






Abstract
提出了一个简单,高效而强大的语义分割框架SegFormer,它将transformer与轻量级多层感知器(MLP)解码器结合在一起。 SegFormer有两个吸引人的特点:1)SegFormer包括一个新颖的分层结构的变压器编码器,输出多尺度特征。 它不需要位置编码,从而避免了当测试分辨率与训练分辨率不同时插入位置编码导致性能下降的问题。 2) SegFormer避免复杂的解码器。 所提出的MLP解码器聚合了来自不同层的信息,从而结合了局部注意和全局注意来呈现强大的表示。 我们表明,这种简单和轻量级的设计是有效分割变压器的关键。 我们扩展了我们的方法,获得了从SegFormer-B0到SegFormer-B5的一系列模型,达到了比以前的同行更好的性能和效率。 例如,SegFormer-B4在ADE20K上使用64M参数实现了50.3%的mIoU,比之前的最佳方法小5倍,提高了2.2%。 我们的最佳模型SegFormer-B5在cityscape验证集上实现了84.0%的mIoU,并且在cityscape - c上显示了出色的零射击鲁棒性。
Introduction
FCN做语义分割:FCN将传统CNN后面的全连接层换成了卷积层,进行了一个上采样的操作,恢复到与输入图像一样的大小,以便对每个像素进行分类。
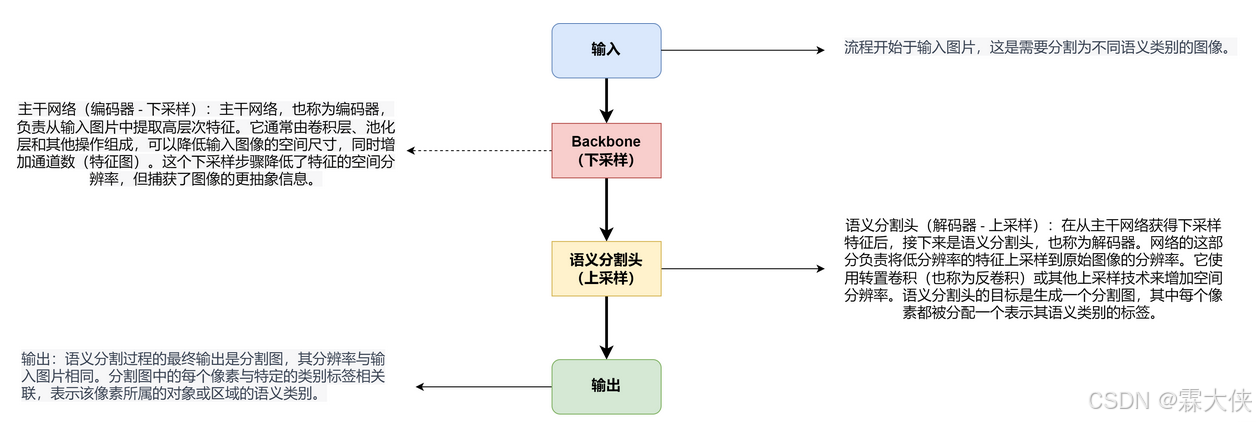
语义分割的两个主要研究领域
1、Backbone设计:经典的卷积神经网络VGG、ResNet、EfficientNet等等
2、将语义分割视为结构化预测问题:一个典型的解决方案就是膨胀卷积,通过在卷积核中插入“空洞”(间隔)来扩大感受野(即覆盖的像素范围),而不增加计算量或降低分辨率。
ViT做图像分类
SETR采用ViT作为主干,并结合多个CNN解码器来提高特征分辨率,1)ViT输出的是单尺度低分辨率特征,而不是多尺度特征。 2)在大图像上计算成本高。
PVT视觉金字塔:考虑了多尺度
这些方法主要考虑的是Transformer编码器的设计,而忽略了解码器对进一步改进的贡献。
本文的创新点:
- 一种新的无位置编码的分层transformer编码器。分层部分使编码器能够同时生成高分辨率的精细特征和低分辨率的粗特征,这与ViT只能生成单个固定分辨率的低分辨率特征图形成了鲜明对比。
