定在[0,1]内,并且sum为1。这样做就把kernal融合的空间压缩为一个三角形空间,相比于CondConv的两个pyramid空间,更适合进行优化;(2)由于attention权重大多数是sparse的(与CondConv的实验异曲同工),所以大多数的kernal得不到训练,为解决这个问题,作者提出了下述公式进行平滑:
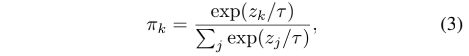
这里
z
k
z_{k}
zk表示第二层FC的输出。举个栗子方便理解:假设该层有K=2个kernal,
z
z
z输出的结果为(0.01, 0.99),那么在反向传播时第二个kernal可以得到更好地学习,而第一个kernal的参数学习会被抑制。所以采用上述公式,假如超参数
τ
=
30
\tau=30
τ=30,那么此时
π
1
\pi_{1}
π1的值就比之前不做平滑的大很多。因为
z
1
z_{1}
z1即使缩小了30被,经指数函数仍然是趋近于1;而
z
2
z_{2}
z2一旦缩小30倍,attention就从
e
0.99
e^{0.99}
e0.99下降成了
e
0.03
e^{0.03}
e0.03,这个削弱幅度是巨大的。因此平滑操作有利于所有的kernel进行参数的迭代更新。
实验太多就不贴了,感兴趣的可以阅读原文细品~
总结
两篇文章都是动态卷积相关的,在不增加计算开销的同时,增大模型的capacity进而提升模型performace。动态卷积的思想就是根据不同的input,动态生成不同的卷积核系数,然后自适应地做kernel的融合,从而能够更好地进行特征提取和表示,打破了kernal对所有输入样例一视同仁的传统。总体上换汤不换药,都可以在经典的网络中plug-in,大致都属于kernal层面的attention,只有实现细节上稍有不同(总感觉无非就是求attention系数计算的不同,CondConv用Sigmoid做约束,而DynamicConv采用了softmax做归一,导致融合的space不一样)。目前我只看到了Google的CondConv代码是开源的,说一句谷歌大法好。
最近还有几篇动态卷积相关的文章:
DyNet: Dynamic Convolution for Accelerating Convolutional Neural Networks
Revisiting Dynamic Convolution via Matrix Decomposition (ICLR21)
后一篇好像很牛批的样子,抽空看下。

















 5733
5733

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









