







1.Markov模型
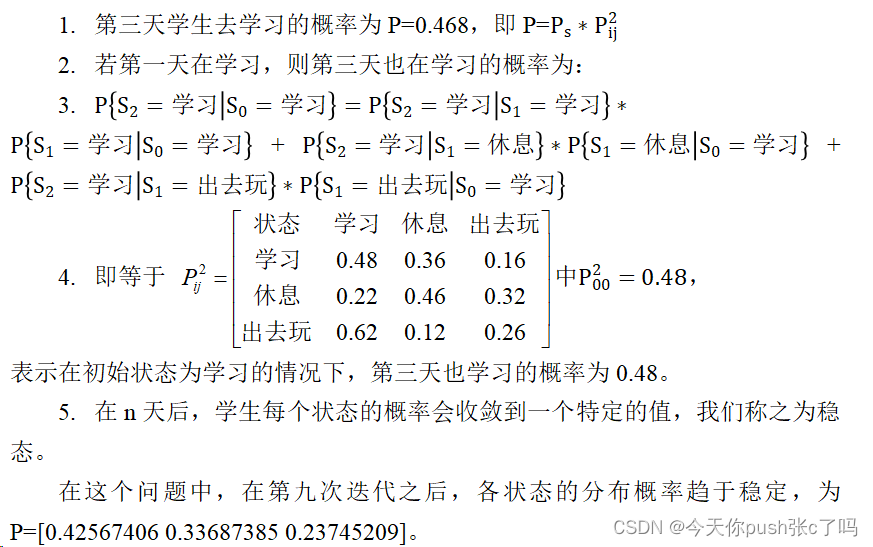
Markov是一个庞大的家族,是有马尔可夫性质(Markov property)的一类概率模型。其中,在马尔可夫过程中,我们考虑一个状态空间,该空间中的每个状态都与一个特定的概率相关。马尔可夫性质指出,在一个随机过程中,在给定当前状态的条件下,未来状态的条件分布只依赖于当前状态,而与过去的状态无关。换句话说,它具有“无记忆”或“无后效性”的特性。这意味着,在马尔可夫过程中,我们可以仅基于当前状态来预测未来的状态。
而且,马尔可夫链(Markov Chain)是描述离散时间马尔可夫过程的一种常见形式。它由一系列状态和在状态之间转移的概率组成。每个状态之间的转移概率称为转移概率矩阵。通过使用转移概率矩阵,我们可以计算在给定初始状态的情况下,随着时间的推移,系统处于不同状态的概率。
另一个与马尔可夫相关的概念是隐马尔可夫模型(Hidden Markov Model,HMM)。HMM是一种常见的统计模型,用于建模具有隐含状态的观测数据序列。在 HMM 中,状态是不可观察的,而我们只能观测到与状态相关的输出。通过学习和推断,我们可以根据观测序列来估计隐藏状态的序列
马尔可夫决策过程(Markov Decision Process,MDP)中,马尔可夫链的概念被引入到决策问题中。MDP是一种建模具有状态、动作和奖励的决策问题的工具。在MDP中,每个状态都有一个关联的奖励,智能体根据当前状态和可选的动作来选择决策,目标是最大化累积奖励。通过使用值函数、策略等概念,我们可以根据MDP模型来求解最优的决策策略,这在强化学习等领域中有广泛的应用。
马尔科夫链蒙特卡洛(Markov Chain Monte Carlo,MCMC)是一种用于模拟复杂概率分布的统计方法。MCMC是一种基于马尔科夫链的采样方法,在采样过程中利用随机漫步来探索样本空间。通过在马尔科夫链中迭代生成样本,并且样本按照一定的概率保持在某些状态上,最终得到的样本集合可以用来估计概率分布的性质,如均值、方差等。
马尔科夫随机场(Markov Random Field,MRF)是一种用于建模随机变量之间的相互依赖关系的概率图模型。它由一组随机变量组成的图结构表示,其中每个节点表示一个随机变量,边表示变量之间的依赖关系。MRF 通过定义一组能量函数来描述变量之间的关系,这些能量函数通常基于变量的局部邻域。
部分可观测马尔科夫决策过程(Partially Observable Markov Decision Process,PDMDP)是对 Markov Decision Process(马尔科夫决策过程)的扩展,其中决策者在每个状态下观察到的信息是不完全的。决策者在每个状态下接收到的观测结果取决于当前状态以及隐藏的环境状态。因此,决策者需要根据这些观测结果来选择最优的行动策略。
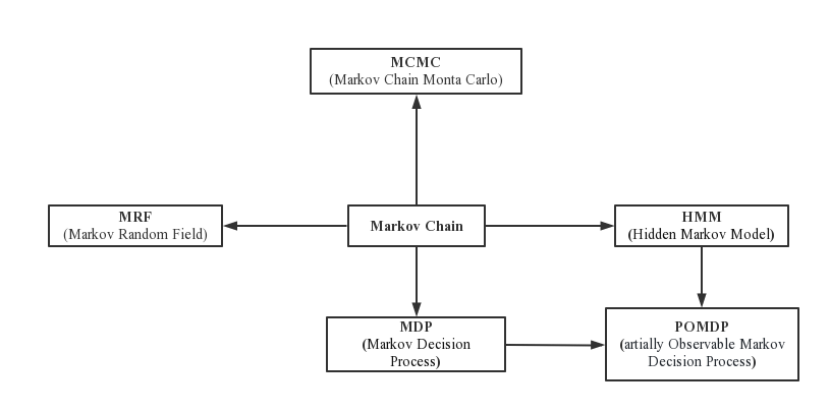
图 1 Markov家族图
1.2基本概念
1.2.1马氏链概念
马尔可夫链中的基本概念如下:
- 状态(State):马尔可夫链中每个可能的情况或状态称为一个状态。例如,在天气预测中,状态可以是"晴天"、"雨天"或"多云"等。
