






跟着StatQuest和3b1b学下transformer。
工作总览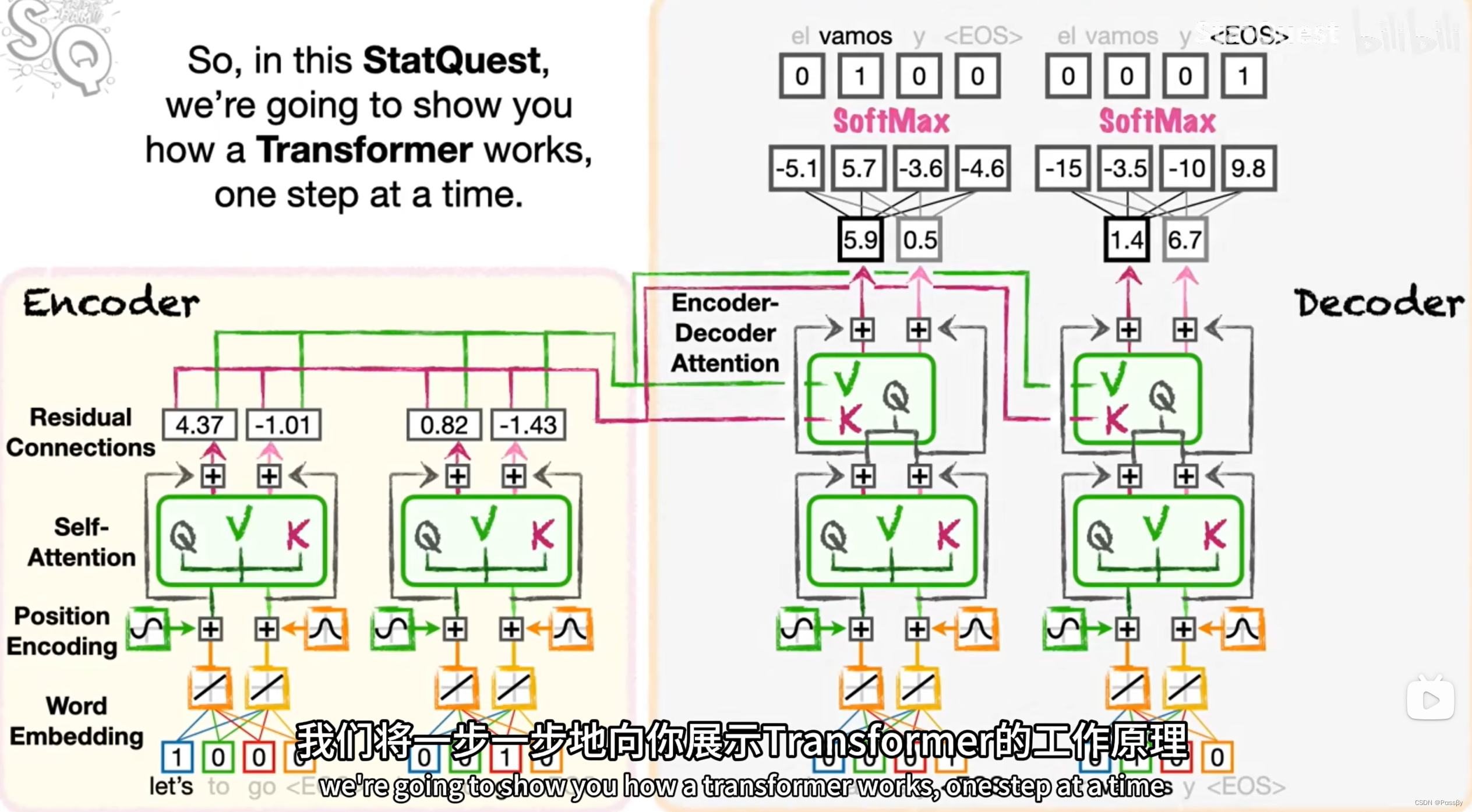
现在我们考虑到这样一个任务:将英语Let’s go!转换为西班牙语iVamos!

