









上一篇梳理了接口
| HTTP Method | API Route | Description |
|---|---|---|
| GET | “/” | 重定向到Swagger文档页面 |
| POST | “/chat/chat” | 与LLM模型对话(通过LLMChain) |
| POST | “/chat/search_engine_chat” | 与搜索引擎对话 |
| POST | “/chat/feedback” | 返回LLM模型对话评分 |
| POST | “/chat/knowledge_base_chat” | 与知识库对话 |
| POST | “/chat/file_chat” | 文件对话 |
| POST | “/chat/agent_chat” | 与agent对话 |
| GET | “/knowledge_base/list_knowledge_bases” | 获取知识库列表 |
| POST | “/knowledge_base/create_knowledge_base” | 创建知识库 |
| POST | “/knowledge_base/delete_knowledge_base” | 删除知识库 |
| GET | “/knowledge_base/list_files” | 获取知识库内的文件列表 |
| POST | “/knowledge_base/search_docs” | 搜索知识库 |
| POST | “/knowledge_base/update_docs_by_id” | 直接更新知识库文档 |
| POST | “/knowledge_base/upload_docs” | 上传文件到知识库,并/或进行向量化 |
| POST | “/knowledge_base/delete_docs” | 删除知识库内指定文件 |
| POST | “/knowledge_base/update_info” | 更新知识库介绍 |
| POST | “/knowledge_base/update_docs” | 更新现有文件到知识库 |
| GET | “/knowledge_base/download_doc” | 下载对应的知识文件 |
| POST | “/knowledge_base/recreate_vector_store” | 根据content中文档重建向量库,流式输出处理进度 |
| POST | “/knowledge_base/upload_temp_docs” | 上传文件到临时目录,用于文件对话 |
| POST | “/knowledge_base/kb_summary_api/summary_file_to_vector_store” | 单个知识库根据文件名称摘要 |
| POST | “/knowledge_base/kb_summary_api/summary_doc_ids_to_vector_store” | 单个知识库根据doc_ids摘要 |
| POST | “/knowledge_base/kb_summary_api/recreate_summary_vector_store” | 重建单个知识库文件摘要 |
| POST | “/llm_model/list_running_models” | 列出当前已加载的模型 |
| POST | “/llm_model/list_config_models” | 列出configs已配置的模型 |
| POST | “/llm_model/get_model_config” | 获取模型配置(合并后) |
| POST | “/llm_model/stop” | 停止指定的LLM模型(Model Worker) |
| POST | “/llm_model/change” | 切换指定的LLM模型(Model Worker) |
| POST | “/server/configs” | 获取服务器原始配置信息 |
| POST | “/server/list_search_engines” | 获取服务器支持的搜索引擎 |
| POST | “/server/get_prompt_template” | 获取服务区配置的prompt模板 |
| POST | “/other/completion” | 要求LLM模型补全(通过LLMChain) |
| POST | “/other/embed_texts” | 将文本向量化,支持本地模型和在线模型 |
启动方式
startup.py里面
命令行参数的解释:
| 参数 | 简写 | 解释 |
|---|---|---|
| –all-webui | -a | 启动所有服务,包括Controller、OpenAI API、Model Worker、自定义API和Web UI |
| –all-api | 启动除Web UI外的所有后端服务,包括Controller、OpenAI API、Model Worker和自定义API | |
| –llm-api | 启动FastChat的Controller、OpenAI API、Model Worker服务 | |
| –openai-api | -o | 启动FastChat的Controller和OpenAI兼容API服务 |
| –model-worker | -m | 启动Model Worker服务,可以搭配–model-name指定要加载的模型 |
| –model-name | -n | 指定要加载的模型名称,可以列出多个,用空格隔开。默认加载LLM_MODELS中的模型 |
| –controller | -c | 指定Model Worker要连接的Controller服务地址,默认使用FSCHAT_CONTROLLER中的地址 |
| –api | 启动自定义API服务 | |
| –webui | -w | 启动Web UI服务 |
| –quiet | -q | 减少FastChat服务的日志输出 |
| –lite | -i | 以Lite模式运行,只支持使用在线API的LLM对话和搜索引擎对话 |
这些参数可以组合使用,例如:
- 启动全部服务:
python main.py -a - 启动后端服务:
python main.py --all-api - 启动Model Worker并指定模型:
python main.py -m -n chatglm-6b moss-moon-003-sft - 启动Controller和OpenAI API:
python main.py -o - 减少日志输出:
python main.py -a -q - 以Lite模式运行:
python main.py -i --api -w
希望这个表格能清晰地呈现所有命令行参数的用法。如果你还有任何问题,欢迎随时问我!
