







项目描述
项目简介
基于GPT-2模型并采用中文聊天语料进行训练,本项目旨在开发一个高效能的中文闲聊机器人,以提供自然而流畅的对话体验。GPT-2,作为OpenAI推出的一款自然语言处理模型,因其强大的语言理解与生成能力而广受好评。本项目通过精心挑选和处理大量的中文聊天数据,使得闲聊机器人能够更加精准地把握中文语境和文化特点,从而在各种聊天场景中提供贴近人类的对话体验。
全部代码和模型均在文末给出
模型架构
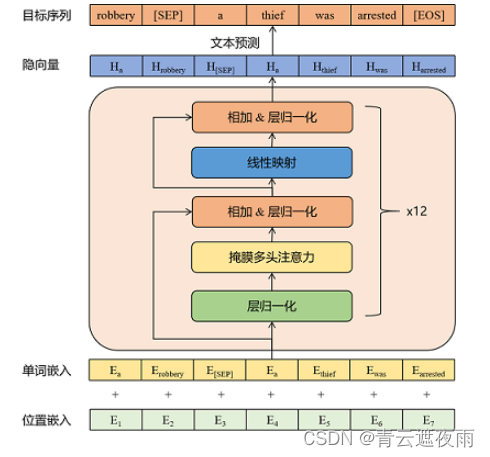
- initializer_range: 0.02
- layer_norm_epsilon: 1e-05
- n_ctx: 1024
- n_embd: 768
- n_head: 12
- n_layer: 12
- n_positions: 1024
- vocab_size: 21128
更多模型细节详见模型的chitchat.yaml文件
效果展示
- 使用控制台进行的人机交互
user :在吗
chatbot:在
user :我不开心
chatbot:怎么啦
user :最近好累啊
chatbot:是挺累的
user :作业好多啊
chatbot:还好还好
user :我觉得我快要挂科了
chatbot:我也是啊,但是我觉得我快熬出头了
user :不说了,我还有好多作业没写
chatbot:我也是啊好多啊
user :那先这样,下次再聊,再见了
chatbot:好哒
- 使用Gradio完成的类似ChatGPT的聊天交互
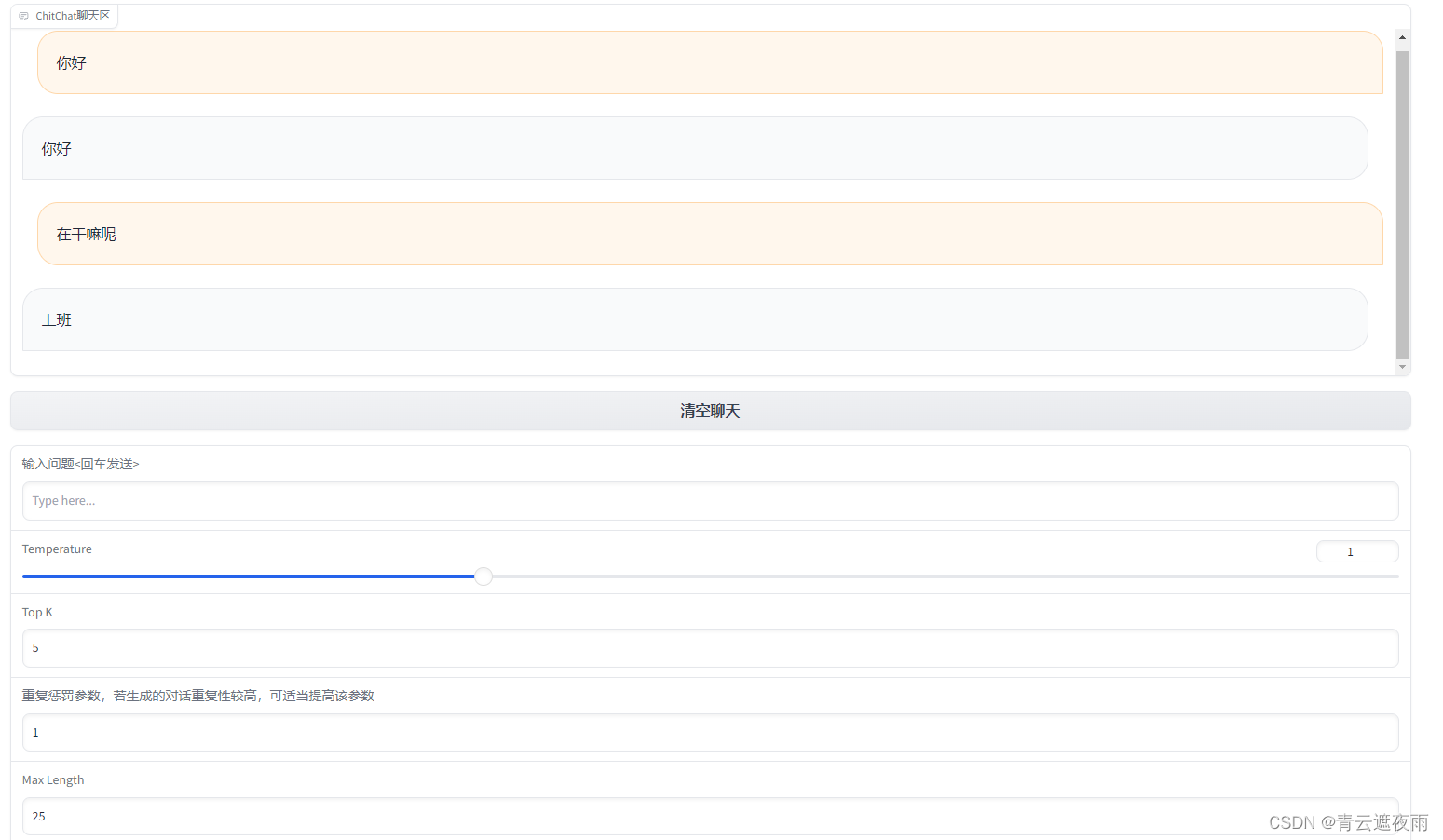
移植过程
项目结构
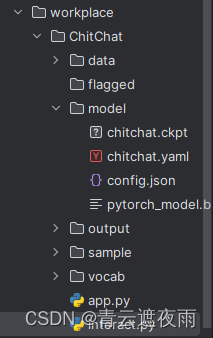
- model:存放模型
- data:存放Cuda日志
- output:存放训练日志
- sample:存放对话历史
- vocab:存放词表
- app.py:Gradio版中文聊天
- interact.py:控制台版中文聊天
模型转换
这部分我们要将HuggingFace上的模型转换为MindSpore可以识别使用的模型。
首先我们去Github上下载ChitChat Pytorch版本的模型,下载地址:https://pan.baidu.com/s/1iEu_-Avy-JTRsO4aJNiRiA#list/path=%2F,提取码ju6m
下载完成后我们获得了初始权重。
转换思路
非常重要的是,在Pytorch和MindSpore中,模型的参数名是一一对应的!
举个例子,下面是一个Pytorch模型,我们打印其全部参数名:
import torch
from test.efficientnet_pytorch.model import EfficientNet as EN_pytorch
import pandas as pd
pytorch_model = EN_pytorch.from_name(cfg['model'], override_params={'num_classes': 3})
pytorch_model.cuda()
pytorch_weights_dict = pytorch_model.state_dict()
param_torch = pytorch_weights_dict.keys()
param_torch_lst = pd.DataFrame(param_torch)
param_torch_lst.to_csv('param_torch.csv')
结果为:
序号
键名
0
_conv_stem.weight
1
_bn0.weight
2
_bn0.bias
3
_bn0.running_mean
4
_bn0.running_var
5
_bn0.num_batches_tracked
6
_blocks.0._depthwise_conv.weight
7
_blocks.0._bn1.weight
8
_blocks.0._bn1.bias
9
_blocks.0._bn1.running_mean
10
_blocks.0._bn1.running_var
\begin{array}{cl} \hline \text{序号} & \text{键名} \\ \hline 0 & \text{\_conv\_stem.weight} \\ 1 & \text{\_bn0.weight} \\ 2 & \text{\_bn0.bias} \\ 3 & \text{\_bn0.running\_mean} \\ 4 & \text{\_bn0.running\_var} \\ 5 & \text{\_bn0.num\_batches\_tracked} \\ 6 & \text{\_blocks.0.\_depthwise\_conv.weight} \\ 7 & \text{\_blocks.0.\_bn1.weight} \\ 8 & \text{\_blocks.0.\_bn1.bias} \\ 9 & \text{\_blocks.0.\_bn1.running\_mean} \\ 10 & \text{\_blocks.0.\_bn1.running\_var} \\ \hline \end{array}
序号012345678910键名_conv_stem.weight_bn0.weight_bn0.bias_bn0.running_mean_bn0.running_var_bn0.num_batches_tracked_blocks.0._depthwise_conv.weight_blocks.0._bn1.weight_blocks.0._bn1.bias_blocks.0._bn1.running_mean_blocks.0._bn1.running_var
同样的模型我们使用MindSpore打印其全部参数名
import mindspore as ms
from test.efficientnet_mindspore.model import EfficientNet as EN_ms
import pandas as pd
mindspore_model = EN_ms.from_name(cfg['model'], override_params={'num_classes': 3})
prams_ms = mindspore_model.parameters_dict().keys()
prams_ms_lst = pd.DataFrame(prams_ms)
prams_ms_lst.to_csv('prams_ms.csv')
结果为:
序号
键名
0
_conv_stem.weight
1
_bn0.moving_mean
2
_bn0.moving_variance
3
_bn0.gamma
