








各位大佬们好!我是小白,前两天接了一个单子,根据客户给出的公司名单去招标网获取公司的所有招标数据,因为客户给的实在太多了,小白也就勉为其难的答应了,做完之后连夜将自己的过程记录的下来跟大家分享一下,希望对一下刚接触的朋友提供一些帮助,也希望大佬们的指正,也欢迎加入我的公zhong号:小白的大数据之旅,一起交流学习。
本文爆肝3W字,里面每一个步骤都比较详细和清楚,可以认真慢慢观看,因为是临时写的,其实还是有一些不足的地方和需要优化的地方,大家如果有什么建议也可以在评论区讨论哦。祝大家事业有成,学业顺利!
初始化
导入必要的库
首先导入接下来自动化所需要的库
from selenium.webdriver.common.by import By
from time import sleep
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import pandas as pd
import requests
from sqlalchemy import create_engine
import pymysql
- selenium.webdriver.common.by import By:
Selenium是一个用于Web应用程序自动化测试的工具。By类提供了一系列用于定位页面元素的方法,如通过ID、名称、XPath、CSS选择器等。这使得编写用于自动化浏览器操作的脚本变得更加容易。 - from time import sleep:
sleep函数用于使程序暂停执行指定的秒数。在自动化测试中,它常被用来等待页面加载完成或元素出现,以确保脚本的稳定性和准确性。 - from selenium import webdriver:
webdriver是Selenium的核心组件之一,它提供了与浏览器交互的接口。通过它,你可以控制浏览器执行各种操作,如打开网页、点击按钮、填写表单等。 - from selenium.webdriver.chrome.options import Options:
Options类允许你配置Chrome浏览器的启动选项,如设置无头模式(不打开浏览器界面)、禁用图片加载、设置代理等。这对于自动化测试中的浏览器行为定制非常有用。 - import pandas as pd:
Pandas是一个强大的数据处理和分析库。它提供了易于使用的数据结构和数据分析工具,使得数据清洗、转换、分析和可视化变得更加简单和高效。 - import requests:
Requests是一个用于发送HTTP请求的Python库。它简化了与Web服务的交互,使得发送GET、POST等请求以及处理响应变得直观和简单。 - from sqlalchemy import create_engine:
SQLAlchemy是一个SQL工具包和对象关系映射(ORM)库。create_engine函数用于创建一个数据库引擎,该引擎可以与数据库建立连接,并执行SQL语句。它支持多种数据库后端,如MySQL、PostgreSQL等。 - import pymysql:
PyMySQL是一个纯Python实现的MySQL客户端。它允许你通过Python代码与MySQL数据库进行交互,执行SQL语句、管理数据库连接等。与SQLAlchemy结合使用时,可以更方便地进行数据库操作。
定义数据库连接
首先定义一下数据库的连接,方便后面使用Pandas进行数据库的访问和写入
adb_param = {
'DBHOST': 'localhost',
'DBUSER': 'root',
'DBPASS': 'xxxx',
'DBNAME': 'ectouch',
'PORT': 3306}
这里定义了一个字典adb_param,包含了连接MySQL数据库所需的所有参数。其中,DBHOST是数据库主机地址,DBUSER是数据库用户名,DBPASS是数据库密码,DBNAME是数据库名,PORT是数据库端口号。
conn=create_engine(
'mysql+pymysql://{}:{}@{}:{}/{}'
.format(adb_param['DBUSER'],
adb_param['DBPASS'],
adb_param['DBHOST'],
adb_param['PORT'],
adb_param['DBNAME'])
)
这里使用了一个格式化字符串,并通过.format方法将adb_param字典中的值插入到相应的位置。这样,就构造出了一个完整的MySQL数据库连接字符串。这个连接字符串遵循了dialect+driver://username:password@host:port/database的格式,其中dialect是数据库方言(这里是mysql),driver是数据库驱动(这里是pymysql),username是数据库用户名,password是数据库密码,host是数据库主机地址,port是数据库端口号,database是数据库名。
