






文章目录
前言
详解tensorRT的高性能部署方案,并附有强大的yolov5、yolox、retinaface、arcface、scrfd、deepsort、alphapose的高性能实现,低耦合,哪来即可用,集成到项目中
repo地址:https://github.com/shouxieai/tensorRT_cpp
准备工作
安装之前请先安装好CUDA、cuDNN、TensorRT和Pytorch
Jetson Nano CUDA、cuDNN、TensorRT与Pytorch环境配置
protobuf-3.11.4、tensorRT_Pro源码安装包下载
链接:https://pan.baidu.com/s/1mrIgGoMo0bq6otGhlh-E3A
提取码:6sb3
一、protobuf-3.11.4安装
安装protobuf-3.11.4依赖项
sudo apt-get install autoconf automake libtool curl make g++ unzip libffi-dev -y
卸载系统旧版本的protobuf
sudo apt-get remove libprotobuf-dev
# which protoc
#运行完“which protoc”会显示一个protoc的路径,如果没有显示则下面这条命令不必执行
rm /usr/local/bin/protoc
#具体路径以“which protoc”显示的为准
#如果原来是源代码安装的,cd 到项目目录输入sudo make uninstall
解压protobuf-3.11.4.zip,打开终端,cd进入解压的文件夹
unzip protobuf-3.11.4.zip
cd protobuf-3.11.4