4
_bn0.beta
5
_0.depthwise_conv.weight
6
_0.bn1.moving_mean
7
_0.bn1.moving_variance
8
_0.bn1.gamma
9
_0.bn1.beta
10
_0.se_reduce.weight
\begin{array}{cl} \hline \text{序号} & \text{键名} \\ \hline 0 & \text{\_conv\_stem.weight} \\ 1 & \text{\_bn0.moving\_mean} \\ 2 & \text{\_bn0.moving\_variance} \\ 3 & \text{\_bn0.gamma} \\ 4 & \text{\_bn0.beta} \\ 5 & \text{\_0.depthwise\_conv.weight} \\ 6 & \text{\_0.bn1.moving\_mean} \\ 7 & \text{\_0.bn1.moving\_variance} \\ 8 & \text{\_0.bn1.gamma} \\ 9 & \text{\_0.bn1.beta} \\ 10 & \text{\_0.se\_reduce.weight} \end{array}
序号012345678910键名_conv_stem.weight_bn0.moving_mean_bn0.moving_variance_bn0.gamma_bn0.beta_0.depthwise_conv.weight_0.bn1.moving_mean_0.bn1.moving_variance_0.bn1.gamma_0.bn1.beta_0.se_reduce.weight
我们将两个结果放在一起可以看出,Pytorch模型和MindSpore模型具有相似的、一一对应的模型参数名,下面给出在GPT-2中全部的参数名对应结果以供参考:
PyTorch 键名
MindSpore 键名
transformer.h.{}.ln_1.weight
backbone.blocks.{}.layernorm1.gamma
transformer.h.{}.ln_1.bias
backbone.blocks.{}.layernorm1.beta
transformer.h.{}.ln_2.weight
backbone.blocks.{}.layernorm2.gamma
transformer.h.{}.ln_2.bias
backbone.blocks.{}.layernorm2.beta
transformer.h.{}.attn.c_proj.weight
backbone.blocks.{}.attention.projection.weight
transformer.h.{}.attn.c_proj.bias
backbone.blocks.{}.attention.projection.bias
transformer.h.{}.attn.c_attn.weight.q
backbone.blocks.{}.attention.dense1.weight
transformer.h.{}.attn.c_attn.bias.q
backbone.blocks.{}.attention.dense1.bias
transformer.h.{}.attn.c_attn.weight.k
backbone.blocks.{}.attention.dense2.weight
transformer.h.{}.attn.c_attn.bias.k
backbone.blocks.{}.attention.dense2.bias
transformer.h.{}.attn.c_attn.weight.v
backbone.blocks.{}.attention.dense3.weight
transformer.h.{}.attn.c_attn.bias.v
backbone.blocks.{}.attention.dense3.bias
transformer.h.{}.mlp.c_fc.weight
backbone.blocks.{}.output.mapping.weight
transformer.h.{}.mlp.c_fc.bias
backbone.blocks.{}.output.mapping.bias
transformer.h.{}.mlp.c_proj.weight
backbone.blocks.{}.output.projection.weight
transformer.h.{}.mlp.c_proj.bias
backbone.blocks.{}.output.projection.bias
transformer.ln_f.weight
backbone.layernorm.gamma
transformer.ln_f.bias
backbone.layernorm.beta
transformer.wte.weight
backbone.embedding.word_embedding.embedding_table
transformer.wpe.weight
backbone.embedding.position_embedding.embedding_table
\begin{array}{ll} \text{PyTorch 键名} & \text{MindSpore 键名} \\ \hline \text{transformer.h.\{\}.ln\_1.weight} & \text{backbone.blocks.\{\}.layernorm1.gamma} \\ \text{transformer.h.\{\}.ln\_1.bias} & \text{backbone.blocks.\{\}.layernorm1.beta} \\ \text{transformer.h.\{\}.ln\_2.weight} & \text{backbone.blocks.\{\}.layernorm2.gamma} \\ \text{transformer.h.\{\}.ln\_2.bias} & \text{backbone.blocks.\{\}.layernorm2.beta} \\ \text{transformer.h.\{\}.attn.c\_proj.weight} & \text{backbone.blocks.\{\}.attention.projection.weight} \\ \text{transformer.h.\{\}.attn.c\_proj.bias} & \text{backbone.blocks.\{\}.attention.projection.bias} \\ \text{transformer.h.