来看看测试文件
学习了一下pytest的使用
| 参数 | 描述 |
|---|---|
-k <expression> | 根据给定的字符串表达式匹配测试用例名称,只运行匹配的测试 |
-m <markname> | 只运行带有指定标记的测试用例 |
-v, --verbose | 输出详细的测试执行信息 |
-q, --quiet | 输出更少的测试执行信息 |
-s | 在输出中展示测试中的print语句 |
--collect-only | 只列出可执行的测试用例,不实际执行 |
--fixtures | 列出可用的夹具函数 |
-x, --exitfirst | 一旦遇到测试失败就退出,不再继续执行 |
--maxfail=num | 设置最大失败测试用例数量,超过就退出 |
--lf, --last-failed | 只重新运行上次失败的测试用例 |
--ff, --failed-first | 先运行上次失败的测试,再执行其他测试 |
-n=numprocesses | 多线程并发执行测试,加快测试速度 |
--capture=method | 设置捕获方法(no,sys,fd)控制输出 |
--durations=N | 显示N个耗时最长的测试用例 |
--tb=style | 设置详细输出模式(auto,long,short,line,native) |
通过组合使用这些参数,您可以控制pytest的运行方式、输出形式等,满足不同的测试需求。同时pytest也支持自定义参数、插件扩展等功能,是一款灵活且强大的测试框架。
看看llm_chat具体是怎么搞的
还是在测试文件里看看
比如pytest tests/api/test_stream_chat_api.py::test_chat_chat -s
-s参数挺有用的

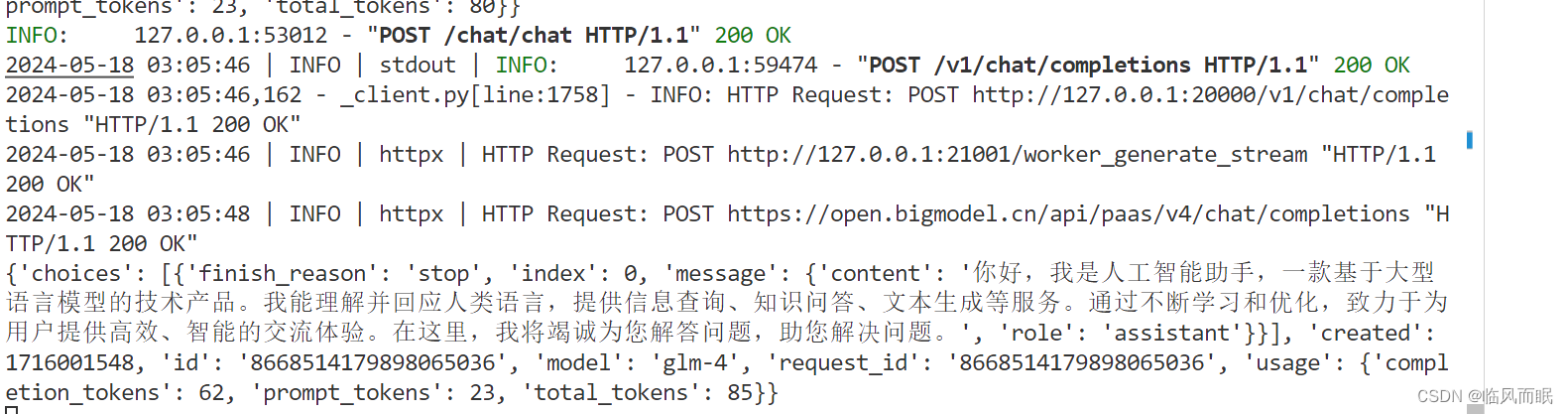
记得要先启动服务才能测试
上面这个是api的,返回是一次性的
本地大模型的返回是下面这样的

还是得去看他是如何处理的
