







好久没有写博客了,这里我分享一下最近参加的一个比赛的方案把。
比赛简介
在这个比赛中我们需要通过官方给的数据以及字段说明对房屋的租金进行预测,赛题数据由训练集和测试集组成,总数据量超过30w,包含31个特征字段。为了保证比赛的公平性,将会从中抽取20万条作为训练集,5万条作为测试集,同时会对部分字段信息进行脱敏。讯飞房屋租赁价格预测挑战赛
数据EDA
df.describe()
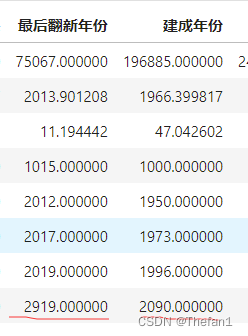
通过上图可以看出,最后翻新年份和建成年份的最大值一个是2919年,一个是2090年,这明显是有问题的,所以我后面将年份大于2019年的全部都改为了2019年,以下为更改代码
def f(x):
if x > 2019:
return 2019
else:
return x
df['建成年份'] = df['建成年份'].apply(f)
df['最后翻新年份'] = df['最后翻新年份'].apply(f)
sns.kdeplot(df['供暖费用'])
plt.show()
sns.kdeplot(df['服务费'])
plt.show()
sns.kdeplot(df['居住面积'])
plt.show()
sns.kdeplot(df['房间数量'])
plt.show()
通过将部分特征的核密度图画出来可以看出这几个特征需要进行截尾处理

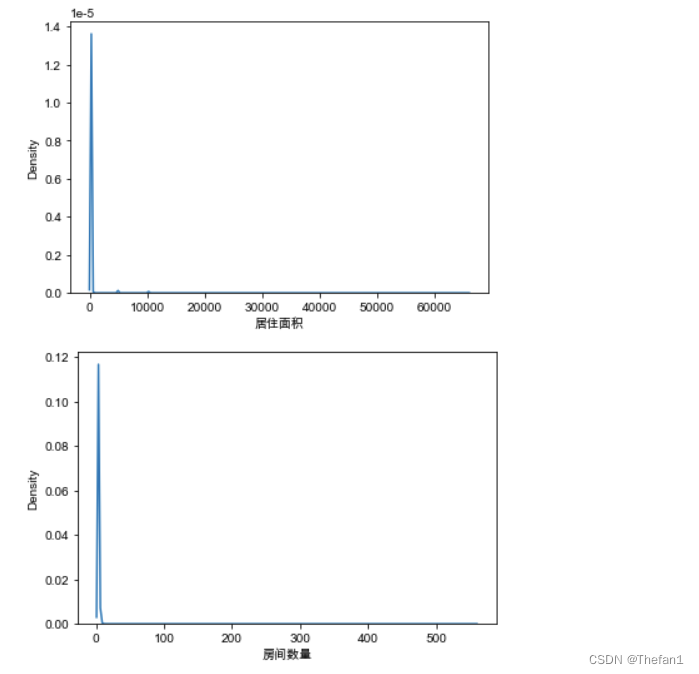
在这里我使用的是最简便的对数处理
df['供暖费用'] = np.log1p(df['供暖费用'])
df['服务费'] = np.log1p(df['服务费'])
df['居住面积'] = np.log1p(df['居住面积'])
df['房间数量'] = np.log1p(df['房间数量'])
特征工程
接下来就是特征工程,我们特征工程是直接梭哈的,没有具体的一个一个建造,下面便是我们特征工程的代码
def freq_enc(df, col):
vc = df[col].value_counts(dropna=True, normalize=True).to_dict()
df[f'{col}_freq'] = df[col].map(vc)
return df
for feat in ['上传日期','没有停车位','房屋状况','可带宠物','加热类型','房屋类型','邮政编码','房间数量','所处楼层','建筑楼层']:
df = freq_enc(df, feat)
df['服务费' + '+' + '居住面积'] = df['服务费'] + df['居住面积']
df['服务费' + '*' + '居住面积'] = df['服务费'] * df['居住面积']
df['服务费' + '-' + '居住面积'] = df['服务费'] - df['居住面积']
df['服务费' + '/' + '居住面积'] = df['服务费'] / df['居住面积']
df['居住面积' + '-' + '服务费'] = df['居住面积'] - df['服务费']
df['居住面积' + '/' + '服务费'] = df['居住面积'] / df['服务费']
def brute_force(df, features, groups):
for method in tqdm(['max', 'min', 'mean', 'median', 'std']):
for feature in features:
for group in groups:
df[f'{group}_{feature}_{method}'] = df.groupby(group)[feature].transform(method)
return df
dense_feats = ['价格趋势','服务费','供暖费用','电力基础价格','居住面积','房间数量','所处楼层','建筑楼层','上传图片数']
cate_feats = ['区域1','区域2','区域3','街道','没有停车位','上传日期','有厨房','有电梯','有地窖','房屋状况','内饰质量','可带宠物','有阳台','加热类型','房屋类型','邮政编码','最后翻新年份','有花园','是新建筑','建成年份']
df = brute_force(df, dense_feats, cate_feats)
接下来我们将几个类别特征进行LabelEncoder
for feat in ['可带宠物', '邮政编码', '上传日期']:
lbl = LabelEncoder()
lbl.fit(df[feat])