\{\}.attn.c\_attn.weight.q} & \text{backbone.blocks.\{\}.attention.dense1.weight} \\ \text{transformer.h.\{\}.attn.c\_attn.bias.q} & \text{backbone.blocks.\{\}.attention.dense1.bias} \\ \text{transformer.h.\{\}.attn.c\_attn.weight.k} & \text{backbone.blocks.\{\}.attention.dense2.weight} \\ \text{transformer.h.\{\}.attn.c\_attn.bias.k} & \text{backbone.blocks.\{\}.attention.dense2.bias} \\ \text{transformer.h.\{\}.attn.c\_attn.weight.v} & \text{backbone.blocks.\{\}.attention.dense3.weight} \\ \text{transformer.h.\{\}.attn.c\_attn.bias.v} & \text{backbone.blocks.\{\}.attention.dense3.bias} \\ \text{transformer.h.\{\}.mlp.c\_fc.weight} & \text{backbone.blocks.\{\}.output.mapping.weight} \\ \text{transformer.h.\{\}.mlp.c\_fc.bias} & \text{backbone.blocks.\{\}.output.mapping.bias} \\ \text{transformer.h.\{\}.mlp.c\_proj.weight} & \text{backbone.blocks.\{\}.output.projection.weight} \\ \text{transformer.h.\{\}.mlp.c\_proj.bias} & \text{backbone.blocks.\{\}.output.projection.bias} \\ \text{transformer.ln\_f.weight} & \text{backbone.layernorm.gamma} \\ \text{transformer.ln\_f.bias} & \text{backbone.layernorm.beta} \\ \text{transformer.wte.weight} & \text{backbone.embedding.word\_embedding.embedding\_table} \\ \text{transformer.wpe.weight} & \text{backbone.embedding.position\_embedding.embedding\_table} \\ \end{array}
PyTorch 键名transformer.h.{}.ln_1.weighttransformer.h.{}.ln_1.biastransformer.h.{}.ln_2.weighttransformer.h.{}.ln_2.biastransformer.h.{}.attn.c_proj.weighttransformer.h.{}.attn.c_proj.biastransformer.h.{}.attn.c_attn.weight.qtransformer.h.{}.attn.c_attn.bias.qtransformer.h.{}.attn.c_attn.weight.ktransformer.h.{}.attn.c_attn.bias.ktransformer.h.{}.attn.c_attn.weight.vtransformer.h.{}.attn.c_attn.bias.vtransformer.h.{}.mlp.c_fc.weighttransformer.h.{}.mlp.c_fc.biastransformer.h.{}.mlp.c_proj.weighttransformer.h.{}.mlp.c_proj.biastransformer.ln_f.weighttransformer.ln_f.biastransformer.wte.weighttransformer.wpe.weightMindSpore 键名backbone.blocks.{}.layernorm1.gammabackbone.blocks.{}.layernorm1.betabackbone.blocks.{}.layernorm2.gammabackbone.blocks.{}.layernorm2.betabackbone.blocks.{}.attention.projection.weightbackbone.blocks.{}.attention.projection.biasbackbone.blocks.{}.attention.dense1.weightbackbone.blocks.{}.attention.dense1.biasbackbone.blocks.{}.attention.dense2.weightbackbone.blocks.{}.attention.dense2.biasbackbone.blocks.{}.attention.dense3.weightbackbone.blocks.{}.attention.dense3.biasbackbone.blocks.{}.output.mapping.weightbackbone.blocks.{}.output.mapping.biasbackbone.blocks.{}.output.projection.weightbackbone.blocks.{}.output.projection.biasbackbone.layernorm.gammabackbone.layernorm.betabackbone.embedding.word_embedding.embedding_tablebackbone.embedding.position_embedding.embedding_table
转化代码
基于上面的思路,我们将Pytorch模型中全部的参数名替换为MindSpore中可识别的参数名,转换代码convert_weight.py如下:
"""Convert checkpoint from torch/huggingface"""
import argparse
import numpy as np
import torch
from mindspore import save_checkpoint, Tensor
