







1、回测的重要性
阅读材料一
量化回测是一种基于历史数据对交易策略进行回测和评估的方法。它可以帮助投资者了解其交易策略在真实市场环境下的表现,以及策略的盈利能力、风险水平等关键指标。
这里面就需要我们使用回测库,如Zipline、Backtrader等,来对交易策略进行回测。
量化回测库的主要功能包括数据采集、策略回测、绩效评估等。它通过获取历史市场数据,根据投资者的交易策略进行模拟交易,并计算收益率、最大回撤等关键指标,帮助投资者评估其策略的有效性。
此外,量化回测库还可以提供可视化图表,如收益曲线图、累计收益图等,使投资者更直观地了解其策略的表现情况。
例如下图就是通过量化回测库获取的回测结果
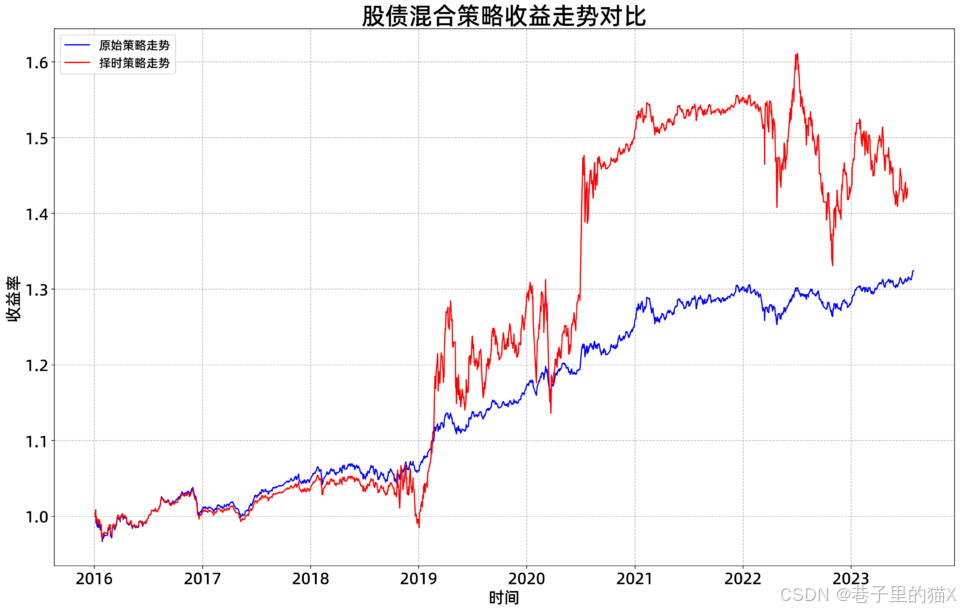
1.1回测框架的构成
无论是哪种回测框架(本地/在线),都脱离不了数据源、策略模型、分析器这三个核心要素(模块)。
1.既然量化回测是基于历史数据进行的,那无论是什么品种/策略,获取相关数据都是第一步的。
2.其次就是策略模型,策略模型可以是我们之前案例学习的移动平均,也可以是你自己独门的技术,但一定要有可量化的准则,从而明确的买卖信号后才能有回测结果。
3.最后就是分析器,分析器的作用就是对回测结果进行评估,比如计算收益率、最大回撤等。
当然还有其它模块,例如可视化图表、交易设置等等,这些模块就属于辅助模块,我们也需要了解。
1.2数据源及准备
数据源:
1.tushare,注册后可以获得基本的行情数据,更多数据就需要付费捐赠。或者akshare接口。
2.行情软件下载,目前有部分行情软件支持数据下载到本地,同花顺、通达信、东财等。
3.各大量化平台的数据接口,部分需要付费才能下载到本地,这个看个人需求。
1.3策略模型
量化策略模型的来源多种多样,主要来源于经典理论、逻辑推理、经验总结、数据挖掘、机器学习等方面。
在经典理论方面,许多量化理论都来源于传统的经典投资理论,如技术分析理论基础、道氏理论、趋势理论、形态理论、波浪理论、时间周期理论等。
量化投资策略的来源除了理论之外,还有经验总结。经验总结包括一些历史经典案例,如股权激励后股票表现、定增后破发套利等等。
总之根据这些理论把它们进行一定的转换——>口诀或者理论转为定量研究,然后根据指标或者规则构建量化模型,最后回测。
1.4分析器
分析器其实就是对回测结果进行评估,比如计算收益率、最大回撤等。
例如我们之前的案例中,写了几个函数,评估最大回测以及夏普率的指标。
#计算收益率年华波动率
def calculate_volatility(return_series):
# 计算收益率的标准差
volatility = np.std(return_series)
# 调整为年化波动率
_volatility = volatility * np.sqrt(252) # 假设每年有252个交易日
return _volatility
#计算夏普比例
def calculate_sharpe(annualized_return, annualized_volatility, risk_free_rate):
sharpe_ratio = (annualized_return - risk_free_rate) / annualized_volatility
return sharpe_ratio
#导入相关库,为了避免重复,这里一次性导入本内容所需要的所有库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import akshare as ak
import warnings
import backtrader as bt
import datetime
warnings.filterwarnings('ignore')
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 设置全局字体2、回测代码的构建流程及方法详解
2.1解析回测的过程
为了方便大家更深刻的了解回测的流程,我们先不引入工具包,用手动回测的方式带大家了解回测全流程,主要分为以下几个步骤:
1.数据获取:获取历史数据,并将其转换为回测框架可用的数据格式。
2.交易信号处理:根据策略模型,生成交易信号。
3.回测计算:根据交易信号和历史数据,执行交易并计算回测结果。
4.回测结果分析:对回测结果进行评估,如计算收益率、最大回撤等。
# akshare获取贵州茅台股票数据
stock_600519 = ak.stock_zh_a_hist(
symbol="600519",
period="daily",
start_date="20200101",
end_date='20231229',
adjust="hfq")
stock_600519
# 需要设置index,并且设置成time格式
stock_600519.set_index(pd.to_datetime(stock_600519['日期']), inplace=True)2.2交易信号处理
根据策略模型,生成交易信号。下面以双均线策略为例进行——短期均线上穿长期均线时买入,短期均线下穿长期均线时卖出。
