







文章目录
一、文献简明(zero)
领域:NLP、预训练语言模型
标题:[2018] Improving Language Understanding by Generative Pre-Training (GPT-1)(通过生成式预训练提升语言理解能力(GPT-1))
作者:OpenAI贡献:提出了GPT-1模型,首次展示了生成式预训练在NLP任务中的潜力。
链接:https://www.mikecaptain.com/resources/pdf/GPT-1.pdf
二、快速预览(first)
1、标题分析
Improving Language Understanding by Generative Pre-Training (GPT-1)
通过生成式预训练提升语言理解能力(GPT-1)
简要介绍
《通过生成式预训练提升语言理解能力(GPT-1)》是由 OpenAI 团队于 2018 年发布的开创性论文。该论文首次提出了基于 Transformer 架构的生成式预训练模型(GPT-1),并证明了其在自然语言处理任务中的有效性。
核心内容
- 生成式预训练:GPT-1 首先在大规模无标注文本语料上进行生成式预训练,通过预测下一个单词来学习语言的结构、语法和语义。这一阶段利用了大量未标注数据,解决了标注数据稀缺的问题。
- 微调阶段:在预训练完成后,模型在特定任务(如问答、文本分类等)上进行微调,以适应不同的下游任务。GPT-1 在微调过程中使用了任务感知的输入转换,仅对模型架构进行了最小的改动。
- Transformer 架构:GPT-1 基于 Transformer 的解码器部分构建,采用自注意力机制来捕捉文本中的上下文关系。这种架构能够高效处理长序列数据,并支持并行计算。
研究成果
GPT-1 在 12 项自然语言理解任务中表现优异,其中在 9 项任务中显著优于传统有监督训练模型。例如,在常识推理(Stories Cloze Test)、问题解答(RACE)和文本引申(MultiNLI)任务中,分别取得了 8.9%、5.7% 的绝对性能提升。
意义
GPT-1 的提出为自然语言处理领域带来了新的思路,证明了生成式预训练结合微调的有效性。它不仅提高了模型对语言的理解能力,还为后续的 GPT 系列模型(如 GPT-2、GPT-3 等)奠定了基础。
2、作者介绍

这张图片列出了四位与 OpenAI 相关的研究人员及其电子邮件地址。以下是对每位作者的简要介绍:
-
Alec Radford
- Alec Radford 是 OpenAI 的研究人员之一,他在人工智能和机器学习领域有丰富的研究经验。他参与了多个重要的项目,包括 GPT(G Preenerative-trained Transformer)系列模型的研究和开发。
-
Karthik Narasimhan
- Karthik Narasimhan 同样是 OpenAI 的研究人员,专注于自然语言处理和机器学习。他的工作涉及开发能够理解和生成自然语言的模型,对提升语言理解和生成能力有重要贡献。
-
Tim Salimans
- Tim Salimans 是 OpenAI 的研究科学家,他在机器学习和人工智能领域有着深厚的背景。他的研究兴趣包括深度学习、生成模型和强化学习,对推动这些领域的发展做出了显著贡献。
-
Ilya Sutskever
- Ilya Sutskever 是 OpenAI 的联合创始人之一,也是该领域的领军人物。他在深度学习和神经网络方面有着开创性的工作,对现代人工智能的发展产生了深远影响。Sutskever 曾在多个顶级学术会议上发表重要论文,并获得了包括神经信息处理系统会议(NeurIPS)的杰出论文奖在内的多项荣誉。
这些研究人员在人工智能和机器学习领域都做出了重要贡献,特别是在自然语言处理和生成模型方面。他们的工作不仅推动了技术的发展,也为未来的研究奠定了基础。
3、引用数
……
4、摘要分析

(1)翻译
