







1、因子投资基础及介绍
因子投资包罗万象,可以用在获取收益,也可以用来控制风险;因子有人研究因子投资的资产配置,也有人研究因子的收益率的波动。
1.1 因子投资的概念基础
阅读材料一
在投资中,影响股票收益率的因素有很多,比如公司的经营状况,公司的财务状况,公司的市场环境,公司的政策环境等等。
如果能把这个影响因素具象化,那么这些因素就是因子。所以因子的范围很广,可以是指标或者特征, 如PE、PB、5日均线、动量、市值等等等。
而因子投资就是根据指标(特征),构建模型进行投资。当然构建模型的前提是需要分析各个因子与股票表现(收益率)之间的关系,从而建立的一套量化模型进行投资。
因子投资的核心理念在于通过识别和利用那些能够解释股票价格变动的因子,来寻找那些未来可能会表现出良好收益走势的股票(资产)。
相比于传统的投资方法,因子投资具有以下优势:
因子投资更加精确和个性化。它可以根据投资者的风险偏好和投资目标,定制适合自己的投资策略。
因子投资更加灵活和多样化。它可以通过调整因子来适应不同的市场情况,从而更好地应对市场变化。
因子投资更加主动和可控。它可以通过分析和预测因子来提前布局,掌握市场变化的主动权,从而更好地控制投资风险。
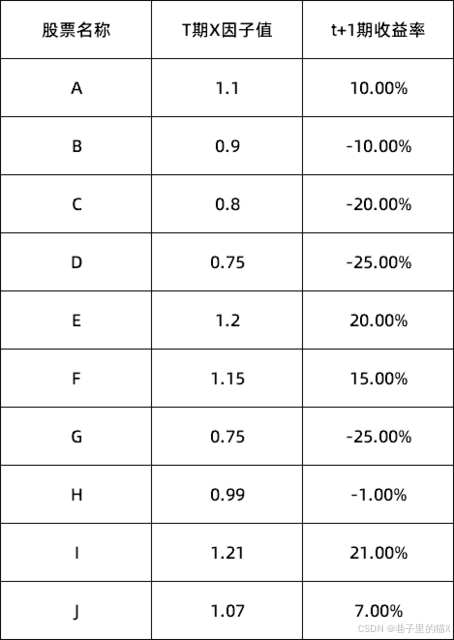
例如上表说明列举的X因子,直观的就可以看出来,X因子与T+1期收益率具有正向的相关关系,理论上来说X因子越大,T+1期收益率越大。
这是T期的因子数据,T+1期是这样的结果,T+2期呢?T+3期呢?直到T+n期结果都是这样,那我们是不是可以认为X因子对收益率影响巨大,我们是不是就可以据X因子进行量化投资!
上述就是因子投资的基本概念,找到影响股票收益率的因子,建立模型进行投资。作为投资人,我们梦寐以求的事情就是找到一个神奇因子,这个因子既能够给股票带来持续的正收益,也能使收益稳定并一直存在。
1.2因子投资的理论公式
阅读材料二
我们上一关了解了资本资产定价模型E(ri)=rf+βim(E(rm)-rf)
其中:
E(ri) 是资产i 的预期回报率
rf 是无风险利率
βim 是Beta系数,即资产i 的系统性风险
E(rm) 是市场m的预期市场回报率
E(rm)-rf 是市场风险溢价,即预期市场回报率与无风险回报率之差。
这个定价公式就是最简单的线性因子模型,其中βim就是因子的暴露程度,而E(rm)-rf就是因子收益率。
因此我们也可以简化一下,因子理论模型可以表达为E[Ri]=βiXi+αi
其中:
E[Ri] 是资产i 的预期超额收益率
βi是因子的暴露程度
Xi是因子预期收益
αi是定价误差 理论模型的存在告诉我们一个概念,不同资产的收益率由因子暴露和因子收益率两个维度影响,参考上面的例子来说,A股票为什么比B股票收益率高?根据理论模型可以认为是因子暴露比较大!*
1.3本节思考题
上述材料也引发一个新的问题,同样的因子理论上收益率是一样的,最终的收益率就由因子暴露决定,暴露高收益率就高,暴露低收益率就低,那我们如何验证这个观点,或者说这个因子的有效性呢?