# 第一步:计算我们需要的ma均线数据
# ma均线计算方式为N的算数平均值,这里我们假设策略参数是5日与20均线
stock_600519['ma5'] = stock_600519['收盘'].rolling(5).mean()
stock_600519['ma20'] = stock_600519['收盘'].rolling(20).mean()
# 第二步:计算交易信号。
# 短期均线大于长期均线,我们标记为1,反之标记为0
stock_600519.loc[(stock_600519['ma5'] > stock_600519['ma20']), 'signal'] = 1
stock_600519.loc[(stock_600519['ma5'] < stock_600519['ma20']), 'signal'] = 0
#第三步:标记具体买卖日期
#交易信号是5日短期均线从下上穿20日均线,买入。从上往下穿入,卖出。利用diff计算signal变化计算交易信号
#当signal从0变成1的时候,因为这短期均线大于长期均线,此时因为diff的原因,order值是1,买入。反之是-1卖出
stock_600519['order']=stock_600519['signal'].diff()
#可视化查看交易信号
plt.figure(figsize=(20,12))
#绘制股价图
plt.plot(stock_600519['收盘'],color='b',label='收盘价')
plt.plot(stock_600519['ma5'],ls='--',color='gray',label='ma5')
plt.plot(stock_600519['ma20'],ls='--',color='k',label='ma20')
plt.scatter(stock_600519.loc[stock_600519['order']==1].index,stock_600519['收盘'][stock_600519.order==1],marker='^',s=100,color='m',label='买入')
plt.scatter(stock_600519.loc[stock_600519['order']==-1].index,stock_600519['收盘'][stock_600519.order==-1],marker='v',s=100,color='g',label='卖出')
plt.yticks(fontsize=20)
plt.xticks(fontsize=20)
plt.legend(fontsize=20)
plt.grid()
plt.show()2.3累计收益计算及可视化
stock_back = pd.DataFrame(index=stock_600519.index)#创建一个空的dataframe
stock_back['signal'] = stock_600519['signal'].shift(1) #迁移交易信号,这里为什么要降一位?避免未来函数
#这里特别说明一下,为什么每日收益序列是(stock_600519['收盘']/stock_600519['收盘'].shift(1)-1)*stock_back['signal']
#(stock_600519['收盘']/stock_600519['收盘'].shift(1)-1)得到的是隔日收益率,即今天相对昨天的涨幅
(stock_600519['收盘']/stock_600519['收盘'].shift(1)-1)
#stock_back['signal']则是持仓或者空仓的状态,1为持仓,0为不持仓,所以相乘计算持仓的收益即可。
stock_back['signal']
stock_back['每日收益率序列'] = (stock_600519['收盘']/stock_600519['收盘'].shift(1)-1)*stock_back['signal']
stock_back['累计收益率'] = (stock_back['每日收益率序列']+1).cumprod()
stock_back['order']=stock_back['signal'].diff()
stock_back
#查看收益率序列
#可视化查看累计收益率
fig ,axex= plt.subplots(2,1,figsize=(20,12),dpi=100) # 创建图
ax1,ax2=axex.flatten() # 创建子图
#绘制股价图
ax1.plot(stock_back['累计收益率'],color='b',label='累计收益率')
ax1.scatter(stock_600519.loc[stock_600519['order']==1].index,stock_back['累计收益率'][stock_back.order==1],marker='^',s=100,color='m',label='买入')
ax1.scatter(stock_600519.loc[stock_600519['order']==-1].index,stock_back['累计收益率'][stock_back.order==-1],marker='v',s=100,color='g',label='卖出')
