






文章目录
前言
需求:根据提供的某个大模型的GGUF文件,将这个大模型部署、运行到目标服务器的Xinference中。
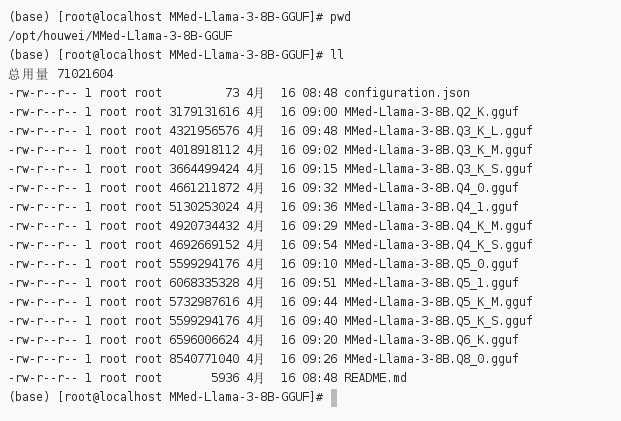
命令行
Xinference官方文档:https://inference.readthedocs.io/zh-cn/latest/models/custom.html
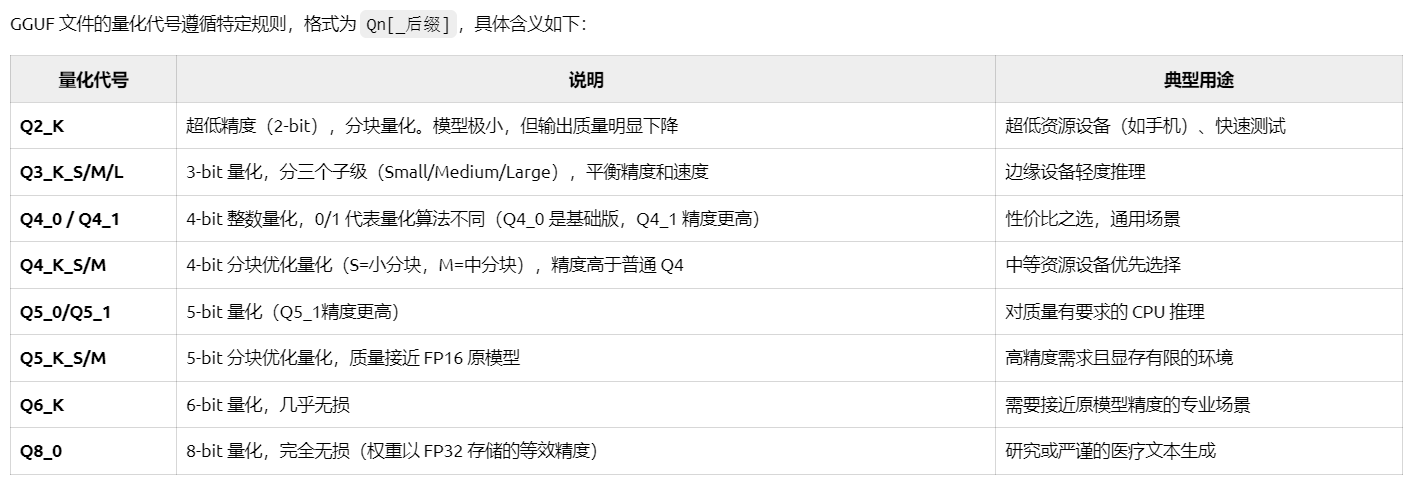
1.定义自定义大模型
根据官网文档所述,如果你想运行自定义的大模型,首先要定义自定义大语言模型,模板如下:
{
"version": 1,
"context_length": 2048,
"model_name": "custom-llama-2-chat",
"model_lang": [
"en"
],
"model_ability": [
"chat"
],
"model_family": "my-llama-2-chat",
"model_specs": [
{
"model_format": "pytorch",
"model_size_in_billions": 7,
"quantizations": [
"none"
],
"model_uri": "file:///path/to/llama-2-chat"
},
{
"model_format": "ggufv2",
"model_size_in_billions": 7,
"quantizations": [
"q4_0",
"q8_0"
],
"model_file_name_template": "llama-2-chat-7b.{quantization}.gguf"
"model_uri": "file:///path/to/gguf-file"
}
],
"chat_template": "{% if messages[0]['role'] == 'system' %}{% set system_message = '<<SYS>>\n' + messages[0]['content'] | trim + '\n<</SYS>>\n\n' %}{% set messages = messages[1:] %}{% else %}{% set system_message = '' %}{% endif %}{% for message in messages %}{% if (message['role'] == 'user') != (loop.index0 % 2 == 0) %}{{ raise_exception('Conversation roles must alternate user/assistant/user/assistant/...') }}{% endif %}{% if loop.index0 == 0 %}{% set content = system_message + message['content'] %}{% else %}{% set content = message['content'] %}{% endif %}{% if message['role'] == 'user' %}{{ '<s>' + '[INST] ' + content | trim + ' [/INST]' }}{% elif message['role'] == 'assistant' %}{{ ' ' + content | trim + ' ' + '</s>' }}{% endif %}{% endfor %}",
"stop_token_ids": [2],
"stop": []
}
model_name: 模型名称。名称必须以字母或数字开头,且只能包含字母、数字、下划线或短划线。
context_length: 一个可选的整数,模型支持的最大上下文长度,包括输入和输出长度。如果未定义,默认值为2048个token(约1,500个词)。
model_lang: 一个字符串列表,表示模型支持的语言。例如:[‘en’],表示该模型支持英语。
model_ability: 一个字符串列表,定义模型的能力。它可以包括像 ‘embed’、’generate’ 和 ‘chat’ 这样的选项。示例表示模型具有 ‘generate’ 的能力。
model_family: A required string representing the family of the model you want to register. This parameter must not conflict with any builtin model names.
