







写的有点乱,后面有时间再整理吧。
问题概览
在做开始,参考了官网和博客的过程,但是过程略微坎坷,问题主要可以总结为:其代码使用了Tensorflow和Pytorch两个框架,我对Tensorflow不是很熟悉,所以直接按照官网的environments.yml安装了,其中的Tensorflow版本使用的Cuda版本为10(我过程中使用的是10.2).而在实际运算的时候我的电脑显卡3060并不支持Cuda10.2.
在官网的数据预处理的命令:
bash process_data.sh Obama
我无法一次性运行该代码,在官网的issue中可以分开执行
python data_util/process_data.py --id=$1 --step=$2
$1这里取得是Obama(视频名) $2取得是步数(0 1 2 ....)
在步数0 1时我使用的是环境为
- Cuda10.2
- Cudnn 7.8.5
- pytorch3D pytorch3d-0.6.1-py37_cu102_pyt181.tar.bz2
- torch==1.8.1+cu102
- torchvision==0.9.1+cu102
在执行到第2步时出现如下的报错 GeForce RTX 3060 Laptop GPU with CUDA capability sm_86 is not compatible with the current PyTorch :
GeForce RTX 3060 Laptop GPU with CUDA capability sm_86 is not compatible with the current PyTorch installation.
The current PyTorch install supports CUDA capabilities sm_37 sm_50 sm_60 sm_61 sm_70 sm_75 compute_37.
If you want to use the GeForce RTX 3060 Laptop GPU GPU with PyTorch, please check the instructions at https://pytorch.org/get-started/locally/
这是个巨坑,30系显卡暂时不支持CUDA11以下版本,CUDA不支持当前显卡的算力。
在此之后,我环境替换为了
- Cuda11.2
- Cudnn8.1.1
- Pytorch3D pytorch3d-0.6.1-py37_cu111_pyt181.tar.bz2
- torch==1.8.1+cu111
- torchvision==0.9.1+cu111
过程参考
博客AD-NeRF 由音频和人脸图像合成人脸视频并表现出自然的说话风格_西西弗Sisyphus的博客-CSDN博客
一. PyTorch 环境配置
1.1 PyTorch 环境配置

在这个 environment.yml安装之前需要更换镜像源.这里我参考了下面的博客,解决了我的问题.
Conda 替换镜像源方法尽头,再也不用到处搜镜像源地址_conda换源_五阿哥爱跳舞的博客-CSDN博客在
在安装其中一个torchvision 0.8.1时一直报错 Solving environment: failed with initial frozen solve. Retrying with flexible solve
我参考了这篇博客
不过我还是没能用conda命令安装,博客最后的pip install 解决了我的问题. (事实上这也是pytorch官网的安装方法)
pip install torch==1.8.1+cu102 torchvision==0.9.1+cu102 torchaudio===0.8.1 -f https://download.pytorch.org/whl/torch_stable.html额由于我的显卡为30系的,后面呃又有其他的bug.
pip install torch==1.8.1+cu111 torchvision==0.9.1+cu111 torchaudio==0.8.1 -f https://download.pytorch.org/whl/torch_stable.html1.2 PyTorch3D 安装

显然我并没有成功地安装,如下
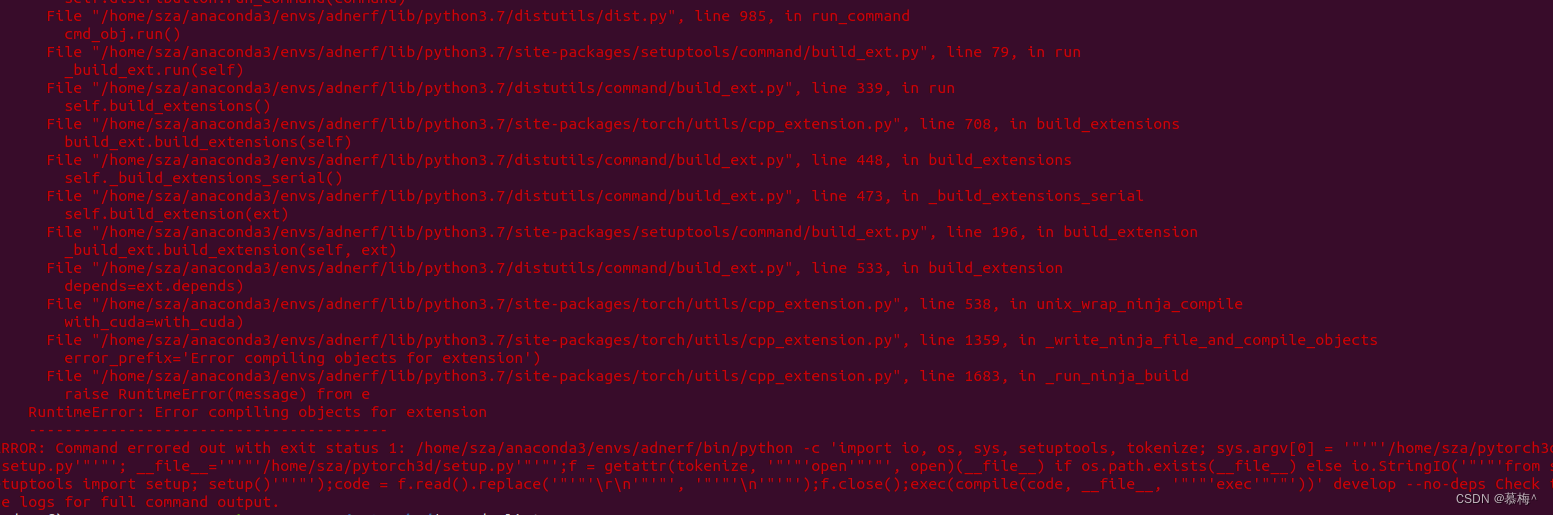
我采用了 下载自己需要的版本的tar.bz2文件 下载地址如下:
唉我的30系显卡无法使用cuda10.2,后面还有一大堆糟糕的事情.
使用conda 命令安装
conda install pytorch3d-0.6.1-py37_cu102_pyt181.tar.bz2
1.3 下载原始BFM模型

填写信息,然后得到邮箱进行下载.

解压后的文件如下:
 将"01_MorphableModel.mat" 放到 data_util/face_tracking/3DMM/ 然后
将"01_MorphableModel.mat" 放到 data_util/face_tracking/3DMM/ 然后
cd data_util/face_tracking 运行python convert_BFM.py
1.4 制作数据集

代码自动会自动找到vids下的文件,当然这一个命令可以分为多部python运行.
具体可以参考AD-NeRF 数据集的制作_ad-nerf 图像边界_西西弗Sisyphus的博客-CSDN博客

然而出现了大面积的错误:具体原因就是我的cuda为11.7而代码里的Tensorflow使用的版本为10
我的解决思路是系统同时有两个cuda,通过环境变量的切换来使用不同的cuda

export CUDA_HOME=/usr/local/cuda-10.2
export LD_LIBRARY_PATH=${CUDA_HOME}/lib64
export PATH=${CUDA_HOME}/bin:${PATH}
source ~/.bashrc

我参考了该博主的解决思路如下:
ubuntu的cuda10和cuda11共存_Dyson Sun的博客-CSDN博客
Ubuntu20.04安装cuda10.2和cudnn7.6.5_ubuntu20安装cuda10.2_小小小白~~的博客-CSDN博客
Ubuntu 20.04 CUDA&cuDNN安装方法(图文教程)-腾讯云开发者社区-腾讯云
最终更改环境变量,更新为cuda10.2

cudnn的安装,网上一搜一大把
最后将cudnn的文件里内容依次复制到对应的include和lib64中.
sudo cp include/cudnn*.h /usr/local/cuda/include
sudo cp -P lib/libcudnn* /usr/local/cuda/lib64
#将include和lib下的文件复制到cuda的安装目录
sudo chmod a+r /usr/local/cuda/include/cudnn*.h /usr/local/cuda/lib64/libcudnn*
cat /usr/local/cuda/include/cudnn_version.h | grep CUDNN_MAJOR -A 2检验一下,这部因人而异,因为我在安装低版本的时候压根没有cudnn_version.h
使用的命令为
cat /usr/local/cuda-10.2/include/cudnn.h | grep CUDNN_MAJOR -A 2第0步 提取声音特征
python data_util/process_data.py --id=demosza --step=0通过ffmpeg命令提取视频中音频数据,存储路径是dataset/$id/aud.wav
通过deepspeech获取音频特征存储路径是dataset/$id/aud.npy


第1步 原始视频转换成图像
python data_util/process_data.py --id=demosza --step=1将原始视频变成一帧帧的图像,数据存储在dataset/$id/ori_imgs文件夹中


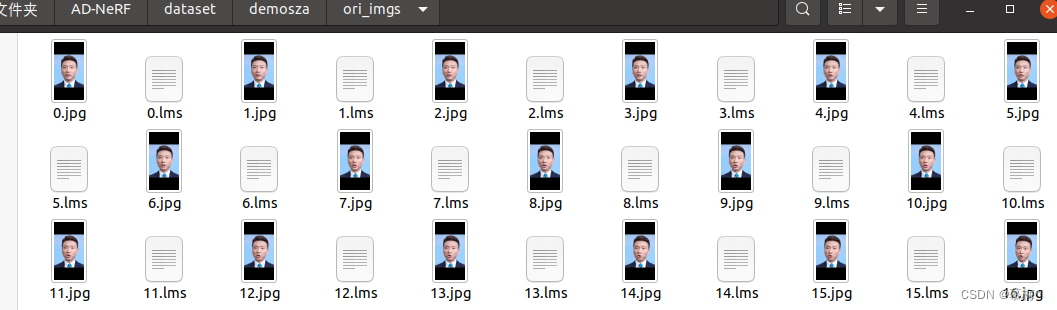
第2步 人脸关键点检测
python data_util/process_data.py --id=demosza --step=2从dataset/$id/ori_imgs文件夹中读取每一张图像,检测关键点,然后同名存储到dataset/$id/ori_imgs文件夹中,文件扩展名是lms
运行时间几十分钟,运行结果如下:

从dataset/Obama/ori_imgs文件夹中读取每一张图像,检测关键点,然后同名存储到dataset/Obama/ori_imgs文件夹中,文件扩展名是lms:
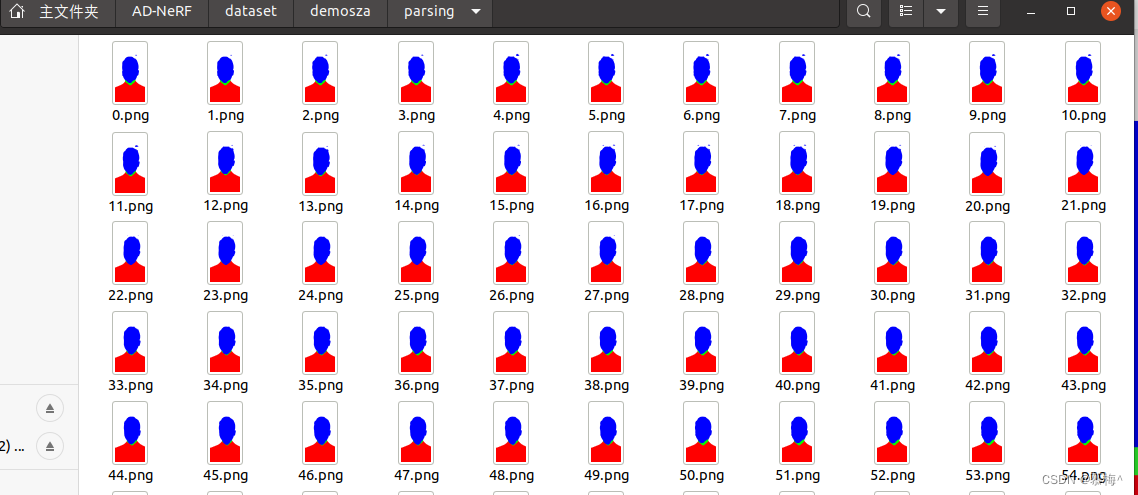
第3步 人脸解析
python data_util/process_data.py --id=demosza --step=3
输入数据路径是dataset/Obama/ori_imgs
输出数据路径是dataset/Obama/parsing
运行结果如下:



第4步 提取背景图片
python data_util/process_data.py --id=demosza --step=4这里在第二步人脸关键点检测的时候,确定了最大有效图像个数,默认是100000
并且获取了图像的高度和宽度,后面的操作就操作这些有效的图像。
输出的背景文件是dataset/Obama/bc.jpg
不知道为啥这个运行也很慢,大约一个小时,运行结果如下:



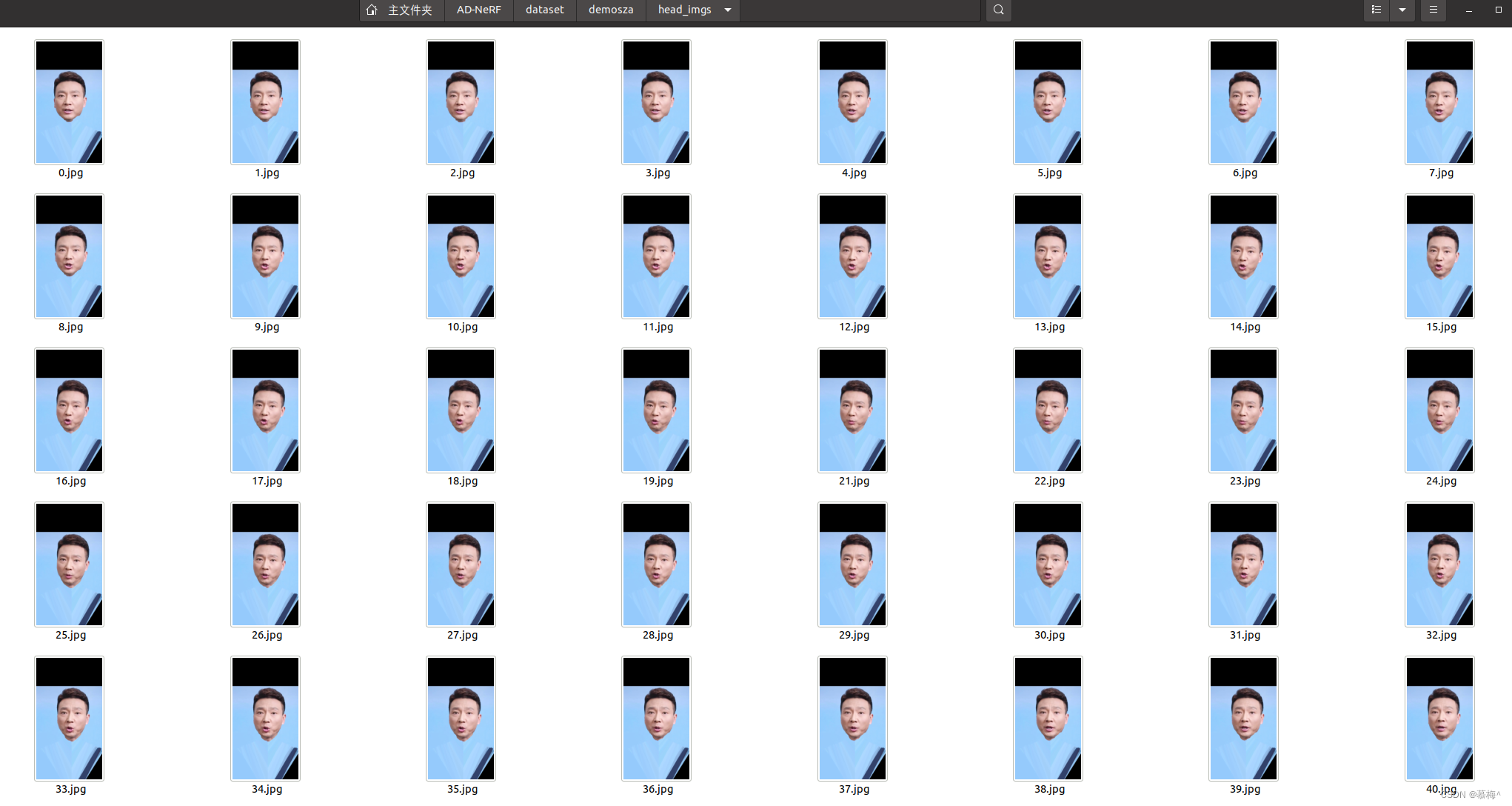
第5步 存储训练数据
python data_util/process_data.py --id=demosza --step=5通过第4步得到背景数据结合第3步得到解析数据最终得到两种训练数据
运行结果如下:


一个是只有头部和背景的数据,dataset/Obama/head_imgs

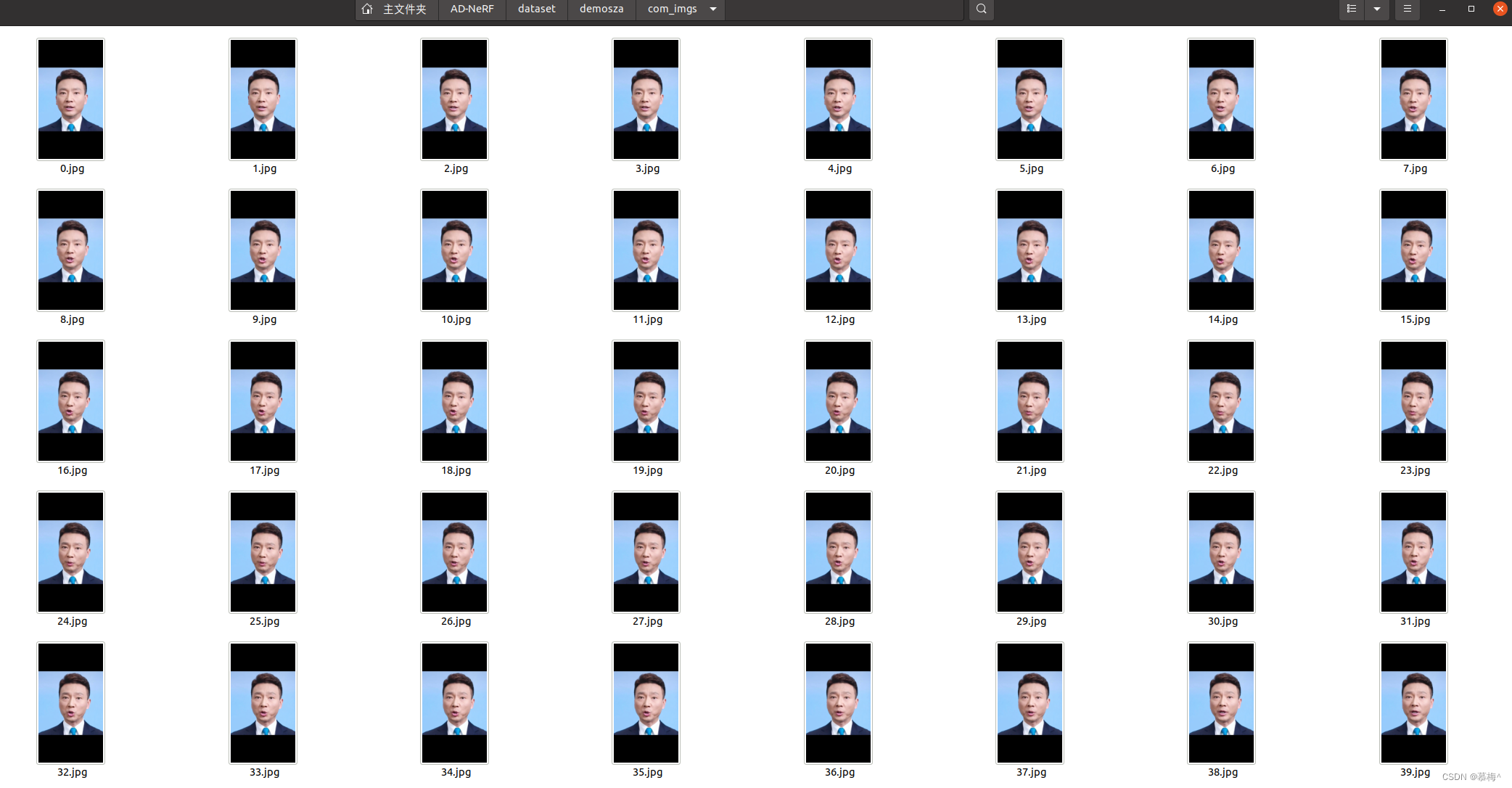
另一个是背景和整个上半身的数据,dataset/Obama/com_imgs(CSDN好像不给放obama的图片,会违规)

第6步 估计头部姿态
python data_util/process_data.py --id=demosza --step=6生成文件的路径是dataset/$id/debug/debug_render
参数存储文件是dataset/$id/track_params.pt
运行结果如下:
这个蛮久的

python data_util/process_data.py --id=Obama --step=7就是保存一下结果
输出包括 HeadNeRF_config.txt TorsoNeRF_config.txt TorsoNeRFTest_config.txt transforms_train.json transforms_val.json
1.5 训练Head-NeRF
训练Head-NeRF
python NeRFs/HeadNeRF/run_nerf.py --config dataset/Obama/HeadNeRF_config.txt


从AD-NeRF/dataset/Obama/logs/Obama_head找到最新的模型, 例如030000_head.tar重命名为head.tar
将head.tar放到AD-NeRF/dataset/Obama/logs/Obama_com中
执行命令
python NeRFs/TorsoNeRF/run_nerf.py --config dataset/Obama/TorsoNeRF_config.txt


1.6 Run AD-NeRF for rendering
两个训练完了就可以用自己的音频特征去驱动之前的目标
python NeRFs/TorsoNeRF/run_nerf.py --config dataset/$id/TorsoNeRFTest_config.txt --aud_file=${deepspeechfile.npy} --test_size=-1
这里输入自己的音频特征文件,可以使用deepspeech获取音频特征文件npy,制作数据集的第一部就是这个.不过我们只需要npy文件,
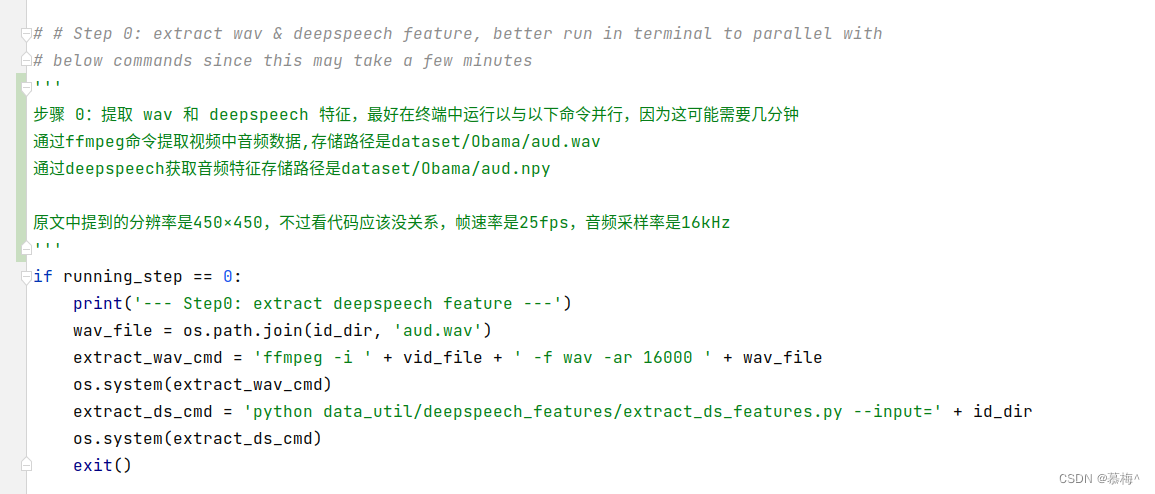
而步骤1是提取视频中的音频文件,再提取音频特征.
我们只需要执行这里面的extract_ds_features.py文件即可,输入我们自己的wav文件.