ax1.grid()
ax1.legend(fontsize=20)
ax2.plot(stock_back['signal'],color='r',label='持仓状态')
ax2.legend(fontsize=20)2.4计算年化收益率以及可视化基准收益对比
#计算年化收益率
def calculate_year_return(final_value, initial_value, years):
_return = (final_value / initial_value) ** (1 / years) - 1
return _return
# 上述回测期约为7.5年,初始资产净值为1,最终净值为5.4435
years =4
initial_value = 1
final_value = 1.8138
annualized_return = calculate_year_return(final_value, initial_value, years)
print("策略年化收益为: {:.2%}".format(annualized_return))
#与基准收益做对比
#这里用的是个股,所以基准就是个股自己的收益,如果是选股策略或者其他策略,则用沪深300做基准收益率。
#可视化查看累计收益率
fig ,ax1= plt.subplots(figsize=(20,12),dpi=50) # 创建图
#绘制股价图
ax1.plot(stock_back['累计收益率'],color='b',label='策略累计收益率')
ax1.plot((stock_600519['收盘']/stock_600519['收盘'].shift(1)).cumprod(),color='r',label='基准走势')
ax1.grid()
ax1.legend(fontsize=20)
2.5计算收益率年华波动率/夏普比例
#计算收益率年华波动率
def calculate_volatility(return_series):
# 计算收益率的标准差
volatility = np.std(return_series)
# 调整为年化波动率
_volatility = volatility * np.sqrt(252) # 假设每年有252个交易日
return _volatility
#计算夏普比例
def calculate_sharpe(annualized_return, annualized_volatility, risk_free_rate):
sharpe_ratio = (annualized_return - risk_free_rate) / annualized_volatility
return sharpe_ratio
# 投资组合的年化收益率为16.05%,年化波动率为X,无风险利率为5%
annualized_return = 0.1605
annualized_volatility = calculate_volatility(stock_back['每日收益率序列'].fillna(0).values)
risk_free_rate = 0.05
sharpe_ratio = calculate_sharpe(annualized_return, annualized_volatility, risk_free_rate)
print("Sharpe Ratio: {:.2f}".format(sharpe_ratio),"年化波动率为: {:.2f}".format(annualized_volatility))2.6计算最大回测
#计算最大回撤
def calculate_max_drawdown(prices):
max_drawdown = 0
peak = prices[0]
for price in prices:
if price > peak:
peak = price
drawdown = (peak - price) / peak
if drawdown > max_drawdown:
max_drawdown = drawdown
return max_drawdown
# 计算最大回撤
max_drawdown = calculate_max_drawdown(stock_back['累计收益率'].fillna(0).values)
print("Max Drawdown: {:.2%}".format(max_drawdown))2.7本节小结:
本节我们学习了量化回测中的交易信号处理,并手动进行了策略回测,分析了投资策略的夏普比例、年化波动率、最大回撤等。主要是让各位理解回测的原理,其实也是很基础的逻辑,用代码落实而已。接下来我们将学习量化回测框架,提高我们的研究效率。
2.8本节练习
本节我们学习了如何使用pandas库来处理交易信号,并计算收益率、波动率、夏普比率、最大回撤等指标。那么你能否利用上述代码,构建一个20/60日均线策略呢?
提示:其它要求不变,主要是参数的改变,复制代码自己尝试下吧!