- 转移概率(Transition Probability):定义了从一个状态到另一个状态的转移概率。对于任意两个状态 i 和 j,转移概率 P(i, j) 表示在当前状态为 i 的条件下,下一个状态为 j 的概率。

- 转移图(Transition Diagram):用图形方式表示马尔可夫链的状态和状态之间的转移关系。每个状态作为一个节点,转移概率则表示为边。
- 初始分布(Initial Distribution):马尔可夫链开始时的状态分布概率,表示在初始时刻各个状态的概率分布。
- 马尔可夫性(Markov Property):即未来状态的概率只与当前状态有关,与过去的状态无关。这意味着给定当前状态,以及当前状态之前的所有历史状态,未来状态的概率分布只由当前状态决定。
1.2.2马氏链举例

在这里我们举一个小例子来更清晰阐述这马尔可夫链:
假设有一名学生,他的日常生活有三种状态:学习、休息和出去玩,并且他明天的状态只基于或取决于他今天的状态。这三种状态我们定义具体的转移规则,如下:
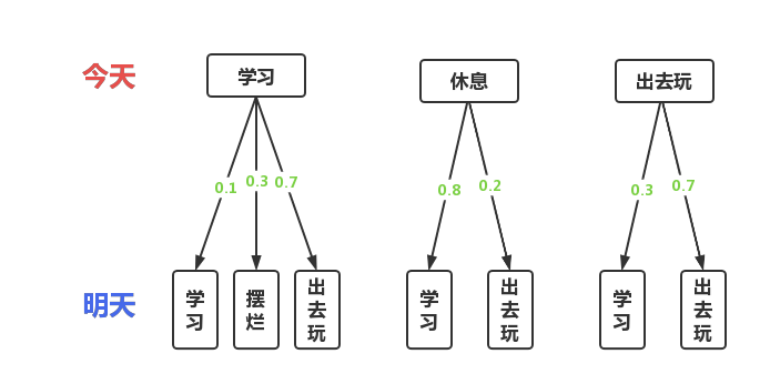
图 2 状态转移规则图示
由此我们可以画出状态转换图:
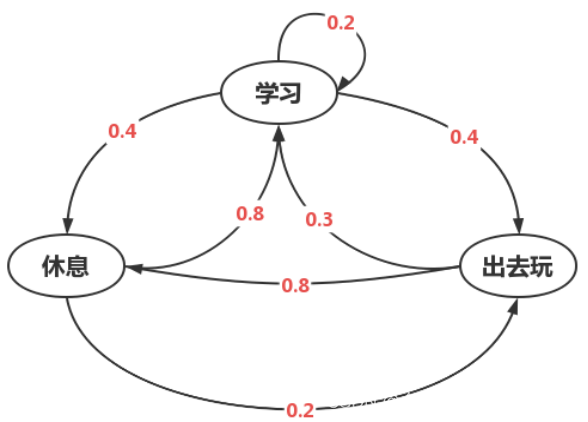
图 3 状态转移图
状态的转移矩阵P为:
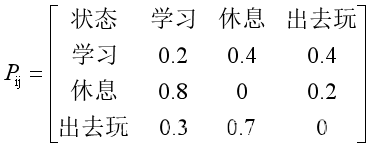
然后我们还定义初始状态的概率为: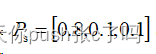 。在这个模型下,我们可以求解各种概率:
。在这个模型下,我们可以求解各种概率:
1.2.3MDP基本概念
MDP是马尔科夫链的扩展,增加了决策者在每个状态下做出的决策的概念。MDP 用于描述决策问题,其中决策者根据当前状态和可能的行动选择,以最大化长期累积奖励。故跟马尔可夫链相比,MDP的概念有如下特点:
- 决策者和行动:在 MDP 中,除了状态转移概率,还引入了决策者的行动选择。决策者在每个状态下可以选择多个行动中的一个,并且行动的选择会影响状态的转移。与马尔可夫链不同,MDP 强调决策者在每个状态下面临的决策问题。
- 奖励函数:MDP 引入了奖励函数,用来评估决策者在每个状态下所获得的即时奖励。决策者的目标是通过选择行动来最大化长期累积的奖励。马尔可夫链没有考虑具体的奖励函数。
- 目标和策略:MDP 规定了一个目标,通常是最大化累积奖励,以及一个策略,即一组决策者在每个状态下采取行动的规则。马尔可夫链没有明确的目标和策略的概念。

图 4 MDP过程图示
1.2.4 MDP求解算法
求解马尔可夫决策过程(MDP)模型的算法有多种,每种算法都有其独特的优缺点和适用范围:
1. 值迭代算法
优点:收敛速度快、易于编程实现、可用于在线计算
缺点:算法执行时间复杂度高,不适用于具有大量状态空间的问题
适用范围:适用于状态空间较小的 MDP 模型求解,能够较好地解决具有确定转移的离散问题。
2. 策略迭代算法
优点:相较于值迭代算法收敛速度较快、可用于非确定性模型的求解并且一定程度上更稳定
缺点:需要对策略进行评估操作,因此迭代次数较多,时间复杂度也相对高。
适用范围:适用于具有确定转移的离散问题的 MDP 模型求解,特别适用于解决非确定性问题。
3. Q-learning算法
优点:能够解决连续空间问题,行动空间大的 MDP 模型求解,也能到达对抗环境下的解决问题。
