







 本文深入探讨了知识蒸馏技术,涉及其分类、蒸馏机制、离线训练方法及softmax温度调整对负样本影响。
本文深入探讨了知识蒸馏技术,涉及其分类、蒸馏机制、离线训练方法及softmax温度调整对负样本影响。
知识蒸馏Knowledge Distillation(KD)
1、简介
一种模型压缩方法
知识蒸馏的一般框架(如下图)
三部分:知识、蒸馏算法、师生架构。

知识
将知识分为三种形式:基于响应的(response-based)、基于特征的(feature-based)、基于关系的(relation-based)。
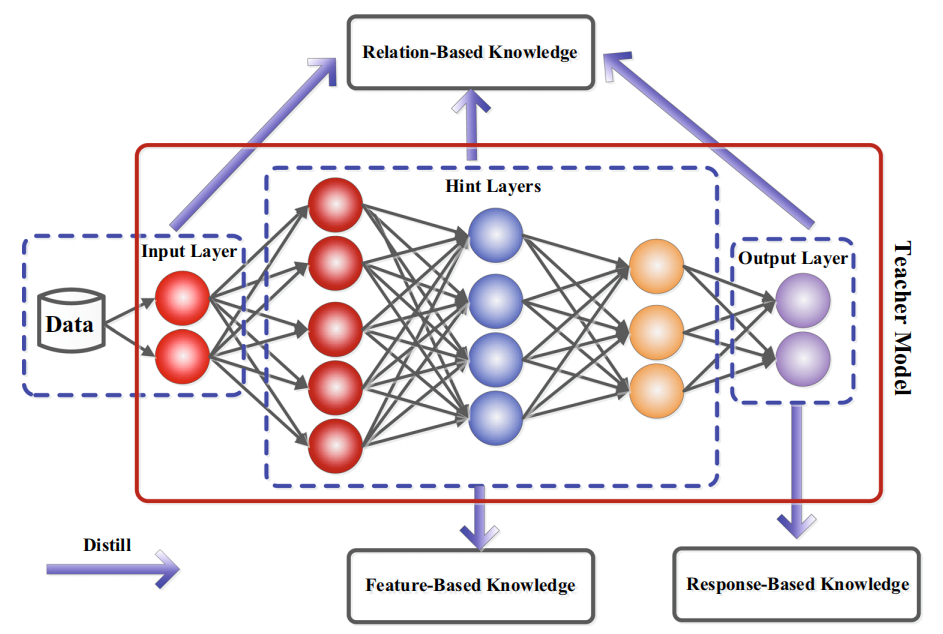
①基于响应的知识(response-based)【常用】
学习的知识是教师模型最后一个输出层logits。由于logits实际上是类别概率分布,因此基于响应的知识蒸馏限制在监督学习。
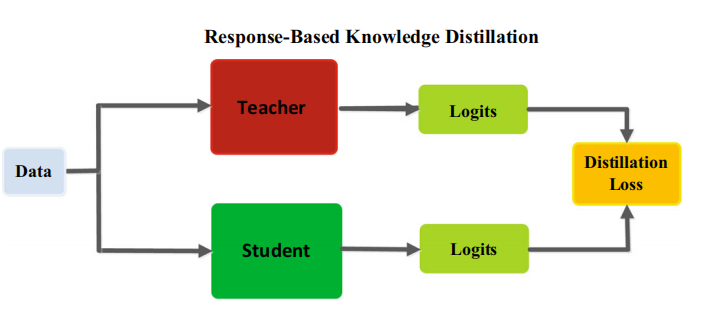
最流行的基于响应的图像分类知识被称为软目标(soft target)。
基于响应的知识蒸馏具体架构如下图。后面具体介绍该类知识蒸馏。
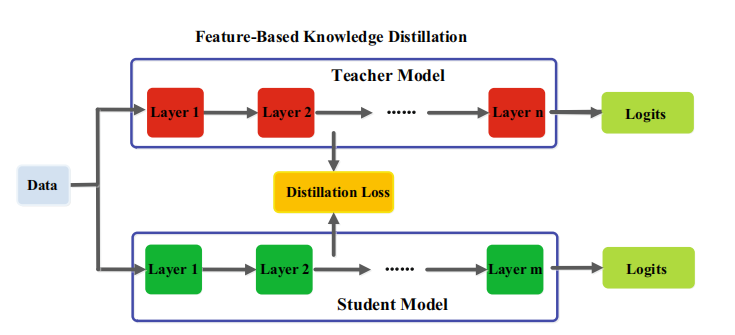
②基于特征的知识(feature-based)
学习的知识是教师模型中间层的基于特征的知识。下图为基于特征的知识蒸馏模型的通常架构。
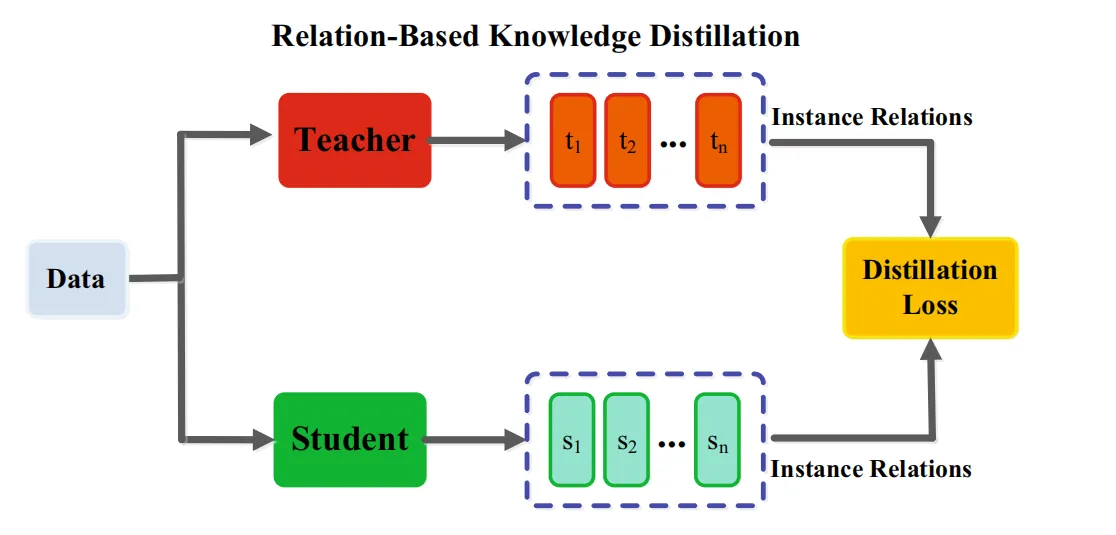
③基于关系的知识(relation-based)
基于响应和基于特征的知识都使用了教师模型中特定层的输出,基于关系的知识进一步探索了不同层或数据样本的关系。下图为实例关系的知识蒸馏架构。