model_specs: 一个包含定义模型规格的对象数组。这些规格包括:
model_format: 一个定义模型格式的字符串,可以是 ‘pytorch’ 或 ‘ggufv2’。
model_size_in_billions: 一个整数,定义模型的参数量,以十亿为单位。
quantizations: 一个字符串列表,定义模型的量化方式。对于 PyTorch 模型,它可以是 “4-bit”、”8-bit” 或 “none”。对于 ggufv2 模型,量化方式应与 model_file_name_template 中的值对应。
model_id:代表模型 id 的字符串,可以是该模型对应的 HuggingFace 仓库 id。如果 model_uri 字段缺失,Xinference 将尝试从此id指示的HuggingFace仓库下载该模型。
model_uri:表示模型文件位置的字符串,例如本地目录:”file:///path/to/llama-2-7b”。当 model_format 是 ggufv2 ,此字段必须是具体的模型文件路径。而当 model_format 是 pytorch 时,此字段必须是一个包含所有模型文件的目录。
model_file_name_template: gguf 模型所需。一个 f-string 模板,用于根据量化定义模型文件名。注意,这里不要填入文件的路径。
chat_template:如果 model_ability 中包含 chat ,那么此选项必须配置以生成合适的完整提示词。这是一个 Jinja 模版字符串。通常,你可以在模型目录的 tokenizer_config.json 文件中找到。
stop_token_ids:如果 model_ability 中包含 chat ,那么推荐配置此选项以合理控制对话的停止。这是一个包含整数的列表,你可以在模型目录的 generation_config.json 和 tokenizer_config.json 文件中提取相应的值。
stop:如果 model_ability 中包含 chat ,那么推荐配置此选项以合理控制对话的停止。这是一个包含字符串的列表,你可以在模型目录的 tokenizer_config.json 文件中找到 token 值对应的字符串。
2.注册
xinference register --model-type <model_type> --file model.json --persist
查询当前Xinference中所有的内置模型和自定义模型
xinference registrations --model-type LLM
3.启动
xinference launch --model-name custom-llama-2 --model-format pytorch
model-format需要声明文件类型,因为我当前的文件是gguf类型的,所以model-format需要修改为gguf
可视化页面
除了命令行启动的方式,也可以使用Xinference自带的可视化页面对自定义大模型进行注册、部署。
1.注册
登录到Xinference的可视化页面点击左侧的注册模型,从上往下按照实际填写,我的这个模型model-family是llama-3的,主要是填写模型规格那一栏,模型格式要选择GGUF文件格式,模型路径选择GGUF文件在服务器中的路径,
当 model_format 是 ggufv2 ,此字段必须是具体的模型文件路径。而当 model_format 是 pytorch
时,此字段必须是一个包含所有模型文件的目录。
根据官方文档上说的,所以建议GGUF格式的把路径写到文件。
都填写完毕后点击保存就可以注册成功。
2.启动
在Xinference的可视化页面点击左侧的启动模型,选择自定义模型那栏,英文版应该是CUSTOM MODEL,反正就是最后那栏。如果上一步注册成功的话可以在这里面看到你的自定义大模型。
点击想要启动的大模型,选择模型引擎等参数,点击🚀图标就可以启动。
注意:如果你注册的时候选择的文件类型为GGUF,那么启动大模型时候的模型引擎只能选llama.cpp,因此如果要跑GGUF文件的模型,你的服务器上要有llama.cpp环境。
查询是否有llama.cpp环境
python -c "import llama_cpp; print(llama_cpp.__version__)"
遇到的坑
1.注册自定义大模型的JSON文件
最开始是想用命令行注册、启动大模型,所以要自己写JSON文件,每次写都有点小问题,一般来说按照官网的案例写就可以,但是还是建议用可视化页面的方式注册吧,它生成的肯定是好用的,也方便一些。
2.资源不足(No available slot found for the model)
当注册成功后,下一步就是启动大模型,当时在我启动的时候报错,报错信息为