- 一种轻量级的All-MLP解码器设计,产生强大的表示,没有复杂和计算要求高的模块。通过聚合来自不同层的信息,MLP解码器结合了本地和全局attention。
Related Work
Semantic Segmentation:语义分割可以看作是图像分类从图像级到像素级的扩展,基础性的工作就是FCN,有好多方法都是对FCN做改进的。
Transformer backbones:提出ViT用于图像分类,达到最好的性能
DETR是第一个用transformers做目标检测的端到端的框架 ,而且没有NMS;SETR采用ViT作为主干提取特征,取得了令人印象深刻的性能
Method
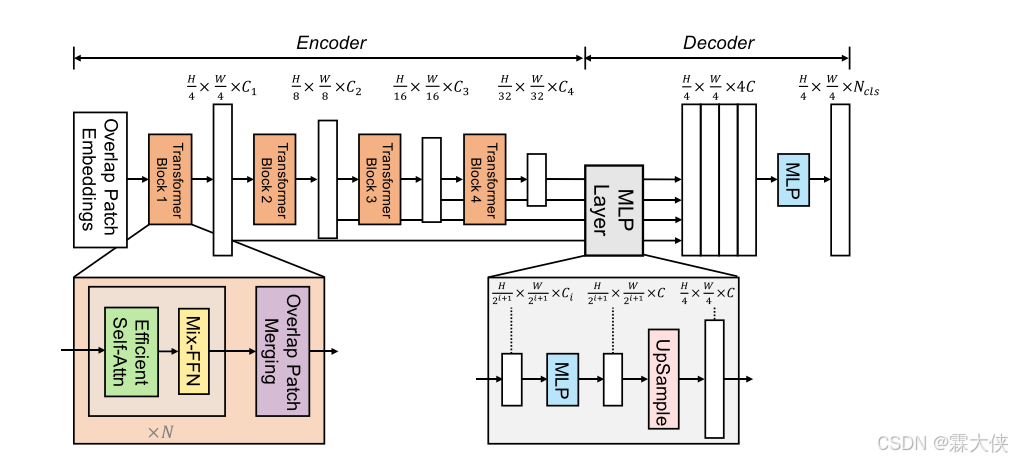
Hierarchical Transformer Encoder


Effient Self-Attention:在原始的多头自注意力过程中,每个头的查询(Q)、键(K)和值(V)具有相同的维度 N×C,其中 N=H×W是序列的长度。
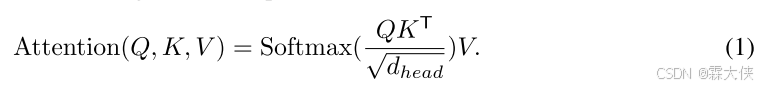
计算复杂度是O(N2)

重塑:改变张量的形状,但是不改变其数据,就像k帽,原始序列的长度N被R除,而特征维度C被 R乘。这样,虽然序列的长度减少了,但是每个元素的特征维度增加了
线性变换:是通过一个线性层(通常是一个全连接层或矩阵乘法)来改变张量的特征维度。
Mix FFN:
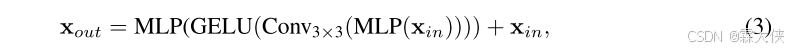
3*3卷积:Mix-FFN通过直接将3×3卷积集成到前馈网络(FFN)中,3×3卷积能够在每个位置上捕捉到周围8个像素(或特征)的信息,因此,它能够有效地学习相邻像素之间的空间关系。xin是来自自注意力模块的特征。
FFN层:通常,FFN由两层MLP组成(第一层通常是一个线性变换,第二层是激活函数)。而在Mix-FFN中,3×3卷积被插入到MLP之后,并且与MLP结合起来形成一个新的处理流程
Lightweight decoder
SegFormer集成了仅由MLP层组成的轻量级解码器,这避免了其他方法中通常使用的手工制作和计算要求高的组件。 实现这种简单解码器的关键是我们的分层变压器编码器比传统的CNN编码器具有更大的有效感受野(ERF)。

Effective Receptive Field Analysis.