得到自己的音频特征文件npy,就可以进行语音驱动face了
python NeRFs/TorsoNeRF/run_nerf.py --config dataset/$id/TorsoNeRFTest_config.txt --aud_file=${deepspeechfile.npy} --test_size=-1

结果在:/home/sza/AD-NeRF/dataset/Obama/logs/Obama_com/test_aud_rst中的result.avi(没有声音)
最后通过ffmpeg合并音频和视频.
ffmpeg -i video.mp4/video.avi -i audio.wav -c:v copy -c:a aac -map 0:v:0 -map 1:a:0 output.mp4音频: /home/sza/AD-NeRF/sza/output.wav
视频: /home/sza/AD-NeRF/dataset/Obama/logs/Obama_com/test_aud_rst/result.avi
在这个命令中,video.mp4是你的视频文件,audio.wav是你的音频文件,output.mp4是输出的合并文件名。
命令解释:
-i video.mp4:指定输入视频文件。-i audio.wav:指定输入音频文件。-c:v copy:表示对视频流进行复制,保持原始编码格式,避免重新编码。-c:a aac:表示对音频流进行AAC编码,用于生成合并后的视频文件。-map 0:v:0:选择输入文件的第一个视频流。-map 1:a:0:选择输入文件的第一个音频流。output.mp4:指定输出文件名。
运行命令后,FFmpeg将合并音频和视频,并生成一个新的视频文件output.mp4。请确保你已经安装了FFmpeg,并将其添加到系统的环境变量中,这样你就可以在命令行中直接使用FFmpeg命令。最后的结果:

二 py文件概览
2.1 process_data.py
import cv2
import numpy as np
import face_alignment
from skimage import io
import torch
import torch.nn.functional as F
import json
import os
from sklearn.neighbors import NearestNeighbors
from pathlib import Path
import argparse
def euler2rot(euler_angle):
batch_size = euler_angle.shape[0]
theta = euler_angle[:, 0].reshape(-1, 1, 1)
phi = euler_angle[:, 1].reshape(-1, 1, 1)
psi = euler_angle[:, 2].reshape(-1, 1, 1)
one = torch.ones((batch_size, 1, 1), dtype=torch.float32,
device=euler_angle.device)
zero = torch.zeros((batch_size, 1, 1), dtype=torch.float32,
device=euler_angle.device)
rot_x = torch.cat((
torch.cat((one, zero, zero), 1),
torch.cat((zero, theta.cos(), theta.sin()), 1),
torch.cat((zero, -theta.sin(), theta.cos()), 1),
), 2)
rot_y = torch.cat((
torch.cat((phi.cos(), zero, -phi.sin()), 1),
torch.cat((zero, one, zero), 1),
torch.cat((phi.sin(), zero, phi.cos()), 1),
), 2)
rot_z = torch.cat((
torch.cat((psi.cos(), -psi.sin(), zero), 1),
torch.cat((psi.sin(), psi.cos(), zero), 1),
torch.cat((zero, zero, one), 1)
), 2)
return torch.bmm(rot_x, torch.bmm(rot_y, rot_z))
parser = argparse.ArgumentParser()
parser.add_argument('--id', type=str,
default='obama', help='identity of target person')
parser.add_argument('--step', type=int,
default=0, help='step for running')
args = parser.parse_args()
id = args.id
vid_file = os.path.join('dataset', 'vids', id+'.mp4')
if not os.path.isfile(vid_file):
print('no video')
exit()
id_dir = os.path.join('dataset', id)
Path(id_dir).mkdir(parents=True, exist_ok=True)
ori_imgs_dir = os.path.join('dataset', id, 'ori_imgs')
Path(ori_imgs_dir).mkdir(parents=True, exist_ok=True)
parsing_dir = os.path.join(id_dir, 'parsing')
Path(parsing_dir).mkdir(parents=True, exist_ok=True)
head_imgs_dir = os.path.join('dataset', id, 'head_imgs')
Path(head_imgs_dir).mkdir(parents=True, exist_ok=True)
com_imgs_dir = os.path.join('dataset', id, 'com_imgs')
Path(com_imgs_dir).mkdir(parents=True, exist_ok=True)
running_step = args.step
# # Step 0: extract wav & deepspeech feature, better run in terminal to parallel with
# below commands since this may take a few minutes
'''
步骤 0:提取 wav 和 deepspeech 特征,最好在终端中运行以与以下命令并行,因为这可能需要几分钟
通过ffmpeg命令提取视频中音频数据,存储路径是dataset/Obama/aud.wav
通过deepspeech获取音频特征存储路径是dataset/Obama/aud.npy
原文中提到的分辨率是450×450,不过看代码应该没关系,帧速率是25fps,音频采样率是16kHz
'''
if running_step == 0:
print('--- Step0: extract deepspeech feature ---')
wav_file = os.path.join(id_dir, 'aud.wav')
extract_wav_cmd = 'ffmpeg -i ' + vid_file + ' -f wav -ar 16000 ' + wav_file
os.system(extract_wav_cmd)
extract_ds_cmd = 'python data_util/deepspeech_features/extract_ds_features.py --input=' + id_dir
os.system(extract_ds_cmd)
exit()
# Step 1: extract images
'''
# 第1步:提取图像
将原始视频变成一帧帧的图像,数据存储在dataset/Obama/ori_imgs文件夹中
'''
if running_step == 1:
print('--- Step1: extract images from vids ---')
cap = cv2.VideoCapture(vid_file)
frame_num = 0
while(True):
_, frame = cap.read()
if frame is None:
break
cv2.imwrite(os.path.join(ori_imgs_dir, str(frame_num) + '.jpg'), frame)
frame_num = frame_num + 1
cap.release()
exit()
# Step 2: detect lands
'''
第步 人脸关键点检测
https://github.com/1adrianb/face-alignment
从dataset/Obama/ori_imgs文件夹中读取每一张图像,检测关键点,然后同名存储到dataset/Obama/ori_imgs文件夹中,文件扩展名是lms
用的是face-alignment,face-alignment可以检测2D或者3D的人脸关键点
'''
if running_step == 2:
print('--- Step 2: detect landmarks ---')
fa = face_alignment.FaceAlignment(
face_alignment.LandmarksType._2D, flip_input=False)
for image_path in os.listdir(ori_imgs_dir):
if image_path.endswith('.jpg'):
input = io.imread(os.path.join(ori_imgs_dir, image_path))[:, :, :3]
preds = fa.get_landmarks(input)
if len(preds) > 0:
lands = preds[0].reshape(-1, 2)[:,:2]
np.savetxt(os.path.join(ori_imgs_dir, image_path[:-3] + 'lms'), lands, '%f')
max_frame_num = 100000
valid_img_ids = []
for i in range(max_frame_num):
if os.path.isfile(os.path.join(ori_imgs_dir, str(i) + '.lms')):
valid_img_ids.append(i)
valid_img_num = len(valid_img_ids)
tmp_img = cv2.imread(os.path.join(ori_imgs_dir, str(valid_img_ids[0])+'.jpg'))
h, w = tmp_img.shape[0], tmp_img.shape[1]
# Step 3: face parsing
'''
第3步 人脸解析
输入数据路径是dataset/Obama/ori_imgs
输出数据路径是dataset/Obama/parsing
'''
if running_step == 3:
print('--- Step 3: face parsing ---')
face_parsing_cmd = 'python data_util/face_parsing/test.py --respath=dataset/' + \
id + '/parsing --imgpath=dataset/' + id + '/ori_imgs'
os.system(face_parsing_cmd)
# Step 4: extract bc image
'''
第4步 提取背景图片
这里在第二步人脸关键点检测的时候,确定了最大有效图像个数,默认是100000
并且获取了图像的高度和宽度,后面的操作就操作这些有效的图像。
输出的背景文件是dataset/Obama/bc.jpg
'''
if running_step == 4:
print('--- Step 4: extract background image ---')
sel_ids = np.array(valid_img_ids)[np.arange(0, valid_img_num, 20)]
all_xys = np.mgrid[0:h, 0:w].reshape(2, -1).transpose()
distss = []
for i in sel_ids:
parse_img = cv2.imread(os.path.join(id_dir, 'parsing', str(i) + '.png'))
bg = (parse_img[..., 0] == 255) & (
parse_img[..., 1] == 255) & (parse_img[..., 2] == 255)
fg_xys = np.stack(np.nonzero(~bg)).transpose(1, 0)
nbrs = NearestNeighbors(n_neighbors=1, algorithm='kd_tree').fit(fg_xys)
dists, _ = nbrs.kneighbors(all_xys)
distss.append(dists)
distss = np.stack(distss)
print(distss.shape)
max_dist = np.max(distss, 0)
max_id = np.argmax(distss, 0)
bc_pixs = max_dist > 5
bc_pixs_id = np.nonzero(bc_pixs)
bc_ids = max_id[bc_pixs]
imgs = []
num_pixs = distss.shape[1]
for i in sel_ids:
img = cv2.imread(os.path.join(ori_imgs_dir, str(i) + '.jpg'))
imgs.append(img)
imgs = np.stack(imgs).reshape(-1, num_pixs, 3)
bc_img = np.zeros((h*w, 3), dtype=np.uint8)
bc_img[bc_pixs_id, :] = imgs[bc_ids, bc_pixs_id, :]
bc_img = bc_img.reshape(h, w, 3)
max_dist = max_dist.reshape(h, w)
bc_pixs = max_dist > 5
bg_xys = np.stack(np.nonzero(~bc_pixs)).transpose()
fg_xys = np.stack(np.nonzero(bc_pixs)).transpose()
nbrs = NearestNeighbors(n_neighbors=1, algorithm='kd_tree').fit(fg_xys)
distances, indices = nbrs.kneighbors(bg_xys)
bg_fg_xys = fg_xys[indices[:, 0]]
print(fg_xys.shape)
print(np.max(bg_fg_xys), np.min(bg_fg_xys))
bc_img[bg_xys[:, 0], bg_xys[:, 1],
:] = bc_img[bg_fg_xys[:, 0], bg_fg_xys[:, 1], :]
cv2.imwrite(os.path.join(id_dir, 'bc.jpg'), bc_img)
# Step 5: save training images
'''
第5步 存储训练数据
通过第4步得到背景数据结合第3步得到解析数据最终得到两种训练数据
一个是只有头部和背景的数据,dataset/Obama/head_imgs
另一个是背景和整个上半身的数据,dataset/Obama/com_imgs
'''
if running_step == 5:
print('--- Step 5: save training images ---')
bc_img = cv2.imread(os.path.join(id_dir, 'bc.jpg'))
for i in valid_img_ids:
parsing_img = cv2.imread(os.path.join(parsing_dir, str(i) + '.png'))
head_part = (parsing_img[:, :, 0] == 255) & (
parsing_img[:, :, 1] == 0) & (parsing_img[:, :, 2] == 0)
bc_part = (parsing_img[:, :, 0] == 255) & (
parsing_img[:, :, 1] == 255) & (parsing_img[:, :, 2] == 255)
img = cv2.imread(os.path.join(ori_imgs_dir, str(i) + '.jpg'))
img[bc_part] = bc_img[bc_part]
cv2.imwrite(os.path.join(com_imgs_dir, str(i) + '.jpg'), img)
img[~head_part] = bc_img[~head_part]
cv2.imwrite(os.path.join(head_imgs_dir, str(i) + '.jpg'), img)
# Step 6: estimate head pose
'''
第6步 估计头部姿态
生成文件的路径是dataset/Obama/debug/debug_render
参数存储文件是dataset/Obama/track_params.pt
'''
if running_step == 6:
print('--- Estimate Head Pose ---')
est_pose_cmd = 'python data_util/face_tracking/face_tracker.py --idname=' + \
id + ' --img_h=' + str(h) + ' --img_w=' + str(w) + \
' --frame_num=' + str(max_frame_num)
os.system(est_pose_cmd)
exit()
# Step 7: save transform param & write config file
'''
第7步 写入Transform参数和配置文件
通过第6步得到track_params.pt参数,输出包括
HeadNeRF_config.txt
TorsoNeRF_config.txt
TorsoNeRFTest_config.txt
transforms_train.json
transforms_val.json
'''
if running_step == 7:
print('--- Step 7: Save Transform Param ---')
'''
加载参数:从指定路径下加载包含转换参数的文件 track_params.pt,并将参数存储在 params_dict 字典中。
'''
params_dict = torch.load(os.path.join(id_dir, 'track_params.pt'))
'''
从params_dict中提取焦距(focal)、欧拉角(euler)和平移(trans)。此外,平移参数会除以10.0进行缩放。
'''
focal_len = params_dict['focal']
euler_angle = params_dict['euler']
trans = params_dict['trans'] / 10.0
'''
计算有效样本数量:获取欧拉角的形状,并计算有效样本的数量。
'''
valid_num = euler_angle.shape[0]
'''
获取欧拉角的有效数量(valid_num),然后计算用于训练和验证集划分的索引(train_val_split)。
其中,训练集的索引范围是从0到train_val_split,验证集的索引范围是从train_val_split到valid_num。
'''
train_val_split = int(valid_num*10/11)
train_ids = torch.arange(0, train_val_split)
val_ids = torch.arange(train_val_split, valid_num)
'''
将欧拉角转换为旋转矩阵(rot),并计算其逆矩阵(rot_inv)。
计算平移的逆变换(trans_inv),通过使用旋转矩阵的逆和平移的负向量的乘积。
'''
rot = euler2rot(euler_angle)
rot_inv = rot.permute(0, 2, 1)
trans_inv = -torch.bmm(rot_inv, trans.unsqueeze(2))
'''
创建一个4x4的单位矩阵(pose),用于存储姿态变换矩阵。
创建两个列表save_ids和train_val_ids,分别用于保存训练集和验证集的ID。
'''
pose = torch.eye(4, dtype=torch.float32)
save_ids = ['train', 'val']
train_val_ids = [train_ids, val_ids]
'''
计算平移参数trans在Z轴上的平均值,并取其相反数作为mean_z。
'''
mean_z = -float(torch.mean(trans[:, 2]).item())
'''
进行一个循环,循环两次,分别处理训练集和验证集。
在循环中,创建一个字典transform_dict,用于存储变换的元数据信息。
将焦距(focal_len)、图像宽度的一半(w/2.0)和图像高度的一半(h/2.0)保存到transform_dict中。
创建一个空列表frames,用于存储每个图像帧的元数据。
获取当前处理的集合的ID范围(ids),以及保存该集合的ID字符串(save_id)。
在ids中进行循环迭代,处理每个图像帧。
获取当前帧的索引i,并创建一个字典frame_dict,用于存储该帧的元数据。
将图像ID(valid_img_ids[i])和音频ID(valid_img_ids[i])保存到frame_dict中。
根据当前帧的索引i,将旋转矩阵和平移参数更新到pose矩阵中,并将变换矩阵(pose)转换为NumPy数组,并将其保存到frame_dict中。
加载当前帧对应的人脸关键点坐标(lms),并根据关键点坐标计算人脸区域的矩形坐标。
将人脸矩形区域(rect)保存到frame_dict中。
将当前帧的元数据(frame_dict)添加到transform_dict['frames']列表中。
将transform_dict以JSON格式写入到文件中,文件名格式为transforms_{save_id}.json。
'''
for i in range(2):
transform_dict = dict()
transform_dict['focal_len'] = float(focal_len[0])
transform_dict['cx'] = float(w/2.0)
transform_dict['cy'] = float(h/2.0)
transform_dict['frames'] = []
ids = train_val_ids[i]
save_id = save_ids[i]
for i in ids:
i = i.item()
frame_dict = dict()
frame_dict['img_id'] = int(valid_img_ids[i])
frame_dict['aud_id'] = int(valid_img_ids[i])
pose[:3, :3] = rot_inv[i]
pose[:3, 3] = trans_inv[i, :, 0]
frame_dict['transform_matrix'] = pose.numpy().tolist()
lms = np.loadtxt(os.path.join(
ori_imgs_dir, str(valid_img_ids[i]) + '.lms'))