缺点:可能无法收敛,在某些情况下会产生过度估计和向一侧偏移的问题。
适用范围:适用于连续空间问题,行动空间大的 MDP 模型求解,另外还可以用于在强化学习无法采用监督学习的情况下的最优策略求解问题。
4. SARSA算法
优点:能够解决连续空间问题,行动空间大的 MDP 模型求解,具有广泛的应用范围。
缺点:需要事先建立模型,算法可能不够有效能。
适用范围:适用于连续空间问题,行动空间大的 MDP 模型求解,在模型已知的情况下,也是一种常用的 Q-learning 算法的替代方案。
5. DQN算法
优点:相较于 Q-learning 算法可以使用神经网络解决高维状态空间问题,并且法适用于大规模数据上训练。
缺点:不稳定性高,容易出现过拟合问题。
适用范围:适用于高维状态空间问题求解,可以使用神经网络进行优化和求解。
6. PPO算法
优点:采用了重要性采样技术,允许在更新策略时使用历史轨迹的样本数据,提高了样本利用率;使用了一种优化约束,确保策略变化不过大,从而保证训练的稳定性和收敛性;相对简单易实现,同时具有较好的性能;在训练过程中可以动态调整优化步长,并具有自适应性
缺点:需要大量的样本集进行训练,可能需要更多的时间和计算资源。
适用范围:适用于于连续动作空间的强化学习问题。
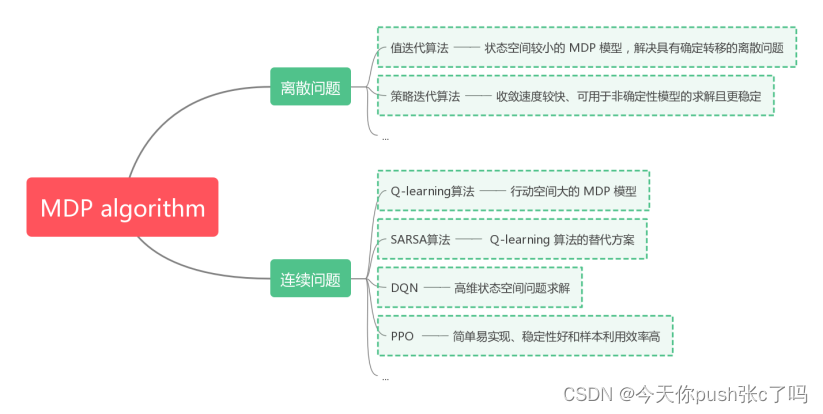
图 5 MDP算法
马尔可夫模型在管理学中具有广泛的应用,特别是在运筹学、供应链管理、金融风险管理和市场营销等领域。下面将介绍Markov模型在这些领域的具体应用。
- 库存管理
马尔可夫模型可以用于预测和优化库存水平。通过分析过去的需求和出货模式,模型可以识别不同库存状态之间的转移概率,从而进行库存水平的优化和预测。有研究针对血小板的库存控制问题,考虑短缺、浪费和输血新鲜度之间的平衡,以效用最大化为目标建立有限时域的马尔科夫决策过程模型,探讨最优的血小板订货策略和使用策略(李猜等, 2019)。
- 客户行为分析
马尔可夫模型可以分析客户行为模式,了解不同转移状态下客户的购买行为、偏好和行为模式。然后,这些分析结果可以用于制定精确的市场推广策略和客户关系管理。在客户CRM的研究当中,有学者提出了一种针对银行业客户行为预测的马尔可夫链模型,利用客户状态变量RF构建相应的客户转移矩阵(李纯青等, 2011)。
- 供应链和项目管理
在供应链中,马尔可夫模型可以用于预测供应链节点之间的转移和需求模式。这有助于优化物流计划、预测库存需求以及保持供应链的高效运转;在项目管理中,马尔可夫模型可以帮助预测不同项目阶段之间的状态转移。通过分析过去的项目数据,可以预测项目完成的时间、资源需求以及可能的风险。
- 维修和保养计划
在设备维修和保养方面,马尔可夫模型可以用于提前预测设备故障和维护需求。通过分析不同设备状态之间的转移概率,模型可以帮助制定更有效的维修和保养计划,以减少停机时间和维修成本。
在下一部分具体例子详述中,该研究就在考虑系统可靠性和维护费用的情况下,将优化问题描述为具有离散和连续混合状态和行动空间的无限水平MDP,以最大化总折扣回报为目标。通过设计一个参数化的动作空间结构和多任务强化学习框架,解决了混合动作空间带来的困难(Zhang等, 2023)。
2.2 论文具体应用详述
在该部分,我们运用论文中的具体实例来系统展示MDP的建模过程。
