






有什么不懂的大家可以在评论区问我,我一定会积极回复哒!!!
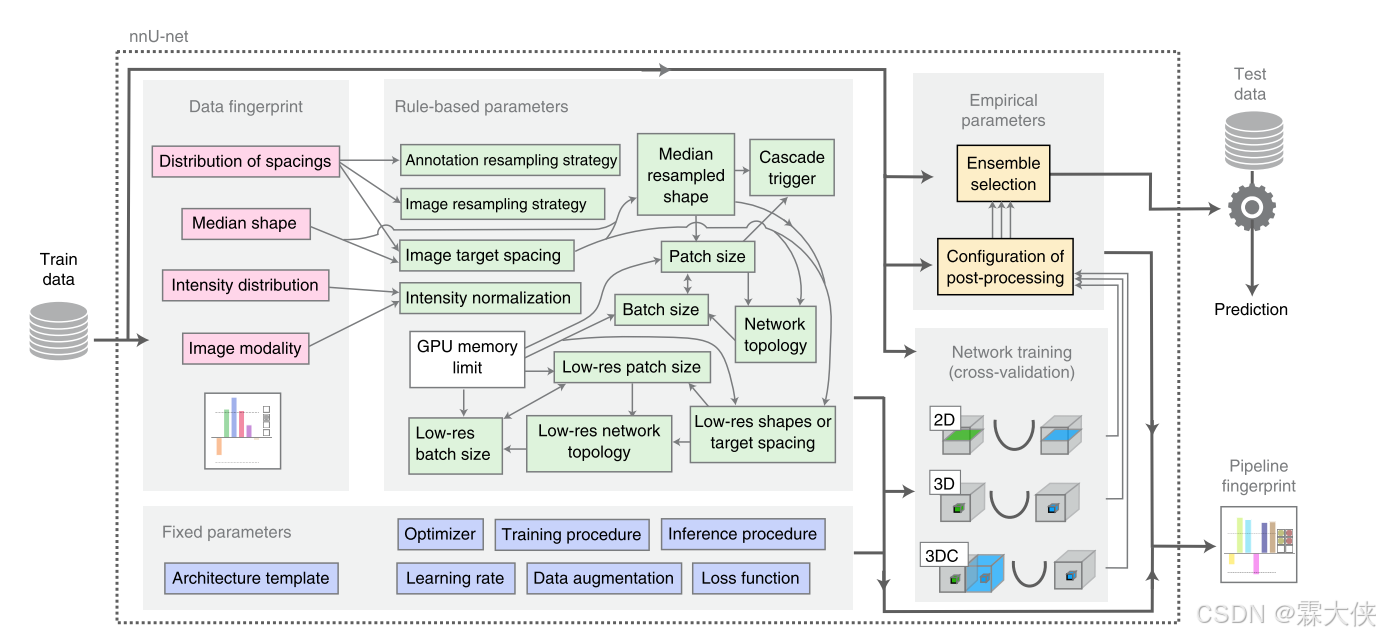
一、环境配置
首先创建一个虚拟环境
conda create -n nnunet python=3.9
conda activate nnunet然后在pytorch官网,安装pytorch,这里我安装的是2.1.2版本,numpy自动安装的是2.0.2版本,后面用的时候出错了,然后变成了1.24.1版本,这个版本是没错的。
conda install pytorch==2.5.1 torchvision==0.20.1 torchaudio==2.5.1 pytorch-cuda=11.8 -c pytorch -c nvidia在使用pip install -e .时,不要在nnUNet文件夹下创建其他文件夹,更改文件夹结构会导致报错
git clone https://github.com/MIC-DKFZ/nnUNet.git
cd nnUNet
pip install -e .二、创建数据集
接下来我们退回到文件夹中,在nnUNet文件夹中创建一个新文件夹nnUNetFrame(该文件夹名称可以自拟)
在文件夹nnUNetFrame下再创建3个文件夹:如下

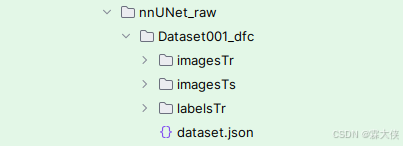
nnUNet_raw文件夹下存放数据集,数据集一定严格遵守源代码的格式,后缀是以_000x结尾的:
dataset.json文件就按照GitHub上给的实例换成自己的就行
设置环境变量,vim ~/.bashrc
export nnUNet_raw=path/to/nnUNet_raw
export nnUNet_preprocessed=path/to/nnUNet_preprocessed
export nnUNet_results=path/to/nnUNet_results然后再source ~/.bahrc就可以了
三、数据集预处理
现在的nnunetv2不用再把所有的数据集格式转换成 .nii.gz 。
默认情况下,支持以下文件格式:
- NaturalImage2DIO:.png、.bmp、.tif
- NibabelIO:.nii.gz、.nrrd、.mha
- NibabelIOWithReorient:.nii.gz、.nrrd、.mha
- SimpleITKIO:.nii.gz、.nrrd、.mha
- Tiff3DIO:.tif,.tiff。
pycharm终端执行下列命令
nnUNetv2_plan_and_preprocess -d 001 --verify_dataset_integrity在这条命令中,你只需要根据自己数据集命名的情况修改-d后面的参数就可以,比如我的数据集名称叫做Dataset001_dfc,那么-d后面跟的就是001,以此类推
出现如下就正确了