最后,将构造好的连接字符串传递给create_engine函数,创建了一个数据库连接引擎。这个引擎可以用于执行SQL语句、管理数据库连接等。
这里只是做一个爬虫项目,如果在企业级别的实战中,最好是把账户,密码这些都放大配置文件中。
设置参数关闭自动化检测
chrome_options = Options()
# 关闭自动化检测
chrome_options.add_experimental_option('excludeSwitches', ['enable-automation'])
# 创建WebDriver对象,指定Chrome浏览器和ChromeOptions
driver = webdriver.Chrome(options=chrome_options)
数据库操作
表查询
首先我们先定义一个函数find_all()该函数用来从数据库中获取数据,因为在获取数据的时候,我们把获取到的每一个公司的情况都记录到数据库表中,这样方便最后能看到都有哪些表获取到了,那些表没有获取到,这样重新启动程序处理因为特殊情况获取失败的公司的时候,可以直接跳过已经处理完的公司
def find_all(adb_param):
db = pymysql.connect(
host=adb_param['DBHOST'],
user=adb_param['DBUSER'],
password=adb_param['DBPASS'],
database=adb_param['DBNAME'],
port=adb_param['PORT']
)
cursor = db.cursor()
#select t1.`index`,t1.allinpay_order_sn,t1.amount,t1.description from tonglian_st2 as t1
cursor.execute('select company_name from company')
data = cursor.fetchall()
data = [row[0] for row in data]
return data
-
find_all 函数接收一个参数 adb_param,这是一个字典,包含了连接MySQL数据库所需的关键信息:主机地址(DBHOST)、用户名(DBUSER)、密码(DBPASS)、数据库名(DBNAME)以及端口号(PORT)。
-
函数首先利用 pymysql.connect 方法与数据库建立连接,所需参数均从 adb_param 字典中获取。连接成功后,会返回一个数据库连接对象 db。
-
随后,通过 db.cursor() 方法创建一个游标对象 cursor。游标在数据库操作中扮演着重要角色,它允许你执行SQL语句并获取结果。
-
接着,cursor.execute 方法被用来执行一个SQL查询语句,这里的查询是 select company_name from company,目的是从 company 表中检索所有公司的名称。
-
执行查询后,cursor.fetchall 方法被调用以获取查询结果的完整列表。这个方法会返回一个列表,其中每个元素都是一个包含查询结果行的元组。由于我们只关心 company_name 字段,因此使用列表推导式 [row[0] for row in data] 对结果进行处理,提取出每行结果中的第一个元素(即公司名称),并组成一个新的列表。
表插入
创建表
首先在数据库中创建一个表,这个表的作用是记录已经操作完成的公司名称,逐渐自增
CREATE TABLE company (
id INT AUTO_INCREMENT,
company_name VARCHAR(50),
PRIMARY KEY (id) -- 这里指定了主键,InnoDB会自动为其创建聚集索引
);
定义插入函数
定义一个数据库插入函数,将成功的表插入到数据库中
def insert_at(sql,adb_param):
try:
db = pymysql.connect(
host=adb_param['DBHOST'],
user=adb_param['DBUSER'],
password=adb_param['DBPASS'],
database=adb_param['DBNAME'],
port=adb_param['PORT']
)
#print(sql)
cursor = db.cursor()
cursor.execute(sql)
db.commit()
except Exception as e :
print(e)
print(sql)
return
- 数据库连接:函数首先尝试使用pymysql.connect方法和adb_param字典中的信息建立数据库连接。
- SQL执行:连接成功后,函数创建一个游标对象cursor,并使用cursor.execute(sql)执行传入的SQL语句。执行完毕后,通过db.commit()提交事务,确保更改被保存到数据库中(如果SQL语句是插入、更新或删除操作的话)。