3、学习回测框架
我们今天要自己手撸一个完整的回测框架么?没必要,用python的原因不就是因为成熟的轮子很多么,现在有很多基于python的量化投资回测工具包,我们直接拿来用就可以了。使用回测框架的好处就是一切开箱可用,省去了我们自己写相关代码的麻烦,让我们把精力更多留在策略研究上面,而不是回测上面接下来我们将以backtrader回测框架为例,学习它并使用它
3.1了解回测中枢
backtrader回测框架有大脑、数据传输、订单、经纪商等模块,其中回测中必不可少,或者说需要了解的模块有大脑、数据传输、经济商、指标几个模块。
我们先按照官网上的案例,看看一个回测的流程,我给每行代码做了注释,我们逐一讲解!
#cerebro是回测的大脑,所有的数据和计算都在这里交汇,所以一个策略的第二步就是引入大脑
#来,现在让你成为亿万富翁,通过cerebro.broker设置。
#我们只需要引入cerebro.broker就行了。
#cerebro.broker.setcash(100000000.0) 设置初始资金10000万
if __name__ == '__main__':
cerebro = bt.Cerebro()#引入大脑,并实例化!在这个例子中:Backtrader被导入Cerebro
#核心其实就是这个Cerebro,有了这个实例,我们后面所有的操作基本都基于这个实例。后面运行后,结果被打印出来。
#我们也可以通过Cerebro这个实例,进行一些设置,上述案例其实是一个默认值。
cerebro.broker.setcash(100000000.0)#常规来说,单只品种设置100万足够了,多只品种设置1000万到1亿。今天我们也富裕一把,就100000000吧。
print('Starting Portfolio Value: %.2f' % cerebro.broker.getvalue())#调用大脑中的broker(经纪商)模块,看看自己有多少钱?
cerebro.run()#运行回测
print('Final Portfolio Value: %.2f' % cerebro.broker.getvalue())#运行过后有多少钱?3.2数据整理与导入
这里以股票为例 ,最基础的数据需要7条line,为 ('close', 'high', 'low', 'open', 'volume', 'openinterest', 'datetime')例如我有下面这种数据,那第一件事就是要把数据整理成上述标准。
stock_600519.loc[:,['收盘','最低','最高','开盘','成交量','日期']].reset_index(drop=True)
stock_600519_test=stock_600519.loc[:,['收盘','最低','最高','开盘','成交量','日期']].reset_index(drop=True)
#调整数据clumns,且按照时间升序
stock_600519_test['openinterest']=0#添加一列数据
data=stock_600519_test.loc[:,['开盘','最高','最低','收盘','成交量','openinterest','日期']]#选择需要的数据
data.columns=['open','high','low','close','volume','openinterest','datetime']#修改列名
data=data.set_index(pd.to_datetime(data['datetime'].astype('str'))).sort_index()#把datetime列改为时间格式并排序
data
#这个数据是整理过的,实际操作中可能会有一下缺失数据,所以需要做一下填充。
data.loc[:,['volume','openinterest']] = data.loc[:,['volume','openinterest']].fillna(0)
data.loc[:,['open','high','low','close']] = data.loc[:,['open','high','low','close']].fillna(method='pad')
#到这里我们需要的回测数据已经整理完毕,下面就到把这个数据导入到回测框架中进行回测了!
#现在把之前整理好的数据导入进去,我们需要用到datafeeds数据传输模块,分为两步1读取,2添加给大脑。
if __name__ == '__main__':
cerebro = bt.Cerebro()#引入大脑,并实例化
datafeed = bt.feeds.PandasData(dataname=data,#导入前面整理好的pddata数据
fromdate=datetime.datetime(2020,1,1),#起始时间
todate=datetime.datetime(2023,12,29)) #结束时间
cerebro.adddata(datafeed, name='000300.SH') # 通过cerebro.adddata添加给大脑,并通过 name赋值 实现数据集与股票的一一对应
print('读取成功')
cerebro.broker.setcash(1000000.0)#设置起始资金
print('Starting Portfolio Value: %.2f' % cerebro.broker.getvalue())#调用大脑中的broker(经纪商)模块,看看自己有多少钱?