def generate_params_dict(total_layers,
mindspore_params_per_layer,
torch_params_per_layer,
mindspore_additional_params,
torch_additional_params):
"""
Generate the total parameter mapping of mindspore and pytorch.
Args:
total_layers(int): The total layers of the net.
mindspore_params_per_layer(list): The list of params per layer for the net of mindspore.
torch_params_per_layer(list): The list of params per layer for the net of pytorch.
mindspore_additional_params(list): The list of params outside the layer for the net of mindspore
torch_additional_params(list): The list of params outside the layer for the net of pytorch.
Returns:
A list of tuple. The first element is the parameter name of mindspore,
the another is the parameter name of pytorch.
"""
mapped_params = list(zip(mindspore_params_per_layer, torch_params_per_layer))
ms_extend_param_list = []
torch_extend_param_list = []
for i in range(total_layers):
for ms_para, torch_para in mapped_params:
src = ms_para.format(i)
tgt = torch_para.format(i)
ms_extend_param_list.append(src)
torch_extend_param_list.append(tgt)
mapped_params = list(zip(mindspore_additional_params, torch_additional_params))
for ms_para, torch_para in mapped_params:
ms_extend_param_list.append(ms_para)
torch_extend_param_list.append(torch_para)
return list(zip(ms_extend_param_list, torch_extend_param_list))
def print_dict(input_dict):
"""
Print the keys and values of input dict
Args:
input_dict(dict): input dict with key and value.
Returns:
None
"""
# for k, v in input_dict.items():
# print(f"Param: {k} with shape {v}")
def get_converted_ckpt(mapped_params, weight_dict):
"""
Print the keys of the loaded checkpoint
Args:
mapped_params(dict): The loaded checkpoint. The key is parameter name and value is the numpy array.
weight_dict(dict): The loaded pytorch checkpoint.
Returns:
None
"""
new_ckpt_list = []
# Currently, the ms_extend_param the torch_extend_param is the full parameters.
for src, tgt in mapped_params:
if tgt not in weight_dict:
# print(f"Missing in PyTorch state dict: {tgt}")
continue
value = weight_dict[tgt].numpy()
# split the attention layer for q, k, v
if 'c_attn.weight' in tgt:
# print("tgt:", tgt)
value = np.transpose(value, [1, 0])
# print(f"Mapping table Mindspore:{src:<30} \t Torch:{tgt:<30} with shape {value.shape}")
new_ckpt_list.append({"data": Tensor(value), "name": src})
return new_ckpt_list
def split_torch_attention(state):
s = list(state.keys())
for name in s:
if name.endswith('attn.c_attn.weight') or name.endswith('attn.c_attn.bias'):
value = state.pop(name)
q, k, v = np.split(value.numpy(), 3, -1)
state[name + '.q'] = torch.tensor(q, dtype=value.dtype)
state[name + '.k'] = torch.tensor(k)
state[name + '.v'] = torch.tensor(v)
if __name__ == '__main__':
parser = argparse.ArgumentParser(description="OPT convert script")
parser.add_argument('--layers',
type=int,
default=12,
help="The number of layers of the model to be converted.")