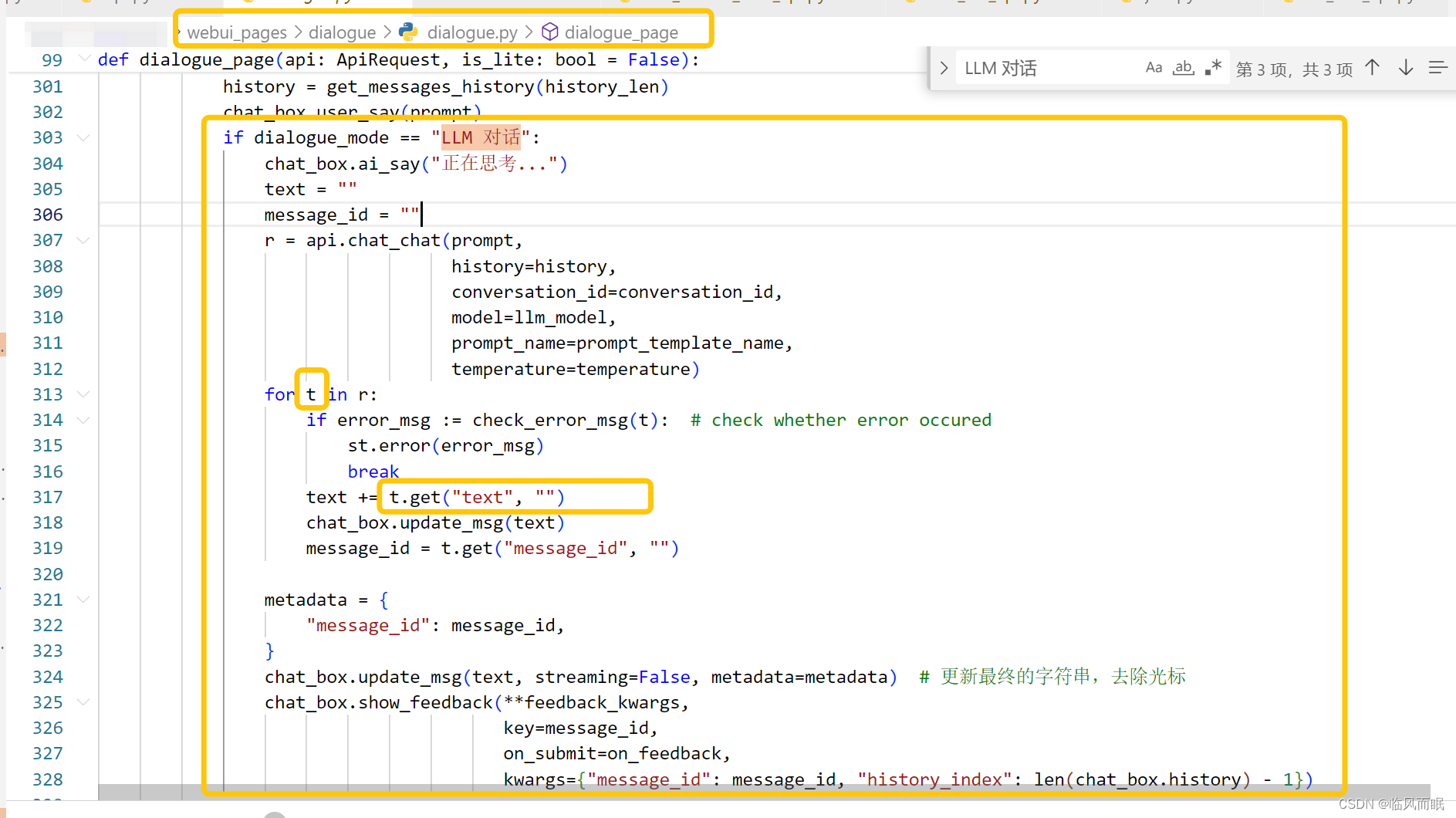
等下
chat/chat对应的函数在这↓
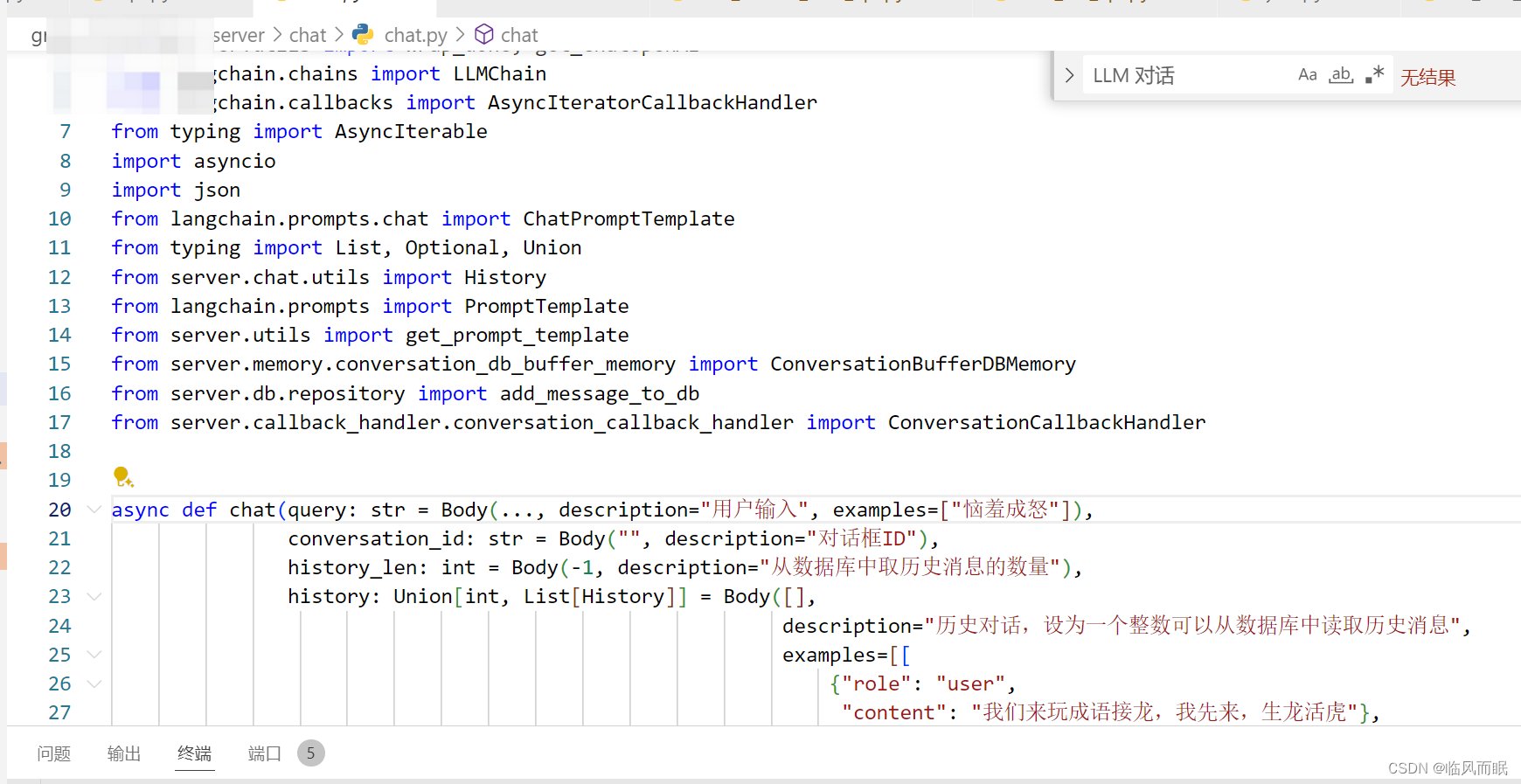
额,流模式是可以在这里指定的

在正式使用的时候是下面这个函数
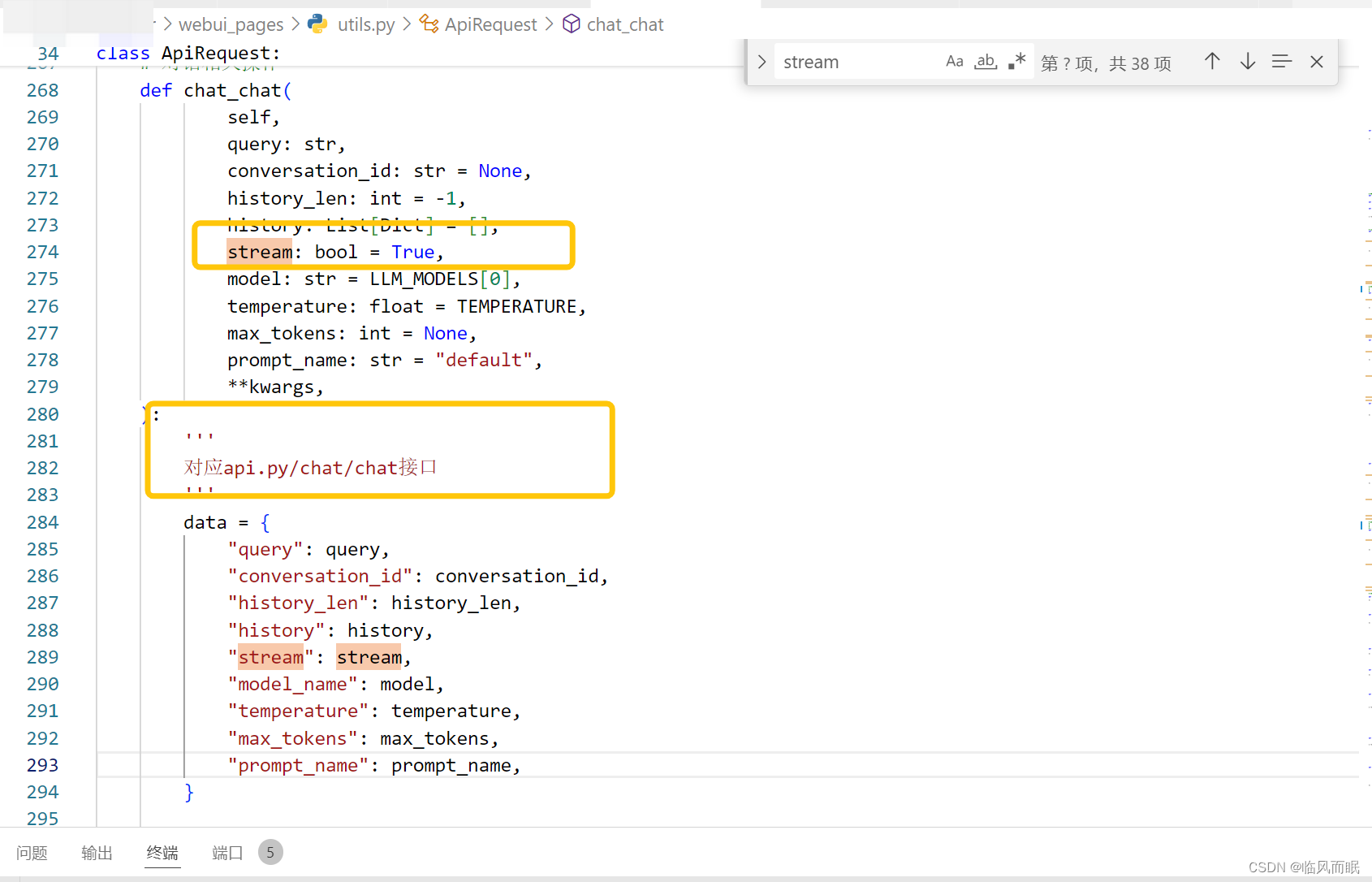
应该就是那个for t in r,然后t.get就行
哦不对
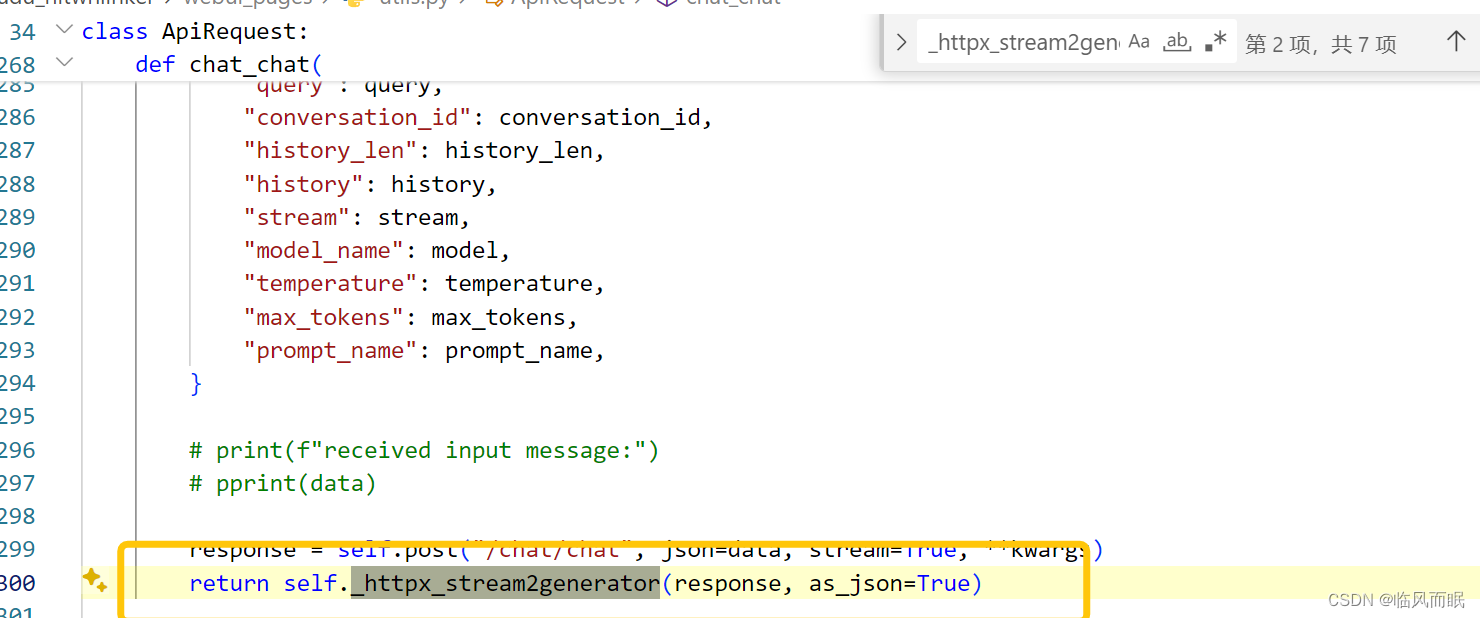
本身是bytes形式的,得先转换一下
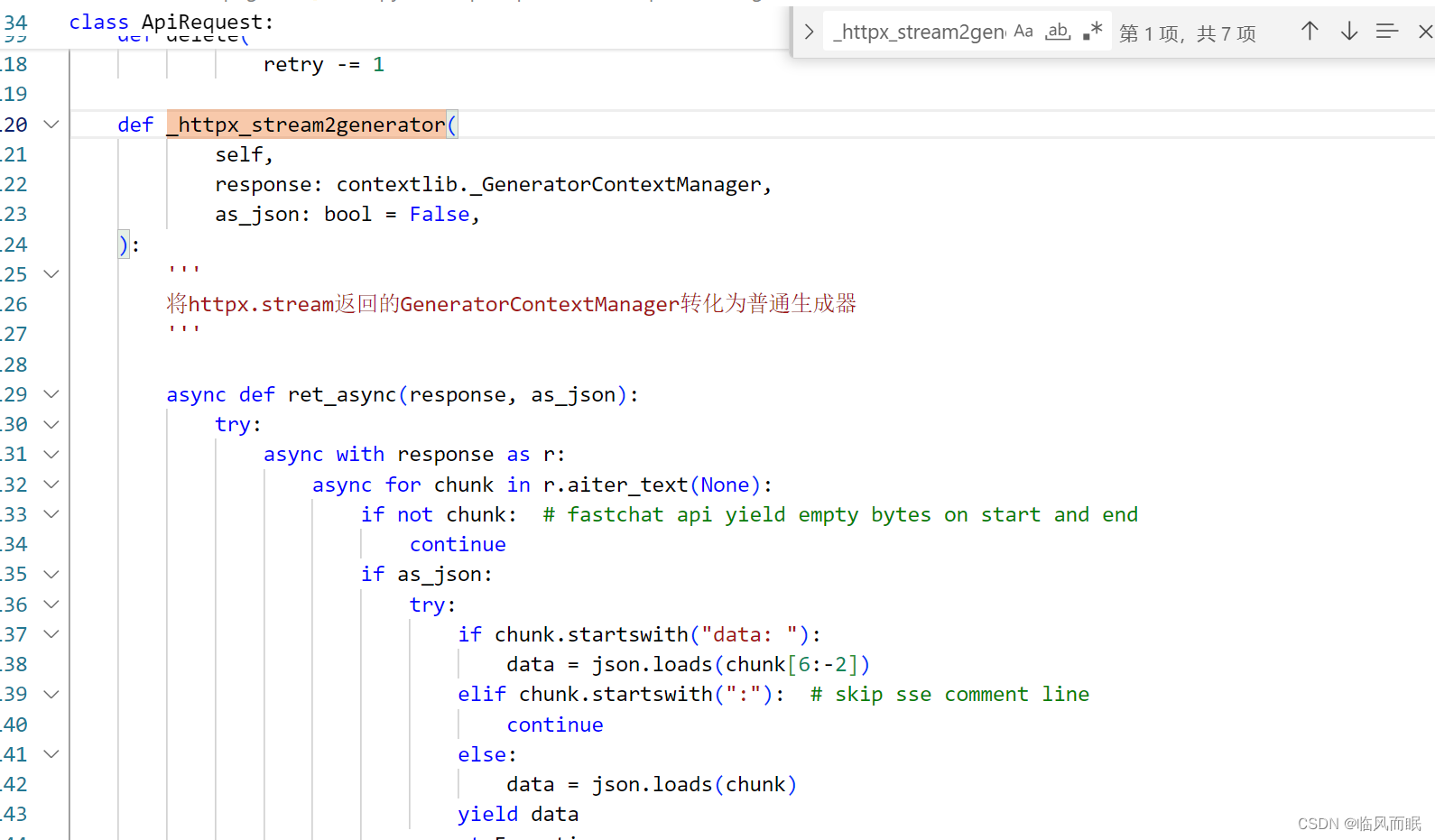
原来如此,现在大概明白了
那个.iter_content

大致明白了,不纠结了
后面知道咋用这些api就行了
梳理一下fastchat框架的作用
核心就是支持通过调用 FastChat api 调用 llm
在自定义页面里面,使用/chat/chat的接口
要看到chat/chat对应的函数
from webui_pages.utils import *
api = ApiRequest(base_url=api_address())

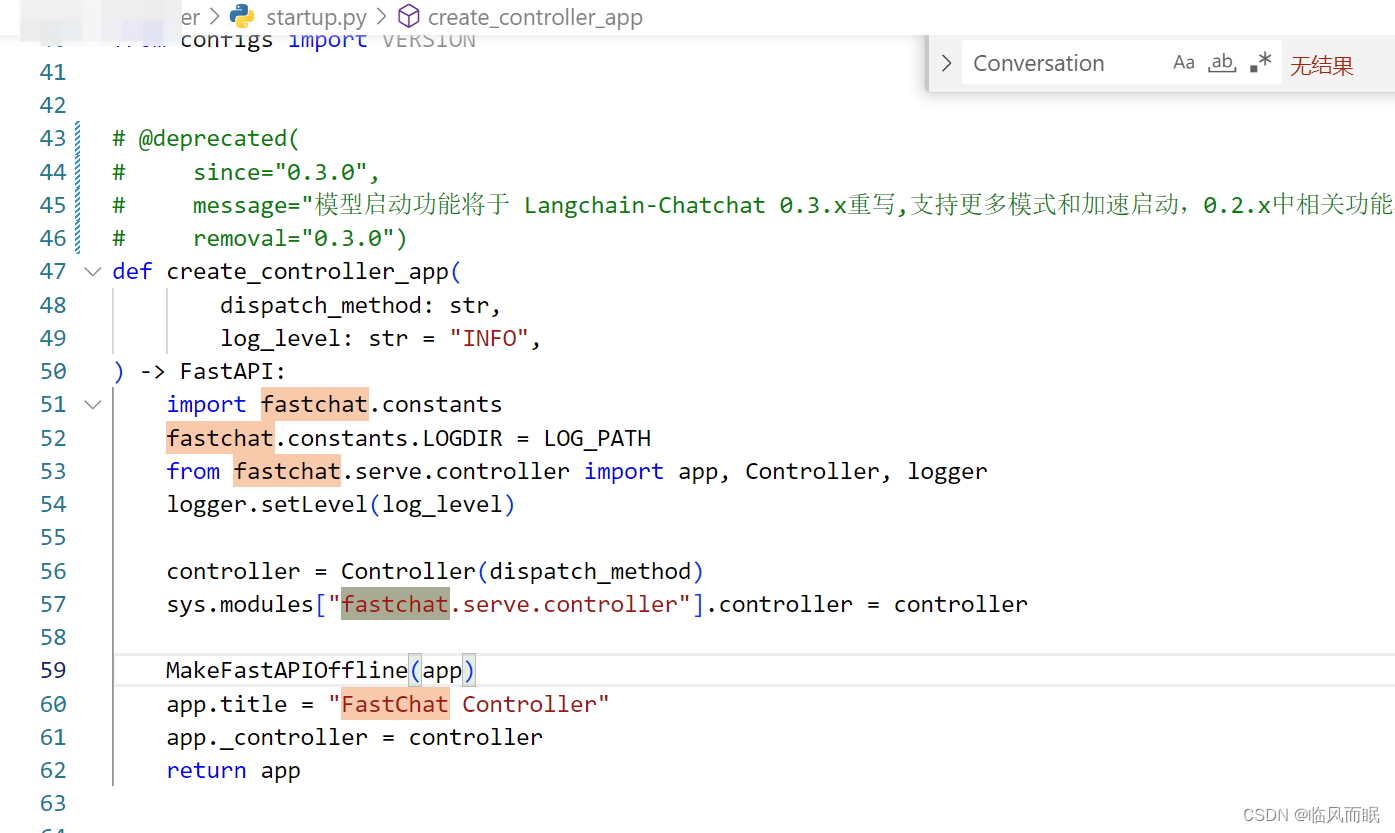
是startup.py里面的函数
def create_model_worker_app(log_level: str = "INFO", **kwargs) -> FastAPI:
"""
kwargs包含的字段如下:
host:
port:
model_names:[`model_name`]
controller_address:
worker_address:
对于Langchain支持的模型:
langchain_model:True
不会使用fschat
对于online_api:
online_api:True
worker_class: `provider`
对于离线模型:
model_path: `model_name_or_path`,huggingface的repo-id或本地路径