min_x, max_x = np.min(lms, 0)[0], np.max(lms, 0)[0]
cx = int((min_x+max_x)/2.0)
cy = int(lms[27, 1])
h_w = int((max_x-cx)*1.5)
h_h = int((lms[8, 1]-cy)*1.15)
rect_x = cx - h_w
rect_y = cy - h_h
if rect_x < 0:
rect_x = 0
if rect_y < 0:
rect_y = 0
rect_w = min(w-1-rect_x, 2*h_w)
rect_h = min(h-1-rect_y, 2*h_h)
rect = np.array((rect_x, rect_y, rect_w, rect_h), dtype=np.int32)
frame_dict['face_rect'] = rect.tolist()
transform_dict['frames'].append(frame_dict)
with open(os.path.join(id_dir, 'transforms_' + save_id + '.json'), 'w') as fp:
json.dump(transform_dict, fp, indent=2, separators=(',', ': '))
'''
获取根目录的路径,并构建HeadNeRF的配置文件路径(HeadNeRF_config_file)。
'''
dir_path = os.path.dirname(os.path.dirname(os.path.realpath(__file__)))
testskip = int(val_ids.shape[0]/7)
'''
使用文件操作,将HeadNeRF的配置信息写入到配置文件中。
创建一个名为id + '_head'的文件夹,用于保存HeadNeRF的日志和输出。
'''
HeadNeRF_config_file = os.path.join(id_dir, 'HeadNeRF_config.txt')
with open(HeadNeRF_config_file, 'w') as file:
file.write('expname = ' + id + '_head\n')
file.write('datadir = ' + os.path.join(dir_path, 'dataset', id) + '\n')
file.write('basedir = ' + os.path.join(dir_path,
'dataset', id, 'logs') + '\n')
file.write('near = ' + str(mean_z-0.2) + '\n')
file.write('far = ' + str(mean_z+0.4) + '\n')
file.write('testskip = ' + str(testskip) + '\n')
Path(os.path.join(dir_path, 'dataset', id, 'logs', id + '_head')
).mkdir(parents=True, exist_ok=True)
'''
torso是躯干的意思
构建ComNeRF的配置文件路径(ComNeRF_config_file),并将ComNeRF的配置信息写入到配置文件中。
创建一个名为id + '_com'的文件夹,用于保存ComNeRF的日志和输出。
构建ComNeRFTest的配置文件路径(ComNeRFTest_config_file),并将ComNeRFTest的配置信息写入到配置文件中。
'''
ComNeRF_config_file = os.path.join(id_dir, 'TorsoNeRF_config.txt')
with open(ComNeRF_config_file, 'w') as file:
file.write('expname = ' + id + '_com\n')
file.write('datadir = ' + os.path.join(dir_path, 'dataset', id) + '\n')
file.write('basedir = ' + os.path.join(dir_path,
'dataset', id, 'logs') + '\n')
file.write('near = ' + str(mean_z-0.2) + '\n')
file.write('far = ' + str(mean_z+0.4) + '\n')
file.write('testskip = ' + str(testskip) + '\n')
Path(os.path.join(dir_path, 'dataset', id, 'logs', id + '_com')
).mkdir(parents=True, exist_ok=True)
ComNeRFTest_config_file = os.path.join(id_dir, 'TorsoNeRFTest_config.txt')
with open(ComNeRFTest_config_file, 'w') as file:
file.write('expname = ' + id + '_com\n')
file.write('datadir = ' + os.path.join(dir_path, 'dataset', id) + '\n')
file.write('basedir = ' + os.path.join(dir_path,
'dataset', id, 'logs') + '\n')
file.write('near = ' + str(mean_z-0.2) + '\n')
file.write('far = ' + str(mean_z+0.4) + '\n')
file.write('with_test = ' + str(1) + '\n')
file.write('test_pose_file = transforms_val.json' + '\n')
print(id + ' data processed done!')
2.2 run_nerf.py
关于nerf,这里很多的内容可以看这两篇博客
【代码详解】nerf-pytorch代码逐行分析_nerf_pytorch代码解读csdn_YuhsiHu的博客-CSDN博客
NeRF神经辐射场学习笔记(二)——Pytorch版NeRF实现以及代码注释_nerf pytorch_右边的口袋的博客-CSDN博客
from load_audface import load_audface_data
import os
import sys
import numpy as np
import imageio
import json
import random
import time
import torch
import torch.nn as nn
import torch.nn.functional as F
from tqdm import tqdm, trange
from natsort import natsorted
from run_nerf_helpers import *
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
np.random.seed(0)
DEBUG = False
def batchify(fn, chunk):
"""Constructs a version of 'fn' that applies to smaller batches.
"""
if chunk is None:
return fn
def ret(inputs):
return torch.cat([fn(inputs[i:i+chunk]) for i in range(0, inputs.shape[0], chunk)], 0)
return ret
def run_network(inputs, viewdirs, aud_para, fn, embed_fn, embeddirs_fn, netchunk=1024*64):
"""Prepares inputs and applies network 'fn'.
"""
inputs_flat = torch.reshape(inputs, [-1, inputs.shape[-1]])
embedded = embed_fn(inputs_flat)
aud = aud_para.unsqueeze(0).expand(inputs_flat.shape[0], -1)
embedded = torch.cat((embedded, aud), -1)
if viewdirs is not None:
input_dirs = viewdirs[:, None].expand(inputs.shape)
input_dirs_flat = torch.reshape(input_dirs, [-1, input_dirs.shape[-1]])
embedded_dirs = embeddirs_fn(input_dirs_flat)
embedded = torch.cat([embedded, embedded_dirs], -1)
outputs_flat = batchify(fn, netchunk)(embedded)
outputs = torch.reshape(outputs_flat, list(
inputs.shape[:-1]) + [outputs_flat.shape[-1]])
return outputs
def batchify_rays(rays_flat, bc_rgb, aud_para, chunk=1024*32, **kwargs):
"""Render rays in smaller minibatches to avoid OOM.
"""
all_ret = {}
for i in range(0, rays_flat.shape[0], chunk):
ret = render_rays(rays_flat[i:i+chunk], bc_rgb[i:i+chunk],
aud_para, **kwargs)
for k in ret:
if k not in all_ret:
all_ret[k] = []
all_ret[k].append(ret[k])
all_ret = {k: torch.cat(all_ret[k], 0) for k in all_ret}
return all_ret
def render_dynamic_face(H, W, focal, cx, cy, chunk=1024*32, rays=None, bc_rgb=None, aud_para=None,
c2w=None, ndc=True, near=0., far=1.,
use_viewdirs=False, c2w_staticcam=None,
**kwargs):
if c2w is not None:
# special case to render full image
rays_o, rays_d = get_rays(H, W, focal, c2w, cx, cy)
bc_rgb = bc_rgb.reshape(-1, 3)
else:
# use provided ray batch
rays_o, rays_d = rays
if use_viewdirs:
# provide ray directions as input
viewdirs = rays_d
if c2w_staticcam is not None:
# special case to visualize effect of viewdirs
rays_o, rays_d = get_rays(H, W, focal, c2w_staticcam, cx, cy)
viewdirs = viewdirs / torch.norm(viewdirs, dim=-1, keepdim=True)
viewdirs = torch.reshape(viewdirs, [-1, 3]).float()
sh = rays_d.shape # [..., 3]
if ndc:
# for forward facing scenes
rays_o, rays_d = ndc_rays(H, W, focal, 1., rays_o, rays_d)
# Create ray batch
rays_o = torch.reshape(rays_o, [-1, 3]).float()
rays_d = torch.reshape(rays_d, [-1, 3]).float()
near, far = near * \
torch.ones_like(rays_d[..., :1]), far * \
torch.ones_like(rays_d[..., :1])
rays = torch.cat([rays_o, rays_d, near, far], -1)
if use_viewdirs:
rays = torch.cat([rays, viewdirs], -1)
# Render and reshape
all_ret = batchify_rays(rays, bc_rgb, aud_para, chunk, **kwargs)
for k in all_ret:
k_sh = list(sh[:-1]) + list(all_ret[k].shape[1:])
all_ret[k] = torch.reshape(all_ret[k], k_sh)
k_extract = ['rgb_map', 'disp_map', 'acc_map', 'last_weight']
ret_list = [all_ret[k] for k in k_extract]
ret_dict = {k: all_ret[k] for k in all_ret if k not in k_extract}
return ret_list + [ret_dict]
def render(H, W, focal, cx, cy, chunk=1024*32, rays=None, c2w=None, ndc=True,
near=0., far=1.,
use_viewdirs=False, c2w_staticcam=None,
**kwargs):
"""Render rays
Args:
H: int. Height of image in pixels.
W: int. Width of image in pixels.
focal: float. Focal length of pinhole camera.
chunk: int. Maximum number of rays to process simultaneously. Used to
control maximum memory usage. Does not affect final results.
rays: array of shape [2, batch_size, 3]. Ray origin and direction for
each example in batch.
c2w: array of shape [3, 4]. Camera-to-world transformation matrix.
ndc: bool. If True, represent ray origin, direction in NDC coordinates.
near: float or array of shape [batch_size]. Nearest distance for a ray.
far: float or array of shape [batch_size]. Farthest distance for a ray.
use_viewdirs: bool. If True, use viewing direction of a point in space in model.
c2w_staticcam: array of shape [3, 4]. If not None, use this transformation matrix for
camera while using other c2w argument for viewing directions.
Returns:
rgb_map: [batch_size, 3]. Predicted RGB values for rays.
disp_map: [batch_size]. Disparity map. Inverse of depth.
acc_map: [batch_size]. Accumulated opacity (alpha) along a ray.
extras: dict with everything returned by render_rays().
"""
if c2w is not None:
# special case to render full image
rays_o, rays_d = get_rays(H, W, focal, c2w, cx, cy)
else:
# use provided ray batch
rays_o, rays_d = rays
if use_viewdirs:
# provide ray directions as input
viewdirs = rays_d
if c2w_staticcam is not None:
# special case to visualize effect of viewdirs
rays_o, rays_d = get_rays(H, W, focal, c2w_staticcam, cx, cy)
viewdirs = viewdirs / torch.norm(viewdirs, dim=-1, keepdim=True)
viewdirs = torch.reshape(viewdirs, [-1, 3]).float()
sh = rays_d.shape # [..., 3]
if ndc:
# for forward facing scenes
rays_o, rays_d = ndc_rays(H, W, focal, 1., rays_o, rays_d)
# Create ray batch
rays_o = torch.reshape(rays_o, [-1, 3]).float()
rays_d = torch.reshape(rays_d, [-1, 3]).float()
near, far = near * \
torch.ones_like(rays_d[..., :1]), far * \
torch.ones_like(rays_d[..., :1])
rays = torch.cat([rays_o, rays_d, near, far], -1)
if use_viewdirs:
rays = torch.cat([rays, viewdirs], -1)
# Render and reshape
all_ret = batchify_rays(rays, chunk, **kwargs)
for k in all_ret:
k_sh = list(sh[:-1]) + list(all_ret[k].shape[1:])
all_ret[k] = torch.reshape(all_ret[k], k_sh)
k_extract = ['rgb_map', 'disp_map', 'acc_map']
ret_list = [all_ret[k] for k in k_extract]
ret_dict = {k: all_ret[k] for k in all_ret if k not in k_extract}
return ret_list + [ret_dict]
def render_path(render_poses, aud_paras, bc_img, hwfcxy,
chunk, render_kwargs, gt_imgs=None, savedir=None, render_factor=0):
H, W, focal, cx, cy = hwfcxy
if render_factor != 0:
# Render downsampled for speed
H = H//render_factor
W = W//render_factor
focal = focal/render_factor
rgbs = []
disps = []
last_weights = []
t = time.time()
for i, c2w in enumerate(tqdm(render_poses)):
print(i, time.time() - t)
t = time.time()
rgb, disp, acc, last_weight, _ = render_dynamic_face(
H, W, focal, cx, cy, chunk=chunk, c2w=c2w[:3,
:4], aud_para=aud_paras[i], bc_rgb=bc_img,
**render_kwargs)
rgbs.append(rgb.cpu().numpy())
disps.append(disp.cpu().numpy())
last_weights.append(last_weight.cpu().numpy())
if i == 0:
print(rgb.shape, disp.shape)
"""
if gt_imgs is not None and render_factor==0:
p = -10. * np.log10(np.mean(np.square(rgb.cpu().numpy() - gt_imgs[i])))
print(p)
"""
if savedir is not None:
rgb8 = to8b(rgbs[-1])
filename = os.path.join(savedir, '{:03d}.png'.format(i))
imageio.imwrite(filename, rgb8)
rgbs = np.stack(rgbs, 0)
disps = np.stack(disps, 0)
last_weights = np.stack(last_weights, 0)
return rgbs, disps, last_weights
def create_nerf(args):
"""Instantiate NeRF's MLP model.
函数接受一个参数args,其中包含了NeRF模型的各种配置选项。
"""