df[feat] = lbl.transform(df[feat])
模型训练
最后就是我们的模型训练了,在选择模型的时候,我们只选用了两个模型,一个是lightgbm,一个是catboost,之所以其他的模型为什么没有用,存粹就是因为我们懒哈哈哈哈,所以我们最终也只使用了两个模型,我认为后面多用几个模型然后融合分数应该会更好,毕竟两个模型还是少了点
首先我们先把训练集和测试集从df中切分出来,然后转化成相应的X和y,不过这里有一个点需要注意,在我之前对数据EDA的时候发现训练集中有一个数据的房屋租金为0,这里我们把这些数据当做异常值全部删除,之后再转化为相应的X和y
no_features = ['ID', '房屋租金']
features = [col for col in df.columns if col not in no_features]
df_train = df[~df['房屋租金'].isnull()]
df_train = df_train[[item for item in df_train.columns if item != 'ID']].drop_duplicates()
df_train = df_train[df_train['房屋租金'] != 0].reset_index(drop = True)
df_test = df[df['房屋租金'].isnull()]
X = df_train[features].astype(float)
y = np.log1p(df_train['房屋租金'].astype(float))
X_test = df_test[features].astype(float)
下面就是我们lgb使用的参数
from sklearn import metrics
from sklearn.model_selection import KFold
from sklearn.preprocessing import LabelEncoder
from catboost import CatBoostRegressor, Pool
# 祖传参数
params = {
'learning_rate': 0.01,
'boosting_type': 'gbdt',
'objective': 'regression',
'metric': 'mae',
'feature_fraction': 0.7,
'bagging_fraction': 0.8,
'bagging_freq': 5,
'num_leaves': 1000,
'verbose': -1,
'max_depth': 10,
'seed': 2022,
}
然后接下来就是十折交叉验证的lgb模型
n_fold = 10
folds = KFold(n_splits=n_fold, shuffle=True, random_state=1314)
oof = np.zeros(len(X))
prediction = np.zeros(len(X_test))
for fold_n, (train_index, valid_index) in enumerate(folds.split(X)):
print('第 ' + str(fold_n + 1) + '折:')
X_train, X_valid = X[features].iloc[train_index], X[features].iloc[valid_index]
y_train, y_valid = y[train_index], y[valid_index]
model = lgb.LGBMRegressor(**params, n_estimators=60000, n_jobs=-1)
model.fit(X_train, y_train,
eval_set=[(X_train, y_train), (X_valid, y_valid)],
eval_metric='rmae',
verbose=1000,
early_stopping_rounds=500)
y_pred_valid = model.predict(X_valid)
y_pred = model.predict(X_test, num_iteration=model.best_iteration_)
oof[valid_index] = y_pred_valid.reshape(-1, )
prediction += y_pred
prediction /= n_fold
这里单模的lgb模型的最后线上分数是82.79558
然后下面是十折交叉验证的catboost模型
from sklearn import metrics
from sklearn.model_selection import KFold
