






提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
一、transformer是什么
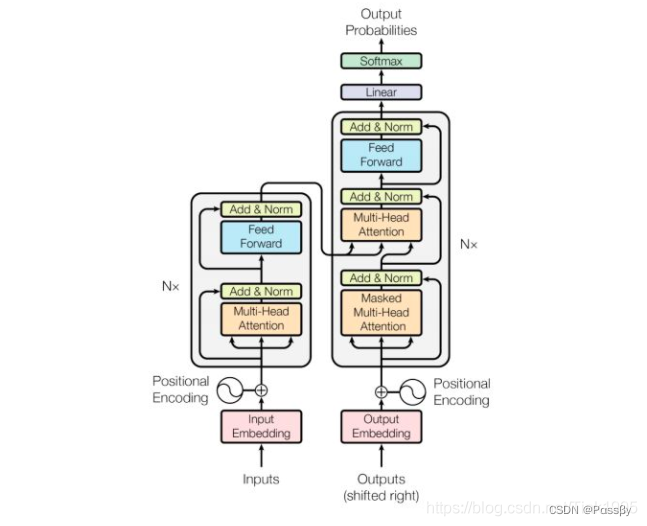
完整transformer的结构
transformer是经典的编码器解码器结构,对于整个结构分为四个主要部分
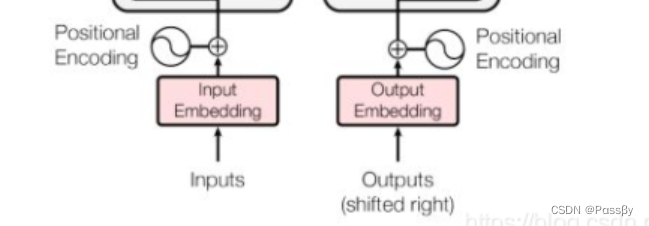
输入部分:transformer输入为固定长度的512(利于残差连接?大概)的向量,他除了包含词的信息还包含位置信息(positional encoding)
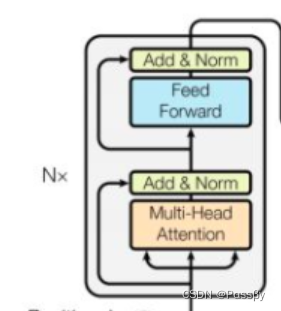
编码器部分:n个Transformer block(n=6)堆叠在一起
编码器主要是输入后进行多头注意力机制,残差连接,正则化,MLP,再残差连接正则化。