# multires = 10 位置编码操作对于3D位置信息的所升维数,默认L=10
# i_embed = 0 是否加入位置编码操作,设为0是默认采用位置编码方法,-1则无
'''
首先,函数调用get_embedder函数来获取位置编码器(embedder)对象和输入通道数input_ch。
位置编码器用于将输入的位置信息进行编码,以供后续的神经网络模型使用。
'''
embed_fn, input_ch = get_embedder(args.multires, args.i_embed)
input_ch_views = 0
embeddirs_fn = None
# use_viewdirs = True用完整的5D信息代替3D信息
if args.use_viewdirs:
'''
接着,根据是否使用视角方向(view directions)的配置选项,
同样使用get_embedder函数获取视角编码器(embedder)对象和输入通道数input_ch_views。
'''
embeddirs_fn, input_ch_views = get_embedder(
args.multires_views, args.i_embed)
output_ch = 5 if args.N_importance > 0 else 4
skips = [4]
'''
根据NeRF模型的其他配置选项,创建一个FaceNeRF模型对象model。
FaceNeRF是NeRF模型的实现,它接受各种输入参数来定义模型的深度、宽度、输入通道数、输出通道数等。
'''
model = FaceNeRF(D=args.netdepth, W=args.netwidth,
input_ch=input_ch, dim_aud=args.dim_aud,
output_ch=output_ch, skips=skips,
input_ch_views=input_ch_views, use_viewdirs=args.use_viewdirs).to(device)
grad_vars = list(model.parameters())
model_fine = None
'''
配置选项中指定了N_importance大于0,则创建一个额外的精细模型model_fine,用于处理更重要的样本
'''
if args.N_importance > 0:
model_fine = FaceNeRF(D=args.netdepth_fine, W=args.netwidth_fine,
input_ch=input_ch, dim_aud=args.dim_aud,
output_ch=output_ch, skips=skips,
input_ch_views=input_ch_views, use_viewdirs=args.use_viewdirs).to(device)
grad_vars += list(model_fine.parameters())
'''
创建了一个network_query_fn函数,用于执行神经网络的前向传播。
这个函数会将输入数据、视角方向、音频参数等传递给网络模型,并返回输出结果。
'''
def network_query_fn(inputs, viewdirs, aud_para, network_fn): \
return run_network(inputs, viewdirs, aud_para, network_fn,
embed_fn=embed_fn, embeddirs_fn=embeddirs_fn, netchunk=args.netchunk)
'''
创建了一个Adam优化器,用于优化模型的参数。
'''
# Create optimizer
optimizer = torch.optim.Adam(
params=grad_vars, lr=args.lrate, betas=(0.9, 0.999))
start = 0
basedir = args.basedir
expname = args.expname
##########################
# Load checkpoints
'''
在加载检查点(checkpoint)时,函数会检查是否指定了检查点文件路径。
如果有,则加载指定的检查点文件,恢复模型和优化器的状态。
'''
if args.ft_path is not None and args.ft_path != 'None':
ckpts = [args.ft_path]
else:
ckpts = [os.path.join(basedir, expname, f) for f in natsorted(
os.listdir(os.path.join(basedir, expname))) if 'tar' in f]
print('Found ckpts', ckpts)
learned_codes_dict = None
AudNet_state = None
AudAttNet_state = None
optimizer_aud_state = None
optimizer_audatt_state = None
if len(ckpts) > 0 and not args.no_reload:
ckpt_path = ckpts[-1]
print('Reloading from', ckpt_path)
ckpt = torch.load(ckpt_path)
start = ckpt['global_step']
optimizer.load_state_dict(ckpt['optimizer_state_dict'])
AudNet_state = ckpt['network_audnet_state_dict']
optimizer_aud_state = ckpt['optimizer_aud_state_dict']
# Load model
model.load_state_dict(ckpt['network_fn_state_dict'])
if model_fine is not None:
model_fine.load_state_dict(ckpt['network_fine_state_dict'])
if 'network_audattnet_state_dict' in ckpt:
AudAttNet_state = ckpt['network_audattnet_state_dict']
if 'optimize_audatt_state_dict' in ckpt:
optimizer_audatt_state = ckpt['optimize_audatt_state_dict']
##########################
'''
最后,函数定义了render_kwargs_train和render_kwargs_test字典,其中包含了渲染模型所需的各种参数配置。
'''
render_kwargs_train = {
'network_query_fn': network_query_fn,
'perturb': args.perturb,
'N_importance': args.N_importance,
'network_fine': model_fine,
'N_samples': args.N_samples,
'network_fn': model,
'use_viewdirs': args.use_viewdirs,
'white_bkgd': args.white_bkgd,
'raw_noise_std': args.raw_noise_std,
}
# NDC only good for LLFF-style forward facing data
if args.dataset_type != 'llff' or args.no_ndc:
print('Not ndc!')
render_kwargs_train['ndc'] = False
render_kwargs_train['lindisp'] = args.lindisp
render_kwargs_test = {
k: render_kwargs_train[k] for k in render_kwargs_train}
render_kwargs_test['perturb'] = False
render_kwargs_test['raw_noise_std'] = 0.
return render_kwargs_train, render_kwargs_test, start, grad_vars, optimizer, learned_codes_dict, \
AudNet_state, optimizer_aud_state, AudAttNet_state, optimizer_audatt_state
def raw2outputs(raw, z_vals, rays_d, bc_rgb, raw_noise_std=0, white_bkgd=False, pytest=False):
"""Transforms model's predictions to semantically meaningful values.
Args:
raw: [num_rays, num_samples along ray, 4]. Prediction from model.
z_vals: [num_rays, num_samples along ray]. Integration time.
rays_d: [num_rays, 3]. Direction of each ray.
Returns:
rgb_map: [num_rays, 3]. Estimated RGB color of a ray.
disp_map: [num_rays]. Disparity map. Inverse of depth map.
acc_map: [num_rays]. Sum of weights along each ray.
weights: [num_rays, num_samples]. Weights assigned to each sampled color.
depth_map: [num_rays]. Estimated distance to object.
"""
def raw2alpha(raw, dists, act_fn=F.relu): return 1. - \
torch.exp(-(act_fn(raw)+1e-6)*dists)
dists = z_vals[..., 1:] - z_vals[..., :-1]
dists = torch.cat([dists, torch.Tensor([1e10]).expand(
dists[..., :1].shape)], -1) # [N_rays, N_samples]
dists = dists * torch.norm(rays_d[..., None, :], dim=-1)
rgb = torch.sigmoid(raw[..., :3]) # [N_rays, N_samples, 3]
rgb = torch.cat((rgb[:, :-1, :], bc_rgb.unsqueeze(1)), dim=1)
noise = 0.
if raw_noise_std > 0.:
noise = torch.randn(raw[..., 3].shape) * raw_noise_std
# Overwrite randomly sampled data if pytest
if pytest:
np.random.seed(0)
noise = np.random.rand(*list(raw[..., 3].shape)) * raw_noise_std
noise = torch.Tensor(noise)
alpha = raw2alpha(raw[..., 3] + noise, dists) # [N_rays, N_samples]
# weights = alpha * tf.math.cumprod(1.-alpha + 1e-10, -1, exclusive=True)
weights = alpha * \
torch.cumprod(
torch.cat([torch.ones((alpha.shape[0], 1)), 1.-alpha + 1e-10], -1), -1)[:, :-1]
rgb_map = torch.sum(weights[..., None] * rgb, -2) # [N_rays, 3]
depth_map = torch.sum(weights * z_vals, -1)
disp_map = 1./torch.max(1e-10 * torch.ones_like(depth_map),
depth_map / torch.sum(weights, -1))
acc_map = torch.sum(weights, -1)
if white_bkgd:
rgb_map = rgb_map + (1.-acc_map[..., None])
return rgb_map, disp_map, acc_map, weights, depth_map
def render_rays(ray_batch,
bc_rgb,
aud_para,
network_fn,
network_query_fn,
N_samples,
retraw=False,
lindisp=False,
perturb=0.,
N_importance=0,
network_fine=None,
white_bkgd=False,
raw_noise_std=0.,
verbose=False,
pytest=False):
"""Volumetric rendering.
Args:
ray_batch: array of shape [batch_size, ...]. All information necessary
for sampling along a ray, including: ray origin, ray direction, min
dist, max dist, and unit-magnitude viewing direction.
network_fn: function. Model for predicting RGB and density at each point
in space.
network_query_fn: function used for passing queries to network_fn.
N_samples: int. Number of different times to sample along each ray.
retraw: bool. If True, include model's raw, unprocessed predictions.
lindisp: bool. If True, sample linearly in inverse depth rather than in depth.
perturb: float, 0 or 1. If non-zero, each ray is sampled at stratified
random points in time.
N_importance: int. Number of additional times to sample along each ray.
These samples are only passed to network_fine.
network_fine: "fine" network with same spec as network_fn.
white_bkgd: bool. If True, assume a white background.
raw_noise_std: ...
verbose: bool. If True, print more debugging info.
Returns:
rgb_map: [num_rays, 3]. Estimated RGB color of a ray. Comes from fine model.
disp_map: [num_rays]. Disparity map. 1 / depth.
acc_map: [num_rays]. Accumulated opacity along each ray. Comes from fine model.
raw: [num_rays, num_samples, 4]. Raw predictions from model.
rgb0: See rgb_map. Output for coarse model.
disp0: See disp_map. Output for coarse model.
acc0: See acc_map. Output for coarse model.
z_std: [num_rays]. Standard deviation of distances along ray for each
sample.
"""
N_rays = ray_batch.shape[0]
rays_o, rays_d = ray_batch[:, 0:3], ray_batch[:, 3:6] # [N_rays, 3] each
viewdirs = ray_batch[:, -3:] if ray_batch.shape[-1] > 8 else None
bounds = torch.reshape(ray_batch[..., 6:8], [-1, 1, 2])
near, far = bounds[..., 0], bounds[..., 1] # [-1,1]
t_vals = torch.linspace(0., 1., steps=N_samples)
if not lindisp:
z_vals = near * (1.-t_vals) + far * (t_vals)
else:
z_vals = 1./(1./near * (1.-t_vals) + 1./far * (t_vals))
z_vals = z_vals.expand([N_rays, N_samples])
if perturb > 0.:
# get intervals between samples
mids = .5 * (z_vals[..., 1:] + z_vals[..., :-1])
upper = torch.cat([mids, z_vals[..., -1:]], -1)
lower = torch.cat([z_vals[..., :1], mids], -1)
# stratified samples in those intervals
t_rand = torch.rand(z_vals.shape)
# Pytest, overwrite u with numpy's fixed random numbers
if pytest:
np.random.seed(0)
t_rand = np.random.rand(*list(z_vals.shape))
t_rand = torch.Tensor(t_rand)
t_rand[..., -1] = 1.0
z_vals = lower + (upper - lower) * t_rand
pts = rays_o[..., None, :] + rays_d[..., None, :] * \
z_vals[..., :, None] # [N_rays, N_samples, 3]
raw = network_query_fn(pts, viewdirs, aud_para, network_fn)
rgb_map, disp_map, acc_map, weights, depth_map = raw2outputs(
raw, z_vals, rays_d, bc_rgb, raw_noise_std, white_bkgd, pytest=pytest)
if N_importance > 0:
rgb_map_0, disp_map_0, acc_map_0 = rgb_map, disp_map, acc_map
z_vals_mid = .5 * (z_vals[..., 1:] + z_vals[..., :-1])
z_samples = sample_pdf(
z_vals_mid, weights[..., 1:-1], N_importance, det=(perturb == 0.), pytest=pytest)
z_samples = z_samples.detach()
z_vals, _ = torch.sort(torch.cat([z_vals, z_samples], -1), -1)
pts = rays_o[..., None, :] + rays_d[..., None, :] * \
z_vals[..., :, None] # [N_rays, N_samples + N_importance, 3]
run_fn = network_fn if network_fine is None else network_fine
raw = network_query_fn(pts, viewdirs, aud_para, run_fn)
rgb_map, disp_map, acc_map, weights, depth_map = raw2outputs(
raw, z_vals, rays_d, bc_rgb, raw_noise_std, white_bkgd, pytest=pytest)
ret = {'rgb_map': rgb_map, 'disp_map': disp_map, 'acc_map': acc_map}
if retraw:
ret['raw'] = raw
if N_importance > 0:
ret['rgb0'] = rgb_map_0
ret['disp0'] = disp_map_0
ret['acc0'] = acc_map_0
ret['z_std'] = torch.std(z_samples, dim=-1, unbiased=False) # [N_rays]
ret['last_weight'] = weights[..., -1]
for k in ret:
if (torch.isnan(ret[k]).any() or torch.isinf(ret[k]).any()) and DEBUG:
print(f"! [Numerical Error] {k} contains nan or inf.")
return ret
def config_parser():
import configargparse