编译安装
# 自动生成configure配置文件
./autogen.sh
# 配置环境
./configure
# 编译源代码(要有耐心!)
make -j4
# 安装
sudo make install
刷新共享库
sudo ldconfig
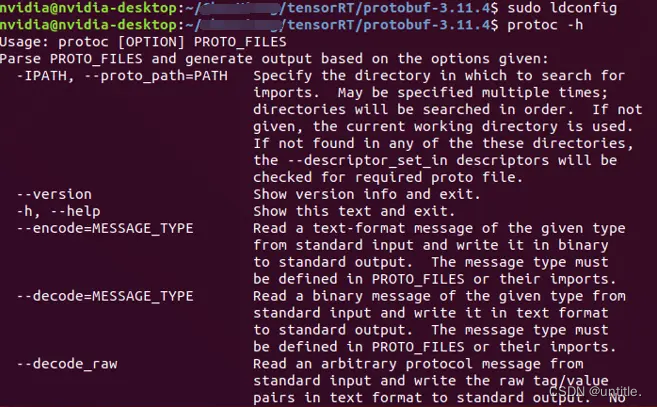
成功后需要使用命令测试
protoc -h
拉取tensorRT_Pro项目
git clone https://github.com/shouxieai/tensorRT_Pro.git
cd tensorRT_Pro
二. trtpy编译安装
2.1 修改CMakeLists.txt文件
为了libtorch和OpenCV能同时编译,在CMakeLists.txt中添加一行
set(CMAKE_CXX_FLAGS "-D_GLIBCXX_USE_CXX11_ABI=1")
设置HAS_PYTHON为ON,配置python路径,修改CUDA_GEN_CODE匹配自己的设备,Nano是“53”
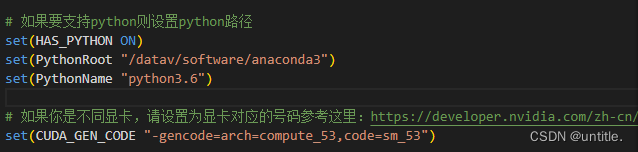
Jetson平台下Cuda环境能够自动找到CUDA、cuDNN和TensorRT文件夹路径一般不需要配置。如果编译有问题,找一下自己的路径更改一下。
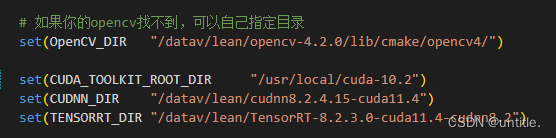
设置protobuf路径

设置include_directories,link_directories,使用系统的python3.6的include中的Python.h等头文件和python动态链接库。
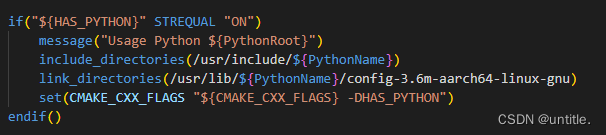
