







前言
上次我们完成了Chatchat的本地部署,使用了LLM对话的功能。这次我们尝试一下其他的功能,之前总是有报错没有跑通,这次处理了几个问题之后才跑通了知识库对话和文件对话。
知识库对话
原理:
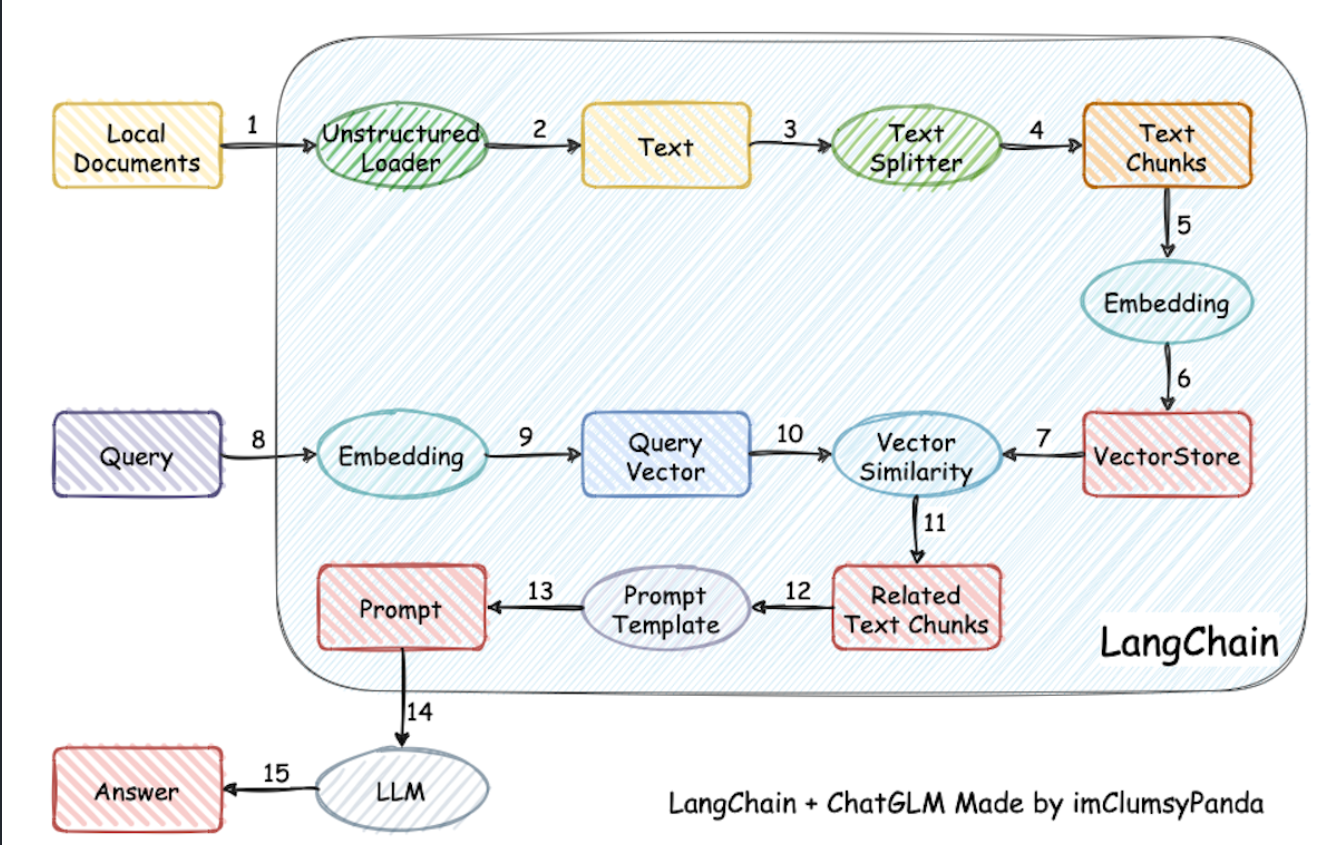
首先我们看这个图可以明白,知识库对话是有很多步骤的,1-7步是把上传的文件做处理,拆分,转为向量储存起来。然后当我们发起查询请求,也会被转换为向量,接着和向量数据库的向量做相似度比较,找到比较相近的向量对应的文本。最后根据这些文本去构造了prompt请求LLM获取返回数据。
使用步骤:
先说明一下这里我用的是智谱AI的API,也就是在线的LLM,本地如果是使用chatglm的话,因为本身个人电脑配置不高,所以能运行的模型参数都相对较小,有些知识库对应的信息可能查不出来,用知识库对话的话建议是使用在线的llm。一开始用本地的llm,问了很多知识库的问题都回答不上来,找不到知识库匹配结果,我还以为是我哪里运行有问题,后来换成在线的llm就可以了。
1.点击知识库管理
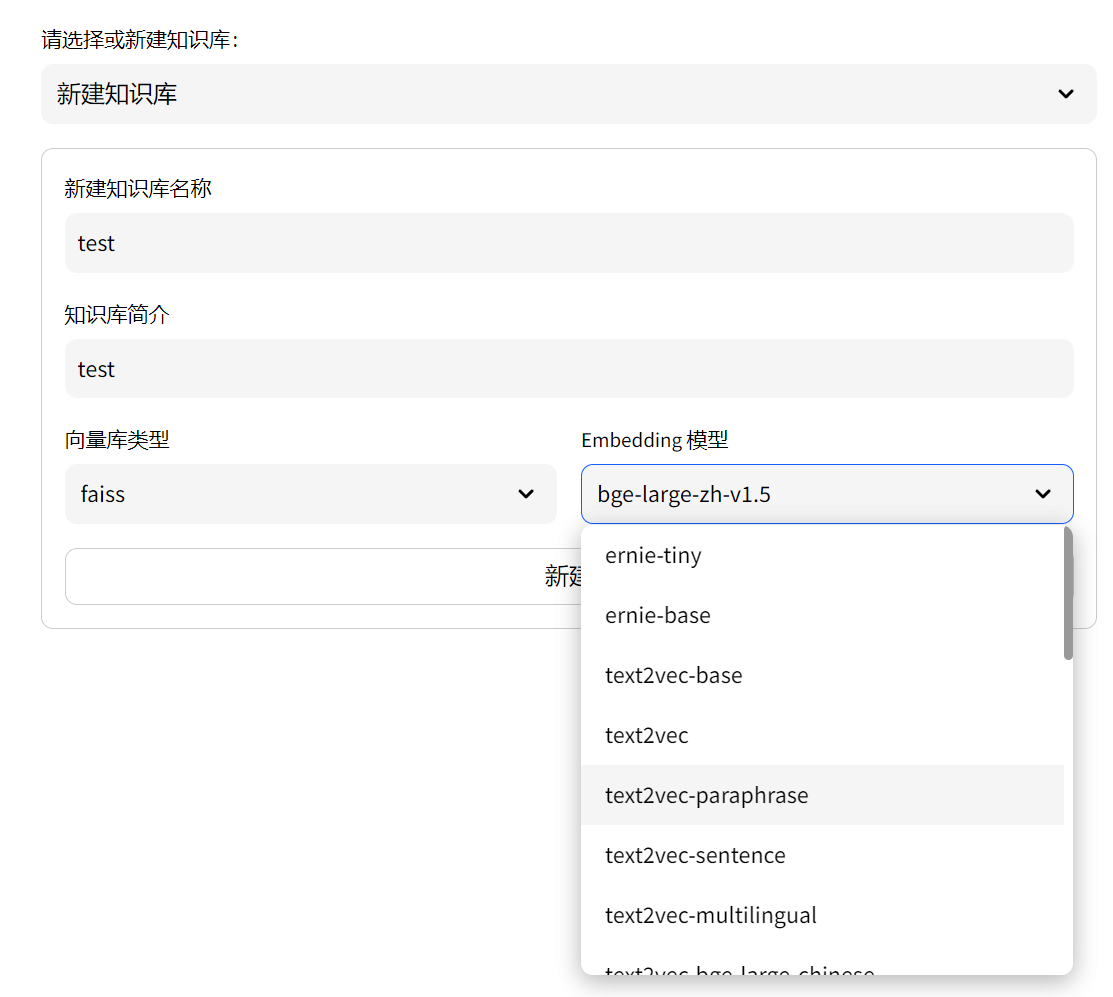
2.选择或者新建一个知识库
这里面有一些向量数据库和Embedding模型可以选择,我就用的默认的,其他的能不能组合跑起来还没有试过。
3.上传知识库文件
这个是github上写的支持的文件格式:
Langchain 应用
本地数据接入接入非结构化文档
- .txt, .rtf, .epub, .srt
- .eml, .msg
