







摘要
尽管通用目标检测的性能已经取得了显著的成功,但小目标检测(SOD)的性能和效率仍然不尽人意。现有的工作在推理速度和SOD性能之间难以平衡。本文提出了一种新颖的Scale-aware Knowledge Distillation(ScaleKD)方法,将复杂教师模型的知识传递给紧凑的学生模型。设计了两个新颖的模块来提升SOD蒸馏中的知识质量:1)尺度解耦特征蒸馏模块,将教师的特征表示解耦成多尺度嵌入,使学生模型能够显式地模仿小目标的特征;2)跨尺度辅助模块,用于优化学生模型产生的嘈杂且信息不足的边界框预测,这可能会误导学生模型并损害知识蒸馏的效果。通过在COCO和VisDrone数据集上进行实验,证明了ScaleKD在通用检测性能上取得了优越的表现,并且在SOD性能上取得了显著的改进。
拟解决的问题
小目标检测(SOD)在目标检测任务中仍然是一个挑战,因为小目标通常在图像中占据的区域较小,容易受到背景和其他较大目标的干扰,导致特征表示质量下降。此外,小目标检测对边界框预测的噪声非常敏感,教师模型的不准确预测可能会严重影响学生模型的性能。
创新之处
- 尺度解耦特征蒸馏模块(SDF):通过多分支卷积块并行处理不同尺度的特征,每个分支处理一个尺度,从而允许学生模型更好地理解从教师模型学习到的特征知识。
- 跨尺度辅助模块(CSA):使用多尺度交叉注意力层来捕获多尺度语义信息,改善学生模型的性能。
方法
- 尺度解耦特征蒸馏:通过并行多分支卷积块,每个分支处理一个尺度的特征,使用不同的扩张率来关注不同大小的对象。
- 跨尺度辅助:采用多尺度交叉注意力模块,将教师和学生模型的特征映射到单一的特征嵌入中,通过多尺度查询-键对将教师的特征投影到多个尺寸,以保留细粒度和低级细节。

尺度解耦特征蒸馏
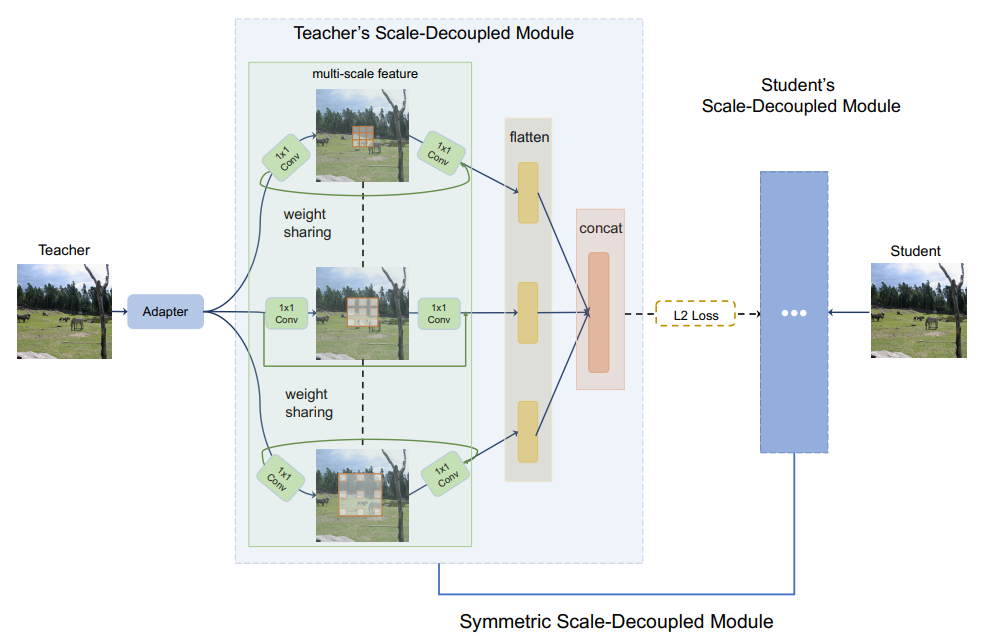
-
特征提取:在主干网络的最后一段,教师和学生网络分别得到特征嵌入Z_T和Z_S。
-
多尺度特征处理:为了充分利用不同输入尺度上的特征表示,设计了一个多分支结构,每个分支使用具有不同扩张率的卷积层。例如,在ResNet中,使用了带有不同扩张率{1, 2, 3}的3x3卷积层。