蒸馏机制
根据教师模型是否与学生模型同时更新,知识蒸馏的学习方案可分为离线(offline)蒸馏、在线(online)蒸馏、自蒸馏(self-distillation)。
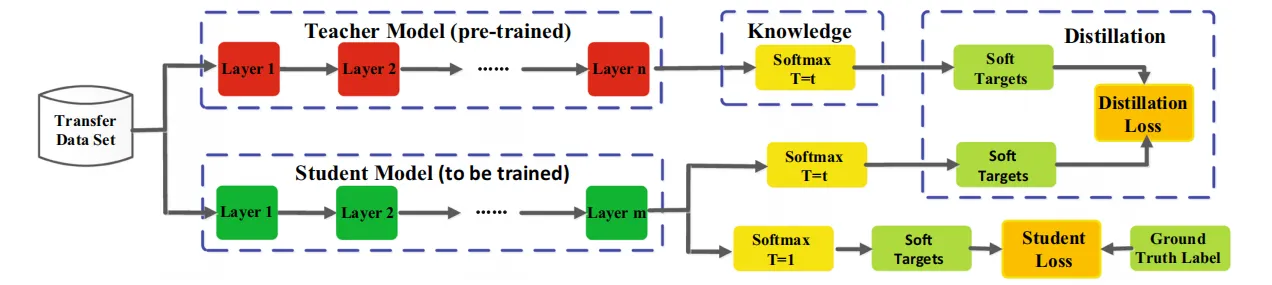
离线蒸馏(常用)
在离线蒸馏中,学生模型仅使用知识进行训练,而不与教师模型同时更新。学生模型独立地使用知识进行训练,目标是使学生模型的输出尽可能接近教师模型的输出。
大多数之前的知识蒸馏方法都是离线的。最初的知识蒸馏中,知识从预训练的教师模型转移到学生模型中,整个训练过程包括两个阶段:1)大型教师模型蒸馏前在训练样本训练;2)教师模型以logits(基于响应,生成软目标(soft target))或中间特征(基于特征)的形式提取知识,将其在蒸馏过程中指导学生模型的训练。
在线蒸馏
在线蒸馏时,教师模型和学生模型同步更新,而整个知识蒸馏框架都是端到端可训练的。
在线蒸馏是一种具有高效并行计算的单阶段端到端训练方案。然而,现有的在线方法(如相互学习)通常无法解决在线环境中的高容量教师,这使进一步探索在线环境中教师和学生模式之间的关系成为一个有趣的话题。
自蒸馏
在自蒸馏中,教师和学生模型使用相同的网络,这可以看作是在线蒸馏的一个特例。
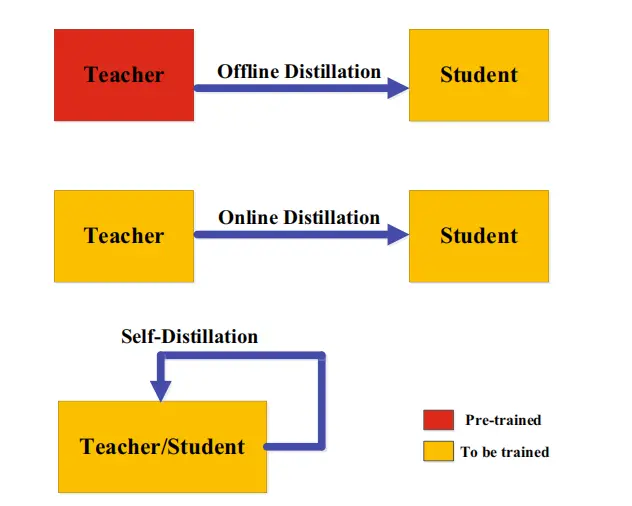
从人类师生学习的角度可以直观地理解离线、在线和自蒸馏。
离线蒸馏是指知识渊博的教师教授学生知识;
在线蒸馏是指教师和学生一起学习;
自我蒸馏是指学生自己学习知识。
师生架构
教师模型(cumbersome model):已经训练好的,较为笨重的模型。
