







 超级会员免费看
超级会员免费看
——1——
attention is all you need

Transformer
基础 Transformer 由一个编码器和一个解码器组成:
编码器:6 个编码器层
每个编码器有 2 个子层:(1)多头自注意力;(2) 前馈神经网络
解码器:6个解码层
每个解码器层有 3 个子层:(1)masked multi-head self-attention;(2) 编码器-解码器多头注意力;(3) 前馈神经网络

multi-head attention
Transformer 模型关键创新便是多头注意力(multi-head attention)
多头注意力用于编码器自注意力(将前一个编码器层的输出作为输入)、解码器自注意力(将前一个解码器层的输出作为输入)和编码器-解码器注意力(使用最终的编码器的输出)V和K的值以及之前的解码器输出Q)在上图中,使用多头注意力的模型部分在左侧用红色框起来。
另外一个便是FF前馈神经网络,前馈神经网络把数据维度变为2048,然后再转换为512维度,以便搜集更多的数据细节。

FF前馈神经网络
——2——
Universal Transformer通用模型
Universal Transformer,它将原始Transformer 模型与一种称为自适应计算时间(ACT)的技术相结合。最初的 Transformer 是一种自然语言处理模型,它并行处理输入序列中的所有单词,同时利用注意力机制来合并上下文。它的训练速度比 RNN 更快,RNN必须一个接一个地处理输入标记。Transformer在语言翻译上取得了不错的成绩。但是,它在字符串复制等算法任务上的性能较差(例如,给定“abc”作为输入,输出“abcabcabc”。)
神经 GPU 和神经图灵(其他类型的模型)在语言翻译上的性能较差,但在算法任务上的性能良好。(例如,给定“abc”作为输入,输出“abcabcabc”。)
Universal Transformer 的目标是仅使用一个模型在语言翻译和算法任务上都取得良好的性能。Universal Transformer 的作者还指出,它是一个图灵模型。
在 Universal Transformers 论文中,作者提供了一个新图来描述他们的模型:

Universal Transformers
下图修改了原始 Transformer 论文中的图,以更清楚地强调 Transformer 和 Universal Transformer 模型的区别。主要区别以红色标注:

Transformer 和 Universal Transformer 之间的主要区别
Transformer 和 Universal Transformer 之间的主要区别如下:
-
Universal Transformer 将编码器应用于每个输入token的可变步数(T 步),而基础 Transformer 仅应用 6 个编码器层。
-
Universal Transformer 将解码器应用于每个输出token的可变步数(T 步),而基础 Transformer 仅应用 6 个解码器层。
-
Universal Transformer 使用不同的输入处理:除了“位置编码”之外,它还包括“时间步嵌入”。
简而言之,自适应计算时间是一种动态的按位置停止机制,允许对每个符号进行不同的计算量。
Universal Transformer 是一种“实时并行自注意力循环序列模型”,可在输入序列上并行化。与基础 Transformer 一样,它有一个“全局感受野”(意味着它同时查看很多单词。)主要的新想法是,在每个循环步骤中,Universal Transformer对序列中所有输入数据使用self-attention,然后是一个跨所有位置和时间步共享的“转换函数”。

Universal Transformer 的参数,包括自注意力和转换权重,与所有位置和时间步长相关联。如果 Universal Transformer 运行固定数量的步骤(而不是可变数量的步骤 T),那么 Universal Transformer 相当于一个多层 Transformer。

——3——
Universal Transformer通用模型的输入

Universal Transformer通用模型的输入
如上图所示,Universal Transformer 的输入是一个长度为 m的序列,表示为 d model维嵌入。在每个时间步,都会添加“坐标编码”。这些“坐标编码”包括位置编码(与原始 Transformer 的位置编码相同)和时间步长编码(与位置编码类似的概念,只是它基于时间 t 而不是位置 i。)
——4——
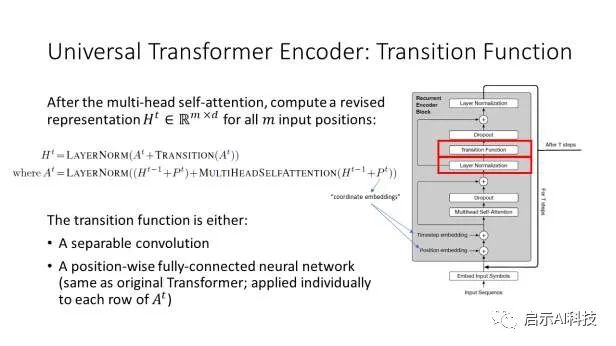
Universal Transformer通用模型的编码器
Universal Transformer 编码器的第一部分是多头自注意力,这与原始 Transformer 编码器的第一部分完全相同。