2.2 注释和删除部分代码文件
注释如下代码,编译deepsort时,在Jetson平台会报错,开发者的建议是删除和deepsort有关的cpp,所以用到deepsort的target就都注释了,接下来还需要删除与deepsort和这两个target相关代码
注释和deepsort有关的代码
删除和deepsort有关的文件
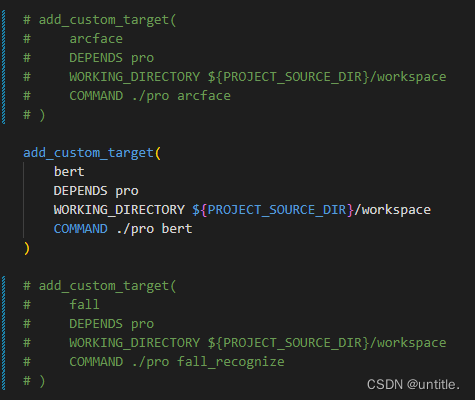
修改这里改成python3
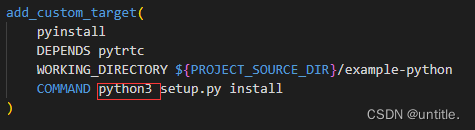
删除和deepsort有关的文件
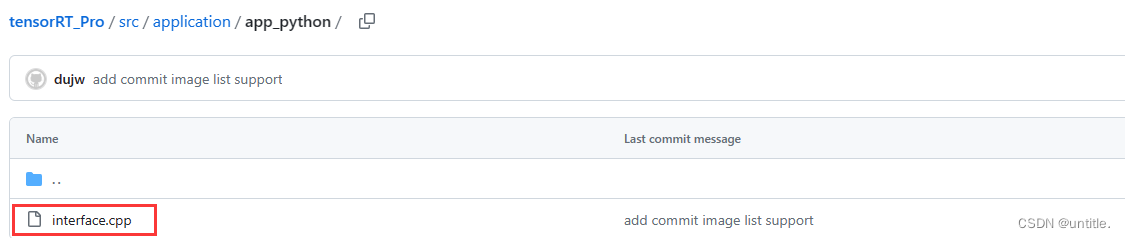
修改src/main.cpp,删除图中红框的部分,去除CMakeLists.txt中注释了的arcface和fall两个target的调用。

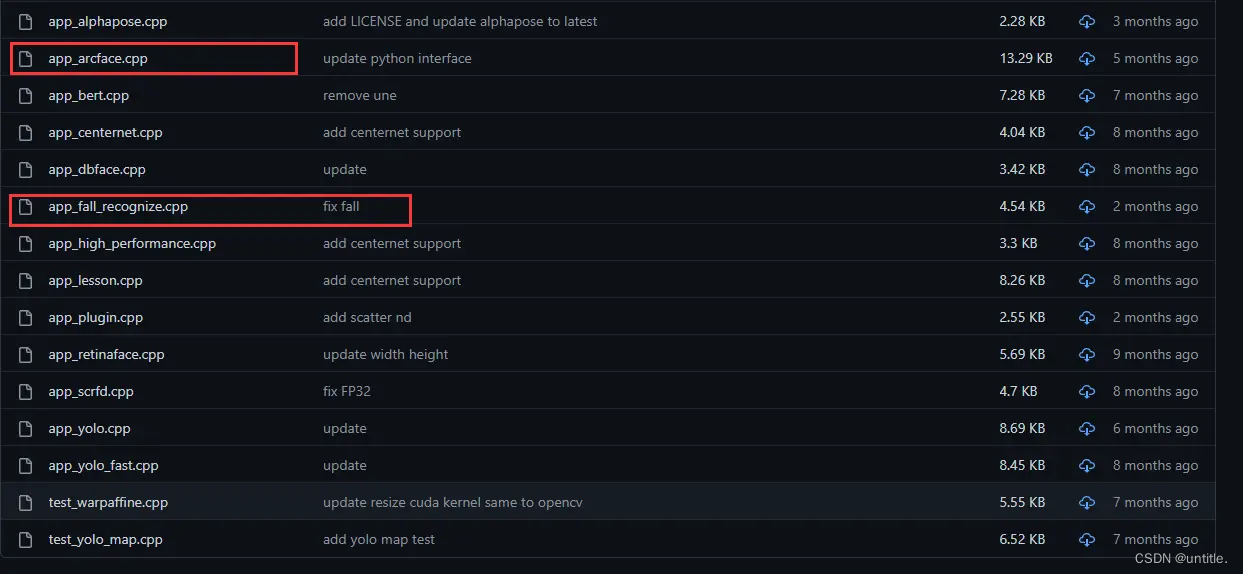
删除src\application中的app_arcface.cpp与app_fall_recognize.cpp,因为这个两个cpp都调用了deepsort。
删除src\application\tools中的deepsort相关文件。
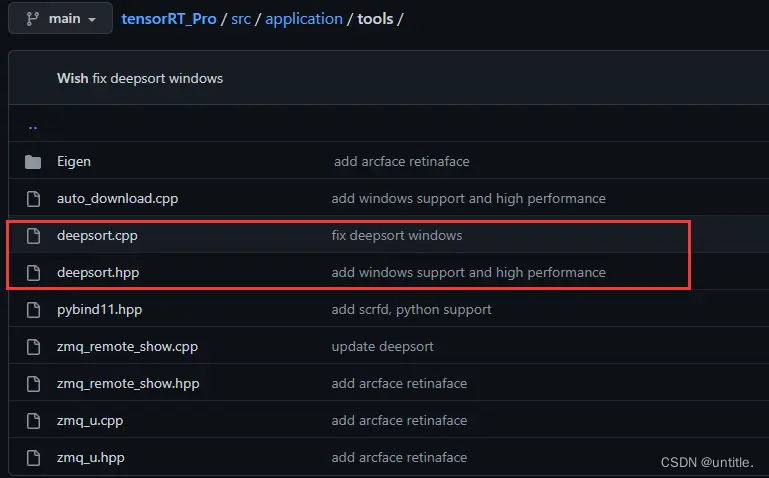
删除src\application\app_python中的deepsort相关文件。
2.3 编译安装trtpy
CMakeLists.txt修改完成后,进入tensorRT_Pro文件夹
# 打开终端,新建build文件夹并且cd进入
mkdir build && cd build
# 使用cmake生成编译相关文件
cmake ..