cerebro.run()#运行
print('Final Portfolio Value: %.2f' % cerebro.broker.getvalue())#运行过后有多少钱?3.3主回测函数
3.3.1:init函数
init函数只执行一次,主要是调用数据的方法。
我们先要了解一下backtrader里面数据的调用格式。之前说过我们的数据总共有7条,为 ('close', 'low', 'high', 'open', 'volume', 'openinterest', 'datetime')
调用时是直接调用一整条数据的,好比pandas里面的series,格式为self.data.XXX(xxx为线的名字),例如调用close数据,self.data.close。
#在init函数中调用self.data.close的效果差不多是这样:
data['close']
#那我们在init中,根据收盘价计算boll指标。
class bollqt(bt.Strategy):#bollqt为此策略的名称,为自定义。
def __init__(self):#全局只调用一次,一般在此函数中计算指标数据。
self.B=bt.ind.BBands(self.data0.close,period=20)#这是backtrader中自带的指标计算函数,也可以用talib计算。
#方式为self.xx=bt.talib.指标代号(‘计算的基础数据,如收盘价’,timeperiod=‘计算参数’)
3.3.2:next函数
next函数按照导入数据的时间周期从头运行到尾。
因为循环的原因,在next中调用数据多了一个因素,就是时间阶段,例如self.data.close调用数据,系统根本不知道你说的哪一天,所以这里需要加上一个数字0——指向当前时间。-1指向前一天,1指向后一天。例如我要调用当天的收盘价,实例就是self.data.close[0],我们来试试看。
class bollqt(bt.Strategy):#bollqt为此策略的名称,为自定义。
def __init__(self):#全局只调用一次,一般在此函数中计算指标数据。
self.B=bt.ind.BBands(self.data0.close,period=20)#这是backtrader中自带的指标计算函数,也可以用talib计算。
#方式为self.xx=bt.talib.指标代号(‘计算的基础数据,如收盘价’,timeperiod=‘计算参数’)
def next(self):
#看看当天的收盘价是多少
print(self.datetime.date(),self.data.close[0])
#看看当天的boll线下轨价是多少
print(self.datetime.date(),'boll线下轨价格为',self.B.bot[0])
cerebro.broker.setcash(1000000.0)#设置起始资金
cerebro.addstrategy(bollqt)#把策略添加给大脑
cerebro.run()#运行3.4必要设置
必要的设置还有手续费,滑点等。
佣金,双边各 0.0003
cerebro.broker.setcommission(commission=0.0003)
滑点:双边各 0.0001
cerebro.broker.set_slippage_perc(perc=0.0001)
3.5买卖条件的写法
买卖条件写在next函数中,举个例子。
例如我们在股价跌到boll线下轨的时候买入,该怎么写?
if self.B.bot[0]>self.data.close[0]
然后买入,该怎么写?调用order模块,买入 buy() 、卖出 sell()、平仓 close() ,它们的调用方式非常简单,大家也经常在案例中看到,交易函数会返回订单 Order 实例,通常会赋值给对象self.order :
self.order = self.buy(self.data,100)买入self.data数据集对象100股
3.6分析器
第一步:通过 addanalyzer(ancls, _name, args, *kwargs) 方法将分析器添加给大脑,ancls 对应内置的分析器类,后面是分析器各自支持的参数,添加的分析器类 ancls 在 cerebro running 区间会被实例化,并分配给 cerebro 中的每个策略,然后分析每个策略的表现,而不是所有策略整体的表现 ;
第二步:分别基于results = cerebro.run() 返回的各个对象 results[x] ,提取该对象 analyzers 属性下的各个分析器的计算结果,并通过 get_analysis() 来获取具体值。
# 添加分析指标
'''# 返回年初至年末的年度收益率
cerebro.addanalyzer(bt.analyzers.AnnualReturn, _name='_AnnualReturn')
# 计算最大回撤相关指标
cerebro.addanalyzer(bt.analyzers.DrawDown, _name='_DrawDown')
# 计算年化夏普比率:
cerebro.addanalyzer(bt.analyzers.SharpeRatio_A, _name='_SharpeRatio_A')
# 启动回测
result = cerebro.run()
# 提取结果
print("--------------- AnnualReturn -----------------")
print(result[0].analyzers._AnnualReturn.get_analysis())
print("--------------- DrawDown -----------------")
print(result[0].analyzers._DrawDown.get_analysis())
print("--------------- SharpeRatio_A -----------------")
print(result[0].analyzers._SharpeRatio_A.get_analysis())'''3.7基于历史数据的策略回测实例展示
#把之前的讲解的模块代码复制进来,注意这里重启后单独运行,避免报错!