在系统可靠性相关研究中,考虑到现有研究缺少对维修过程的动态过程和关于负载分担的研究,有学者提出了一种求解暂态OM优化问题的无限水平MDP框架。在保证系统性能的前提下,以期望维护费用最小为目标,根据各部件的节点健康状况和负载状态动态选择维护动作。为准备DRL算法,设计了参数化的动作空间。下面主要介绍状态空间、动作空间、状态转移函数和优化公式。
- 定义状态空间:

- 确定行动集合:定义系统可以采取的行动集合,每个状态下的行动可以是离散的或连续的。
在每个检查时间步长,有四个互不相容的维护操作,包括什么都不做、纠正更换、PM和OM。每个组件必须从四个动作中选择一个,以在每个时间步长执行。这四种操作中有离散和连续两种类型,为了将他们效率结合起来一起表示,设计了如下图所示的参数空间,量化他们的效率。PM和OM的维护效率在[0,1]的范围内被参数化.
图 6 维修动作参数化
故步骤k处的动作空间被定义为:![]()
- 设立状态转移模型:

- 确定即时奖励函数:对定义在每个状态和采取每个行动后系统所获得的即时奖励(可负可正)。该模型的目标是在可接受的维护预算下保持稳定的运行性能。故MDP的目标是最大化期望的贴现回报,综合可靠系统获得的利润和在时间范围内的维护成本。奖励函数
是给定在时间步长k的状态和动作的即时奖励。对于上面所表达的MDP,奖励是完成生产任务所获得的利润减去第k次检查中的维护动作所产生的维护成本。利润的大小取决于多态系统的绩效水平。即时奖励函数表示如下:
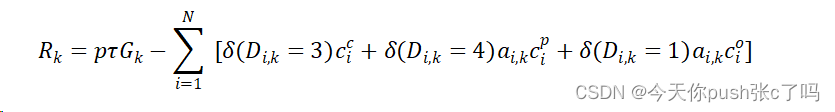
- 确定目标函数:

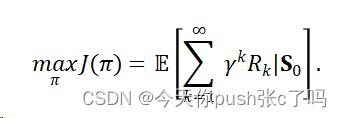
- 开始策略迭代或值迭代:

- 评估和优化策略:使用得到的最优策略或值函数进行模拟或实际测试,评估系统的性能并进行优化。根据评估结果,可以调整模型参数或策略,以满足特定需求或优化目标。该论文中运用了两个例子来进行实际测试。两个说明性示例中表示,定制的DRL方法可以有效地识别具有可接受的运行时间的最优OM策略。
马尔可夫模型可以使用多种软件工具进行建模和分析。以下是一些常用的软件工具:
R:R是一种广泛使用的统计分析软件,具有丰富的统计和机器学习功能。在R中,可以使用各种包(如"markovchain"和"HMM")来建立和分析马尔可夫模型。
Python:Python是一种通用编程语言,也被广泛用于数据科学和机器学习。在Python中,可以使用库(如"numpy"和"scipy")进行马尔可夫模型的建模和分析。
MATLAB:MATLAB是一种专业的数值计算和科学编程环境,也可用于马尔可夫模型的建模。MATLAB提供了丰富的统计和机器学习工具箱,例如"Statistics and Machine Learning Toolbox"。
SAS:SAS是一种流行的商业分析软件,也支持马尔可夫模型的建模。SAS提供了广泛的统计分析和数据挖掘功能,可以用于创建和分析马尔可夫模型。
HMMToolbox:HMMToolbox是一个专门用于隐马尔可夫模型的开源软件工具包。它提供了各种算法和函数来构建和分析隐马尔可夫模型。
3.2MDP建模示例
3.2.1问题描述

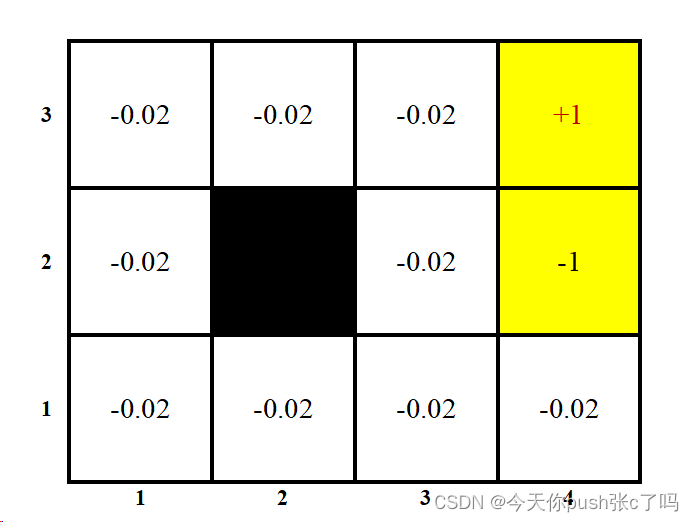
3.2.2求解步骤