# 执行make yolo -j4
make yolo -j4
# 确保yolo能够正确编译后,执行make编译安装trtpy,否则请进行详细检查确保yolo编译成功
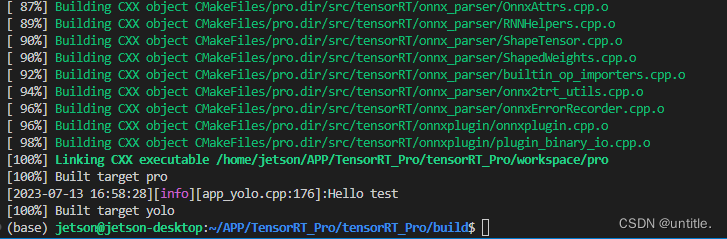
sudo make pyinstall -j4
安装完成如下图
三、部署yolov7项目
3.1 导出yolov7-tiny.onnx
拉取yolov7代码
git clone https://github.com/WongKinYiu/yolov7.git
修改代码
如果直接用官方的yolov7-tiny.pz预训练模型,则在models/yolo.py的Detect类下修改;
如果用的是自己训练的模型,用netron工具查看末尾节点是否为IDetect,若是则在models/yolo.py的IDetect类下修改;
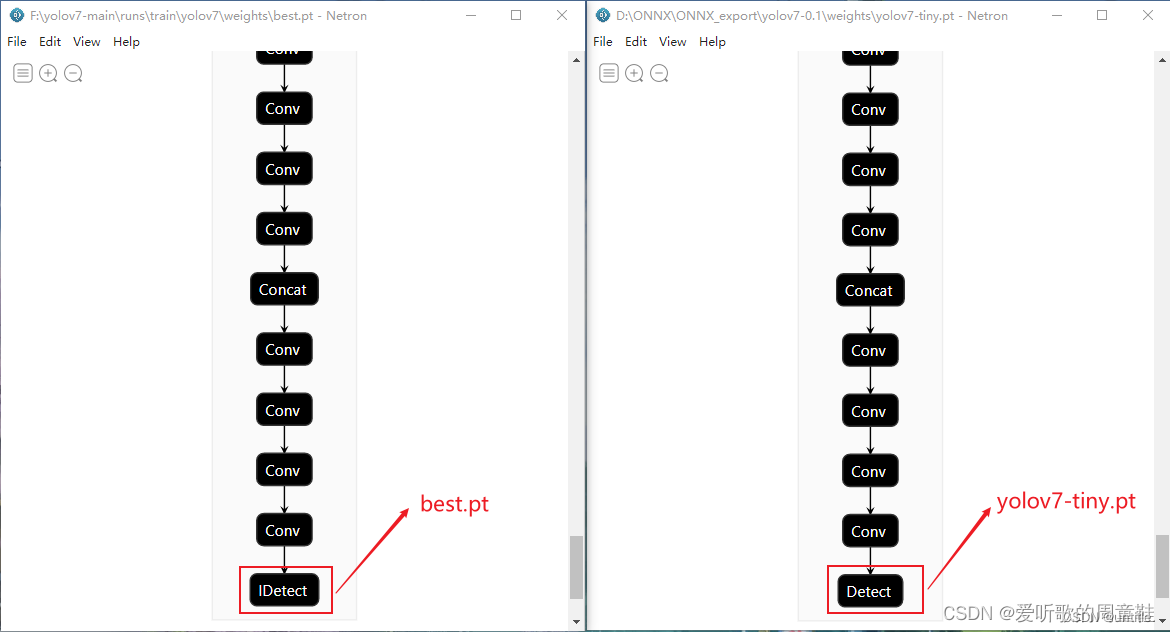
修改这三处地方
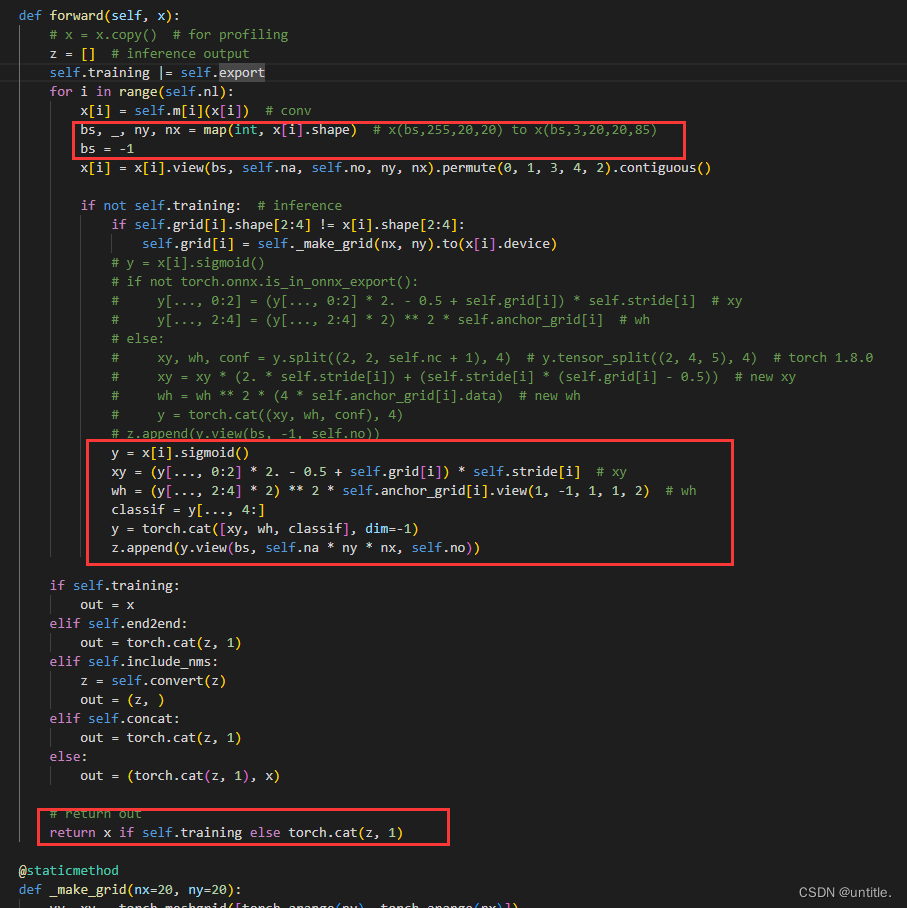
再到export.py下修改

导出onnx模型
cd yolov7
python export.py --dynamic --grid --weights=best.pt
查看网络结构
netron yolov7-tiny.onnx
结构如下图则为成功
3.2 运行
源码修改
yolo模型的推理代码主要在src/application/app_yolo.cpp文件中,需要推理的图片放在workspace/inference文件夹中,将上述修改后导出的ONNX文件放在workspace/文件夹下。源码修改较简单主要有以下几点:
若果是自己训练的模型则改动1、2、3点,使用预训练模型则改动第1、点
- app_yolo.cpp 177行 “yolov7"改成"best”,构建best.pt模型
- app_yolo.cpp 100行 cocolabels修改为mylabels
- app_yolo.cpp 25行 新增mylabels数组,添加自训练模型的类别名称
具体修改如下