- .html, .xml, .toml, .mhtml
- .json, .jsonl
- .md, .rst
- .docx, .doc, .pptx, .ppt, .odt
- .enex
- .jpg, .jpeg, .png, .bmp
- .py, .ipynb
4.添加文件到知识库中
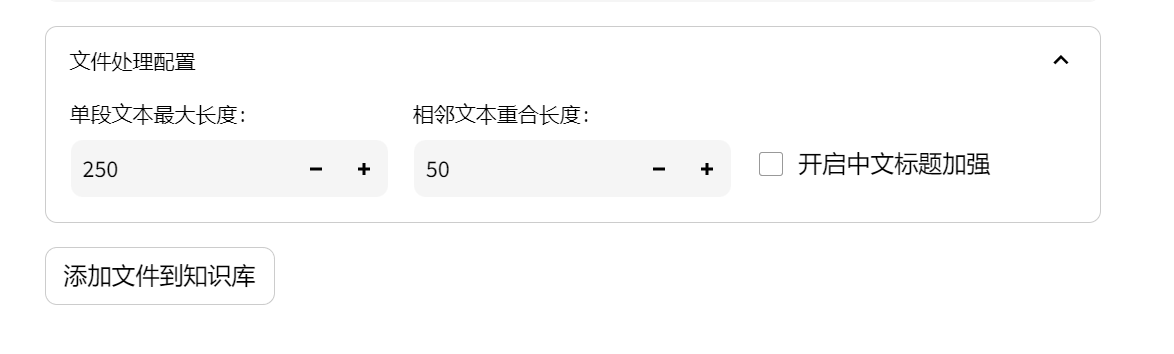
点击添加文件到知识库,就会把文件保存到知识库,然后裁剪拆分成向量,往向量库放一份当前文本对应的向量。
这里可以根据文档的具体数据类型来调整,每一段文本的长度。相邻文本重合长度是指的两个文本会重叠的部分,举个例子按照文本250字符切分的话,可能会把一句正常的话给截断掉,所以会多选择一些字符串。
比如说上面的设置是chunk_size=250, chunk_overlap=50。
处理文本时,每个文本块的实际长度是 chunk_size=250 个字符。
但是,由于chunk_overlap=50,相邻文本块之间会有 50 个字符的重叠。
这意味着:
- 第一个文本块长度是 250
- 第二个文本块从第一个块的第 201 个字符(250-50=200,+1=201)开始,长度还是 250
- 第三个文本块从第二个块的第 201 个字符开始,长度还是 250
- 以此类推
5.展示结果
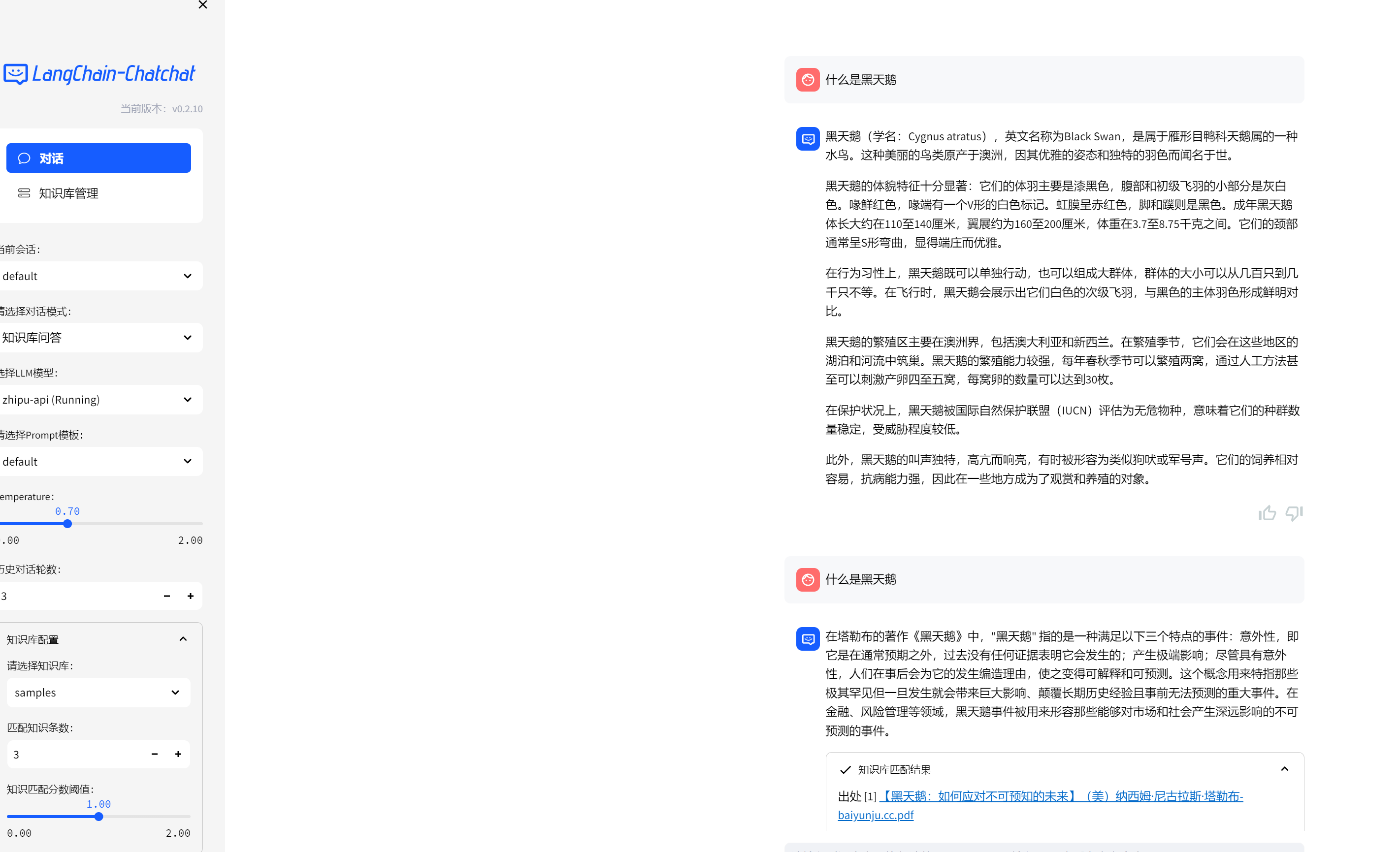