Encoder
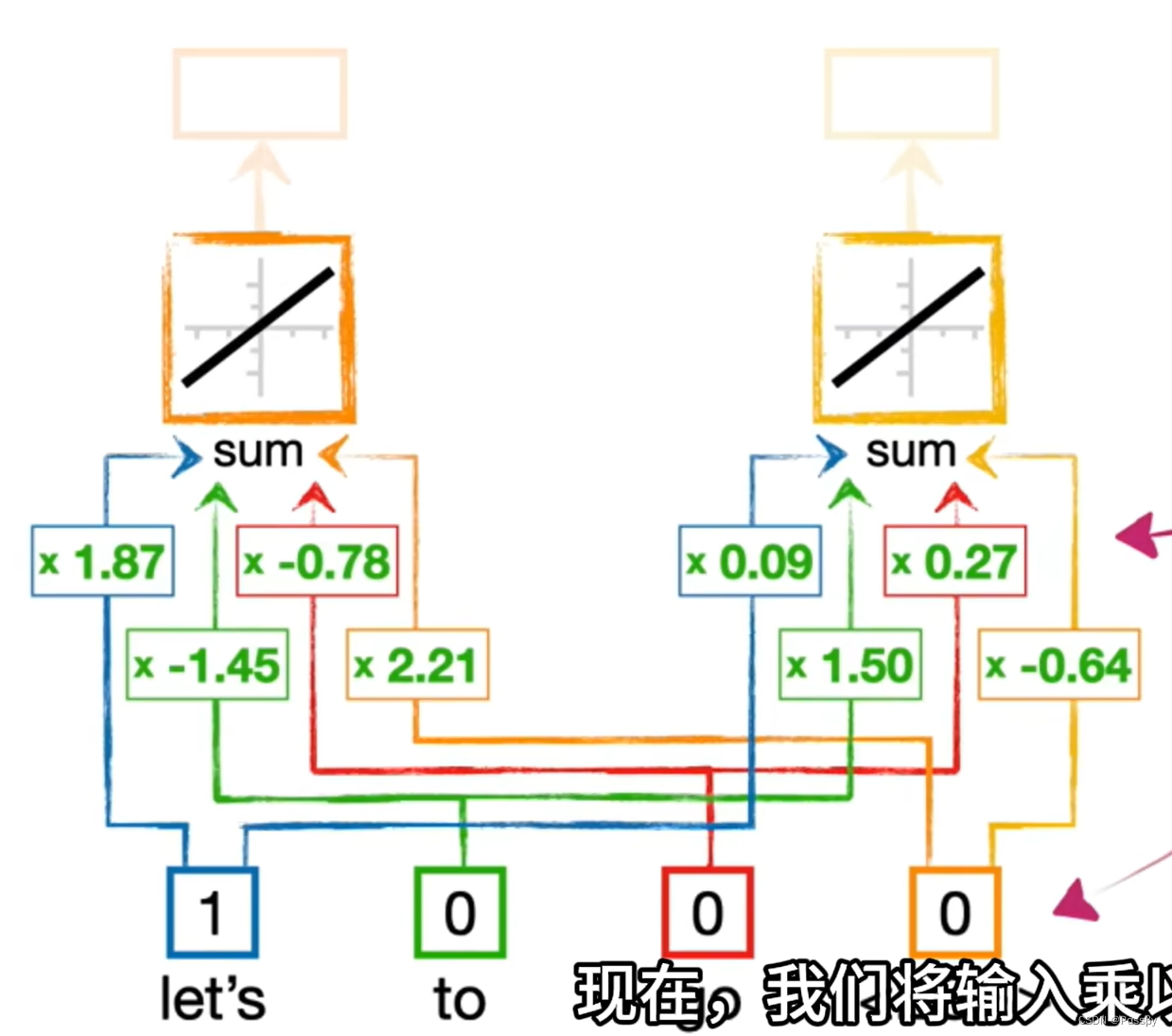
1.Word embedding
主要思想:通过使用一个相对简单的神经网络,为词汇表中的每个单词或者符号提供一个输入(结尾符号可以用<EOS>表示),并且我们将每个这样的词称为Token,
通过一个学习过的全连接层,最后再连接到一个激活函数。
全连接层
全连接层由一组神经元组成,每个神经元都与前一层的所有神经元相连。这种连接方式使得每个神经元的输出都是前一层所有神经元输出的加权和。在解码器中,所有字符采用相同的全连接层计算,并得到多个输出给激活层。而权重通过反向传播计算求解。
独热编码
独热编码是一种将分类数据转换为数值形式的方法,其中每个类别通过一个二进制向量表示,向量的长度等于类别的总数。对于一个特定的类别,其对应的独热编码向量在该类别的索引位置上为1,其他位置上为0。