-
适配器层:在尺度解耦特征模块之前添加了一个适配器层(通常是多层感知机),目的是对齐教师和学生模型之间的特征维度。
-
权重共享:受到神经架构搜索中的权重共享网络的启发,设计中采用了权重共享策略。由于所有三个分支都有相同的运算符,所以只保留一组权重,减少了训练时的内存需求。
-
扁平层和连接:为了避免过度复杂的超参数调整,每个分支都使用了一个扁平层(多层感知机),并将它们连接在一起。这样只需要一个l2损失函数(标记为Lf eat)来度量教师和学生模型之间连接扁平层的距离。
-
唯一损失函数:通过唯一的l2损失函数,引导模型优化过程,使得学生模型能够尽可能地接近教师模型的表现。
-
模块设计:提出的这种模块设计被称为“对称尺度解耦模块”,因为教师和学生网络的对应模块是相互对应的。
跨尺度辅助
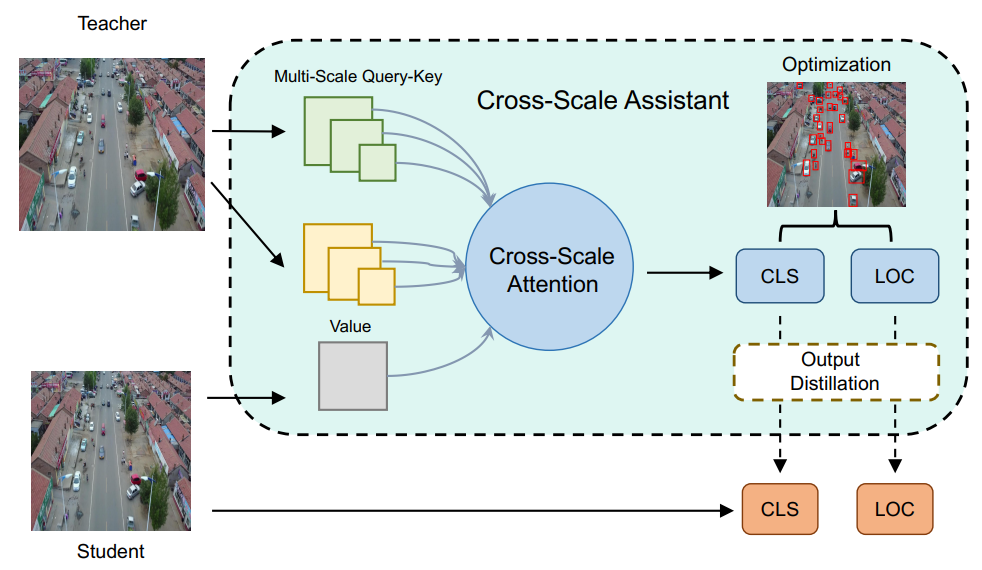
-
交叉注意模块:通过交叉注意模块建立CSA,其作用是在教师网络的知识范围内计算键(Keys)和查询(Queries),然后将这些键和查询与学生模型的输出(作为值张量)进行映射,以获得每个查询的注意区域。
-
多尺度处理:在每个学生金字塔尺度上执行上述过程,以检索基于不同尺度的区域信息特征。
-
普通交叉注意的问题:虽然可以使用普通的交叉注意机制,但先前的研究发现这种标准的交叉注意会在不同的头部重复关注显著区域,导致对大物体的关注过多而忽略了小物体。
-
多尺度交叉注意:为了解决这个问题,开发了一种多尺度交叉注意层。与普通交叉注意相比,该层能够更好地关注不同尺度的对象,确保小物体也能被正确地学习到。
-
多尺度查询-键对:将查询-键对拆分成多个子对,每个子对代表一组特定尺度的对象。这样做可以迫使注意模块关注具有不同尺度的区域,从而让所有对象都能参与到特征学习的过程中。
-
全局信息提取:交叉注意提取全局信息,对于每个查询-键对都会生成一个值来突出显示最敏感的区域。
具体细节:给出来自老师的输入序列 F-T ∈ R h×w×c 和来自学生的另一个输入序列 F-S ∈ R- h×w×c ,为简单起见,在此假设两个张量具有相同的大小。 F-T 被投影到查询(Q)和键(K),而 F-S 被投影到值(V)。键 K 和值 V 被下采样到不同的大小,以 i 为索引。