- 异常处理:如果在执行SQL语句或提交事务过程中发生异常,函数会捕获这个异常,并打印异常信息和传入的SQL语句。然后,函数通过return语句提前结束,不会执行后续的代码。需要注意的是,这里的return语句后面有一个多余的),这是一个语法错误,应该被移除。
- 游标管理:由于异常处理部分提前返回,如果SQL执行成功,函数会再次创建一个新的游标对象cursor(这里的代码设计存在问题,因为成功执行SQL后不应该再次创建游标,除非有必要执行另一个SQL语句)。然而,由于前面的异常处理可能导致函数提前返回,这个新创建的游标实际上只有在没有异常发生时才会被使用。
- 查询公司名称:无论前面的SQL语句执行成功与否(实际上,由于异常处理的存在,如果失败则函数不会执行到这里),函数都会尝试使用新创建的游标执行一个查询语句,从company表中检索所有公司的名称。
- 结果处理:查询结果通过cursor.fetchall()获取,并使用列表推导式处理成只包含公司名称的列表。
- 返回值:函数返回处理后的公司名称列表。
设置异常处理函数
因为在有一些情况下,每个招标信息的内容都是不固定的,例如项目编号,有的招标信息有,有的招标信息没有,所以要先做好异常处理,如果定位不到指定的元素就给默认是而不是报错
def get_element_text(dr,locator):
"""
尝试获取指定定位器的元素文本,如果不存在则返回空字符串。
:param dr: 每个招标的实例
:param locator: 元素定位器,例如 (By.ID, 'element_id')
:return: 元素文本或空字符串
"""
try:
element = dr.find_element(By.XPATH,locator)
return element.text
except Exception:
return ""
设置报警函数
这一步可有可无,因为我担心有一些写入到数据库失败或者没有找到公司的情况,有这种情况的话就直接通过企业微信向我发送报警,因为要获取的公司很多数据量也很大,我们自己也不可能一直在电脑前面看着,直接挂到后台就行,然后如果程序出现问题直接通过机器人给我们报警就可以了,当然了,大家也可以采用其他方式进行报警提醒
def to_qw_error(mess):
url = "https://qyapi"
headers = {
"Content-Type": "application/json"}
data = {
"msgtype": "text",
"text": {
"content": mess,
"mentioned_mobile_list": ["xxx"]
}
}
result = requests.post(url, headers=headers, json=data)
return
url中写上企业微信的机器人地址
mentioned_mobile_list中写上自己的手机号,用于机器人进行@
该函数接收一个mess参数,该参数是要发送的报错信息
读取公司名称
因为要批量获取指定公司的名称,这些公司名称都放到了Excel文件中,所以要从Excel文件中读取这些公司的名称然后循环去自动化查询
# 读取要查询的公司名称
df = pd.read_excel('公司名称.xlsx')
# 将结果转换成数组
company_lis = df.to_numpy()
打开网页
打开网页之后先停留10秒,因为没有登录
#打开网页
driver.get('https://xunbiaobao.baidu.com/s?q=%E5%8C%97%E4%BA%AC%E6%96%B9%E6%AD%A3%E7%A7%91%E6%8A%80%E4%BF%A1%E6%81%AF%E4%BA%A&tab=0&count')
#等待50秒钟,最好别访问太快
sleep(50)
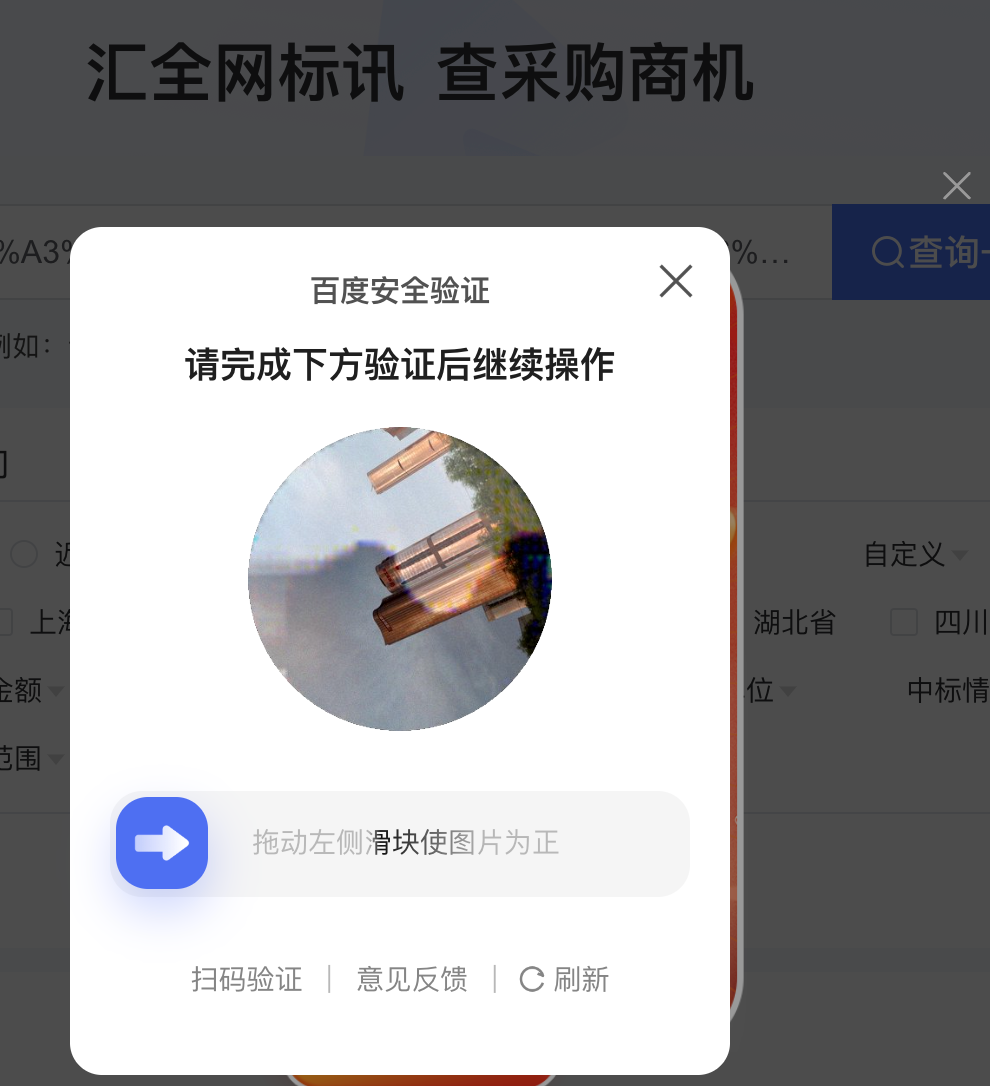
因为没有登录,打开网站的时候可能会出现一些验证,这些验证可能回不相同,这里暂时通过等待50秒之后手动处理验证
例如下面这种验证,但是验证可能不止一种
循环处理公司
开始循环遍历要查询的公司
for company_name in company_lis:
判断是否已处理
通过调用find_all()函数获取已经查询过的公司,然后进行判断,如果已经处理过了就跳过本次循环
data = find_all(adb_param)
#如果已经执行过的公司就不处理了
if company_name[0] in data :
#已经执行过的表=公司不进行处理,跳过本次循环
continue
print(f'当前正在执行公司名称为:{
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 198
198

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