parser.add_argument("--torch_path",
type=str,
default=None,
required=True,
help="The torch checkpoint path.")
parser.add_argument("--mindspore_path",
type=str,
required=True,
default="The output mindspore checkpoint path.",
help="Use device nums, default is 128.")
opt = parser.parse_args()
state_dict = torch.load(opt.torch_path, map_location='cpu')
# print_dict(state_dict)
ms_name = [
"backbone.blocks.{}.layernorm1.gamma",
"backbone.blocks.{}.layernorm1.beta",
"backbone.blocks.{}.layernorm2.gamma",
"backbone.blocks.{}.layernorm2.beta",
"backbone.blocks.{}.attention.projection.weight",
"backbone.blocks.{}.attention.projection.bias",
"backbone.blocks.{}.attention.dense1.weight",
"backbone.blocks.{}.attention.dense1.bias",
"backbone.blocks.{}.attention.dense2.weight",
"backbone.blocks.{}.attention.dense2.bias",
"backbone.blocks.{}.attention.dense3.weight",
"backbone.blocks.{}.attention.dense3.bias",
"backbone.blocks.{}.output.mapping.weight",
"backbone.blocks.{}.output.mapping.bias",
"backbone.blocks.{}.output.projection.weight",
"backbone.blocks.{}.output.projection.bias",
]
torch_name = [
"transformer.h.{}.ln_1.weight",
"transformer.h.{}.ln_1.bias",
"transformer.h.{}.ln_2.weight",
"transformer.h.{}.ln_2.bias",
"transformer.h.{}.attn.c_proj.weight",
"transformer.h.{}.attn.c_proj.bias",
"transformer.h.{}.attn.c_attn.weight.q",
"transformer.h.{}.attn.c_attn.bias.q",
"transformer.h.{}.attn.c_attn.weight.k",
"transformer.h.{}.attn.c_attn.bias.k",
"transformer.h.{}.attn.c_attn.weight.v",
"transformer.h.{}.attn.c_attn.bias.v",
"transformer.h.{}.mlp.c_fc.weight",
"transformer.h.{}.mlp.c_fc.bias",
"transformer.h.{}.mlp.c_proj.weight",
"transformer.h.{}.mlp.c_proj.bias"
]
addition_mindspore = [
"backbone.layernorm.gamma",
"backbone.layernorm.beta",
"backbone.embedding.word_embedding.embedding_table",
"backbone.embedding.position_embedding.embedding_table",
]
addition_torch = [
"transformer.ln_f.weight",
"transformer.ln_f.bias",
"transformer.wte.weight",
"transformer.wpe.weight",
]
mapped_param = generate_params_dict(total_layers=opt.layers,
mindspore_params_per_layer=ms_name,
torch_params_per_layer=torch_name,
mindspore_additional_params=addition_mindspore,
torch_additional_params=addition_torch)
split_torch_attention(state_dict)
new_ckpt = get_converted_ckpt(mapped_param, state_dict)
save_checkpoint(new_ckpt, opt.mindspore_path)
print(f"Convert finished, the output is saved to {opt.mindspore_path}")
通过调用下面的命令完成转换:
python convert_weight.py --layers 10 --torch_path "你的Pytorch模型位置" --mindspore_path "输出MindSpore模型位置"
注意此GPT-2模型是10层,代码中的默认层数是12层
完成后我们得到了MindSpore能使用的GPT-2模型
代码迁移
完成模型转换之后我们仍不能直接使用模型,如果简单替换模型运行interact.py,会导致如下报错:
ValueError: For 'Mul', x.shape and y.shape need to broadcast. The value of x.shape[1] or y.shape[1] must be 1 or -1 when they are not the same, but got x.shape = [const vector]{1, 4, 4} and y.shape = [const vector]{1, 300, 300}
这是由于MindSpore中的GPT2LMHeadModel实现中并没有实现填充Padding的功能,它将这些功能集成到了model.generate这个API中,但我们生成聊天语句并不是简单的文本生成,因此不能直接使用model.generate这个API,我们希望在尽量不改动MindSpore源码的情况下完成聊天功能的实现,我们需要去手动的实现填充功能。
代码如下:
def pad_input_ids(input_ids, pad_length=300, pad_token_id=0):
# 确保 input_ids 是一个 numpy 数组
if isinstance(input_ids, Tensor):
input_ids = input_ids.asnumpy() # 将 Mindspore Tensor 转换为 NumPy 数组
elif not isinstance(input_ids, np.ndarray):
input_ids = np.array(input_ids)
# 获取当前的批次大小和序列长度
batch_size, current_seq_length = input_ids.shape
# 计算需要填充的长度
padding_length = max(0, pad_length - current_seq_length)
# 如果不需要填充,直接返回原始数组
if padding_length == 0:
return Tensor(input_ids, dtype=mstype.int32)
# 创建填充数组
padding = np.full((batch_size, padding_length), pad_token_id)
# 将原始input_ids和填充合并
padded_input_ids = np.concatenate([input_ids, padding], axis=1)
# 将结果转换为 Mindspore Tensor
return Tensor(padded_input_ids, dtype=mstype.int32)
最后我们将所有的PyTorch的API通过MindSpore给出文档替换为MindSpore自己实现的API,完整的交互代码如下:
import mindspore
import os
import argparse
from datetime import datetime
import logging
from mindformers import GPT2LMHeadModel
from mindformers import BertTokenizer
from mindspore import ops
import numpy as np
import mindspore.common.dtype as mstype
from mindspore import Tensor
PAD = '[PAD]'
pad_id = 0
def set_args():
"""
Sets up the arguments.