残差连接LayerNorm(x+Sublayer(x)),防止梯度消失
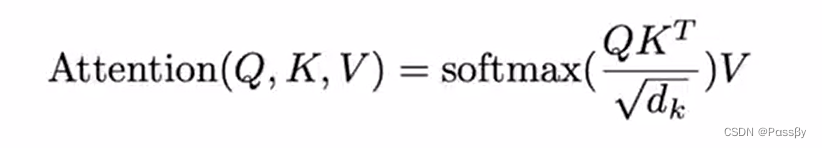
注意力机制,key,query,value,形象一点的理解:key相当于名字,value是分数,query表示我想看谁的分数,所以通过query去查key对应的value,获得最终的结果
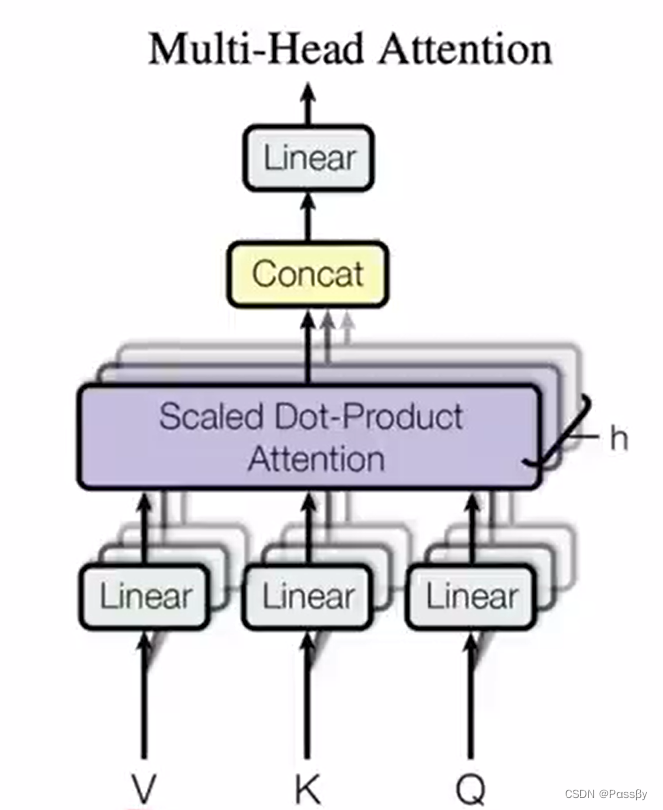
将vkq投影后进行点乘后拼接进行输出,点乘不像相加可以有参数学习,线性投影倒是可以学习
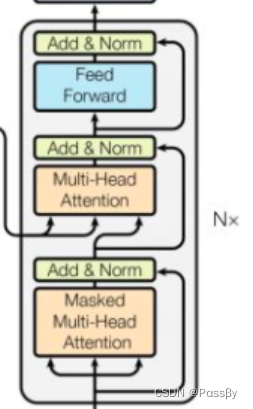
解码器部分:自回归,上一时刻的输出是这一时刻的输入(相当于输入不仅是当前输入值还包含上一时刻输出值),但不应该看到下一时刻的信息,所以是masked multi-head attention
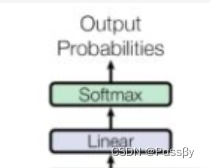
