







Implicit Process Reward Model (PRM) 是一种无需显式标注过程级奖励的数据驱动方法,通过训练基于响应级标签的结果奖励模型(Outcome Reward Model, ORM),间接生成过程级奖励。其核心是利用语言模型的对数似然比作为奖励信号,通过每一步的前向传播计算出精确的 Q 值(即累积奖励期望),从而实现对过程奖励的高效建模。Implicit PRM 不需要昂贵的逐步标注数据,却能提供稠密的、逐字级别的奖励信号,极大缓解了强化学习中稀疏奖励的问题,并显著提升推理和建模效率。
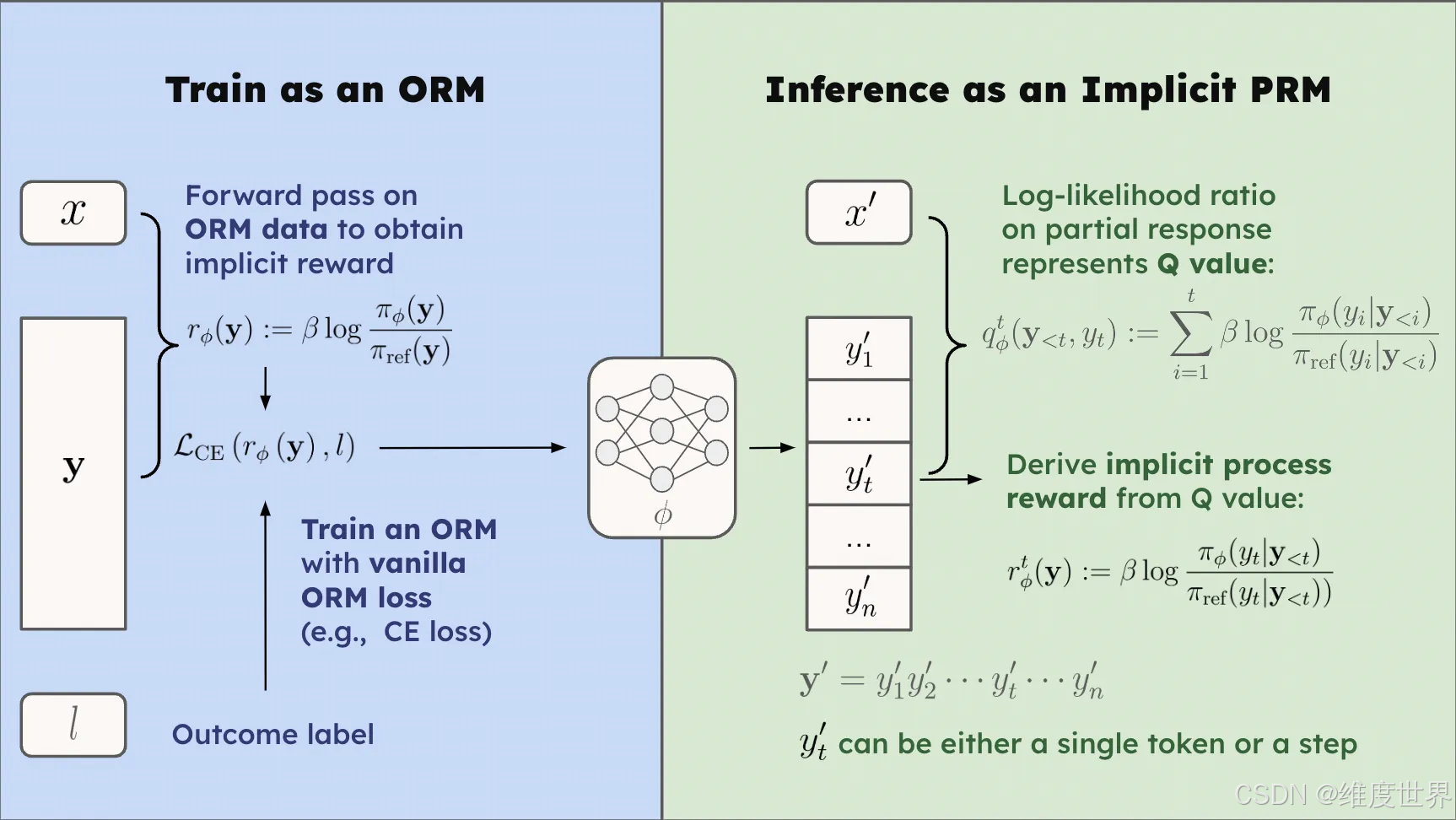
Implicit PRM 构建方法
Implicit Process Reward Model (PRM) 的目标是通过结果级奖励建模过程级奖励,提供稠密的奖励信号,从而提升强化学习的稳定性和效率。
目标模型 ( π ϕ \pi_\phi πϕ)
-
定义:
目标模型 π ϕ \pi_\phi πϕ 是我们希望优化的语言模型,具有参数 ϕ \phi ϕ。它负责生成输出序列 y \mathbf{y} y,并在强化学习过程中通过奖励信号不断改进。 -
作用:
- 生成序列:目标模型 π ϕ \pi_\phi πϕ 根据输入 x x x 和当前策略分布 π ϕ ( y ∣ x ) \pi_\phi(y | x) πϕ(y∣x) 生成候选响应序列 y \mathbf{y} y。
- 学习过程:在强化学习中,目标模型通过结合过程奖励 r ϕ t r_\phi^t rϕt 和结果奖励 r ϕ ( y ) r_\phi(\mathbf{y}) rϕ(y) 来更新其参数 ϕ \phi ϕ,从而提高生成结果的质量。
- 核心目标:优化目标模型的策略 π ϕ \pi_\phi πϕ,使得生成的序列 y \mathbf{y} y 在给定奖励函数下表现最佳。
参考模型 ( π ref \pi_{\text{ref}} πref)
-
定义:
