







1.导论
心理学原理
动物需要在复杂环境下有效关注值得注意的点
心理学框架:人类根据随意线索和不随意线索选择注意点
一眼扫过去,你看到一个红色的杯子,这是随意线索,你想读书了,你看到一本书,这是不随意线索
卷积、全连接、池化层都只考虑不随意线索
·注意力机制则显示的考虑随意线索,随意线索被称之为查询(query)。每个输入是一个值(value)和不随意线索(key)的对
通过注意力池化层来有偏向性的选择选择某些输入
非参注意力池化层
给定数据(xi;yi), i = 1,..., n
平均池化是最简单的方案
更好的方案是60年代提出来的Nadaraya-Watson核回归
参数化的注意力机制
在之前的基础上引入可以学习的w
2.注意力分数
拓展到高维度

注意力池化层
Additive Attention

等价于将key和value合并起来后放入到一个隐藏大小为h输出大小为1的单隐藏层MLP
Scaled Dot-Product Attention、

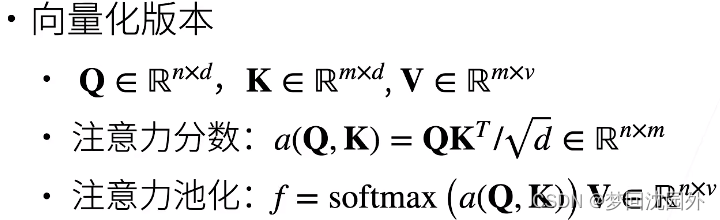
·注意力分数是query和key的相似度,注意力权重是分数的softmax结果。这就好比与,我们找工作的预期薪资,我们看的是相同行业能力差不多的人的平均薪资,相当于我们给这些人一些较大的权重。
·两种常见的分数计算:
·将query和key合并起来进入一个单输出单隐藏层的MLP·
直接将query和key做内积
3.使用注意力机制的seq2seq
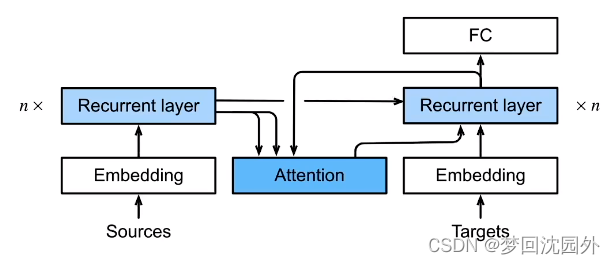
· 机器翻译中,每个生成的词可能相关于源句子中不同的词
因为在seq2seq解码器输入的是编码器最后时刻的隐藏状态。而我们希望每次在输出一个词是,生成的词主要关注于编码器中对应的词,因此,我们引入了注意力机制。