自然语言理解涵盖了广泛的多样化任务,如文本蕴含、问答、语义相似度评估和文档分类。尽管有大量的未标注文本语料库,但用于学习这些特定任务的标注数据却很稀缺,这使得通过判别式训练的模型很难充分表现。我们展示了通过对语言模型在多样化的未标注文本语料库上进行生成式预训练,然后在每个特定任务上进行判别式微调,可以在这些任务上实现显著的提升。与之前的方法相比,我们在微调过程中利用了任务感知的输入转换,以实现有效的迁移,同时对模型架构的改动最小。我们在广泛的自然语言理解基准测试中展示了我们方法的有效性。我们的通用任务无关模型在12项研究任务中的9项上超越了使用为每个任务专门设计的架构的判别式训练模型,显著提高了当前技术水平。例如,我们在常识推理(Stories Cloze Test)、问答(RACE)和文本蕴含(MultiNLI)任务上分别实现了8.9%、5.7%和1.5%的绝对提升。
(2)分析
这段摘要主要介绍了一种新的自然语言处理(NLP)方法,该方法通过生成式预训练和判别式微调来提高模型在多种NLP任务上的表现。以下是关键点的分析:
-
问题背景:
- 自然语言理解任务多样,但标注数据稀缺,这限制了传统判别式训练模型的性能。
-
方法介绍:
- 提出了一种新的方法,即先在大量未标注文本上进行生成式预训练,然后在特定任务上进行判别式微调。
- 使用任务感知的输入转换来实现有效的迁移学习,同时保持模型架构的稳定性。
-
效果评估:
- 在多个自然语言理解基准测试中验证了方法的有效性。
- 通用模型在大多数任务上超越了为特定任务设计的模型,显示了方法的广泛适用性和优越性。
-
具体成果:
- 在常识推理、问答和文本蕴含等任务上取得了显著的性能提升,具体数值如8.9%、5.7%和1.5%的绝对提升,表明了方法的实际效果。
-
创新点:
- 利用生成式预训练和判别式微调的结合,以及任务感知的输入转换,提高了模型的迁移能力和适应性。
- 展示了通用模型在多种任务上的优越性能,证明了方法的广泛适用性和有效性。
总的来说,这段摘要清晰地介绍了研究的背景、方法、评估和成果,突出了其在自然语言理解领域的创新和贡献。
5、总结分析

(1)翻译
我们介绍了一个框架,通过生成式预训练和判别式微调,使用单一任务无关模型实现强大的自然语言理解能力。通过在包含大量连续文本的多样化语料库上进行预训练,我们的模型获得了显著的世界知识和处理长距离依赖关系的能力,这些能力随后成功转移到解决判别式任务上,如问答、语义相似度评估、蕴含判断和文本分类,提高了我们研究的12个数据集中9个的最新技术水平。利用无监督(预)训练来提升判别式任务的性能一直是机器学习研究的重要目标。我们的工作表明,实现显著的性能提升确实是可能的,并为哪些模型(Transformers)和数据集(具有长距离依赖关系的文本)最适合这种方法提供了线索。我们希望这将有助于开启无监督学习的新研究,无论是在自然语言理解还是其他领域,进一步改善我们对无监督学习如何以及何时起作用的理解。
(2)分析
这段结论总结了论文的主要贡献和发现,并对未来的研究方向提出了展望。以下是关键点的分析:
-
方法概述:
- 论文提出了一种结合生成式预训练和判别式微调的方法,使用单一任务无关模型来实现强大的自然语言理解能力。
-
预训练的效果:
- 通过在多样化的语料库上进行预训练,模型能够获得丰富的世界知识和处理长距离依赖关系的能力,这对于解决各种自然语言理解任务至关重要。
-
性能提升:
- 该方法在多个自然语言理解任务上取得了显著的性能提升,特别是在12个研究数据集中的9个上,显示了方法的广泛适用性和有效性。
-
无监督学习的重要性:
- 利用无监督预训练来提升判别式任务的性能是机器学习研究的重要目标。论文的方法和结果支持了这一观点,并展示了无监督学习在自然语言处理中的潜力。
-
模型和数据集的选择:
- 论文指出,Transformers模型和具有长距离依赖关系的文本数据集是这种方法的理想选择,为未来的研究提供了指导。
-
未来研究方向:
- 论文希望其工作能够促进无监督学习在自然语言理解和其他领域的研究,进一步探索无监督学习的有效性和适用性。
总的来说,这段结论清晰地总结了论文的主要贡献,并对未来的研究方向提出了有见地的建议,强调了无监督学习在自然语言处理中的重要性和潜力。
6、部分图表