"""
parser = argparse.ArgumentParser()
parser.add_argument('--device', default='0', type=str, required=False, help='生成设备')
parser.add_argument('--temperature', default=1, type=float, required=False, help='生成的temperature')
parser.add_argument('--topk', default=5, type=int, required=False, help='最高k选1')
parser.add_argument('--topp', default=0, type=float, required=False, help='最高积累概率')
# parser.add_argument('--model_config', default='model/config.json', type=str, required=False,help='模型参数')
parser.add_argument('--log_path', default='data/interact.log', type=str, required=False,
help='interact日志存放位置')
parser.add_argument('--vocab_path', default='vocab/vocab.txt', type=str, required=False, help='选择词库')
parser.add_argument('--model_path', default='model/', type=str, required=False, help='对话模型路径')
parser.add_argument('--save_samples_path', default="sample/", type=str, required=False,
help="保存聊天记录的文件路径")
parser.add_argument('--repetition_penalty', default=1.0, type=float, required=False,
help="重复惩罚参数,若生成的对话重复性较高,可适当提高该参数")
# parser.add_argument('--seed', type=int, default=None, help='设置种子用于生成随机数,以使得训练的结果是确定的')
parser.add_argument('--max_len', type=int, default=25, help='每个utterance的最大长度,超过指定长度则进行截断')
parser.add_argument('--max_history_len', type=int, default=3, help="dialogue history的最大长度")
parser.add_argument('--no_cuda', action='store_true', help='不使用GPU进行预测')
return parser.parse_args()
def create_logger(args):
"""
将日志输出到日志文件和控制台
"""
logger = logging.getLogger(__name__)
logger.setLevel(logging.INFO)
formatter = logging.Formatter(
'%(asctime)s - %(levelname)s - %(message)s')
# 创建一个handler,用于写入日志文件
file_handler = logging.FileHandler(
filename=args.log_path)
file_handler.setFormatter(formatter)
file_handler.setLevel(logging.INFO)
logger.addHandler(file_handler)
# 创建一个handler,用于将日志输出到控制台
console = logging.StreamHandler()
console.setLevel(logging.DEBUG)
console.setFormatter(formatter)
logger.addHandler(console)
return logger
def top_k_top_p_filtering(logits, top_k=0, top_p=0.0, filter_value=-float('Inf')):
assert logits.dim() == 1 # batch size 1 for now - could be updated for more but the code would be less clear
top_k = min(top_k, logits.shape[-1]) # Safety check
if top_k > 0:
# Remove all tokens with a probability less than the last token of the top-k
# torch.topk()返回最后一维最大的top_k个元素,返回值为二维(values,indices)
# ...表示其他维度由计算机自行推断
indices_to_remove = logits < mindspore.ops.topk(logits, top_k)[0][..., -1, None]
logits[indices_to_remove] = filter_value # 对于topk之外的其他元素的logits值设为负无穷
if top_p > 0.0:
sorted_logits, sorted_indices = mindspore.ops.sort(logits, descending=True) # 对logits进行递减排序
cumulative_probs = mindspore.Tensor.cumsum(ops.softmax(sorted_logits, axis=-1), axis=-1)
# Remove tokens with cumulative probability above the threshold
sorted_indices_to_remove = cumulative_probs > top_p
# Shift the indices to the right to keep also the first token above the threshold
sorted_indices_to_remove[..., 1:] = sorted_indices_to_remove[..., :-1].clone()
sorted_indices_to_remove[..., 0] = 0
indices_to_remove = sorted_indices[sorted_indices_to_remove]
logits[indices_to_remove] = filter_value
return logits
def pad_input_ids(input_ids, pad_length=300, pad_token_id=0):
# 确保 input_ids 是一个 numpy 数组
if isinstance(input_ids, Tensor):
input_ids = input_ids.asnumpy() # 将 Mindspore Tensor 转换为 NumPy 数组
elif not isinstance(input_ids, np.ndarray):
input_ids = np.array(input_ids)
# 获取当前的批次大小和序列长度
batch_size, current_seq_length = input_ids.shape
# 计算需要填充的长度
padding_length = max(0, pad_length - current_seq_length)
# 如果不需要填充,直接返回原始数组
if padding_length == 0:
return Tensor(input_ids, dtype=mstype.int32)
# 创建填充数组
padding = np.full((batch_size, padding_length), pad_token_id)
# 将原始input_ids和填充合并
padded_input_ids = np.concatenate([input_ids, padding], axis=1)
# 将结果转换为 Mindspore Tensor
return Tensor(padded_input_ids, dtype=mstype.int32)
def main():
args = set_args()
logger = create_logger(args)
tokenizer = BertTokenizer(vocab_file=args.vocab_path, sep_token="[SEP]", pad_token="[PAD]", cls_token="[CLS]")
# tokenizer = BertTokenizer(vocab_file=args.voca_path)
model = GPT2LMHeadModel.from_pretrained(args.model_path)
model.set_train(False)
if args.save_samples_path:
if not os.path.exists(args.save_samples_path):
os.makedirs(args.save_samples_path)
samples_file = open(args.save_samples_path + '/samples.txt', 'a', encoding='utf8')
samples_file.write("聊天记录{}:\n".format(datetime.now()))
# 存储聊天记录,每个utterance以token的id的形式进行存储
history = []
print('开始和chatbot聊天,输入CTRL + Z以退出')