device:`LLM_DEVICE`
"""
import fastchat.constants
fastchat.constants.LOGDIR = LOG_PATH
import argparse
parser = argparse.ArgumentParser()
args = parser.parse_args([])
for k, v in kwargs.items():
setattr(args, k, v)
if worker_class := kwargs.get("langchain_model"): # Langchian支持的模型不用做操作
from fastchat.serve.base_model_worker import app
worker = ""
# 在线模型API
elif worker_class := kwargs.get("worker_class"):
from fastchat.serve.base_model_worker import app
worker = worker_class(model_names=args.model_names,
controller_addr=args.controller_address,
worker_addr=args.worker_address)
# sys.modules["fastchat.serve.base_model_worker"].worker = worker
sys.modules["fastchat.serve.base_model_worker"].logger.setLevel(log_level)
# 本地模型
else:
from configs.model_config import VLLM_MODEL_DICT
if kwargs["model_names"][0] in VLLM_MODEL_DICT and args.infer_turbo == "vllm":
import fastchat.serve.vllm_worker
from fastchat.serve.vllm_worker import VLLMWorker, app, worker_id
from vllm import AsyncLLMEngine
from vllm.engine.arg_utils import AsyncEngineArgs
args.tokenizer = args.model_path
args.tokenizer_mode = 'auto'
args.trust_remote_code = True
args.download_dir = None
args.load_format = 'auto'
args.dtype = 'auto'
args.seed = 0
args.worker_use_ray = False
args.pipeline_parallel_size = 1
args.tensor_parallel_size = 1
args.block_size = 16
args.swap_space = 4 # GiB
args.gpu_memory_utilization = 0.90
args.max_num_batched_tokens = None # 一个批次中的最大令牌(tokens)数量,这个取决于你的显卡和大模型设置,设置太大显存会不够
args.max_num_seqs = 256
args.disable_log_stats = False
args.conv_template = None
args.limit_worker_concurrency = 5
args.no_register = False
args.num_gpus = 1 # vllm worker的切分是tensor并行,这里填写显卡的数量
args.engine_use_ray = False
args.disable_log_requests = False
# 0.2.1 vllm后要加的参数, 但是这里不需要
args.max_model_len = None