输出部分:输出就是线性层进行softmax
二、Bert是什么
bert指基于transformer的双向编码器表示
和transformer的区别:transformer使用位置编码,通过直到位置信息就知道了前文的信息,而bert认为还能直到后面的信息,他使用一个掩码的语言模型,简单来说就像是完形填空一样。
wordpiece:对于一个很少出现的词,可以把他切成一个个词根,让他变成更常见的词
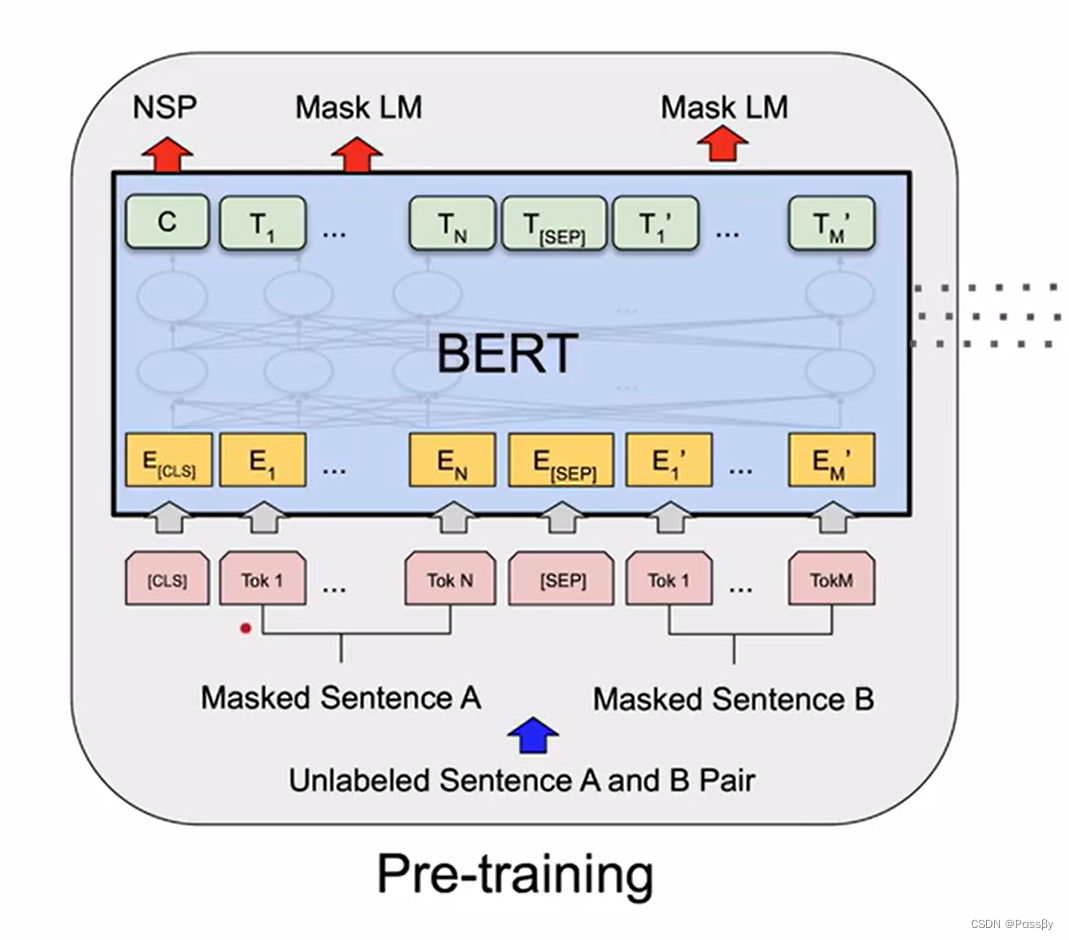
预训练
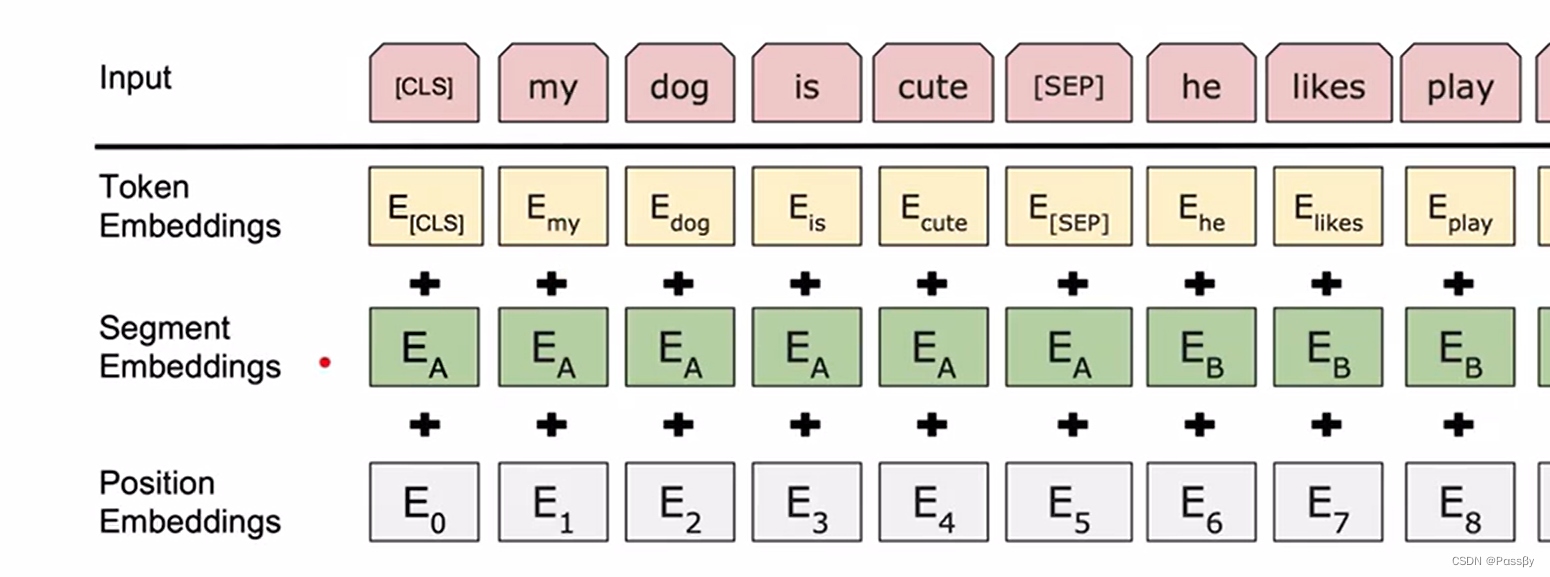
具体而言每一个输入包含三个信息:每个词自身的embedding信息,他在哪个句子部分的信息,他所在位置的信息















 2151
2151











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