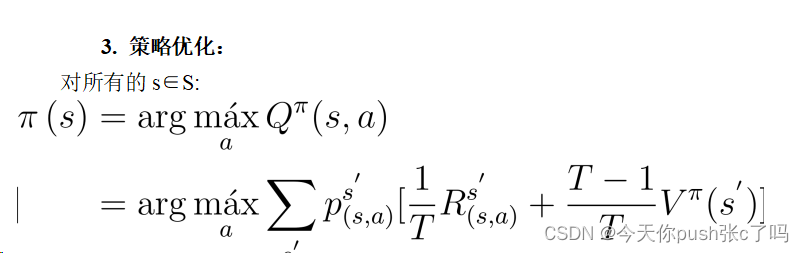
3.2.3 代码实现
import numpy as np
###part1:输入MDP四元组<S, A, P, R>, 累积奖赏参数T
S=[(1,1),(1,2),(1,3),(1,4),(2,1),(2,3),(2,4),(3,1),(3,2),(3,3),(3,4)];
size_state=len(S);#状态向量
final_state=[(2,4), (3,4)]
A=['n', 'e', 'w', 's'];size_action=len(A);#actions向量
P=[];#转移概率矩阵
for i in range(size_state):
if S[i] in final_state:
action_state=[{i:1},{i:1},{i:1},{i:1}]
else:
action_state=[]
for j in range(size_action):
state=S[i]; action=A[j];
if action=='n':
state_pro={i:0}
next_state=(state[0]+1, state[1])
if next_state in S:
state_pro[S.index(next_state)]=0.8;
else:
state_pro[i]=state_pro[i]+0.8;
next_state=(state[0], state[1]+1);
if next_state in S:
state_pro[S.index(next_state)]=0.1;
else:
state_pro[i]=state_pro[i]+0.1;
next_state=(state[0], state[1]-1)
if next_state in S:
state_pro[S.index(next_state)]=0.1;
else:
state_pro[i]=state_pro[i]+0.1
action_state.append(state_pro)
elif action=='e':
state_pro={i:0}
next_state=(state[0], state[1]+1)
if next_state in S:
state_pro[S.index(next_state)]=0.8;
else:
state_pro[i]=state_pro[i]+0.8;
next_state=(state[0]+1, state[1]);
if next_state in S:
state_pro[S.index(next_state)]=0.1;
else:
state_pro[i]=state_pro[i]+0.1;
next_state=(state[0]-1, state[1])
if next_state in S:
state_pro[S.index(next_state)]=0.1;
else:
state_pro[i]=state_pro[i]+0.1
action_state.append(state_pro)
elif action=='w':
state_pro={i:0}
next_state=(state[0], state[1]-1)
if next_state in S:
state_pro[S.index(next_state)]=0.8;
else:
state_pro[i]=state_pro[i]+0.8;
next_state=(state[0]+1, state[1]);
if next_state in S:
state_pro[S.index(next_state)]=0.1;
else:
state_pro[i]=state_pro[i]+0.1;
next_state=(state[0]-1, state[1])
if next_state in S:
state_pro[S.index(next_state)]=0.1;
else:
state_pro[i]=state_pro[i]+0.1
action_state.append(state_pro)
else:
state_pro={i:0}
next_state=(state[0]-1, state[1])
if next_state in S:
state_pro[S.index(next_state)]=0.8;
else:
state_pro[i]=state_pro[i]+0.8;
next_state=(state[0], state[1]+1);
if next_state in S:
state_pro[S.index(next_state)]=0.1;
else:
state_pro[i]=state_pro[i]+0.1;
next_state=(state[0], state[1]-1)
if next_state in S:
state_pro[S.index(next_state)]=0.1;
else:
state_pro[i]=state_pro[i]+0.1
action_state.append(state_pro)
P.append(action_state)
R = np.array([-0.02, -0.02, -0.02, -0.02, -0.02, -0.02, -0.23, -0.02, -0.02, -0.02, 1]); # rewards
print(P)
T=100;#累积步长
###part2:初始化
value=np.zeros(size_state); #初始化value
policy=np.zeros((size_state, size_action))+1/size_action;# 初始化policy
###part3:策略估计
T_MAX=100;
for t in range(1,T_MAX+1):
value_new=np.zeros(size_state);
for state in range(size_state):#对所有s,计算对应的value
for action in range(size_action):#对某个s,按照当前策略选取a
state_action_state=P[state][action]
q_state_action=0
for next_state in state_action_state:#(s, a)下,转移到s'的概率
trans_pro=state_action_state[next_state]