对于我们使用的符号表而言,所有单词、字符都对应一个独热编码。
激活函数
激活函数是一个数学函数,用于确定一个人工神经元是否应该被激活。它将神经元的输入(通常是前一层神经元的输出加权和)转换为输出。激活函数的主要作用是为线性模型添加非线性,使得神经网络能够解决线性不可分问题。
2.Position Encoding
主要思想:记录一句话中词语的顺序问题。例如我想吃披萨和披萨想吃我的含义完全不同。对此一种常见的做法是通过多个 正余弦函数分别在y=sin(n)的位置采样(n为当前这个词所在句子的位置),对于每个激活函数的输出,按序提供一个不同的正余弦函数并计算结果并相加,就能够得到位置编码的信息并嵌入到词向量。

3.Self Attention
主要思想:通过检测每个单词和句子当时所有词(包括他自己)的相似度。
注意力机制要实现的目标:理解这个token在当前语境中的含义
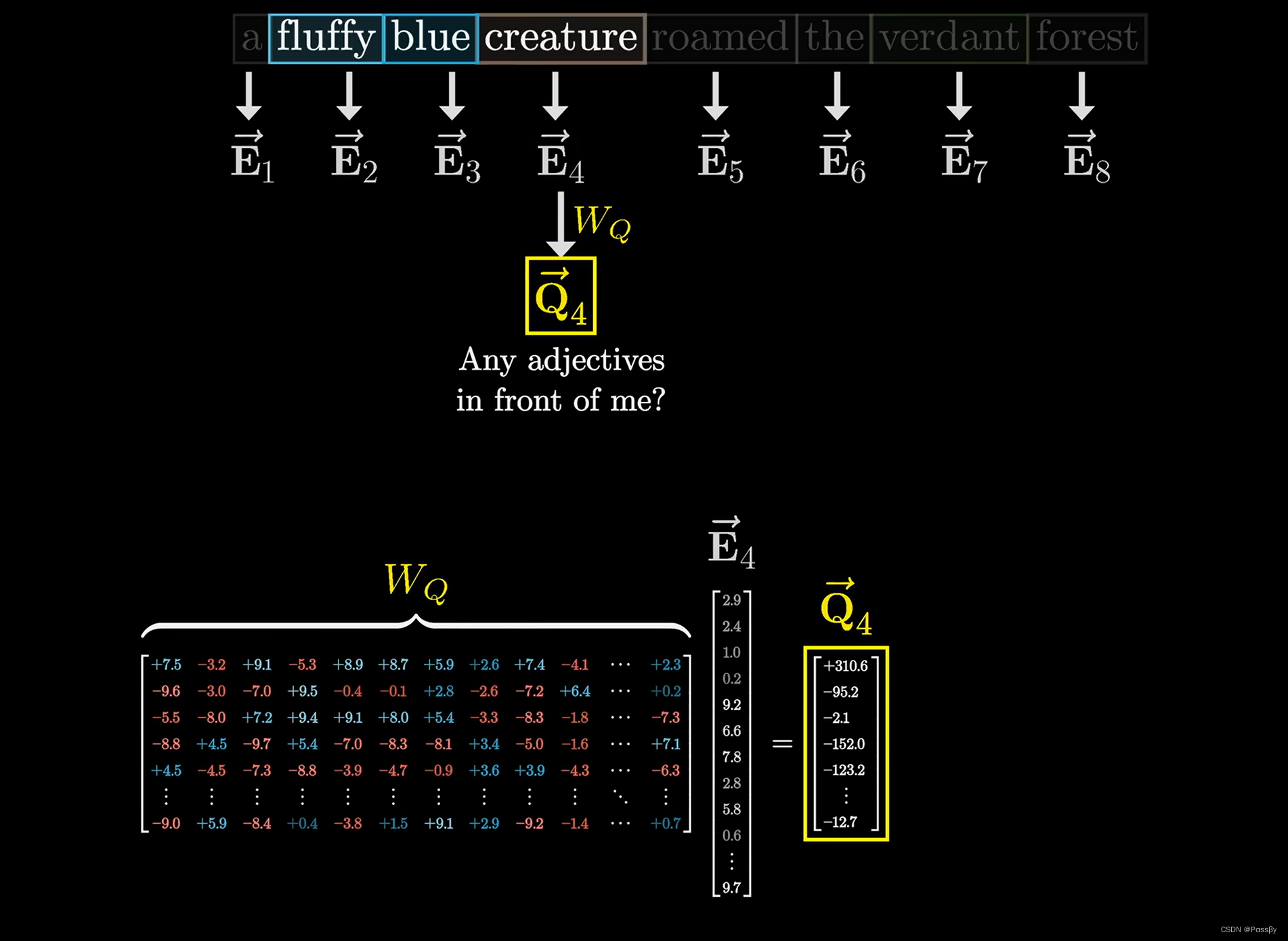
Query&Key
我们抽象的来理解Query和Key:现在我们有一个词 creature,通过词嵌入表示为
E
4
⃗
\vec{E_4}
E4,通过查询
W
Q
W_Q
WQ矩阵(也就是
W
Q
⋅
E
4
⃗
W_Q \cdot \vec{E_4}
WQ⋅E4),我们可以抽象的理解为:creature在查询:我想找一个形容词形容,我接下来需要跟着一个动词;同理通过
W
K
W_K
WK矩阵,相当于creature在发布自己的密钥:我是名词。