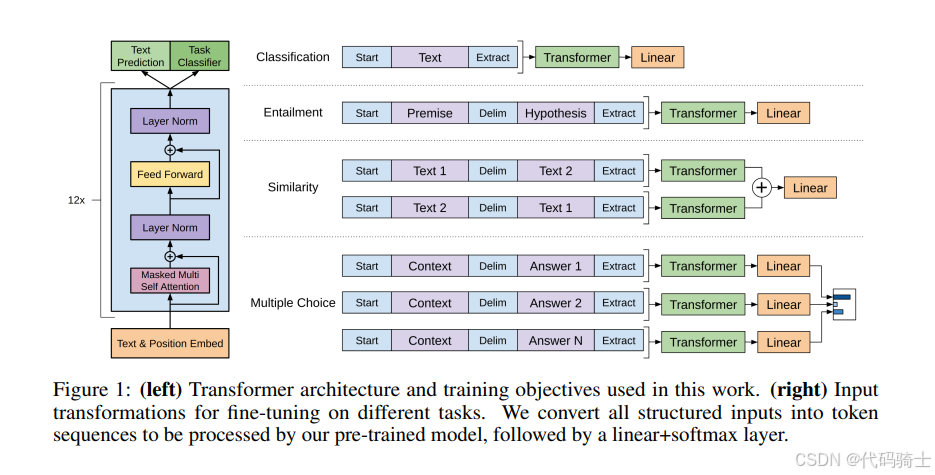
图表展示了用于自然语言处理任务的 Transformer 模型架构和不同任务的输入转换方式。以下是对图表的详细分析:
左侧:Transformer 架构
左侧部分展示了 Transformer 模型的基本架构,该架构由多个相同的层(图中显示了12层)堆叠而成。每一层包含以下组件:
- Masked Multi-Self Attention(掩码多头自注意力):允许模型在处理序列时关注序列中的不同位置,同时通过掩码机制防止模型在训练时看到未来的信息。
- Layer Norm(层归一化):对输入进行归一化处理,有助于加速训练并提高模型的稳定性。
- Feed Forward(前馈网络):对每个位置的输出进行独立的非线性变换。
- Text & Position Embed(文本和位置嵌入):将输入文本转换为模型可以理解的向量表示,并加入位置信息以保留序列顺序。
右侧:不同任务的输入转换
右侧部分展示了如何将不同的自然语言处理任务转换为适合 Transformer 模型处理的输入格式。每种任务都有特定的输入格式和目标:
-
Classification(分类):
- 输入格式:
[Start] Text [Extract] - 目标:对整个文本进行分类。
- 处理流程:输入经过 Transformer 后,通过一个线性层进行分类。
- 输入格式:
-
Entailment(蕴含):
- 输入格式:
[Start] Premise [Delim] Hypothesis [Extract] - 目标:判断前提是否蕴含结论。
- 处理流程:输入经过 Transformer 后,通过两个线性层进行处理。
- 输入格式:
-
Similarity(相似度):
- 输入格式:
[Start] Text 1 [Delim] Text 2 [Extract] - 目标:计算两个文本之间的相似度。
- 处理流程:输入经过两个 Transformer(分别处理两个文本),然后通过一个线性层进行相似度计算。
- 输入格式:
-
Multiple Choice(多项选择):
- 输入格式:
[Start] Context [Delim] Answer 1 [Extract] - 目标:从多个选项中选择正确答案。
- 处理流程:输入经过 Transformer 后,通过线性层和 softmax 层进行分类。
- 输入格式:
每种任务的输入格式都经过特定的转换,以适应 Transformer 模型的处理方式。这些转换包括添加特殊的标记(如 [Start]、[Delim]、[Extract])来指示输入的不同部分。经过 Transformer 处理后,输入通过线性层或线性-softmax 层进行最终的分类或相似度计算。
总结
图表展示了 Transformer 模型在不同自然语言处理任务中的应用,强调了通过适当的输入转换和微调,单一的预训练模型可以适应多种任务。这种方法不仅提高了模型的通用性和效率,还展示了无监督预训练在自然语言处理中的巨大潜力。
7、引言分析
(1)翻译
1 引言
从原始文本中有效学习的能力对于减轻自然语言处理(NLP)中对监督学习的依赖至关重要。大多数深度学习方法需要大量的手动标注数据,这限制了它们在许多缺乏标注资源的领域的适用性。在这种情况下,能够利用未标注数据中的语言学信息的模型提供了一种有价值的替代方案,以收集更多标注数据,这可能既耗时又昂贵。此外,即使在有大量监督的情况下,以无监督的方式学习良好的表示也可以显著提高性能。迄今为止,最有说服力的证据是广泛使用预训练词嵌入来提高各种 NLP 任务的性能。
然而,从未标注文本中利用超出词级的信息是具有挑战性的,原因有两个。首先,目前尚不清楚哪种类型的优化目标在学习对迁移有用的文本表示方面最有效。最近的研究已经研究了各种目标,如语言建模、机器翻译和话语连贯性,每种方法在不同任务上都优于其他方法。其次,对于如何最有效地将学习到的表示转移到目标任务上没有共识。现有的技术涉及对模型架构进行任务特定的更改、使用复杂的学习方案和添加辅助学习目标。这些不确定性使得开发有效的半监督学习方法用于语言处理变得困难。