while True:
try:
text = input("user:")
if args.save_samples_path:
samples_file.write("user:{}\n".format(text))
text_ids = tokenizer.encode(text, add_special_tokens=False)
history.append(text_ids)
input_ids = [tokenizer.cls_token_id] # 每个input以[CLS]为开头
for history_id, history_utr in enumerate(history[-args.max_history_len:]):
input_ids.extend(history_utr)
input_ids.append(tokenizer.sep_token_id)
# print(input_ids)
input_ids = np.array(input_ids)
seq_len = input_ids.shape[0]
input_ids = mindspore.tensor(input_ids, dtype=mindspore.int32)
input_ids = input_ids.unsqueeze(0)
# print(input_ids)
response = [] # 根据context,生成的response
# 最多生成max_len个token
for _ in range(args.max_len):
input_token = pad_input_ids(input_ids, pad_length=300)
logits_tensor, tokens, loss_mask = model(input_ids=input_token)
# print(logits_tensor.shape)
next_token_logits = logits_tensor[0, -(300-seq_len)-1, :] # 从logits张量中提取最后一个token的logits
# 对于已生成的结果generated中的每个token添加一个重复惩罚项,降低其生成概率
for id in set(response):
next_token_logits[id] /= args.repetition_penalty
next_token_logits = next_token_logits / args.temperature
# 对于[UNK]的概率设为无穷小,也就是说模型的预测结果不可能是[UNK]这个token
next_token_logits[tokenizer.convert_tokens_to_ids('[UNK]')] = -float('Inf')
filtered_logits = top_k_top_p_filtering(next_token_logits, top_k=args.topk, top_p=args.topp)
# torch.multinomial表示从候选集合中无放回地进行抽取num_samples个元素,权重越高,抽到的几率越高,返回元素的下标
next_token = mindspore.ops.multinomial(ops.softmax(filtered_logits, axis=-1), num_samples=1, replacement=False)
if next_token == tokenizer.sep_token_id: # 遇到[SEP]则表明response生成结束
break
response.append(next_token.item())
input_ids = mindspore.ops.cat((input_ids, next_token.unsqueeze(0)), axis=1)
seq_len = input_ids.shape[1]
history.append(response)
text = tokenizer.convert_ids_to_tokens(response)
print("chatbot:" + "".join(text))
if args.save_samples_path:
samples_file.write("chatbot:{}\n".format("".join(text)))
except KeyboardInterrupt:
if args.save_samples_path:
samples_file.close()
break
if __name__ == '__main__':
main()
完成后我们使用下面的代码运行人机交互:
python interact.py
具体的参数在代码中列出
使用Gradio实现可视化聊天
接下来我们使用Gradio完成一个类似ChatGPT的聊天界面,代码如下:
import gradio as gr
import time
import mindspore
import os
import argparse
from datetime import datetime
import logging
from mindformers import GPT2LMHeadModel
from mindformers import BertTokenizer
from mindspore import ops
import numpy as np
import mindspore.common.dtype as mstype
from mindspore import Tensor
# system_message = {"role": "system", "content": "You are my AI assistant."}
vocab_path = 'vocab/vocab.txt'
model_path = './model'
topp = 0
tokenizer = BertTokenizer(vocab_file=vocab_path, sep_token="[SEP]", pad_token="[PAD]", cls_token="[CLS]")
model = GPT2LMHeadModel.from_pretrained(model_path)
model.set_train(False)
def top_k_top_p_filtering(logits, top_k=0, top_p=0.0, filter_value=-float('Inf')):
assert logits.dim() == 1 # 确保logits的维度为1
top_k = min(top_k, logits.shape[-1]) # 安全检查
if top_k > 0:
# 移除概率低于top-k最后一个token的所有token
indices_to_remove = logits < ops.top_k(logits, top_k)[0][..., -1, None]
logits[indices_to_remove] = filter_value
if top_p > 0.0:
sorted_logits, sorted_indices = ops.sort(logits, descending=True)
cumulative_probs = ops.cumsum(ops.softmax(sorted_logits, axis=-1), axis=-1)
# 移除累积概率高于阈值的token
sorted_indices_to_remove = cumulative_probs > top_p
# 将索引向右移动以保留阈值以上的第一个token
sorted_indices_to_remove[..., 1:] = sorted_indices_to_remove[..., :-1].clone()
sorted_indices_to_remove[..., 0] = False
indices_to_remove = sorted_indices[sorted_indices_to_remove]
logits[indices_to_remove] = filter_value
return logits
def pad_input_ids(input_ids, pad_length=300, pad_token_id=0):
# 确保 input_ids 是一个 numpy 数组
if isinstance(input_ids, Tensor):
input_ids = input_ids.asnumpy() # 将 Mindspore Tensor 转换为 NumPy 数组
elif not isinstance(input_ids, np.ndarray):
input_ids = np.array(input_ids)
# 获取当前的批次大小和序列长度
batch_size, current_seq_length = input_ids.shape
# 计算需要填充的长度
padding_length = max(0, pad_length - current_seq_length)
# 如果不需要填充,直接返回原始数组
if padding_length == 0:
return Tensor(input_ids, dtype=mstype.int32)
# 创建填充数组
padding = np.full((batch_size, padding_length), pad_token_id)
# 将原始input_ids和填充合并
padded_input_ids = np.concatenate([input_ids, padding], axis=1)
# 将结果转换为 Mindspore Tensor
return Tensor(padded_input_ids, dtype=mstype.int32)
with gr.Blocks(title="ChitChat") as chat:
chatbot = gr.Chatbot(label="ChitChat聊天区")
clear = gr.Button("清空聊天")
msg = gr.Textbox(label="输入问题<回车发送>", placeholder="Type here...")