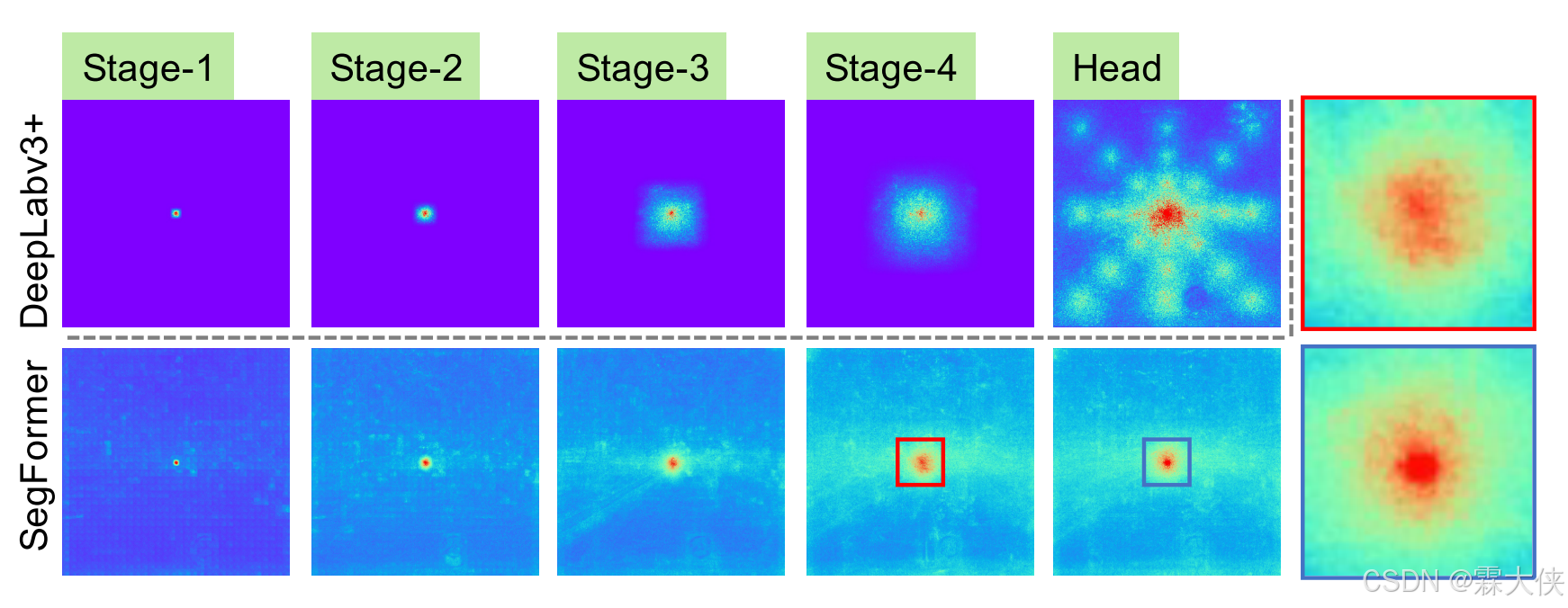
- DeepLabv3+的ERF即使在最深的stage-4也相对较小
- SegFormer的编码器自然地产生类似于较低阶段卷积的局部注意,同时能够输出高度非局部注意,有效地捕获阶段4的上下文
- 如图中的放大斑块所示,MLP头部(蓝框)的ERF与阶段4(红框)不同,除了非局部注意外,局部注意明显更强。
CNN有限的感受野需要借助诸如ASPP之类的上下文模块来扩大感受野,但不可避免地会变得沉重。 我们的解码器设计受益于Transformer中的非局部注意,并且在不复杂的情况下产生更大的感受野。 然而,相同的解码器设计在CNN主干上不能很好地工作,因为在Stage-4中,整个接受场的上限是有限的。
还有一个重要原因是我们的解码器设计本质上利用了Transformer诱导特性,该特性同时产生高度局部和非局部关注。
Relationship to SETR
- 我们只使用ImageNet-1K进行预训练。 SETR中的ViT是在更大的ImageNet-22K上预训练的。
- SegFormer的编码器具有分层结构,比ViT小,可以捕获高分辨率的粗特征和低分辨率的细特征。 相比之下,SETR的ViT编码器只能生成单个低分辨率特征图。
- 我们在编码器中去掉了位置嵌入,而SETR使用固定形状的位置嵌入,当推理分辨率与训练分辨率不同时,会降低精度。
- 我们的MLP解码器比SETR中的更紧凑,计算需求更少。 这将导致可以忽略不计的计算开销。 相比之下,SETR需要具有多个3×3卷积的重型解码器。
Experiments
Experimental Settings
Datasets:Cityscapes、ADE20K、COCO-Stuff
Implementation details:使用mmsegmentation1代码库,并在一台带有8 Tesla V100的服务器上进行训练。 我们在Imagenet-1K数据集上预训练编码器,并随机初始化解码器。 在训练过程中,我们分别对ADE20K、cityscape和COCO-Stuff进行了随机调整大小(比例为0.5-2.0)、随机水平翻转和随机裁剪至512 × 512、1024×1024、512 × 512的数据增强。 