parser = configargparse.ArgumentParser()
parser.add_argument('--config', is_config_file=True,
help='config file path')
parser.add_argument("--expname", type=str,
help='experiment name')
parser.add_argument("--basedir", type=str, default='./logs/',
help='where to store ckpts and logs')
parser.add_argument("--datadir", type=str, default='./data/llff/fern',
help='input data directory')
# training options
parser.add_argument("--netdepth", type=int, default=8,
help='layers in network')
parser.add_argument("--netwidth", type=int, default=256,
help='channels per layer')
parser.add_argument("--netdepth_fine", type=int, default=8,
help='layers in fine network')
parser.add_argument("--netwidth_fine", type=int, default=256,
help='channels per layer in fine network')
parser.add_argument("--N_rand", type=int, default=1024,
help='batch size (number of random rays per gradient step)')
parser.add_argument("--lrate", type=float, default=5e-4,
help='learning rate')
parser.add_argument("--lrate_decay", type=int, default=250,
help='exponential learning rate decay (in 1000 steps)')
parser.add_argument("--chunk", type=int, default=1024,
help='number of rays processed in parallel, decrease if running out of memory')
parser.add_argument("--netchunk", type=int, default=1024*64,
help='number of pts sent through network in parallel, decrease if running out of memory')
parser.add_argument("--no_batching", action='store_false',
help='only take random rays from 1 image at a time')
parser.add_argument("--no_reload", action='store_true',
help='do not reload weights from saved ckpt')
parser.add_argument("--ft_path", type=str, default=None,
help='specific weights npy file to reload for coarse network')
parser.add_argument("--N_iters", type=int, default=400000,
help='number of iterations')
# rendering options
parser.add_argument("--N_samples", type=int, default=16,
help='number of coarse samples per ray')
parser.add_argument("--N_importance", type=int, default=128,
help='number of additional fine samples per ray')
parser.add_argument("--perturb", type=float, default=1.,
help='set to 0. for no jitter, 1. for jitter')
parser.add_argument("--use_viewdirs", action='store_false',
help='use full 5D input instead of 3D')
parser.add_argument("--i_embed", type=int, default=0,
help='set 0 for default positional encoding, -1 for none')
parser.add_argument("--multires", type=int, default=10,
help='log2 of max freq for positional encoding (3D location)')
parser.add_argument("--multires_views", type=int, default=4,
help='log2 of max freq for positional encoding (2D direction)')
parser.add_argument("--raw_noise_std", type=float, default=0.,
help='std dev of noise added to regularize sigma_a output, 1e0 recommended')
# 只渲染,不进行优化等训练操作,相当于前向传播
parser.add_argument("--render_only", action='store_true',
help='do not optimize, reload weights and render out render_poses path')
parser.add_argument("--render_test", action='store_true',
help='render the test set instead of render_poses path')
parser.add_argument("--render_factor", type=int, default=0,
help='downsampling factor to speed up rendering, set 4 or 8 for fast preview')
# training options
parser.add_argument("--precrop_iters", type=int, default=0,
help='number of steps to train on central crops')
parser.add_argument("--precrop_frac", type=float,
default=.5, help='fraction of img taken for central crops')
# dataset options
parser.add_argument("--dataset_type", type=str, default='audface',
help='options: llff / blender / deepvoxels')
parser.add_argument("--testskip", type=int, default=8,
help='will load 1/N images from test/val sets, useful for large datasets like deepvoxels')
# deepvoxels flags
parser.add_argument("--shape", type=str, default='greek',
help='options : armchair / cube / greek / vase')
# blender flags
parser.add_argument("--white_bkgd", action='store_false',
help='set to render synthetic data on a white bkgd (always use for dvoxels)')
parser.add_argument("--half_res", action='store_true',
help='load blender synthetic data at 400x400 instead of 800x800')
# face flags
parser.add_argument("--with_test", type=int, default=0,
help='whether to use test set')
parser.add_argument("--dim_aud", type=int, default=64,
help='dimension of audio features for NeRF')
parser.add_argument("--sample_rate", type=float, default=0.95,
help="sample rate in a bounding box")
parser.add_argument("--near", type=float, default=0.3,
help="near sampling plane")
parser.add_argument("--far", type=float, default=0.9,
help="far sampling plane")
parser.add_argument("--test_file", type=str, default='transforms_test.json',
help='test file')
parser.add_argument("--aud_file", type=str, default='aud.npy',
help='test audio deepspeech file')
parser.add_argument("--win_size", type=int, default=16,
help="windows size of audio feature")
parser.add_argument("--smo_size", type=int, default=8,
help="window size for smoothing audio features")
parser.add_argument('--nosmo_iters', type=int, default=200000,
help='number of iterations befor applying smoothing on audio features')
# llff flags
parser.add_argument("--factor", type=int, default=8,
help='downsample factor for LLFF images')
parser.add_argument("--no_ndc", action='store_true',
help='do not use normalized device coordinates (set for non-forward facing scenes)')
parser.add_argument("--lindisp", action='store_true',
help='sampling linearly in disparity rather than depth')
parser.add_argument("--spherify", action='store_true',
help='set for spherical 360 scenes')
parser.add_argument("--llffhold", type=int, default=8,
help='will take every 1/N images as LLFF test set, paper uses 8')
# logging/saving options
parser.add_argument("--i_print", type=int, default=100,
help='frequency of console printout and metric loggin')
parser.add_argument("--i_img", type=int, default=500,
help='frequency of tensorboard image logging')
parser.add_argument("--i_weights", type=int, default=10000,
help='frequency of weight ckpt saving')
parser.add_argument("--i_testset", type=int, default=10000,
help='frequency of testset saving')
parser.add_argument("--i_video", type=int, default=50000,
help='frequency of render_poses video saving')
return parser
def train():
parser = config_parser()
args = parser.parse_args()
# Load data
'''
load_audface_data():
这个函数的目的是加载音频-视觉人脸识别任务的数据集。函数根据输入的参数和文件路径,加载训练集、验证集或测试集的图像数据、姿态数据、音频数据和其他相关信息。
具体来说,函数的目的是:
如果指定了测试集文件(test_file),则加载该测试集的元数据和音频特征数据。
函数返回测试集的姿态数据、音频数据、背景图像、图像尺寸和中心点坐标等信息。
如果未指定测试集文件,函数会加载训练集和验证集的元数据和音频特征数据。函数将训练集和验证集的图像数据、姿态数据、音频数据和样本矩形区域数据合并,
并返回合并后的数据以及背景图像、图像尺寸和中心点坐标等信息。
因此,该函数的主要目的是加载用于音频-视觉人脸识别任务的数据集,并提供方便访问和使用数据的接口。
'''
args.datadir = '/home/sza/AD-NeRF/dataset/Obama' # config.txt文件
args.basedir = '/home/sza/AD-NeRF/dataset/Obama/logs' # 指定实验结果的输出路径
if args.dataset_type == 'audface':
if args.with_test == 1:# 是否使用测试集
poses, auds, bc_img, hwfcxy = \
load_audface_data(args.datadir, args.testskip,
args.test_file, args.aud_file)
images = np.zeros(1)
else:
images, poses, auds, bc_img, hwfcxy, sample_rects, mouth_rects, i_split = load_audface_data(
args.datadir, args.testskip)
print('Loaded audface', images.shape, hwfcxy, args.datadir)
if args.with_test == 0:
i_train, i_val = i_split
near = args.near
far = args.far
else:
print('Unknown dataset type', args.dataset_type, 'exiting')
return
# Cast intrinsics to right types
# 将内在函数转换为正确的类型
H, W, focal, cx, cy = hwfcxy
H, W = int(H), int(W)
hwf = [H, W, focal]
hwfcxy = [H, W, focal, cx, cy]
# if args.render_test:
# render_poses = np.array(poses[i_test])
# Create log dir and copy the config file
'''
创建日志目录并复制配置文件。
首先,代码获取了args.basedir和args.expname的值,用于构建日志目录的路径。args.basedir是指定实验结果的输出路径,args.expname是实验名称。
'''
args.expname = 'Obama_com'
basedir = args.basedir
absolute_path = os.path.abspath(basedir)
expname = args.expname
'''
使用os.makedirs函数创建日志目录,如果该目录已经存在,则不进行任何操作。
这里在expname目录下生成args.txt和config.txt文件
其中args.txt文件是是用来保存之前设置的所有arg配置
for arg in sorted(vars(args)):
attr = getattr(args, arg)
file.write('{} = {}\n'.format(arg, attr))
而config则是读取制作数据集的产生的文件中'
HeadNeRF_config.txt
TorsoNeRF_config.txt
TorsoNeRFTest_config.txt
'''
os.makedirs(os.path.join(basedir, expname), exist_ok=True)
f = os.path.join(basedir, expname, 'args.txt')
with open(f, 'w') as file:
for arg in sorted(vars(args)):
attr = getattr(args, arg)
file.write('{} = {}\n'.format(arg, attr))
if args.config is not None:
f = os.path.join(basedir, expname, 'config.txt')
with open(f, 'w') as file:
file.write(open(args.config, 'r').read())
# Create nerf model
# 通过这段代码,NERF模型、音频网络(`AudNet`)和音频注意力网络(`AudAttNet`)被创建,并加载了之前训练的状态,以便从之前的训练中继续训练或进行推断。
'''
首先,调用`create_nerf(args)`函数创建NERF模型所需的参数和对象。
该函数返回了训练和测试的渲染参数`render_kwargs_train`和`render_kwargs_test`,
优化器`optimizer`,起始训练步骤`start`,可训练变量`grad_vars`,学习到的代码`learned_codes`,以及与音频网络(`AudNet`)相关的状态和优化器状态。
'''
render_kwargs_train, render_kwargs_test, start, grad_vars, optimizer, \
learned_codes, AudNet_state, optimizer_aud_state, AudAttNet_state, optimizer_audatt_state \
= create_nerf(args)
global_step = start
'''
AudioAttNet模型具有注意力机制,而AudioNet模型是一个编码器模型。
根据给定的参数创建音频网络(`AudNet`)和音频注意力网络(`AudAttNet`)。
`AudNet`是一个接收音频输入并生成相应特征的网络模型,而`AudAttNet`是一个用于音频注意力的网络模型。这两个网络被移动到指定的设备(如GPU)上。
'''
AudNet = AudioNet(args.dim_aud, args.win_size).to(device)
AudAttNet = AudioAttNet().to(device)
'''
使用`torch.optim.Adam`函数创建两个优化器`optimizer_Aud`和`optimizer_AudAtt`,用于分别优化`AudNet`和`AudAttNet`的参数。这些优化器将被用于在训练过程中更新网络的权重。
'''
optimizer_Aud = torch.optim.Adam(
params=list(AudNet.parameters()), lr=args.lrate, betas=(0.9, 0.999))
optimizer_AudAtt = torch.optim.Adam(
params=list(AudAttNet.parameters()), lr=args.lrate, betas=(0.9, 0.999))
'''
加载先前保存的模型状态字典(`AudNet_state`、`optimizer_aud_state`、`AudAttNet_state`和`optimizer_audatt_state`),
将之前训练的模型状态恢复到相应的网络和优化器中。如果之前没有保存的模型状态,则跳过此步骤。
'''
if AudNet_state is not None:
AudNet.load_state_dict(AudNet_state, strict=False)
if optimizer_aud_state is not None:
optimizer_Aud.load_state_dict(optimizer_aud_state)
if AudAttNet_state is not None:
AudAttNet.load_state_dict(AudAttNet_state, strict=False)