·编码器对每次词的输出作为key和value(它是编码器对应词的隐藏状态)
·解码器RNN对上一个词的输出是query·
注意力的输出和下一个词的词嵌入合并进入解码器
4.Bahdanau注意力
该层接所有编码器的输出作为输入,与解码器先前的隐藏状态(例如h)合并 该层为每个编码器的输出而输出一个分数(或嫡);该分数用于衡量每个输出与解码器先前的隐藏状态对齐的程度。最后,所有分数都经过softmax层,以获取每个编码器输出的最终权重
5.Luong注意力
由于注意力机制的目的是测量编码器的输出之一与解码器的先前隐藏状态之间的相似性,因此作者提出了简单地计算这两个向量的点积,点积给出一个分数,所有的分数(在给定的解码器时间步长)都经过softmax层以给出最终的权重,就像在Bahdanau注意力中一样。他们提出的另一种简化方法是在当前时间步而不是在前一个时间步长中使用解码器的隐藏状态(即ht)而不是(h(t-1)),然后使用注意力机制的输出(ht)直接计算解码器的预测(而不是使用它来计算解码器的当前隐藏状态)。他们还提出了一种点积机制的变体,其中编码器的输出在计算点积之前先经过线性变换(即没有偏置项的时间分布Dense层)。这称为“通用”点积方法。他们将两种点积方法与合并注意力机制进行了比较(添加了一个重新缩放参数向量v),他们观察到,点积变体的效果要好于合并注意力。因此,现在很少使用合并注意力。
6.自注意力机制
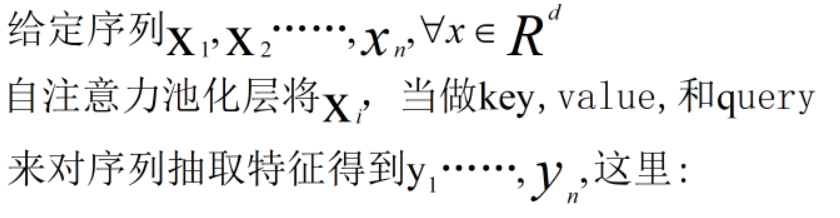
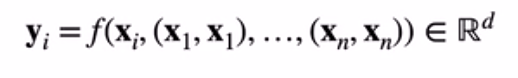
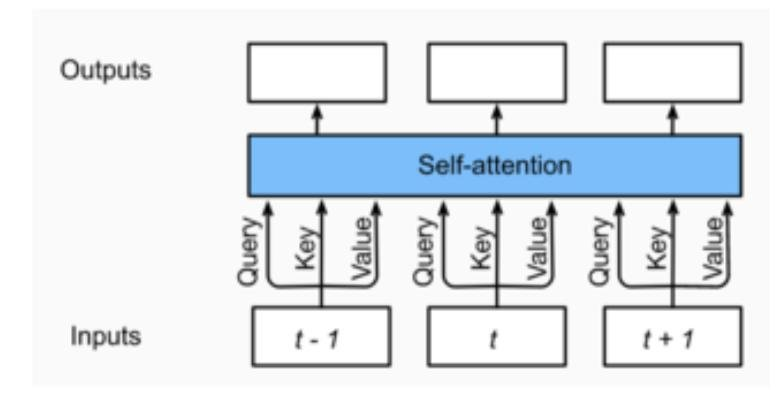 位置编码:
位置编码:
相对位置信息

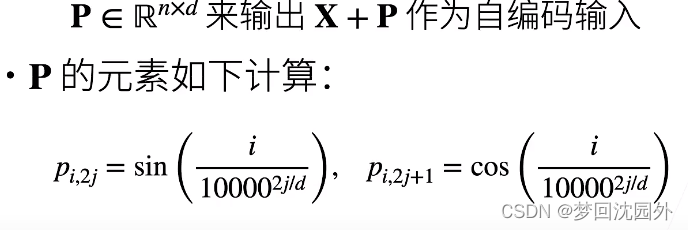
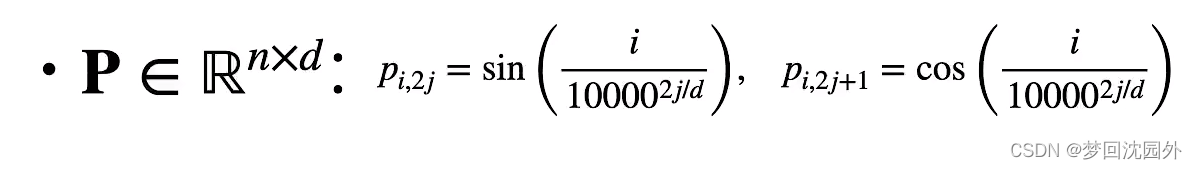
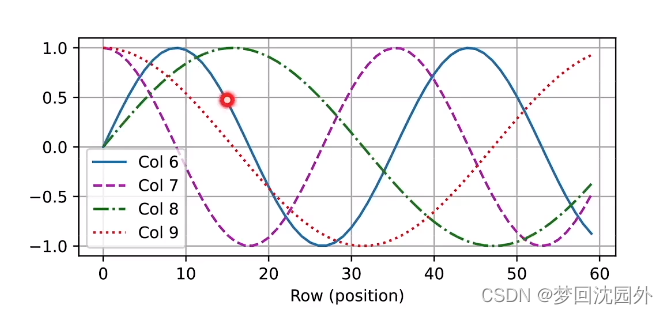

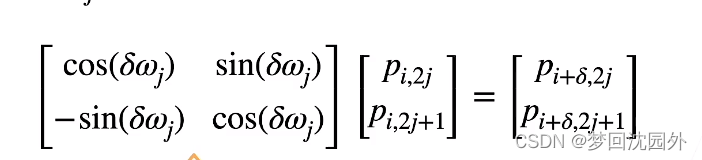
投影位置跟i无关

















 4880
4880











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