以下我们设置裁剪尺寸为640 × 640在ADE20K为我们最大的模型B5。 我们使用AdamW优化器对ADE20K、cityscape和COCO-Stuff进行160K迭代和80K迭代的模型进行训练。 特别的是,对于消融研究,我们训练模型进行40K次迭代。 我们在ADE20K和COCO-Stuff中使用了16个批次,在cityscape中使用了8个批次。 学习率设置为初始值0.00006,然后默认使用因子为1.0的“poly”LR调度。 为简单起见,我们没有采用OHEM、辅助损失或类平衡损失等广泛使用的技巧。 在评估过程中,我们将图像的短边重新调整为训练裁剪大小,并保持ADE20K和COCO-Stuff的宽高比。 对于城市景观,我们通过裁剪1024×1024窗口来使用滑动窗口测试进行推理。 我们使用平均交联(mIoU)报告语义分割性能。
Ablation Studies
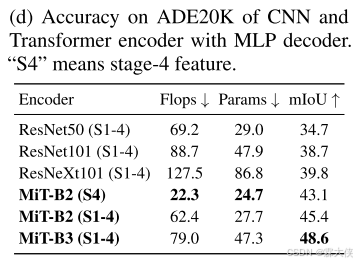
Influence of the size of model:encoder越大,在数据集上的表现效果越好
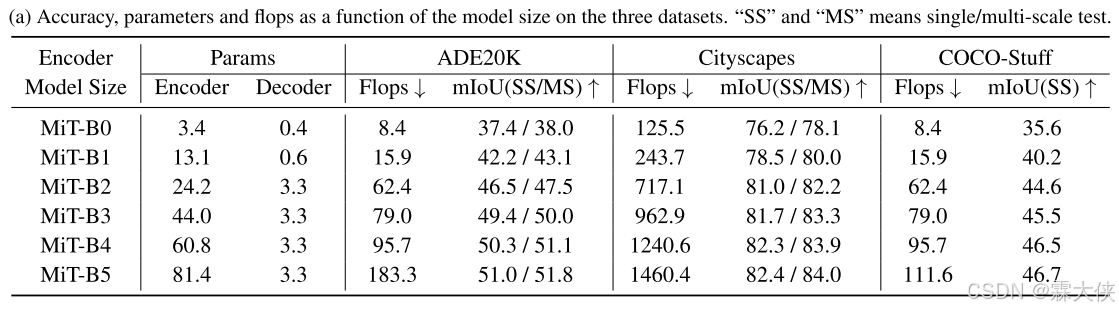
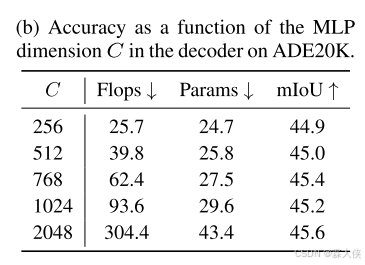
MLP解码器通道尺寸的影响:设置C = 256提供了非常有竞争力的性能和计算成本。 性能随C的增加而增加,但它会导致更大、效率更低的模型。设置C=256SegFormer-B0, B1 and 其余的C =768
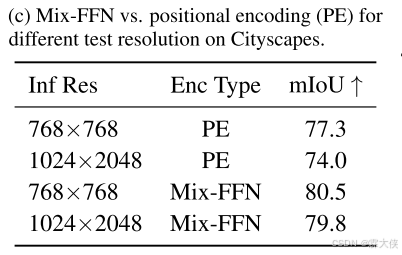
Mix-FFN:位置编码的差异
有效感受野evaluation:与其他CNN模型相比,我们的MLP解码器受益于transformer具有更大的有效感受野。


















 948
948

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









