







Kolmogorov-Smirnov检验(K-S检验)是一种非参数检验方法,用于比较两个概率分布(或一个样本与参考分布)之间的差异。
1. K-S检验的核心处理
(1) 计算累积分布函数(CDF)
• 对两组数据分别计算经验累积分布函数(ECDF):
# 示例:计算训练集的ECDF
sorted_data = np.sort(x_train)
cdf = np.arange(1, len(sorted_data)+1) / len(sorted_data) # 阶梯式累积概率
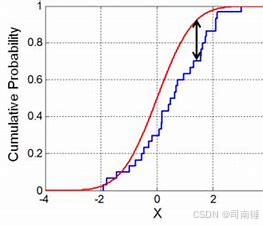
(2) 寻找最大垂直距离
• 统计量 D = 两组CDF曲线的最大垂直距离:
D
=
sup
x
∣
F
1
(
x
)
−
F
2
(
x
)
∣
D = \sup_x |F_1(x) - F_2(x)|
D=xsup∣F1(x)−F2(x)∣
• 其中
F
1
(
x
)
F_1(x)
F1(x) 和
F
2
(
x
)
F_2(x)
F2(x) 分别为两组数据的CDF
• statistic_location 即最大差异点的x坐标值
(3) 计算显著性(p值)
• 基于D值和大样本近似公式,计算p值判断差异是否显著:
p ≈ 2 e − 2 n D 2 ( n = n 1 n 2 n 1 + n 2 ) p \approx 2e^{-2nD^2} \quad (n=\frac{n_1n_2}{n_1+n_2}) p≈2e−2nD2(n=n1+n2n1n2)
2. K-S检验的适用场景
| 场景 | 处理方式 | 示例应用 |
|---|---|---|
| 两样本比较 | 比较两组数据的ECDF差异 | 验证训练集/测试集分布一致性 |
| 单样本拟合优度 | 比较样本与理论分布(如正态分布) | 检验数据正态性 |
| 多维度扩展 | 通过边缘分布或降维处理 | 高维数据分布对比(需谨慎) |
3. 与其他方法的对比
| 方法 | 优势 | 局限性 |
|---|---|---|
| K-S检验 | 非参数、对分布形状敏感 | 大样本时过度敏感,忽略局部差异 |
| t检验 | 检测均值差异高效 | 需正态分布假设 |
| Wasserstein | 对微小差异更稳健 | 计算复杂度高(O(n logn)) |
| PSI | 分箱后稳定性检测直观 | 依赖分箱策略 |
4. 实际应用注意事项
(1) 大样本问题
• 现象:样本量>1万时,K-S检验会检测到无实际意义的微小差异(如D=0.001但p<0.05)
• 解决方案:
# 结合效应量判断
effect_size = ks_result.statistic * np.sqrt(len(x_train)*len(x_test)/(len(x_train)+len(x_test)))
print(f"效应量: {effect_size:.3f}") # <0.1可忽略
(2) 多模态分布
• K-S检验对多峰分布的差异定位不敏感,建议配合可视化:
import seaborn as sns
sns.kdeplot(x_train, label="Train")
sns.kdeplot(x_test, label="Test")
plt.axvline(ks_result.statistic_location, color='red', linestyle='--')
(3) 分类数据
• 需先数值化(如通过分箱),但会损失信息,推荐使用卡方检验
5. 代码示例(完整流程)
from scipy import stats
import numpy as np
# 生成示例数据
np.random.seed(42)
x_train = np.random.normal(0, 1, 10000)
x_test = np.random.normal(0.05, 1, 8000) # 微小偏移
# 执行K-S检验
ks_result = stats.ks_2samp(x_train, x_test)
print(f"D值: {ks_result.statistic:.4f}, p值: {ks_result.pvalue:.2e}")
# 计算效应量
n_eff = len(x_train)*len(x_test)/(len(x_train)+len(x_test))
effect_size = ks_result.statistic * np.sqrt(n_eff)
print(f"效应量: {effect_size:.3f}") # >0.2有意义
# 可视化CDF差异
plt.figure(figsize=(10, 6))
plt.plot(np.sort(x_train), np.arange(len(x_train))/len(x_train), label='Train')
plt.plot(np.sort(x_test), np.arange(len(x_test))/len(x_test), label='Test')
plt.axvline(ks_result.statistic_location, color='black', linestyle='--',
label=f'Max Diff at {ks_result.statistic_location:.1f}')
plt.legend()
plt.show()
总结
K-S检验通过比较CDF曲线的最大距离来评估分布差异,适用于:
• 非参数场景
• 需要检测分布形状差异
• 样本量适中(<10万)
但在大数据场景下,建议结合效应量、Wasserstein距离或PSI综合判断,避免被统计显著性误导。



















 392
392

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