test(Yolo::Type::V7, TRT::Mode::FP32, "best") //修改1 177行"yolov7"改成"best"
for(auto& obj : boxes){
...
auto name = mylabels[obj.class_label]; //修改2 100行cocolabels修改为mylabels
...
}
static const char* mylabels[] = {"have_mask", "no_mask"}; //修改3 25行新增代码,为自训练模型的类别名称
编译
编译生成可执行文件.pro,保存在workspace/文件夹下,指令如下:
$ cd tensorRT_Pro-main
$ mkdir build && cd build
$ cmake .. && make -j8
耐心等待编译完成(PS:需要一段时间),make -j参数的选取一般时以CPU核心数两倍为宜,参考自make -j参数简介,Linux下CPU核心数可通过lscpu指令查看,jetson nano的cpu核心数为4。
模型构建和推理
编译完成后的可执行文件.pro存放在workspace/文件夹下,故进入workspace文件夹下执行以下指令
$ cd workspace // 进入可执行文件目录下
$ ls // 查看当前目录下所有文件
$ ./pro yolo // 构建模型并推理
模型构建和推理图解如下所示。在workspace/文件夹下会生成best.FP32.trtmodel引擎文件用于模型推理,会生成best_Yolov7_FP32_result文件夹,该文件夹下保存了推理的图片。
参考
1、Jetson Xavier NX Trtpy安装
2、Ubuntu卸载protobuf并安装3.6.0版本的protobuf
3、OpenCV 编译链接 undefined reference to ‘cv::imread(std::string const&, int)’















 125
125











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