在本文中,我们探索了一种结合无监督预训练和监督微调的半监督方法来处理语言理解任务。我们的目标是学习一种通用表示,该表示在广泛的任务中只需很少的调整即可转移。我们假设可以访问大量未标注文本和几个带有手动标注训练样本的数据集(目标任务)。我们的设置不要求这些目标任务与未标注语料库处于同一领域。我们采用两阶段训练过程。首先,我们使用语言建模目标在未标注数据上学习神经网络模型的初始参数。随后,我们使用相应的监督目标调整这些参数以适应目标任务。
对于我们的模型架构,我们使用 Transformer,它已在各种任务中表现出色,如机器翻译、文档生成和句法解析。与循环网络等替代方案相比,这种模型选择为我们提供了更结构化的内存来处理文本中的长期依赖关系,从而在不同任务中实现稳健的迁移性能。在迁移过程中,我们利用从旅行式方法派生的任务特定输入转换,将结构化文本输入处理为单个连续的标记序列。正如我们在实验中所展示的,这些调整使我们能够有效地微调,而对预训练模型的架构进行最小的更改。
我们在四种类型的语言理解任务上评估了我们的方法——自然语言推理、问答、语义相似性和文本分类。我们的通用任务无关模型在12项研究任务中的9项上超越了使用为每个任务专门设计的架构的判别式训练模型,显著提高了最新技术水平。例如,我们在常识推理(Stories Cloze Test)、问答(RACE)、文本蕴含(MultiNLI)和最近引入的 GLUE 多任务基准测试中分别实现了8.9%、5.7%、1.5%和5.5%的绝对改进。我们还分析了预训练模型在四种不同设置中的零样本行为,并证明它为下游任务获取了有用的语言知识。
(2)分析
这段引言和后续段落详细介绍了论文的研究背景、目标、方法和主要发现。以下是关键点的分析:
-
研究背景:
- 强调了从原始文本中有效学习的重要性,以减少对监督学习的依赖。
- 指出了深度学习方法在标注数据稀缺的领域的局限性。
-
研究目标:
- 提出了一种结合无监督预训练和监督微调的半监督方法。
- 目标是学习一种通用表示,该表示在广泛的任务中只需很少的调整即可转移。
-
方法概述:
- 使用 Transformer 模型架构,该架构在处理长期依赖关系方面具有优势。
- 采用两阶段训练过程:首先在未标注数据上进行预训练,然后在特定任务上进行微调。
- 使用任务特定的输入转换来适应不同的任务。
-
实验结果:
- 在四种类型的语言理解任务上评估了方法的有效性。
- 通用任务无关模型在大多数任务上超越了专门设计的模型,显示了方法的广泛适用性和优越性。
-
主要发现:
- 通过无监督预训练和监督微调,可以在多种任务中实现显著的性能提升。
- 预训练模型能够获取有用的语言知识,为下游任务提供支持。
总的来说,这段引言和后续段落清晰地介绍了论文的研究动机、方法和主要贡献,强调了无监督预训练和半监督学习在自然语言处理中的重要性和潜力。
8、全部标题
以下是提取的标题及其对应的中文翻译:
-
Abstract
摘要 -
1 Introduction
1 引言 -
2 Related Work
2 相关工作 -
3 Framework
3 框架 -
3.1 Unsupervised pre-training
3.1 无监督预训练 -
3.2 Supervised fine-tuning
3.2 监督微调 -
3.3 Task-specific input transformations
3.3 任务特定的输入转换 -
4 Experiments
4 实验 -
4.1 Setup
4.1 设置 -
4.2 Supervised fine-tuning
4.2 监督微调 -
5 Analysis
5 分析 -
6 Conclusion
6 结论 -
References
参考文献
9、参考文献
以下是前10条参考文献及其对应的中文翻译:
-
[1] S. Arora, Y. Liang, and T. Ma. A simple but tough-to-beat baseline for sentence embeddings. 2016.