Server error: 503 - [address=0.0.0.0:23615, pid=9649] No available slot found for the model
查询资料后说这是典型的 资源调度器无法分配模型所需资源 的表现,意思就是没资源可用了。然后就是排查服务器的CPU、GPU、内存之类的资源是不是满了。
例如执行命令
# 查询GPU等资源使用情况
nvidia-smi
# 查看当前实例状态
xinference list --all
一顿排查发现资源还有不少,不应该没资源用了。
最后发现原因:Xinference里面之前还启动了一个deepseek的模型,当时在启动的时候有个参数是那个GPU默认选的AUTO,我那个服务器一共就两个GPU,默认AUTO启动之后直接把我两个GPU都占用了,而且查询资料发现大模型好像是独占GPU,所以就没资源跑别的模型了。最后就是他俩模型一人一个GPU就行了。
3.缺少llama.cpp环境
当我解决了资源不足的问题之后,再次点击启动出现了新的报错,报错信息如下:
Failed to import module 'llama_cpp' Please make sure 'llama_cpp' is installed. You can install it by visiting the installation section of the git repo: https://github.com/abetlen/llama-cpp-python#installation-with-openblas--cublas--clblast--metal
意思就是缺少llama.cpp环境,因为gguf文件只能用llama.cpp驱动去跑。
然后当时我看我跑其他模型的时候模型驱动那一项都是Transformer,后面问了一下大模型。
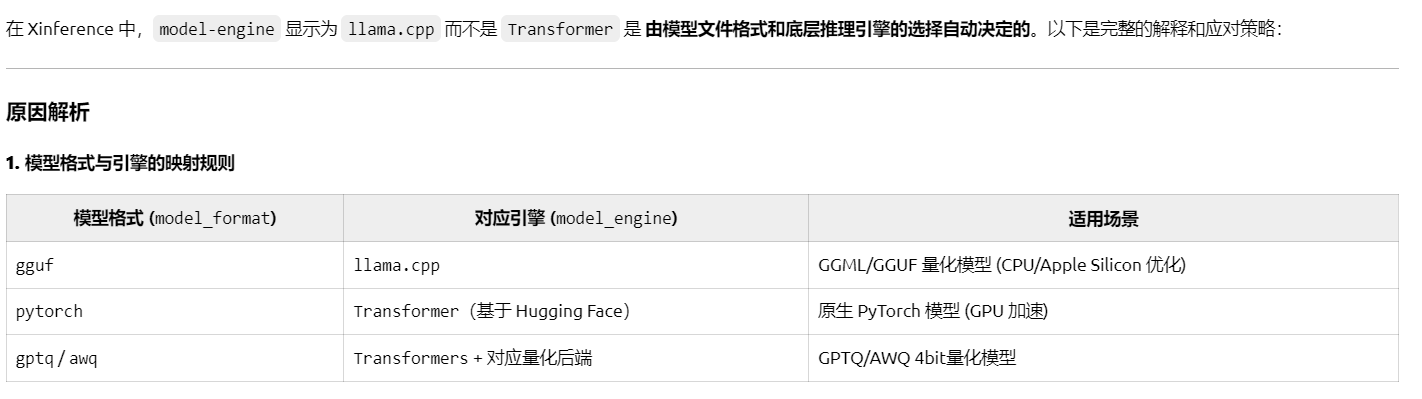
然后根据报错提示的git地址拉了一份程序上传到了服务器中
提示的git地址:https://github.com/abetlen/llama-cpp-python#installation-with-openblas–cublas–clblast–metal
后续就是上网找一些Linux安装llama-cpp-python的教程帖安装一下环境,然后按照一些帖子的命令去操作,最后到执行pip install -e .报错,报错信息如下:
ERROR: ERROR: Failed to build installable wheels for some pyproject.toml based projects (llama_cpp_python)
一般这种都是什么gcc版本问题,缺一些需要的依赖之类的,我也搞不懂,后来看了一个帖子解决了我的问题,帖子链接如下
https://blog.csdn.net/woai8339/article/details/143369842?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522c2c941f963a50b6ca466a2a7a08bd8fb%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=c2c941f963a50b6ca466a2a7a08bd8fb&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2allfirst_rank_ecpm_v1~rank_v31_ecpm-5-143369842-null-null.142v102pc_search_result_base5&utm_term=ERROR%3A%20ERROR%3A%20Failed%20to%20build%20installable%20wheels%20for%20some%20pyproject.toml%20based%20projects%20%28llama_cpp_python%29&spm=1018.2226.3001.4187
4.虚拟环境
当我成功安装了llama_cpp_python之后再去启动自定义的模型发现还是报和之前一样缺少环境的错,我很确认我当时的服务器中有这个环境。
经过一系列排查后发现原因:目标服务器的Xinference装在了虚拟环境,所以要切换到虚拟环境去装llama_cpp_python
# 切换虚拟环境,环境名按自己的来
conda activate xinference
切换完之后再安一遍llama_cpp_python就行了,安完之后用命令确认一下就行了
# 正确输出示例:0.2.77
python3 -c "import llama_cpp; print(llama_cpp.__version__)"

















 2609
2609

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