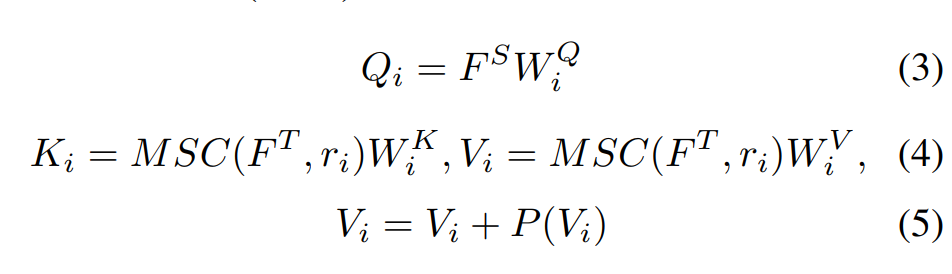
其中 MSC(·, r_i) 是用于第 i 个头聚合的 MLP 层,下采样率为 r_i ,P(·) 是用于投影的深度卷积层。与标准交叉注意相比,保留了更多有利于 SOD 的细粒度和低级细节。 最后,计算注意力张量:
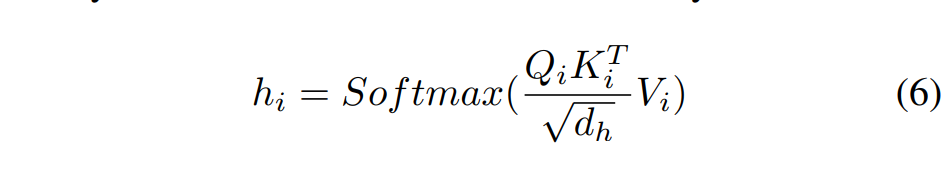
d_h 是维度。CSA 的目的是在教师和学生模型之间架起跨尺度信息桥梁,以改进 KD 中的边界框监督。因此,文章将头部层与分类分支和回归分支堆叠在一起,以更新这些可学习模块的权重。在蒸馏过程中,不是将教师的输出知识迁移给学生,而是将 CSA 在分类和回归分支上的知识迁移给学生。
最终,学生模型的总体训练目标如下所示:
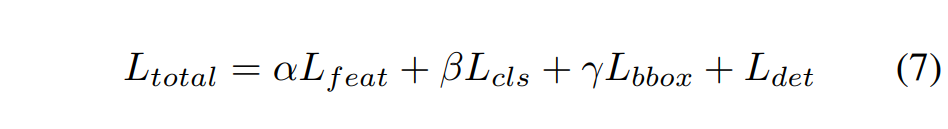
L_feat:训练过程中用来衡量模型产生的特征图与目标特征图之间差异的损失
L_cls:用来评估模型分类预测准确性的损失
L_bbox:用于衡量模型预测的边界框位置与真实边界框位置之间的误差
L_det:检测器的标准训练损失
超参数自己设就行,文章是:
对所有两阶段模型设置 α = 0.07、β = 0.5、γ = 0.2
对所有一阶段模型设置 α = 0.01、β = 0.2、γ = 0.05
实验结果
结论
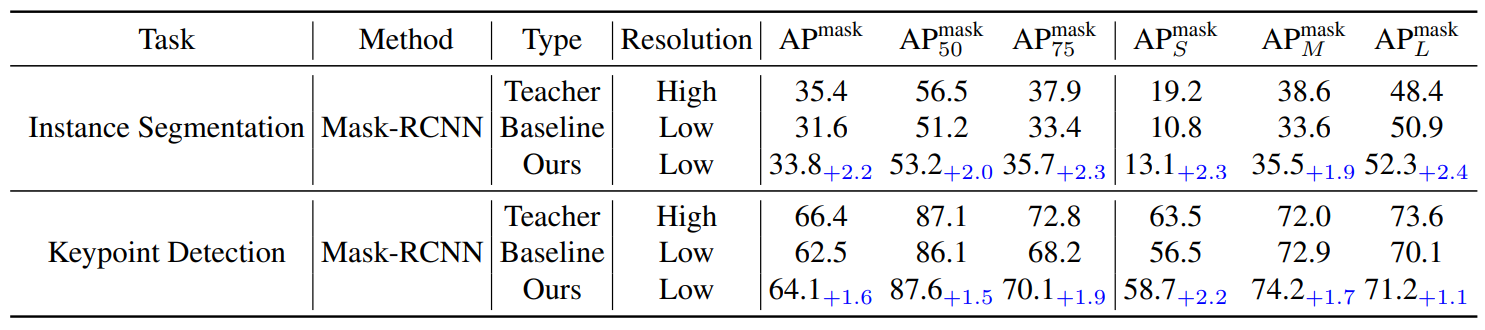
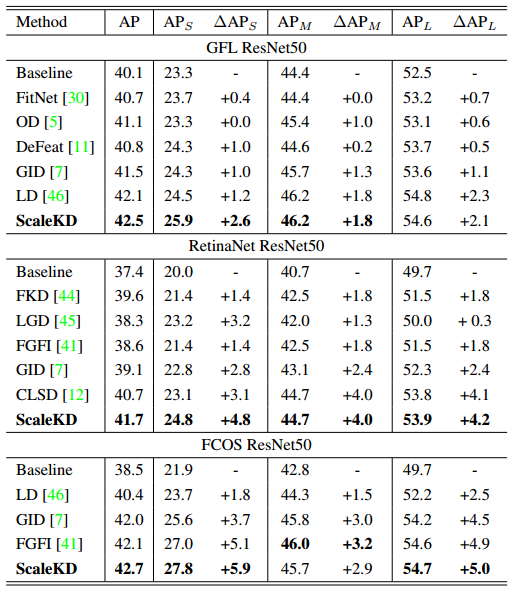
ScaleKD方法在COCO和VisDrone数据集上进行了实验,证明了其在通用目标检测和SOD性能上的优越性。该方法不仅提高了学生模型在小目标上的检测性能,而且没有在测试时引入额外的计算成本。此外,ScaleKD方法在实例分割和关键点检测等实例级任务上也表现出色,证明了其在处理视觉任务中的小目标方面的优越性。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