学生模型:通过蒸馏,将教师模型中已经学习到的知识迁移到的新的轻量级的模型。
2、学生模型的训练(基于响应的离线知识蒸馏)
hard target(硬目标)与 soft target(软目标)
hard target仅包含正样本信息
soft target具有更多信息,不仅包含正样本信息,还有相似负样本信息,比如左图的正样本标签为2,但由于写法与3相像,因此对标签3也给予一定的关注通过增大概率值;而右图的正样本标签2写法与7相像,因此对标签7也给予一定的关注。
具体到代码中就是加入蒸馏温度T。

蒸馏温度 T T T
原来的softmax 将多分类的输出结果映射为概率值。 q i = e z i ∑ j = 1 n e z j q_i=\frac{e^{z_i}}{\sum_{j=1}^n{e^{z_j}}} qi=∑j=1nezjezi,其中 z i z_i zi是模型的softmax层输出logits。
在进行知识蒸馏时,如果将教师模型的softmax输出,作为学生模型的 s o f t − t a r g e t soft-target soft−target,那么负标签的值接近于0,对学生模型的损失函数贡献非常小,使得模型难以利用教师模型学到的知识。因此,提出蒸馏温度T的概念,使得softmax是输出更加平滑。
加入蒸馏温度 T T T后的softmax
q i = e ( z i / T )
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4558
4558

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