[1] S. Arora, Y. Liang 和 T. Ma. 句子嵌入的一个简单但难以超越的基线。2016。 -
[2] J. L. Ba, J. R. Kiros, and G. E. Hinton. Layer normalization. arXiv preprint arXiv:1607.06450, 2016.
[2] J. L. Ba, J. R. Kiros 和 G. E. Hinton. 层归一化。arXiv 预印本 arXiv:1607.06450, 2016。 -
[3] Y. Bengio, P. Lamblin, D. Popovici, and H. Larochelle. Greedy layer-wise training of deep networks. In Advances in neural information processing systems, pages 153–160, 2007.
[3] Y. Bengio, P. Lamblin, D. Popovici 和 H. Larochelle. 深度网络的贪婪层级训练。在神经信息处理系统进展中,页码153–160, 2007。 -
[4] L. Bentivogli, P. Clark, I. Dagan, and D. Giampiccolo. The fifth pascal recognizing textual entailment challenge. In TAC, 2009.
[4] L. Bentivogli, P. Clark, I. Dagan 和 D. Giampiccolo. 第五届Pascal文本蕴含识别挑战赛。在TAC中,2009。 -
[5] S. R. Bowman, G. Angeli, C. Potts, and C. D. Manning. A large annotated corpus for learning natural language inference. EMNLP, 2015.
[5] S. R. Bowman, G. Angeli, C. Potts 和 C. D. Manning. 用于学习自然语言推理的大型标注语料库。EMNLP, 2015。 -
[6] D. Cer, M. Diab, E. Agirre, I. Lopez-Gazpio, and L. Specia. Semeval-2017 task 1: Semantic textual similarity-multilingual and cross-lingual focused evaluation. arXiv preprint arXiv:1708.00055, 2017.
[6] D. Cer, M. Diab, E. Agirre, I. Lopez-Gazpio 和 L. Specia. Semeval-2017任务1:多语言和跨语言聚焦的语义文本相似性评估。arXiv 预印本 arXiv:1708.00055, 2017。 -
[7] S. Chaturvedi, H. Peng, and D. Roth. Story comprehension for predicting what happens next. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pages 1603–1614, 2017.
[7] S. Chaturvedi, H. Peng 和 D. Roth. 用于预测接下来发生的事情的故事理解。在2017年自然语言处理实证方法会议论文集中,页码1603–1614, 2017。 -
[8] D. Chen and C. Manning. A fast and accurate dependency parser using neural networks. In Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), pages 740–750, 2014.
[8] D. Chen 和 C. Manning. 使用神经网络的快速准确依存句法分析器。在2014年自然语言处理实证方法会议论文集中,页码740–750, 2014。 -
[9] Z. Chen, H. Zhang, X. Zhang, and L. Zhao. Quora question pairs. https://data.quora.com/First-QuoraDataset-Release-Question-Pairs, 2018.
[9] Z. Chen, H. Zhang, X. Zhang 和 L. Zhao. Quora问题对。https://data.quora.com/First-QuoraDataset-Release-Question-Pairs, 2018。 -
[10] R. Collobert and J. Weston. A unified architecture for natural language processing: Deep neural networks with multitask learning. In Proceedings of the 25th international conference on Machine learning, pages 160–167. ACM, 2008.
[10] R. Collobert 和 J. Weston. 自然语言处理的统一架构:具有多任务学习的深度神经网络。在第25届国际机器学习会议论文集中,页码160–167。ACM, 2008。
……


















 5546
5546

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