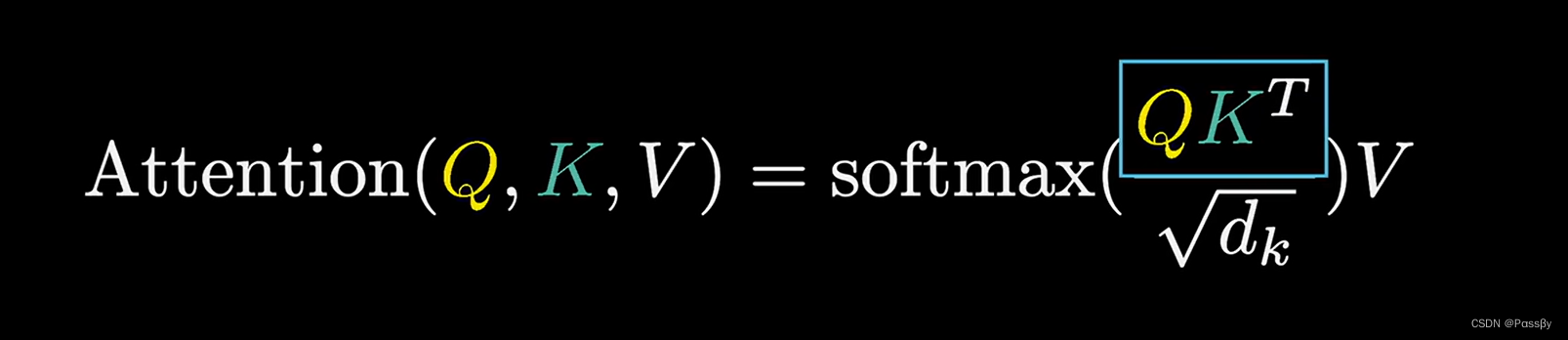
在Transformer原文中,分母还有
d
k
\sqrt{d_k}
dk项,表示查询空间维度的平方根,用于数值的稳定性。
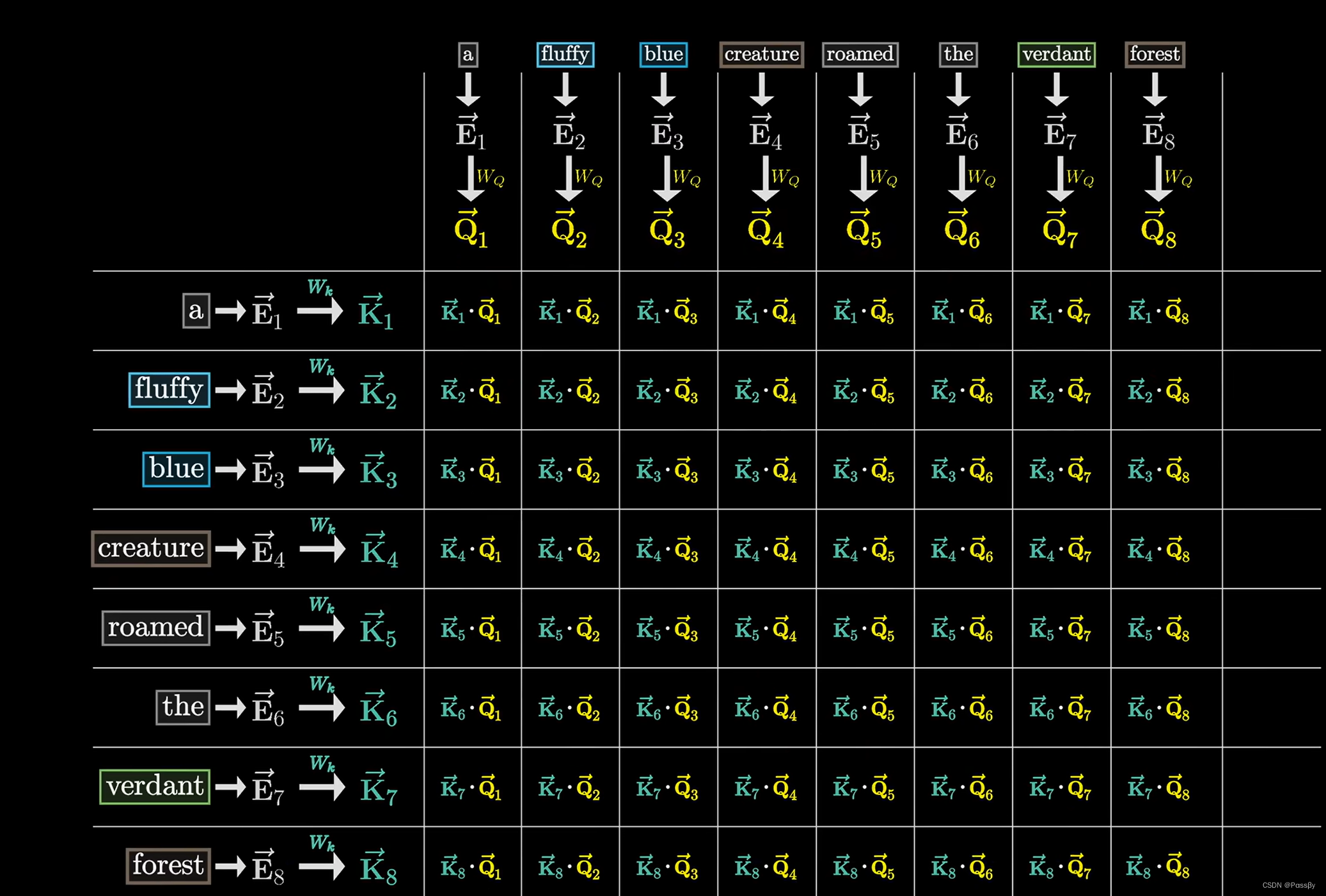
将
K
⃗
⋅
Q
⃗
\vec{K} \cdot \vec{Q}
K⋅Q后,需要使用softmax归一化操作,将数值转换到概率空间(按列计算)。
训练过程
对于一个完整序列,可以同时训练其子序列预测下一个词,这也就意味着前面的词不能看到后面的词(对于GPT而言词是一个一个生成的,所以并不能看到后面的序列),换而言之在上述查询矩阵中,下三角矩阵元素应该置0(具体操作为先将其值设置为-INF,通过softmax后就会转换为0).