args.revision = None
args.quantization = None
args.max_log_len = None
args.tokenizer_revision = None
# 0.2.2 vllm需要新加的参数
args.max_paddings = 256
if args.model_path:
args.model = args.model_path
if args.num_gpus > 1:
args.tensor_parallel_size = args.num_gpus
for k, v in kwargs.items():
setattr(args, k, v)
engine_args = AsyncEngineArgs.from_cli_args(args)
engine = AsyncLLMEngine.from_engine_args(engine_args)
worker = VLLMWorker(
controller_addr=args.controller_address,
worker_addr=args.worker_address,
worker_id=worker_id,
model_path=args.model_path,
model_names=args.model_names,
limit_worker_concurrency=args.limit_worker_concurrency,
no_register=args.no_register,
llm_engine=engine,
conv_template=args.conv_template,
)
sys.modules["fastchat.serve.vllm_worker"].engine = engine
sys.modules["fastchat.serve.vllm_worker"].worker = worker
sys.modules["fastchat.serve.vllm_worker"].logger.setLevel(log_level)
else:
from fastchat.serve.model_worker import app, GptqConfig, AWQConfig, ModelWorker, worker_id
args.gpus = "0" # GPU的编号,如果有多个GPU,可以设置为"0,1,2,3"
args.max_gpu_memory = "22GiB"
args.num_gpus = 1 # model worker的切分是model并行,这里填写显卡的数量
args.load_8bit = False
args.cpu_offloading = None
args.gptq_ckpt = None
args.gptq_wbits = 16
args.gptq_groupsize = -1
args.gptq_act_order = False
args.awq_ckpt = None
args.awq_wbits = 16
args.awq_groupsize = -1
args.model_names = [""]
args.conv_template = None
args.limit_worker_concurrency = 5
args.stream_interval = 2
args.no_register = False
args.embed_in_truncate = False
for k, v in kwargs.items():
setattr(args, k, v)
if args.gpus:
if args.num_gpus is None:
args.num_gpus = len(args.gpus.split(','))
if len(args.gpus.split(",")) < args.num_gpus:
raise ValueError(
f"Larger --num-gpus ({args.num_gpus}) than --gpus {args.gpus}!"