2、使用python进行因子有效性分析
既然知道了因子投资的核心是因子暴露与因子收益率,那么接下来我们就需要做因子测试与分析了。
我们先以单因子为例。大致的流程如下:
获取数据->分组测试->结果分析->评价因子
2.1排序法构建因子投资组合
阅读材料三
这里有一个默认点,因子暴露与因子值之间具有数学关系,所以常规来说都是用因子值作为因子暴露来使用的,由此我们可以依据排序法构建因子投资组合,测试因子暴露值的高低是否对收益率有显著影响。
排序法说明:
1.N只股票按照因子值的大小从大到小或者从小到大排序。
2.按照排名高低分为N组(一般5到10),做多排名最高(或最低)的分组,分组内个股等权或者加权计算收益率。
3.定期更新,按周或者月滚动操作,在时序上重复此动作,就得出来各分组的时序收益率。
通过排序分组可以简单的构建因子投资组合,有了这些数据,我们就可以检验出因子预期收益率以及因子排序(暴露的大小)是否具有单调性,从而确定因子值的区分能力。
#导入相关库,为了避免重复,这里一次性导入本内容所需要的所有库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import akshare as ak
import warnings
import time
warnings.filterwarnings('ignore')
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 设置全局字体
#节约时间,导入相关数据,为全部A股2018-2022年数据。
#导入数据,并查看
df_a=pd.read_csv(r'/home/mw/input/0014684/QF1_3所需数据.csv',index_col=0)
df_a2.1.1数据整理
#数据准备好了,但是还没有处理,我们接下来需要做的是单因子的测试,这里就要引入一个alphalens的工具包,Alphalens是Quantopian公司旗下的开源利器之一。
#在使用它之前,我们需要对我们的数据进行处理。
#首先我们需要因子值的dataframe,并且我们需要双重索引,日期为一级,代码为2级。
df_a.index=pd.to_datetime(df_a.index)
df_a.sort_index(inplace=True)
#df_a.fillna(0,inplace=True)
#这里面是日线数据,一般基本面因子是以周/月为周期进行测试,所以我们还要调整一下,只保留每个月最后一天的数据。
stock_count=pd.DataFrame(columns=['code', 'date', 'turnover_rate', 'turnover_rate_f',
'volume_ratio', 'pe', 'pe_ttm', 'pb', 'ps', 'ps_ttm', 'dv_ratio',
'dv_ttm', 'total_share', 'float_share', 'free_share', 'total_mv',
'circ_mv', 'close.1', 'vol'])
for a,b in df_a.groupby('code'):
b.sort_index(inplace=True)
stock_count_1=b.resample('M').last()
stock_count=pd.concat([stock_count,stock_count_1])
stock_count.sort_index(inplace=True)
stock_count['date']=stock_count.index
stock_count#展示一下2.1.2计算需要的因子
#这里计算一下BM因子,BM因子是PB的倒数
stock_count['BM']=1/stock_count['pb']
factor=stock_count.loc[:,['code','BM']]#只需要代码列和因子列
factor= factor.dropna(subset=['BM'])
factor
2.1.3因子去极值标准化
#去极值,均值 3倍标准差,也可以是中位数
mean = np.mean(factor['BM'].values)
std = np.std(factor['BM'].values)
# 定义范围,例如均值加减3倍标准差
lower_bound = mean - 3 * std
upper_bound = mean + 3 * std
# 根据范围剔除极值
factor= factor[(factor['BM']>= lower_bound) & (factor['BM']<= upper_bound)]
factor
#这里采用标准差方法标准化
factor['BM_standardize']=(factor['BM']-factor['BM'].mean())/factor['BM'].std()
factor
#我们可以看到因子标准化后的值,有所变化,可视化看看分布情况
factor['BM_standardize'].hist(bins=20)
assets=factor.set_index([factor.index,factor['code']],drop=True)#设置双重index。
assets
#制作一个股价透视表,方便工具计算
close =stock_count.pivot_table(index='date', columns='code', values='close.1')#透视表
close.index = pd.to_datetime(close.index)#设置类型为datetime
close.sort_index(inplace=True)