Universal Transformer通用模型的编码器
Universal Transformer 编码器的第二部分是转换函数。转换函数可以是位置范围的全连接神经网络,在这种情况下,这与原始 Transformer 编码器的第二部分完全相同。或者转换函数可以是可分离卷积。作者没有讨论何时使用按位置的全连接网络与可分离卷积,但推测这种选择会影响 Universal Transformer 在不同任务上的性能。
什么是可分离卷积?可分离卷积将卷积核拆分为两个独立的核,分别进行两次卷积:

可分离卷积
Universal Transformer编码器,如果选择按位置的前馈网络作为转换函数,则Universal Transformer 编码器与原始 Transformer 编码器相同。
——5——
Universal Transformer通用模型的解码器
类似地,如果您选择按位置前馈网络作为转换函数,Universal Transformer 解码器与原始 Transformer 解码器相同。共有三个解码器子层:
-
子层 1:多头自注意力
-
子层 2:多头编码器-解码器注意力。
-
子层 3:转换函数。
更多Transformer模型VIT 模型SWIN Transformer模型参考头条号:人工智能研究所

动图详解transfomer
——6——
Universal Transformer通用模型的训练
Universal Transformer 论文的一个很好的方面是它提供了更多关于如何训练transformer的背景知识。这也适用于原始的 Transformer,但在原始的 Transformer 论文中没有详细讨论。
Transformer 解码器(原始和通用)是“自回归的”,这意味着它一次生成一个输出。它使用“teacher-forcing”进行训练。shift right input的sequence mask(因此模型看不到当前单词它应该是预测的)和被屏蔽的(所以模型看不到未来的信息。),这些都跟transformer模型一致。
——7——
Universal Transformer通用模型的自适应计算时间 (ACT)
这是 Universal Transformers 论文的主要贡献:他们将最初在 RNN 中开发的自适应计算时间应用于 Transformer 模型:
ACT 根据模型在每一步预测的数据动态调整处理每个输入所需的计算步骤数。Universal Transformers 将动态 ACT 停止机制分别应用于每个位置(例如每个单词)。一旦一个特定的循环块停止,它的状态就会被复制到下一步,直到所有块停止,或者直到达到最大步数。编码器的最终输出是以这种方式产生的。
以下是 ACT 工作原理的简要总结:
在每一步,我们都会得到:停止概率和之前的状态(初始化为零)
一个介于 0 和 1 之间的标量停止阈值首先,我们使用 Universal Transformer 计算每个位置的新状态。然后我们使用全连接层计算概率值,该层将状态降低到 1 维,并应用 sigmoid 激活函数使输出介于 0 和 1 之间的类似概率的值。
我们现在已经了解了 Universal Transformers 中的所有关键概念。Universal Transformers 论文中有五个任务,总结如下:

Universal Transformers 论文中有五个任务
在 bAbi Question Answering 上,Universal Transformer 获得了比原始 Transformer 更好的性能。在 Universal Transformers 论文中,bAbi 任务的不同时间步长上的注意力权重有几种可视化。可视化基于对 bAbi 故事和问题中所有事实的不同头的注意力。四个不同的注意力头对应四种不同的颜色:

最后,作者展示了 Universal Transformer 在包括复制、反向和加法在内的几种算法任务上取得了良好的性能。Universal Transformer 在英德机器翻译方面的表现也优于基础 Transformer。
总结就是Universal Transformer = 原始Transformer+ 自适应计算时间

















 7764
7764











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











