







基于李沐机器学习视频做的笔记3.1 8分钟机器学习介绍【斯坦福21秋季:实用机器学习中文版】_哔哩哔哩_bilibili
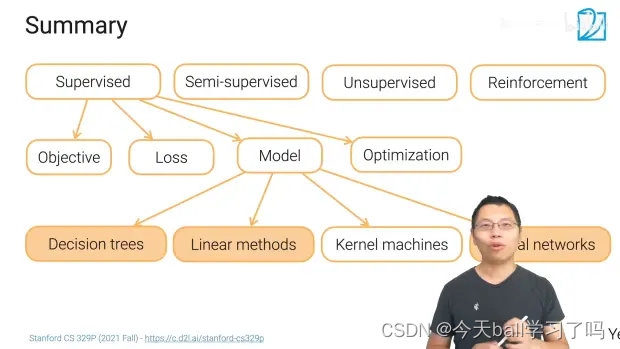
机器学习算法分类
1、监督学习:在有标号的数据上训练一个模型,任务就是去预测这个标号【自监督学习,产生标号,标号来源于数据的本身(字嵌入、BERT)】;
2、半监督学习:有一些标好的数据,还有大部分没有标好的数据,在这里有两个任务:【像监督学习一样学习一个模型去预测标号,但尽量使用未标注的信息;将没有标注的数据的标号给预测出来(自训练)】;
3、无监督学习:整个数据是没有标号的,任务也不是去预测一个标号(聚类算法、估计分布(GAN));
4、强化学习:模型跟环境进行交互,从环境中获取观测点之后进行学习,再做一些行为重新获取反馈(更像是人类的学习方式);
讨论比较多的还是监督学习和无监督学习。
监督学习的组成部分
1、模型(Model):通过输入预测输出;
eg. listing house→sale price
2、损失函数(Loss):用于衡量模型预测出来的值与真实之间的差距;
eg. predict_price-sale_price
3、目标(Objective):在训练训练时,优化函数:
eg. minimize the sum of losses over examples
4、优化(Optimization):在模型中没有指定的参数(刻意学习的参数),在实际数据中填上值,使得能最小化损失。
监督学习的分类
1、决策树(Decision Trees):用树来做决定;
2、线性模型(Liner methds):做决策时做决策的东西是根据输入的线性组合;
3、核方法(Kernel machines):用核函数来衡量两个样本间特征的相似度;
4、神经网络(Neural network):用多层的神经网络来学习一个特征表示,使得能在之后接的一个线性方法里会有一个很好的表示。
总结














 2923
2923











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