)
os.environ["CUDA_VISIBLE_DEVICES"] = args.gpus
gptq_config = GptqConfig(
ckpt=args.gptq_ckpt or args.model_path,
wbits=args.gptq_wbits,
groupsize=args.gptq_groupsize,
act_order=args.gptq_act_order,
)
awq_config = AWQConfig(
ckpt=args.awq_ckpt or args.model_path,
wbits=args.awq_wbits,
groupsize=args.awq_groupsize,
)
worker = ModelWorker(
controller_addr=args.controller_address,
worker_addr=args.worker_address,
worker_id=worker_id,
model_path=args.model_path,
model_names=args.model_names,
limit_worker_concurrency=args.limit_worker_concurrency,
no_register=args.no_register,
device=args.device,
num_gpus=args.num_gpus,
max_gpu_memory=args.max_gpu_memory,
load_8bit=args.load_8bit,
cpu_offloading=args.cpu_offloading,
gptq_config=gptq_config,
awq_config=awq_config,
stream_interval=args.stream_interval,
conv_template=args.conv_template,
embed_in_truncate=args.embed_in_truncate,
)
sys.modules["fastchat.serve.model_worker"].args = args
sys.modules["fastchat.serve.model_worker"].gptq_config = gptq_config
# sys.modules["fastchat.serve.model_worker"].worker = worker
sys.modules["fastchat.serve.model_worker"].logger.setLevel(log_level)
MakeFastAPIOffline(app)
app.title = f"FastChat LLM Server ({args.model_names[0]})"
app._worker = worker
return app
startup.py里面很多东西
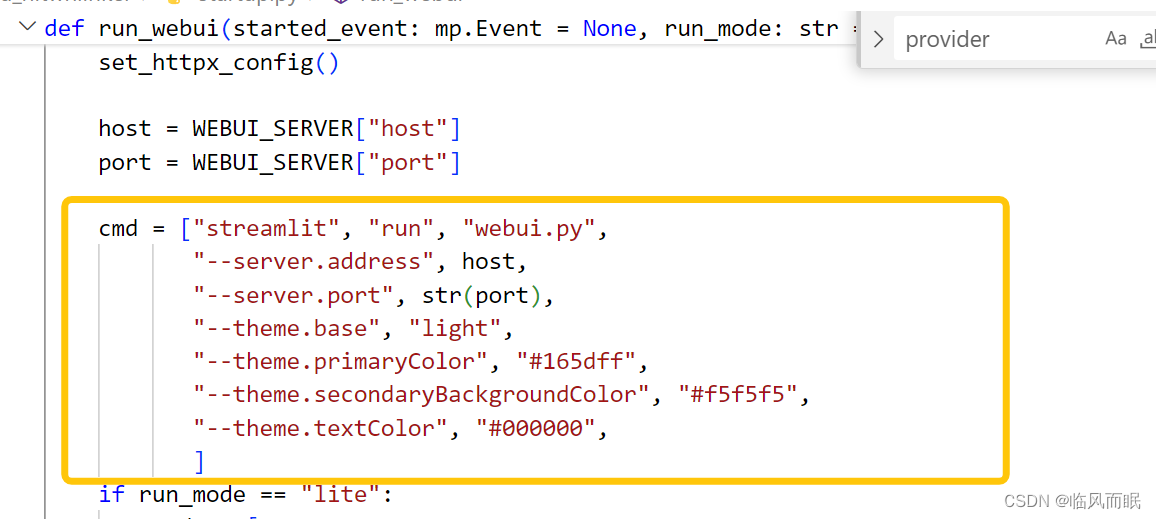
-a会启动各种















 1595
1595











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