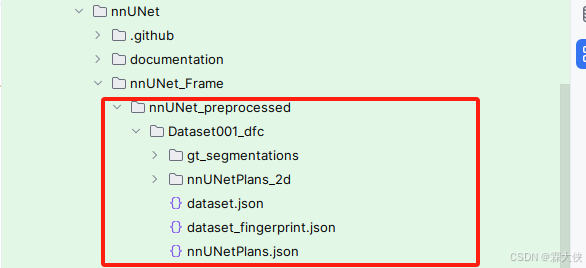
运行成功后,nnUNet_preprocessed中会出现如下内容
三、训练
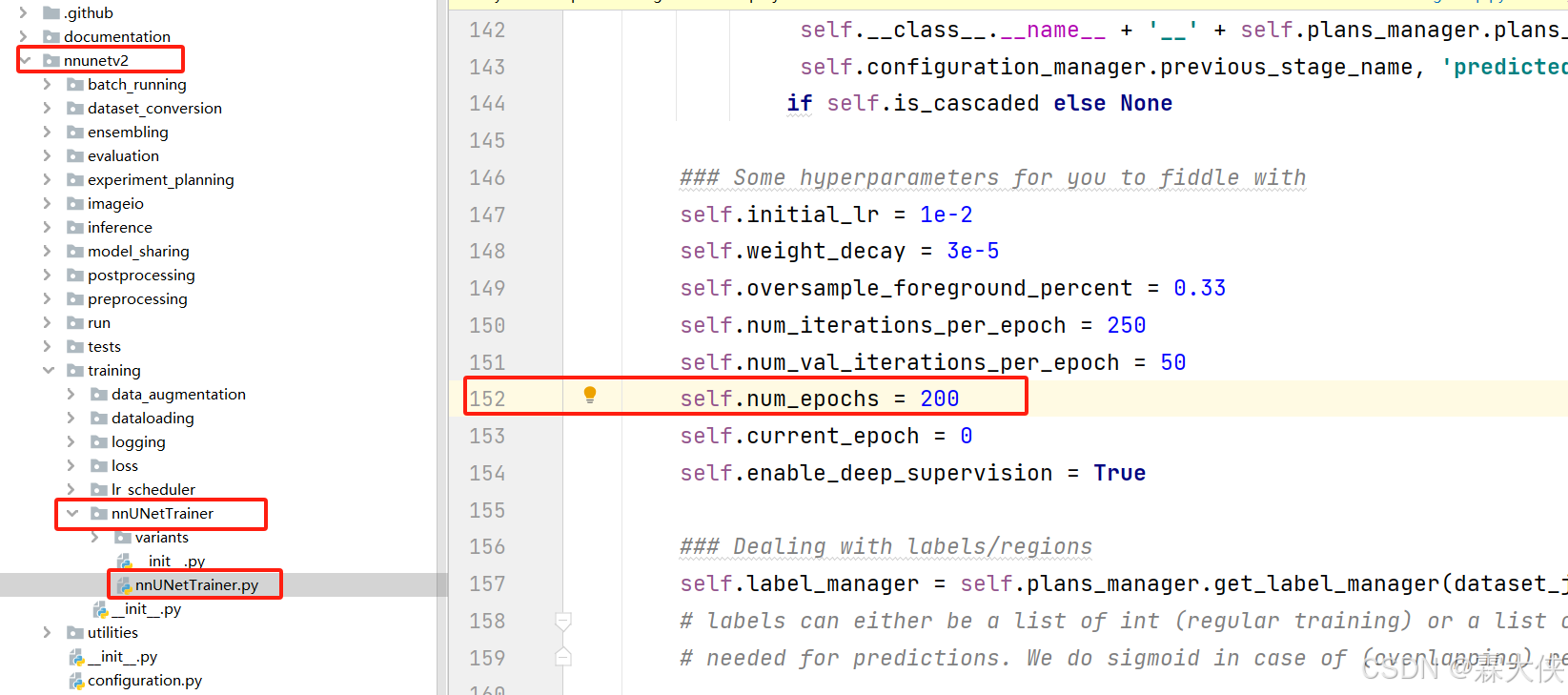
然后修改一下训练epoch,我这里改成了200epoch
训练命令
2D训练指令如下:
nnU-Net默认使用5折交叉验证来训练所有U-Net配置
train后面的第一个数字为数据集编号,后面的2d为本次训练所使用的模型,2d后面的数字为第几折,因为使用的是五折交叉验证,所以需要训练5次,这里可以创建一个train.sh文件,直接执行bash train.sh就可以了
nnUNetv2_train 1 2d 0
nnUNetv2_train 1 2d 1
nnUNetv2_train 1 2d 2
nnUNetv2_train 1 2d 3
nnUNetv2_train 1 2d 4 这样就是开始训练了,差不多1分钟一个epoch

训练完之后nnUNet_results文件夹下就会出现如下所示:
四、验证
nnUNetv2_train 1 2d 0 --val --npz
nnUNetv2_train 1 2d 1 --val --npz
nnUNetv2_train 1 2d 2 --val --npz
nnUNetv2_train 1 2d 3 --val --npz
nnUNetv2_train 1 2d 4 --val --npz五、推理
nnunet可以自己找寻最优模型并给出推理命令,使用如下命令自动寻找最优:
nnUNetv2_find_best_configuration 1 -c 2d -f 0 1 2 3 4稍等后会出现如下图所示

下面给出了推理命令和后处理命令,将-i 和-o后面的内容替换成自己的文件夹就可以,这样就完成了所有的训练和推理过程。
有什么不懂的大家可以在评论区问我,我一定会积极回复哒!!!


















 762
762

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