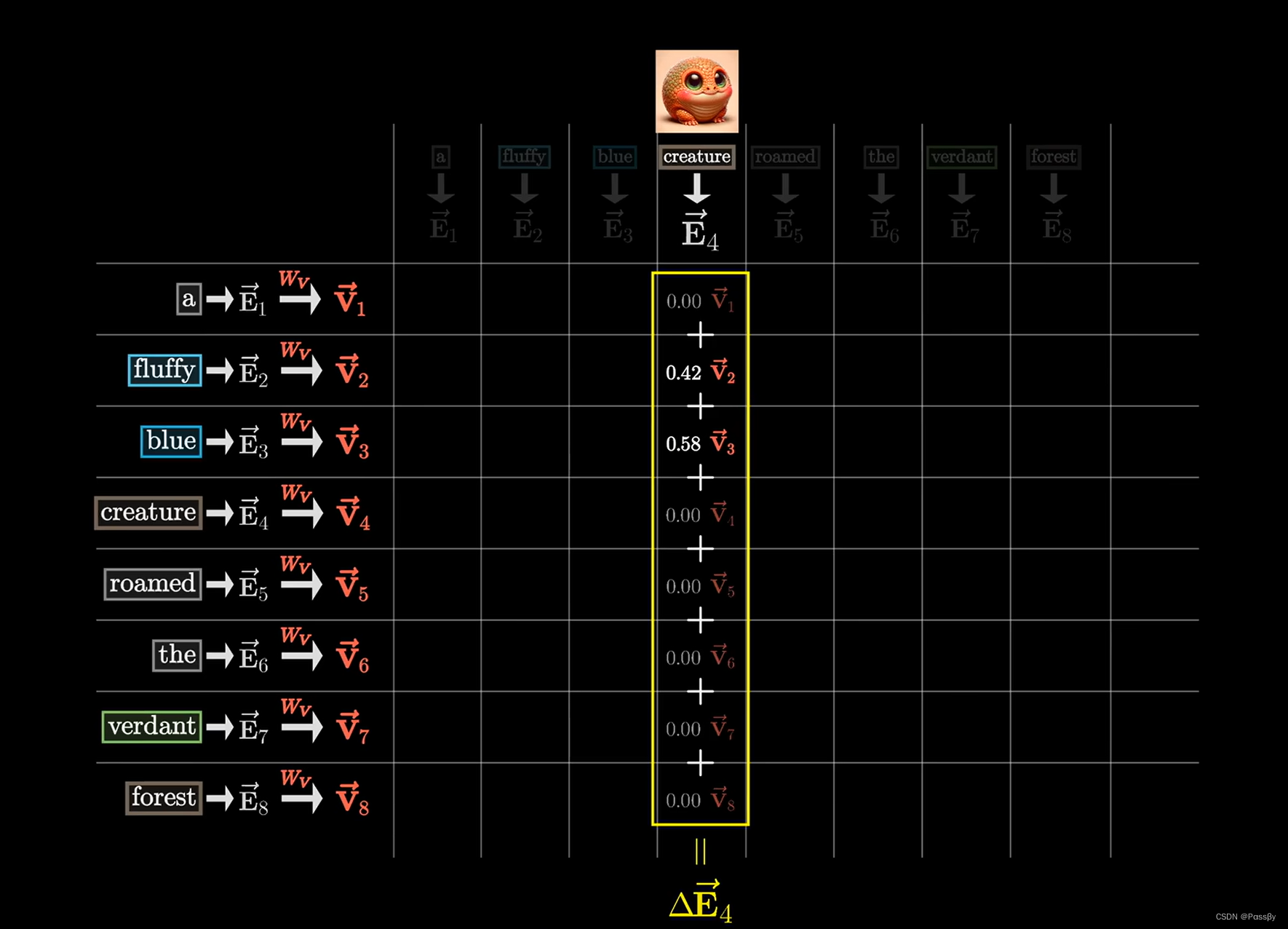
Value

想象场景中本身不考虑上下文信息的creature,通过上文blue fluffy更新他的词向量,具体就是通过乘以
W
v
W_v
Wv矩阵
多头注意力机制
多个不同的矩阵计算value
4.Residual Connection
主要思想:允许网络中的信号绕过一层或多层直接传递,解决深度神经网络中的梯度消失或梯度爆炸问题,使网络能够学习更深层次的特征。
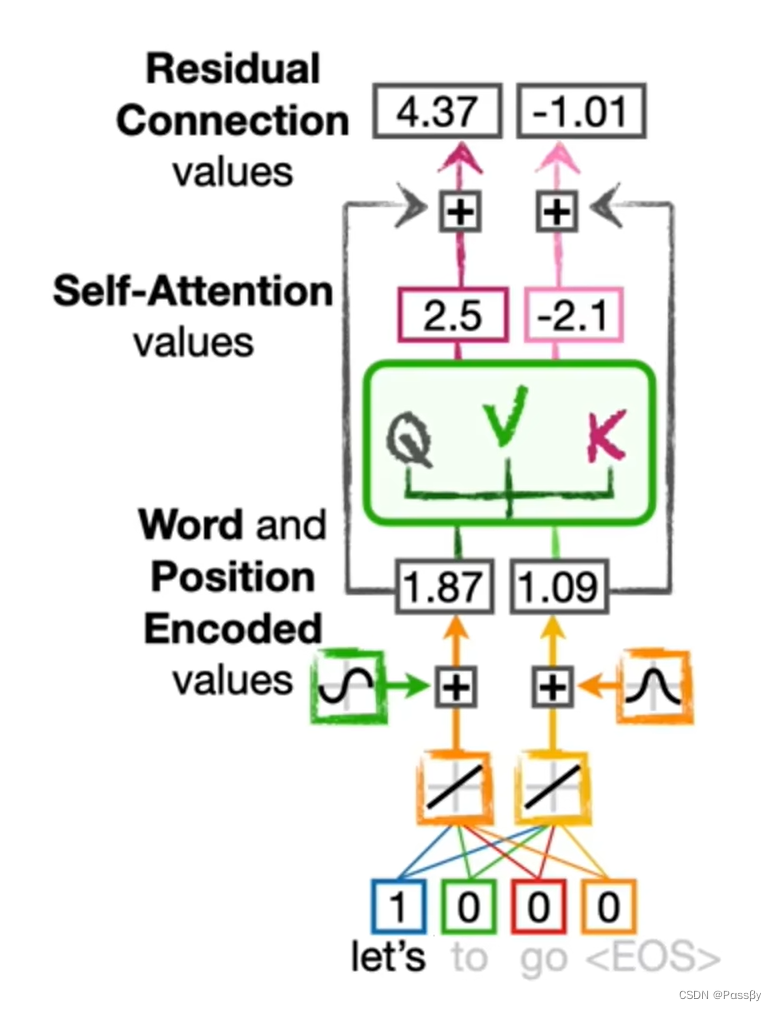
此外,值得一提的是所有词的词嵌入、位置编码、自注意力机制、残差链接并不像RNN那样需要顺序执行,可以同时进行计算
Decoder
解码器同样也需要词嵌入,但此时使用的是被翻译语言的词嵌入,与此同时,由于被翻译语句的结束,这里解码的第一个词往往从<EOS/>或者<SOS>开始。并且采用相同的激活函数、位置编码方式(这里就是用相同的正余弦函数)
和Encoder架构差不多,也有自注意力分数。(权重和Encoder的不同)















 426
426











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