参考模型 π ref \pi_{\text{ref}} πref 是一个预训练的、固定的语言模型,用作基准参考。它的参数是固定的,不会在训练过程中更新。 -
作用:
-
计算对数似然比:参考模型 π ref \pi_{\text{ref}} πref 的主要作用是提供一个固定的分布,用来与目标模型 π ϕ \pi_\phi πϕ 进行比较,从而计算奖励信号。其公式如下:
r ϕ ( y ) : = β log π ϕ ( y ) π ref ( y ) r_\phi(\mathbf{y}) := \beta \log \frac{\pi_\phi(\mathbf{y})}{\pi_{\text{ref}}(\mathbf{y})} rϕ(y):=βlogπref(y)πϕ(y) -
正则化训练:通过与参考模型的对比,可以避免目标模型在优化过程中生成偏离初始分布的无意义响应(即“奖励黑客”问题)。
-
固定基准:由于参考模型的参数不更新,它为奖励计算提供了一个稳定的基准,确保奖励信号的稳定性。
-
目标模型与参考模型的区别与配合
| 属性 | 目标模型 ( π ϕ \pi_\phi πϕ) | 参考模型 ( π ref \pi_{\text{ref}} πref) |
|---|---|---|
| 作用 | 优化策略以生成高质量序列 | 提供稳定的参考分布,计算奖励信号 |
| 参数是否更新 | 是:通过强化学习更新 | 否:固定不变 |
| 使用阶段 | 在训练和推断过程中均参与 | 仅用于计算奖励信号,不参与生成 |
| 核心功能 | 生成序列,并通过奖励信号更新策略 | 为目标模型提供对比基准,用于奖励计算 |
-
π ϕ \pi_\phi πϕ 是强化学习的优化目标,生成候选响应并根据奖励信号不断改进。
-
π ref \pi_{\text{ref}} π
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 775
775

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