if optimizer_audatt_state is not None:
optimizer_AudAtt.load_state_dict(optimizer_audatt_state)
bds_dict = {
'near': near,
'far': far,
}
'''
将近场和远场的边界距离(`near`和`far`)作为字典添加到`render_kwargs_train`和`render_kwargs_test`中。这些参数将用于指定NERF模型的工作范围。
'''
render_kwargs_train.update(bds_dict)
render_kwargs_test.update(bds_dict)
# Move training data to GPU
bc_img = torch.Tensor(bc_img).to(device).float()/255.0
poses = torch.Tensor(poses).to(device).float()
auds = torch.Tensor(auds).to(device).float()
# 只渲染,不进行优化等训练操作,相当于前向传播
if args.render_only:# 默认为False
print('RENDER ONLY')
with torch.no_grad():
# Default is smoother render_poses path
images = None
testsavedir = os.path.join(basedir, expname, 'renderonly_{}_{:06d}'.format(
'test' if args.render_test else 'path', start))
os.makedirs(testsavedir, exist_ok=True)
print('test poses shape', poses.shape)
auds_val = AudNet(auds)
rgbs, disp, last_weight = render_path(poses, auds_val, bc_img, hwfcxy, args.chunk, render_kwargs_test,
gt_imgs=images, savedir=testsavedir, render_factor=args.render_factor)
np.save(os.path.join(testsavedir, 'last_weight.npy'), last_weight)
print('Done rendering', testsavedir)
imageio.mimwrite(os.path.join(
testsavedir, 'video.mp4'), to8b(rgbs), fps=30, quality=8)
return
num_frames = images.shape[0]
'''
通过这段代码,NERF模型、音频网络(`AudNet`)和音频注意力网络(`AudAttNet`)被创建,并加载了之前训练的状态,以便从之前的训练中继续训练或进行推断。
'''
# Prepare raybatch tensor if batching random rays
N_rand = args.N_rand
print('N_rand', N_rand, 'no_batching',
args.no_batching, 'sample_rate', args.sample_rate)
use_batching = not args.no_batching
if use_batching:
# For random ray batching
print('get rays')
rays = np.stack([get_rays_np(H, W, focal, p, cx, cy)
for p in poses[:, :3, :4]], 0) # [N, ro+rd, H, W, 3]
print('done, concats')
# [N, ro+rd+rgb, H, W, 3]
rays_rgb = np.concatenate([rays, images[:, None]], 1)
# [N, H, W, ro+rd+rgb, 3]
rays_rgb = np.transpose(rays_rgb, [0, 2, 3, 1, 4])
rays_rgb = np.stack([rays_rgb[i]
for i in i_train], 0) # train images only
# [(N-1)*H*W, ro+rd+rgb, 3]
rays_rgb = np.reshape(rays_rgb, [-1, 3, 3])
rays_rgb = rays_rgb.astype(np.float32)
print('shuffle rays')
np.random.shuffle(rays_rgb)
print('done')
i_batch = 0
if use_batching:
rays_rgb = torch.Tensor(rays_rgb).to(device)
N_iters = args.N_iters + 1
print('Begin')
print('TRAIN views are', i_train)
print('VAL views are', i_val)
start = start + 1
for i in trange(start, N_iters):
time0 = time.time()
# Sample random ray batch
if use_batching:
# Random over all images
batch = rays_rgb[i_batch:i_batch+N_rand] # [B, 2+1, 3*?]
batch = torch.transpose(batch, 0, 1)
batch_rays, target_s = batch[:2], batch[2]
i_batch += N_rand
if i_batch >= rays_rgb.shape[0]:
print("Shuffle data after an epoch!")
rand_idx = torch.randperm(rays_rgb.shape[0])
rays_rgb = rays_rgb[rand_idx]
i_batch = 0
else:
'''
从i_train数组中随机选择一个索引img_i,表示选择一个训练图像。
'''
# Random from one image
img_i = np.random.choice(i_train)
'''
使用imageio.imread()函数读取图像数据,并将其转换为torch.Tensor类型,并将像素值缩放到范围[0, 1]之间。
'''
target = torch.as_tensor(imageio.imread(
images[img_i])).to(device).float()/255.0
'''
从poses数组中获取对应的姿态矩阵pose。
从sample_rects数组中获取采样矩形区域rect。
从mouth_rects数组中获取嘴部矩形区域mouth_rect。
从auds数组中获取对应的音频特征aud。
'''
pose = poses[img_i, :3, :4]
rect = sample_rects[img_i]
mouth_rect = mouth_rects[img_i]
aud = auds[img_i]
if global_step >= args.nosmo_iters:# 我这里是站global=149999 nosmo_iters=200000
'''
如果global_step大于等于args.nosmo_iters,进行平滑处理:
根据args.smo_size的一半大小获取左右相邻的音频特征窗口范围。
对超出范围的部分进行填充。
使用AudAttNet对音频特征窗口进行处理,得到平滑后的音频特征aud_smo。
'''
smo_half_win = int(args.smo_size / 2)
left_i = img_i - smo_half_win
right_i = img_i + smo_half_win
pad_left, pad_right = 0, 0
if left_i < 0:
pad_left = -left_i
left_i = 0
if right_i > i_train.shape[0]:
pad_right = right_i-i_train.shape[0]
right_i = i_train.shape[0]
auds_win = auds[left_i:right_i]
if pad_left > 0:
auds_win = torch.cat(
(torch.zeros_like(auds_win)[:pad_left], auds_win), dim=0)
if pad_right > 0:
auds_win = torch.cat(
(auds_win, torch.zeros_like(auds_win)[:pad_right]), dim=0)
auds_win = AudNet(auds_win)
aud = auds_win[smo_half_win]
aud_smo = AudAttNet(auds_win)
else:
'''
如果global_step小于args.nosmo_iters,直接使用AudNet对音频特征进行处理,得到处理后的音频特征aud。
'''
aud = AudNet(aud.unsqueeze(0))
if N_rand is not None:
'''
如果N_rand不为None,进行随机采样:
根据图像尺寸、相机参数和姿态矩阵获取射线的起点和方向。
如果迭代次数小于args.precrop_iters,进行中心裁剪,裁剪尺寸为图像尺寸的一半乘以args.precrop_frac。
对于每个采样点,判断是否在rect区域内,将其分为在区域内和在区域外的点。
根据采样率选择在区域内和在区域外的点,使得采样点数满足N_rand要求。
根据选择的采样点坐标从目标图像和背景图像中提取对应的像素值。
'''
rays_o, rays_d = get_rays(
H, W, focal, torch.Tensor(pose), cx, cy) # (H, W, 3), (H, W, 3)
if i < args.precrop_iters:
dH = int(H//2 * args.precrop_frac)
dW = int(W//2 * args.precrop_frac)
coords = torch.stack(
torch.meshgrid(
torch.linspace(H//2 - dH, H//2 + dH - 1, 2*dH),
torch.linspace(W//2 - dW, W//2 + dW - 1, 2*dW)
), -1)
if i == start:
print(
f"[Config] Center cropping of size {2*dH} x {2*dW} is enabled until iter {args.precrop_iters}")
else:
coords = torch.stack(torch.meshgrid(torch.linspace(
0, H-1, H), torch.linspace(0, W-1, W)), -1) # (H, W, 2)
coords = torch.reshape(coords, [-1, 2]) # (H * W, 2)
if args.sample_rate > 0:
rect_inds = (coords[:, 0] >= rect[0]) & (
coords[:, 0] <= rect[0] + rect[2]) & (
coords[:, 1] >= rect[1]) & (
coords[:, 1] <= rect[1] + rect[3])
coords_rect = coords[rect_inds]
coords_norect = coords[~rect_inds]
rect_num = int(N_rand*args.sample_rate)
norect_num = N_rand - rect_num
select_inds_rect = np.random.choice(
coords_rect.shape[0], size=[rect_num], replace=False) # (N_rand,)
# (N_rand, 2)
select_coords_rect = coords_rect[select_inds_rect].long()
select_inds_norect = np.random.choice(
coords_norect.shape[0], size=[norect_num], replace=False) # (N_rand,)
# (N_rand, 2)
select_coords_norect = coords_norect[select_inds_norect].long(
)
select_coords = torch.cat(
(select_coords_rect, select_coords_norect), dim=0)
else:
select_inds = np.random.choice(
coords.shape[0], size=[N_rand], replace=False) # (N_rand,)
select_coords = coords[select_inds].long()
'''
返回采样得到的数据,包括射线起点、射线方向、目标图像的采样像素值和背景图像的采样像素值。
'''
rays_o = rays_o[select_coords[:, 0],
select_coords[:, 1]] # (N_rand, 3)
rays_d = rays_d[select_coords[:, 0],
select_coords[:, 1]] # (N_rand, 3)
batch_rays = torch.stack([rays_o, rays_d], 0)
target_s = target[select_coords[:, 0],
select_coords[:, 1]] # (N_rand, 3)
bc_rgb = bc_img[select_coords[:, 0],
select_coords[:, 1]]
##### Core optimization loop #####
'''
这段代码是核心的优化循环,用于执行模型的前向传播和计算损失。
'''
if global_step >= args.nosmo_iters:
'''
如果global_step大于等于args.nosmo_iters,使用平滑后的音频特征aud_smo进行渲染;
'''
rgb, disp, acc, _, extras = render_dynamic_face(H, W, focal, cx, cy, chunk=args.chunk, rays=batch_rays,
aud_para=aud_smo, bc_rgb=bc_rgb,
verbose=i < 10, retraw=True,
**render_kwargs_train)
else:
'''
否则,使用原始音频特征aud进行渲染。调用render_dynamic_face()函数进行面部渲染,根据给定的参数生成渲染的RGB图像、视差图、累积图以及其他附加信息。
'''
rgb, disp, acc, _, extras = render_dynamic_face(H, W, focal, cx, cy, chunk=args.chunk, rays=batch_rays,
aud_para=aud, bc_rgb=bc_rgb,
verbose=i < 10, retraw=True,
**render_kwargs_train)
'''
使用优化器对象optimizer、optimizer_Aud和optimizer_AudAtt将梯度置零,准备进行反向传播和参数更新。
'''
optimizer.zero_grad()
optimizer_Aud.zero_grad()
optimizer_AudAtt.zero_grad()
'''
计算图像损失,使用img2mse()函数计算渲染的RGB图像与目标图像之间的均方误差(MSE)损失。
'''
img_loss = img2mse(rgb, target_s)
trans = extras['raw'][..., -1]
loss = img_loss
'''
使用mse2psnr()函数计算图像损失的峰值信噪比(PSNR)。
'''
psnr = mse2psnr(img_loss)
if 'rgb0' in extras:
img_loss0 = img2mse(extras['rgb0'], target_s)
loss = loss + img_loss0
psnr0 = mse2psnr(img_loss0)
'''
使用loss.backward()进行损失的反向传播,计算梯度。
'''
loss.backward()
'''
使用optimizer.step()和optimizer_Aud.step()分别更新nerf模型和音频特征模型的参数。
'''
optimizer.step()
optimizer_Aud.step()
if global_step >= args.nosmo_iters:
'''
如果global_step大于等于args.nosmo_iters,使用optimizer_AudAtt.step()更新注意力模型的参数。
'''
optimizer_AudAtt.step()
# NOTE: IMPORTANT!
### update learning rate ###
''''
定义学习率衰减的参数。decay_rate表示衰减率,取值为0.1,表示每个衰减步骤学习率减小到原来的10%。
decay_steps表示衰减步骤的总数,计算为args.lrate_decay乘以1000,
表示每1000个步骤进行一次学习率衰减。
'''
decay_rate = 0.1
decay_steps = args.lrate_decay * 1000
'''
根据当前的全局步骤global_step和衰减步骤数,计算新的学习率new_lrate。采用指数衰减的方式,将初始学习率args.lrate乘以衰减率的指数函数。
'''
new_lrate = args.lrate * (decay_rate ** (global_step / decay_steps))
for param_group in optimizer.param_groups:
'''
遍历优化器optimizer的参数组,并将学习率更新为new_lrate。
'''
param_group['lr'] = new_lrate
for param_group in optimizer_Aud.param_groups:
'''
遍历音频特征优化器optimizer_Aud的参数组,并将学习率更新为new_lrate。
'''
param_group['lr'] = new_lrate
for param_group in optimizer_AudAtt.param_groups:
'''
遍历注意力模型优化器optimizer_AudAtt的参数组,并将学习率更新为new_lrate的5倍。
'''
param_group['lr'] = new_lrate*5
################################
dt = time.time()-time0
# Rest is logging
if i % args.i_weights == 0:
path = os.path.join(basedir, expname, '{:06d}_head.tar'.format(i))
torch.save({
'global_step': global_step,
'network_fn_state_dict': render_kwargs_train['network_fn'].state_dict(),
'network_fine_state_dict': render_kwargs_train['network_fine'].state_dict(),
'network_audnet_state_dict': AudNet.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'optimizer_aud_state_dict': optimizer_Aud.state_dict(),
'network_audattnet_state_dict': AudAttNet.state_dict(),
'optimizer_audatt_state_dict': optimizer_AudAtt.state_dict(),
}, path)
print('Saved checkpoints at', path)
if i % args.i_testset == 0 and i > 0:
testsavedir = os.path.join(
basedir, expname, 'testset_{:06d}'.format(i))
os.makedirs(testsavedir, exist_ok=True)
print('test poses shape', poses[i_val].shape)
auds_val = AudNet(auds[i_val])
with torch.no_grad():
render_path(torch.Tensor(poses[i_val]).to(
device), auds_val, bc_img, hwfcxy, args.chunk, render_kwargs_test, gt_imgs=None, savedir=testsavedir)
print('Saved test set')
if i % args.i_print == 0:
tqdm.write(
f"[TRAIN] Iter: {i} Loss: {loss.item()} PSNR: {psnr.item()}")
global_step += 1
if __name__ == '__main__':
torch.set_default_tensor_type('torch.cuda.FloatTensor')
train()














 7489
7489











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