close2.2因子分析工具的使用
数据准备好之后,我们直接导入分析包alphalens进行分析即可
2.2.1 Alphalens的安装与简单讲解
安装:pip install alphalens
阅读材料四
alphalens.utils.get_clean_factor_and_forward_returns(factor, prices,
groupby=None, binning_by_group=False,
quantiles=5, bins=None, periods=(1, 5, 10),
filter_zscore=20, groupby_labels=None,
max_loss=0.35)
参数说明:
factor:因子值,DataFrame,index为日期,columns为因子值
prices:价格数据,DataFrame,index为日期,columns为股票代码
groupby:分组,默认为None,即不分组,如果为字典/Series,则按照对应映射进行分组。
binning_by_group:用于设置是否按行业分别计算股票的分位数。
quantiles:就是分组测试中分组的数量,默认等分。
bins:对因子值进行等分,然后根据等分后的因子值区间对股票进行分组。
periods:是回测的调仓周期列表,我们可以设置想测试的调仓周期,且可以设置多个调仓周期。
filter_zscore:过滤掉收益率离群值,默认值为20。
groupby_labels:行业分类的映射。
max_loss:数据损失参数,数据超过则报错。主要还是alphalens处理计算的时候难免会丢失一些数据,若丢失超过设置的值则报错。
al.tears.create_returns_tear_sheet(factor_data, long_short=True, group_neutral=False, by_group=False)
参数说明:
factor_data : pd.DataFrame 之前计算的出来的ret对象
long_short : bool->是否计算多空组合。
group_neutral : bool->是否进行组别中性化,以消除行业的影响。
by_group : bool->是否分别显示各组别的结果。
2.2.2 因子分析工具的使用
from alphalens.utils import get_clean_factor_and_forward_returns#因子分析
ret = get_clean_factor_and_forward_returns(assets[['BM_standardize']],close,quantiles=10,periods=(1,))#因子分析,返回因子分组及指定周期收益率
ret#查看一下
import alphalens as al
#计算因子收益率并分析
al.tears.create_returns_tear_sheet(ret,long_short=True)每副图讲解
图一:各分组(分位)收益平均回报。
图二:各个分位组中股票的收益分布。
图三:将因子取值当作权重,交易整个市场中所有的股票所获得的累计收益。
图四:各个分组的累计回报。
图五:头减尾分组的回报时序分布
这里我们重点看第1幅图,各分组(分位)收益平均回报。能直观的看出来,分组收益随着因子分位数上升而上升,说明收益率与因子高低有正向的关系。
接下来使用IC分析辅助判断因子的有效性。
#可以计算一下相关系数,将分组收益率从低到高依次为1-10,因子值分组从低到高排序依次为1-10.
from scipy.stats import spearmanr
mean_return,std_ = al.performance.mean_return_by_quantile(ret, by_date=True)
mean_return=mean_return.groupby(level=0).mean()#获取分组的平均收益
std_=mean_return.groupby(level=0).std()
# 计算斯皮尔曼秩相关系数
rho, pval = spearmanr(np.arange(1,11), mean_return.rank(method='average').values)
print(f"Spearman's rho: {rho}, p-value: {pval}")
2.2.3因子IC分析
(information coefficient)分析是度量一个预测性值的好坏的手段。IC分析有点类似于度量两个随机变量的线性相关性,一头是T期因子值,另一头是T+1期收益率。IC值一般在/0.03/之上,就认为因子具有预测性。
#因子IC分析,在Alphalens中用于检测一个因子IC的函数:
al.tears.create_information_tear_sheet(ret)对于IC而言:
- IC 值序列的均值及绝对值均值:判断因子有效性;
- IC 值序列的标准差:判断因子稳定性;
- IC 值序列大于0.03的占比:判断因子效果的一致性。
投资者最希望的就是一个因子具有稳定的IC序列,均值高,方差小,t统计量大。
从上述结果来看,BM因子IC分析均值高,T值大,是具有一定预测效应的因子!因此可以纳入选股因子池。
2.2.4本节小结:
到这里我们如果进行单因子策略回测,剩下的是我们需要找到另外的有效因子,然后尝试选股回测!
值得一提的是,为了方便学习,这里把因子测试简化了,没有考虑行业因素和市值因素,大家知道这一点就好,不影响后期的学习。
等各位踏进量化的大门后,精进的时候在考虑以上两点!
2.2.5本节小练习
利用上述数据及方法,尝试自己对circ_mv(流动市值)因子进行分析,自己是否能独立完成呢?