这个知识库我传了一本关于黑天鹅事件的pdf,从图中可以看到上面是没有知识库匹配的时候,llm以为我问的是黑天鹅这个物种。下面选择了知识库问答之后,返回的事对黑天鹅事件的描述,对于问问题的人来说,如果一开始就知道要从哪些文档里面去找答案的话,用知识库匹配会更加贴近你想要问的问题。我的理解是,知识库问答在llm问答之前相当于是做了一层预处理,帮助我们构建了更加合理的prompt,所以得到的答案会更加准确,本质上还是llm的能力。因为如果llm本身没有黑天鹅这个知识,它也没法回答我,所以要想好好利用llm的能力,实际上是要构建最合适的问题,这也就是所谓的prompt工程吧。
文件对话

文件对话就不多说了,相当于只有搜索向量库,而没有llm优化后回答得部分,东西是能搜索出的。如果是对于有大量数据文档的话,这个向量搜索还是有用的,可以帮助检索提升效率。因为很多时候问问题的人并不是那么的专业,可能问题本身就会会跑偏,直接文本匹配的话,不一定是找到有用的信息。向量搜索能更好地匹配语义相关的结果,可以返回表达类似含义但用词不同的文档,这就是它的优势所在。
遇到问题
1.上传文件的时候报错utils.py[line:377] - ERROR: ImportError: 从文件 test/test.txt 加载文档时出错:libGL.so.1: cannot open shared object file: No such file or directory
首先我使用的是pdf,报了这个错,我以为是pdf不能识别的问题。然后就按照chatchat的github的wiki里面对文件进行预处理。修改成了比较简单内容,而且是txt格式方便程序来识别。结果还是报错,就查了下这个报错。发现问题是因为少了系统包下面是gpt对这两个包的说明,反正就是会用的的库吧。