temperature = gr.Slider(minimum=0.0, maximum=3.0, value=1.0, label="Temperature")
topk = gr.Number(value=5, label="Top K")
repetition_penalty = gr.Number(value=1.0, label="重复惩罚参数,若生成的对话重复性较高,可适当提高该参数")
max_len = gr.Number(value=25, label="Max Length")
max_history_len = gr.Number(value=3, label="Max History Length")
state = gr.State([])
def user(user_message, history):
return "", history + [[user_message, None]]
def bot(history, messages_history,temperature, topk, max_len, max_history_len,repetition_penalty):
user_message = history[-1][0]
bot_message, messages_history = ask_model(user_message, messages_history, temperature, topk, max_len, max_history_len,topp,repetition_penalty)
messages_history += [{"role": "assistant", "content": bot_message}]
history[-1][1] = bot_message
time.sleep(1)
return history, messages_history
def ask_model(message, messages_history,temperature, topk, max_len, max_history_len,topp,repetition_penalty):
max_history_len = int(max_history_len)
max_len = int(max_len)
topk = int(topk)
messages_history += [{"role": "user", "content": message}]
input_ids = [tokenizer.cls_token_id] # 每个input以[CLS]为开头
for history_id, history_utr in enumerate(messages_history[-max_history_len:]):
token = tokenizer.encode(history_utr["content"], add_special_tokens=False)
input_ids.extend(token)
input_ids.append(tokenizer.sep_token_id)
print(input_ids)
input_ids = np.array(input_ids)
seq_len = input_ids.shape[0]
input_ids = mindspore.tensor(input_ids, dtype=mindspore.int32)
input_ids = input_ids.unsqueeze(0)
response = []
# 最多生成max_len个token
for _ in range(max_len):
input_token = pad_input_ids(input_ids, pad_length=300)
logits_tensor, tokens, loss_mask = model(input_ids=input_token)
# print(logits_tensor.shape)
next_token_logits = logits_tensor[0, -(300 - seq_len) - 1, :] # 从logits张量中提取最后一个token的logits
# 对于已生成的结果generated中的每个token添加一个重复惩罚项,降低其生成概率
for id in set(response):
next_token_logits[id] /= repetition_penalty
next_token_logits = next_token_logits / temperature
# 对于[UNK]的概率设为无穷小,也就是说模型的预测结果不可能是[UNK]这个token
next_token_logits[tokenizer.convert_tokens_to_ids('[UNK]')] = -float('Inf')
filtered_logits = top_k_top_p_filtering(next_token_logits, top_k=topk, top_p=topp)
# torch.multinomial表示从候选集合中无放回地进行抽取num_samples个元素,权重越高,抽到的几率越高,返回元素的下标
next_token = mindspore.ops.multinomial(ops.softmax(filtered_logits, axis=-1), num_samples=1,
replacement=False)
if next_token == tokenizer.sep_token_id: # 遇到[SEP]则表明response生成结束
break
response.append(next_token.item())
input_ids = mindspore.ops.cat((input_ids, next_token.unsqueeze(0)), axis=1)
seq_len = input_ids.shape[1]
text = tokenizer.convert_ids_to_tokens(response)
text = ''.join(text)
return text, messages_history
def init_history(messages_history):
messages_history = []
return messages_history
msg.submit(user, [msg, chatbot], [msg, chatbot], queue=False).then(
bot, [chatbot, state, temperature, topk, max_len, max_history_len,repetition_penalty], [chatbot, state])
clear.click(lambda: None, None, chatbot, queue=False).success(init_history, [state], [state])
if __name__ == '__main__':
chat.launch(share=False)
全部模型和代码地址
Pytroch源码来源:https://github.com/yangjianxin1/GPT2-chitchat
Pytorch模型下载:https://pan.baidu.com/s/1iEu_-Avy-JTRsO4aJNiRiA#list/path=%2F,提取码ju6m
MindSpore代码地址:https://xihe.mindspore.cn/projects/guojialiang/ChitChat
MindSpore模型下载:https://xihe.mindspore.cn/models/guojialiang/ChitChat_model


















 1515
1515

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