3、使用python进行因子选股实践
3.1因子池构建
我们上面的文件中有N个因子值,那这里我们每个都测试一遍,然后根据'IC mean', 'IC std', 'IC>0.02比例','因子加权收益率'来给因子进行评分,我们选累计得分第一的进行选股
stock_count.drop('date',axis=1,inplace=True)
#stock_count=stock_count.dropna()
stock_count
#去极值,3倍标准差
def De_extremu(df):
factor_dict={}
for i in df.columns:
if i not in ['code']:
i_=pd.DataFrame(index=df.index,columns=['code',i],data=df[['code',i]].values)
i_=i_.dropna()
mean = np.mean(i_[i].values)
std = np.std(i_[i].values)
lower_bound = mean - 3 * std
upper_bound = mean + 3 * std
# 根据范围剔除极值
i_= i_[(i_[i]>= lower_bound) & (i_[i]<= upper_bound)]
#这里采用标准差方法标准化
i_[i]=((i_[i]-i_[i].mean())/i_[i].std()).astype(float)
factor_dict[i]=i_
return factor_dict
factor_dict=De_extremu(stock_count)
factor_dict#字典格式储存标准化后的因子,key是因子名称
#循环测试因子,并储存'IC mean', 'IC std', 'IC>0.03比例','因子加权收益率'等数据
#避免变量冲突,定义一个函数
def my_factor(factor_dict):
my_factor_dict={}
for i in factor_dict.keys():
assets=factor_dict[i].set_index([factor_dict[i].index,factor_dict[i]['code']],drop=True)#设置双重index。
ret_=get_clean_factor_and_forward_returns(assets[[i]],close,quantiles=10,periods=(1,),max_loss=1)#因子分析,返回因子分组及指定周期收益率
IC_data=al.performance.factor_information_coefficient(ret_)#因子IC序列
IC_mean=al.performance.factor_information_coefficient(ret_).values.mean()#因子IC均值
IC_std=al.performance.factor_information_coefficient(ret_).values.std()#因子IC标准差
IC_003=(IC_data[IC_data>0.03].count().values+ IC_data[IC_data<-0.03].count().values)/IC_data.count().values#因子IC大于特定值的比例
IC_IR=IC_mean/IC_std #代表IC的稳定性
factor_returns_=al.performance.factor_returns(ret_).values.mean()#因子加权平均回报
# 创建一个1行5列的DataFrame
test_result = pd.DataFrame([{'IC_mean': IC_mean, 'IC_std': IC_std, 'IC_003': IC_003, 'IC_IR': IC_IR, 'factor_returns_': factor_returns_}])
my_factor_dict[i]=test_result
return my_factor_dict
my_factor_dict=my_factor(factor_dict)
# 将所有DataFrame合并为一个
combined_df =pd.concat(my_factor_dict)
combined_df
# 到这里我们就已有的因子做了分析,在只考虑因子IC均值大,因子加权平均收益高的情况下,我们做以下因子打分。即:IC均值和factor_returns_、IC_003越高,分数越大。
factor_rank_num=combined_df.dropna().loc[:,['IC_mean','factor_returns_','IC_003']].rank()#返回排名
factor_rank_num['因子测试打分']=factor_rank_num.sum(axis=1)#求和
factor_rank_num.sort_values('因子测试打分')就已有数据的分析结果来看,pe、BM、dv_ttm三个因子组合分数最高,理论上这三个因子是具有较强投资能力的。我们可以根据这三个因子进行选股构建组合进行回测,若结果喜人,则可以进一步落地到实践中!
3.2因子选股
#我们就以现有数据中的dv_ttm因子为例进行选股
#注意,这里用的是历史数据,不是实时数据。
df_a.loc['2022-12-30'].sort_values(by='dv_ttm',ascending=False).head(10)3.3本节小结:
本节我们构建了因子池,并且利用指标对因子进行了评分,从而判断因子的投资能力。当然这只是其中一部分,在实践中还有很多方法受制于篇幅没法展开一一细讲,这就需要我们自己主动探索和学习了!
3.4本节动手题
上述我们是以历史数据进行的选股操作,你是否能够利用数据库获取最新的选股结果呢?

















 1009
1009

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