libgl1-mesa-glx 和 libglib2.0-0 是两个非常重要的库文件:
- libgl1-mesa-glx 这个包提供了Mesa 3D图形库的OpenGL实现。OpenGL(OpenGL Library)是一个跨语言、跨平台的2D和3D图形API,被广泛应用于图形渲染、游戏开发、CAD、虚拟现实、科学可视化等领域。Mesa是一个开源的OpenGL实现,用于在Linux、Windows、macOS等操作系统上提供硬件3D加速支持。libgl1-mesa-glx是Mesa的GLX实现,用于在X Window系统上运行OpenGL程序。
- libglib2.0-0
这个包含有GLib库的核心文件。GLib是GNOME项目的底层系统库,提供了基本的系统独立型数据结构和操作,如链表、树、哈希表、内存分配等。它被广泛用作GTK+、GStreamer、WebKitGTK+等GNOME软件的基础构件。GLib提供了线程抽象、IPC、事件循环、Unicode处理等通用功能,是编写应用程序的基础,也可以单独使用。
总的来说,libgl1-mesa-glx提供OpenGL 3D图形渲染支持,而libglib2.0-0则是编写GTK+/GNOME应用程序及其它应用的核心基础库。这两个库在图形界面应用、游戏、科学计算等领域都有重要应用。
















 9600
9600

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