q_state_action=q_state_action+trans_pro*(R[next_state]/t+value[next_state]*(t-1)/t);
value_new[state]=value_new[state]+policy[state][action]*q_state_action
if t==T+1:
break
else:
value=value_new[:]
print(value);
###part3:选取最优策略
new_policy=[0 for i in range(size_state)];
opt_policy=[0 for i in range(size_state)];
policy_stable=True
while policy_stable:
for state in range(size_state):#对所有s,求对应的最优策略a
q_state_actions=[]
for action in range(size_action):#对某个s,对所有可能采取的a计算Q(s, a)
state_action_state=P[state][action]
q_state_action=0
for next_state in state_action_state:
trans_pro=state_action_state[next_state]
q_state_action=q_state_action+trans_pro*(R[next_state]/T+value[next_state]*(T-1)/T);
q_state_actions.append(q_state_action)
new_policy[state]=q_state_actions.index(max(q_state_actions));
if new_policy==opt_policy:
policy_stable=False
else:
opt_policy=new_policy
###输出结果
print('opt_policy:', opt_policy)参考文献:
[1]李猜, 耿娜, & 王春鸣. (2019). 基于MDP的血小板库存最优订货策略和使用策略研究. 运筹与管理, 28(7), 108–117. C类. [2]李纯青, 袁亮, & 马军平. (2011). 马尔可夫链概率矩阵的银行业客户行为预测. 西安工业大学学报, 31(06), 554–558. https://doi.org/10.16185/j.jxatu.edu.cn.2011.06.004 [2]Zhang, C., Li, Y.-F., & Coit, D. W. (2023). Deep Reinforcement Learning for Dynamic Opportunistic Maintenance of Multi-Component Systems With Load Sharing. IEEE Transactions on Reliability, 72(3), 863–877. Q1. https://doi.org/10.1109/TR.2022.3197322















 827
827











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