from sklearn.preprocessing import LabelEncoder
from catboost import CatBoostRegressor, Pool
n_fold = 10
folds = KFold(n_splits=n_fold, shuffle=True, random_state=1314)
oof = np.zeros(len(X))
prediction = np.zeros(len(X_test))
for fold_n, (train_index, valid_index) in enumerate(folds.split(X)):
print('第 ' + str(fold_n + 1) + '折:')
X_train, X_valid = X[features].iloc[train_index], X[features].iloc[valid_index]
y_train, y_valid = y[train_index], y[valid_index]
train_pool = Pool(X_train, y_train)
eval_pool = Pool(X_valid, y_valid)
cbt_model = CatBoostRegressor(iterations=70000,
learning_rate=0.03,
eval_metric='MAE',
use_best_model=True,
random_seed=42,
logging_level='Verbose',
task_type='GPU',
devices='0',
gpu_ram_part=0.5,
depth=10,
early_stopping_rounds=500)
cbt_model.fit(train_pool,
eval_set=eval_pool,
verbose=1000)
y_pred_valid = cbt_model.predict(X_valid)
y_pred = cbt_model.predict(X_test)
oof[valid_index] = y_pred_valid.reshape(-1, )
prediction += y_pred
prediction /= n_fold
这里单模的catboost模型的最后线上分数是82.23733
后面就是模型融合了
我们选择的模型融合方式也是最简单的,结果加权融合,下面是融合的代码
import pandas as pd
data1 = pd.read_csv(r'E:\竞赛数据集\房屋租赁价格预测挑战赛公开数据\catboost_10折_600维特征.csv') #2
data2 = pd.read_csv(r'E:\竞赛数据集\房屋租赁价格预测挑战赛公开数据\lgb_10折_600维特征.csv') #3
data3 = pd.read_csv(r'E:\竞赛数据集\房屋租赁价格预测挑战赛公开数据\catboost_10折_700维特征.csv') #1
data4 = pd.read_csv(r'E:\竞赛数据集\房屋租赁价格预测挑战赛公开数据\lgb_10折_700维特征.csv') #4
df_ = pd.DataFrame()
df_['ID'] = data1['ID']
df_['房屋租金'] = data1['房屋租金'] * 0.3 + data2['房屋租金'] * 0.2 + data3['房屋租金'] * 0.3 + data4['房屋租金'] * 0.2
df_.to_csv('E:\竞赛数据集\房屋租赁价格预测挑战赛公开数据\submit_4模型融合_2.csv', index=None)
这里肯定会有人有疑惑,为什么我融合之前读取的结果文件名字中有600维特征和700维特征,这里我解释一下,因为我们之前一顿梭哈构造出了接近1000维特征,后面删除了特征重要性为0的特征,然后就只剩下了700多维特征,但是后面我发现特征中有重复的,删除掉了这些重复的特征就只剩下了600维特征,不过因为考虑到我们只有两个模型,就训练出两个结果融合有点少了,我们后面就干脆一个人用600维特征训练两个模型,一个人用700维特征训练两个模型,然后最后将四个结果融合起来。
最后四个模型融合的分数就是我们的最好成绩 81.70936
总结
大家可以看出这个比赛很简单,而且奖金低,所以我们才能侥幸拿到top2,不过我感觉还是可以的,毕竟这次是我比赛第一次拿奖哈哈哈哈















 998
998











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