#数据样本
cerebro = bt.Cerebro()#引入大脑,并实例化
datafeed = bt.feeds.PandasData(dataname=data,#导入前面整理好的pddata数据
fromdate=datetime.datetime(2020,1,1),#起始时间
todate=datetime.datetime(2023,12,29)) #结束时间
cerebro.adddata(datafeed, name='600519.SH') # 通过cerebro.adddata添加给大脑,并通过 name赋值 实现数据集与股票的一一对应
print('读取成功')
cerebro.broker.setcash(1000000.0)#设置起始资金
class bollqt(bt.Strategy):#bollqt为此策略的名称,为自定义。
def __init__(self):#全局只调用一次,一般在此函数中计算指标数据。
self.B=bt.ind.BBands(self.data0.close,period=20)#这是backtrader中自带的指标计算函数,也可以用talib计算。
#方式为self.xx=bt.talib.指标代号(‘计算的基础数据,如收盘价’,timeperiod=‘计算参数’)
def next(self):
#计算买卖条件
if self.getposition(self.data).size==0:#通过此函数查询持仓,若持仓等于0
if self.B.bot[0]>self.data.close[0] and self.B.bot[-1]<self.data.close[-1]:#当前一日接近下轨,当日跌破下轨时买入
self.order = self.buy(self.data,100)#买入100股
print('买入成功')
else:
pass
#print('不符合入场条件')
elif self.getposition(self.data).size >0: #持仓大于0时
if self.B.top[0]<self.data.close[0] and self.B.top[-1]>self.data.close[-1]:#前一期小于上轨,当日突破上轨卖出
self.order = self.close(self.data,100)#平仓100股
print('卖出成功')
else:
pass
#print('不符合卖出条件')
cerebro.broker.setcash(1000000.0)#设置起始资金
cerebro.addstrategy(bollqt)#把策略添加给大脑
# 添加分析指标
# 返回年初至年末的年度收益率
cerebro.addanalyzer(bt.analyzers.AnnualReturn, _name='_AnnualReturn')
# 计算最大回撤相关指标
cerebro.addanalyzer(bt.analyzers.DrawDown, _name='_DrawDown')
# 计算年化夏普比率:
cerebro.addanalyzer(bt.analyzers.SharpeRatio_A, _name='_SharpeRatio_A')
# 返回收益率时
cerebro.addanalyzer(bt.analyzers.TimeReturn,_name='_TimeReturn')
result=cerebro.run()#运行
#查看夏普
result[0].analyzers._SharpeRatio_A.get_analysis()
#查看最大回撤
result[0].analyzers._DrawDown.get_analysis()
#查看收益率时序
#走势对比
ret = pd.Series(result[0].analyzers._TimeReturn.get_analysis())#获得收益时序图
#画图
fig, axes = plt.subplots(2, 1, figsize=(20,12),dpi=100)
ax1, ax2 = axes.flatten()
ax1.plot(ret.index,(ret+1).cumprod().values,'r-',label = "策略走势") # 绘制第一个子图
ax2.plot(ret.index,ret.values,'b-',label = "策略时序走势") # 绘制第二个子图
#自带的工具可视化展示
cerebro.plot()更多内容,请参考backtrader官方说明文档
[https://www.backtrader.com/docu/observers-and-statistics/observers-and-statistics/#google_vignette]
3.8本节小结:
本节我们学习了backtrader这个回测框架,并且用这个框架写了一个策略——利用布林带判断买入和卖出。最终累计收益为7.66%,夏普比例为0.13,最大回撤为34%。严格来说这个策略并不好。中间也有很多可以优化的地方。当然对于一个初学者来说,这个策略已经发挥了它应有的作用——成为一个代码模版/教学案例,带你入门!
3.9本节练习:
你能否把第二节的均线策略用backtrader框架实现一遍呢?你可能遇到的问题:
1.init函数里面的计算,这里面可以参考backtrader的文档或者talib库的文档。
2.next函数里面的买卖条件设置,这里面其实就是利用False或True条件引入buy或sell函数进行买卖。
3.自己动手尝试一下吧,错了没关系可以逐行看代码注释,理解代码原理。如果都不敢尝试错误,那怎么赢得正确?你说对吗,未来的投资大佬!

















 935
935

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









